基于数据中台的财务大数据可视化分析的实现
2021-09-12汪争贤吴建琳陈胡嵘夏禹晨
汪争贤 吴建琳 陈胡嵘 夏禹晨

摘 要:数据中台是以企业多类型大数据量的汇聚为基础,以统一数据模型为标准,通过丰富的数据标签,为前端应用提供敏捷的统一数据服务。基于此,针对电力企业财务管理对“企业资源实时掌握、经营活动动态反映”的要求,结合存储在ERP、财务管控系统、MDM平台、PMS系统中的基础业务数据,研究通过数据中台实现数据可视化分析的整个过程,对相关企业解决数据孤岛问题,实现数据融合有一定参考意义。
关键词:电力企业;数据中台;财务大数据;可视化
中图分类号:F23 文献标志码:A 文章编号:1673-291X(2021)20-0128-03
一、财务大数据可视化实现目标
基于数据中台的财务大数据可视化分析,是以各业务系统数据为基础,实现多维数据分析与展示,重点聚焦在数据分析服务化、数据应用工具化的能力上,围绕“会计信息实时反映、预算全链条管理、工程全过程管控、资产全寿命管理、电价电费全环节管控、资金全方位管理、风险在线监控”等专业管理模块,实现精益管理的需求。
系统实现上,通过数据中台总体架构,全面支持财务数据的接入、数据转换、数据计算、数据服务、展示分析。同时,结合省公司专业处室、基层单位新增业务、板块、应用场景需求,继续开展数据溯源、模型搭建、输出设计、数据分析与应用场景建设。整体上在充分利用现有各财务系统的建设成果基础上,通过技术整合、功能整合、数据整合、模式整合、业务整合等技术手段,将各个分离的信息数据集成实现共享,并能够以数据服务方式对外分享,使资源达到充分共享,结果将有效节省建设的投资,提升系统建设的经济效益。
二、总体构架
(一)总体架构
总体架构分为数据汇聚与服务层、数据可视化分析层。基于阿里DataWorks平台实现的数据汇聚与服务层,能够实现数据集成、开发、治理、服务、质量和安全等全套数据研发工作。数据可视化分析层,基于国家电网公司统一应用开发平台,通过集成可视化框架(WebGL、VUEX、ECharts、Mapbox、Three.js等),以采用B/S架构的方式对外提供服务。
(二)数据汇聚与服务层架构
数据汇聚与服务实现流程如下:
1.通过数据集成同步业务数据和日志数据至MaxCompute。
2.通过MaxCompute、DataWorks对数据进行ETL处理。
3.同步分析后的结果数据同步至分析库。
4.通过Quick BI、ECharts可视化建立用户画像。
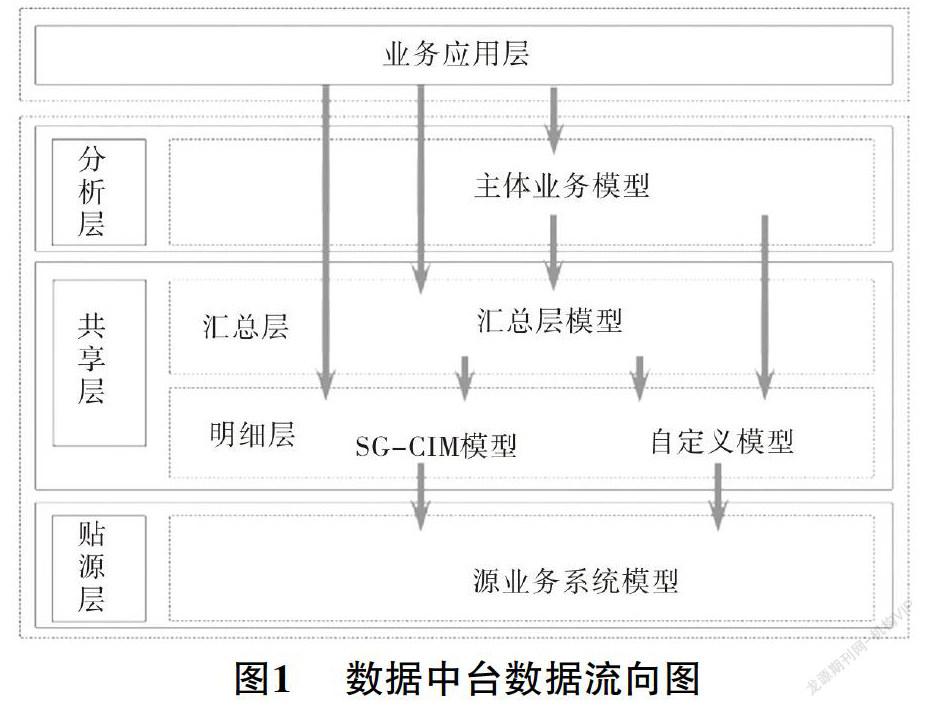
基于数据中台的大数据分析总体数据流向,如图1所示。
贴源层使用分布式数据仓库MaxCompute,源业务系统数据通过DataWorks DI、DTS、DataHub组件接入MaxCompute全量表和增量表;共享层使用分布式数据仓库MaxCompute,通过DataWorks-DI组件完成贴源层数据表到共享层基于模型的数据表和标准表转化;分析层利用MaxCompute、RDS、ADB等计算平台与分析库,通过DataWorks组件基于业务逻辑完成业务分析,保存计算后的结果表开发。计算结果可以封装为数据服务API,发布注册至API网关后,供外部报表工具调用进行可视化展示,或者以SDK方式共外部报表工具或应用进行调用。最后利用QuickBI、ECharts等报表组件或界面开发的方式进行可视化展示分析应用。
(三)数据可视化分析层架构
数据可视化分析层基于国网公司SG-UAP开发平台构建,其好处是遵守国家电网公司统一的开发标准,与统一权限系统等已实现标准的集成,运行平稳,降低了开发成本。详见图2。
由于SG-UAP平台集成开发工具是基于Eclipse工具实现的,符合业界主流开发标准,展现层能够很容易地与VUEX、ECharts等多种可视化框架集成,能够实现海量的可视化效果。
三、实现过程
(一)数据接入
将各业务系统数据进行汇聚整合,保留全量业务原始数据,形成贴源层,也称ODS层。源业务系统数据通过Datawork DI、DTS、DataHub组件接入MaxCompute贴源层全量表和增量表。该层只对各个来源的数据做汇聚、整合,并没有做过多的加工处理,数据基本还是原始结构。贴源层不做业务的解释,更不适合数据的分析、挖掘。
1.全量数据接入
针对数据量较小(小于50M),全量数据抽取对源端系统影响小。使用DataWorks-DI定时做全量抽取。每天全量保存在MaxCompute一个新的分区里面,按需开展数据更新。
新的分区,指的是通过设置分区字段,设置表为分区表。当使用分区字段对表进行分区时,新增分区、更新分区内数据和读取分区数据均不需要做全表扫描,可提高处理效率。
2.增量数据接入
(1)增量定时抽取
针对源端表只存在数据新增操作,且数据表具备增量标识字段,如日志类、访问流量类信息,可采取增量定时抽取策略。存量数据一次性通过DataWorks-DI从源端数据库表全量抽取,数据写入(INSERT OVERWRITE)MaxCompute贴源层的全量表。全量表按天分区,不设置生命周期。
增量数据每日根据增量标识使用DataWorks-DI做增量数据同步,数据直接存入MaxCompute全量表相应分区内。每天定时通过脚本将当天增量數据同步(INSERT)至MaxCompute全量表当日分区。
(2)增量实时同步
针对数据量较大并且源端数据存在增删改的情况,在数据接入中,存量数据一次性通过DataWorks-DI从源端数据库表全量抽取,数据写入(INSERT OVERWRITE)MaxCompute贴源层的全量表当日分区,全量数据按天分区保留全量切片数据,为节省空间仅保留两天分区数据。
