星上高光谱图像无损压缩方法
2021-09-11武少林张天序
舒 锐,武少林,龚 伟,陈 阳,张天序
(1.上海卫星工程研究所,上海 200240;2.华中科技大学 人工智能与自动化学院,湖北 武汉 430074;3.武汉工程大学 电气信息学院,湖北 武汉 430062)
0 引言
JPEG-LS(Joint Photographic Experts Group-Lossless)是图像无损压缩领域中最经典的、基于预测的算法,于2000 年由联合图像专家小组JPEG 所提出,其核心是LOCO-I(Low Complexity Lossless Compression,LOCO-I)算 法。JPEG-LS 算法先利用周围左边、左上边及上边的3 个像素值做一个简单的中值边界检测预测,然后通过上下文模型修正预测值,最后转化为Golomb-rice 编码输出。JPEGLS 算法以较低的复杂度达到了当年(2000 年)的最高压缩比。LOCO-I 算法仅为单通道的灰度图像设计,SHAWN 等[1]于2004年将LOCO-I 推广到了 高光谱图像压缩,提出了LOCO-3D 算法,压缩比提高了约0.2。2015 年,在C-DPCM 算法的基础上,WU等[2]发现剔除原始高光谱图像数据中的异常像素值后,预测的准确率提升了,此附带局部光谱异常数据剔除的算法被称为C-DPCM-RLSO(C-DPCMRemoval of Local Spectral Outliers)。人工智能的研究热潮将神经网络技术带到了各行各业中,LUO等[3]于2019 年提出了C-DPCM-RNN(C-DPCMRecurrent Neural Networks)方法,将C-DPCM 中的线性预测器替换为循环神经网络(Recurrent Neural Network,RNN),该方法在矫正的机载可见光/红外成像光谱仪(Airborne Visible Infrared Imaging Spectrometer,AVIRIS)公开高光谱测试集上取得目前本领域内最高的压缩比。目前,现存的很多高光谱图像压缩算法的通用性不强,很多算法采取单一的上下文模型,这类固定的上下文建模算法存在明显的弊端,容易产生偏好现象。例如,JPEG 算法在医学图像上的压缩性能表现明显优于其他类型图像,JPEG 2000 算法偏向于场景过度平滑的自然照片[4]。此外,有些算法需要调优参数才能达到较好的压缩性能。例如,C-DPCM 类算法虽然取得目前本领域内最好的压缩效果,但是算法需要提前给定图像聚类数目[5],显然,不同类型的图像的最优聚类数目是不同的,不恰当的图像聚类数目会降低算法的压缩性能。
针对上述目前很多算法存在的通用性与实用性方面不足的问题,本文从消除谱间信息冗余、谱内空间信息冗余这两个角度展开研究,综合了基于变换和基于预测的压缩技术,提出了一种基于KLT(Karhunen-Loève Transform)和自由无损图像格式(Free Lossless Image Format,FLIF)算法的通用型高光谱图像无损压缩算法。
1 设计思路
KLT,也称为主成分分析(Principal Components Analysis,PCA)变换,是一种能有效提取关键图像信息以及消除冗余的工具[6]。KLT 是一种线性变换,通过旋转坐标系让原始图像数据尽可能地落在新的坐标轴上,算法原理是通过旋转坐标系使得原始数据的协方差矩阵对角化。KLT 后的图像数据谱间将会不具备相关性。
本方案首先对高光谱图像进行可逆整数KLT,去除谱间相关性;再对可逆整数KLT 后的高光谱图像逐通道计算图像均匀性指标SR;对较均匀的图像通道采用FLIF 压缩器编码,对均匀性差的图像通道切换到哈夫曼编码器。通过对高光谱图像做一个可逆的整数KLT 变换来去除其谱间相关性,降低了原始数据的信息熵,去除了谱间的冗余信息,然后采取FLIF 压缩编码来消除谱内空间信息冗余,从而取得高压缩比。为了优化方案算法的压缩速度,本方案还提出了根据图像特点灵活切换压缩系统的策略,针对均匀图像(高SR 值)使用FLIF 算法压缩编码,针对非均匀图像(低SR 值)切换到简单的哈夫曼编码以加快压缩速度。本方法的算法流程如图1 所示。
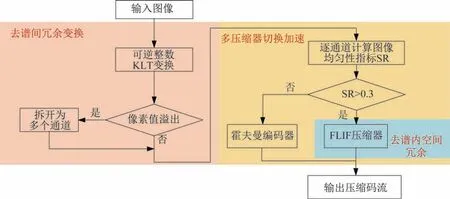
图1 高光谱图像无损压缩总体方案流程图Fig.1 Flow chart of the overall scheme for lossless compression of hyperspectral images
FLIF 压缩算法的工作流程图如图2 所示。FLIF 算法采取逐行逐个像素扫描的工作方式,像素首先经过1 个固定的预测模板得到残差值,残差进一步分解为近零符号编码表示。后续MANIAC 决策树将计算出上下文环境属性值,决策树根据属性标签值自顶向下遍历为该像素值选出最优的上下文环境,随后更新所有相关上下文环境,并对决策节点进行调整,调整决策树有助于提高下个输入像素的预测准确度。最后,算术编码器根据上下文环境提供的概率分布信息完成编码,并输出压缩码流。
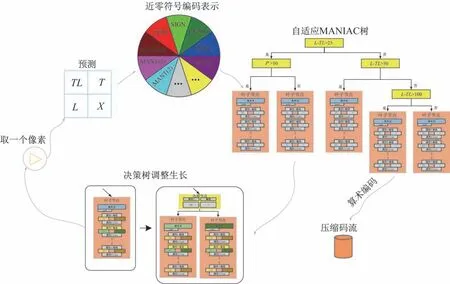
图2 FLIF 算法的工作流程Fig.2 Flow chart of the FLIF algorithm
图中,X表示待预测位置的像素,T表示X的上方像素,L表示X左边的像素,TL表示左上角的像素,可以根据T、L、TL像素值来预测X的值。
近零符号编码由零位(ZERO)、符号位(SIGN)、指数位(EXP(k,sign))和尾数位MANT(k)这几个部分组成。
MANIAC(Meta-Adaptive Near-zero Integer Arithmetic Coding)即元自适应近零整数算术编码。
2 数学模型的建立
2.1 KLT
KLT 的第1 步是计算原始高光谱图像数据的协方差矩阵COV:
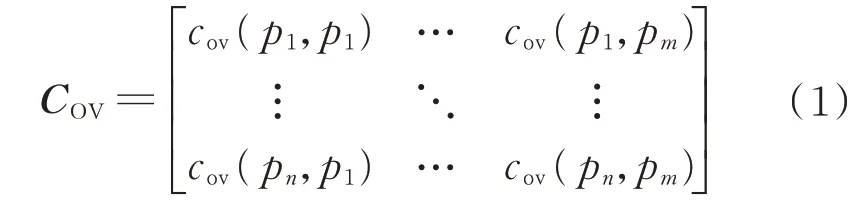
式 中:cov(pi,pj)为 第i个谱段和 第j个谱段的 协方差。
KLT 的目的是去除谱间图像的相关性,可以将去除谱间数据相关性的问题转化为将协方差矩阵COV中的元素cov(pi,pj)置 为0(i≠j),即为任意两个谱段数据的协方差为0。KLT 变换的原理是把协方差矩阵COV对角化。假设存在矩阵P,使得满足

式中:Λ为对角矩阵。
KLT 是一种线性变换,为了使变换后的新坐标系相互垂直,必须对上面的变换矩阵P进行正交化,正交化后的矩阵P即为KLT 矩阵。
求解正交变换矩阵P的方法分为两步:首先将协方差矩阵COV对角化得到变换矩阵P;然后再对矩阵P正交化。矩阵对角化的详细步骤如下所述。
通过求解下面的线性方程组

式中:λ为特征值;E为单位向量
对式(1)运用线性代数的方法,能解出p个特征值与p个相应的特征向量。再把特征向量按照特征值从大到小的顺序重新排列,得到变换矩阵为
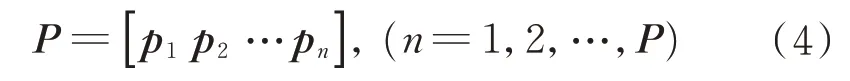
式中:p1为最大的特征值λ1所对应的特征向量;以此类推,pn为最大的特征值λn所对应的特征向量。
对式(4)得到矩阵P依次进行正交化与单位化,使得矩阵P满足

采用施密特正交化方法规范化向量p1,p2,…,pr。正交化的过程如下:
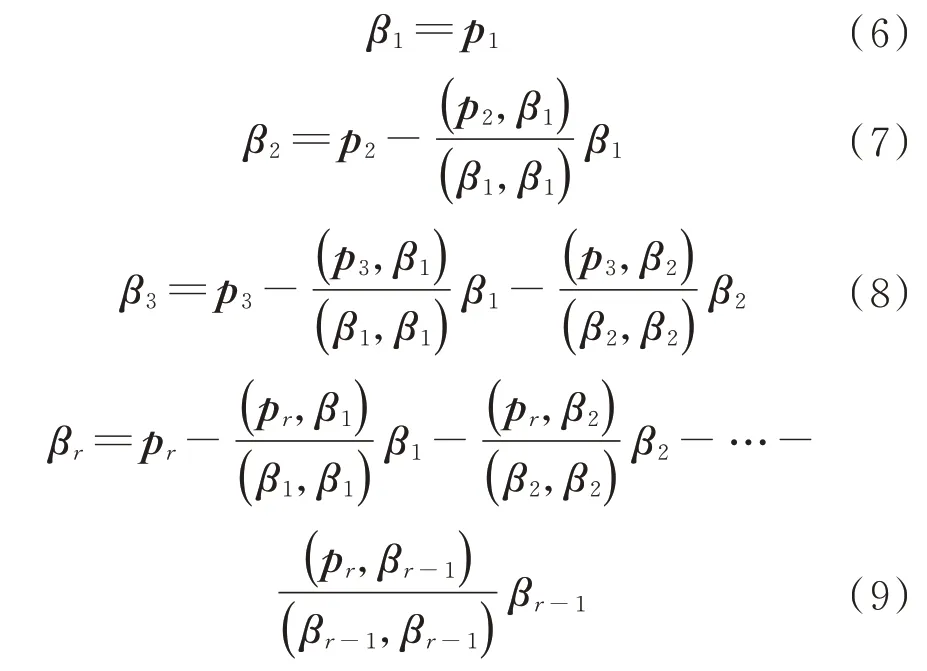
最后,将向量组β1β2…βr单位化,具 体方法如下:
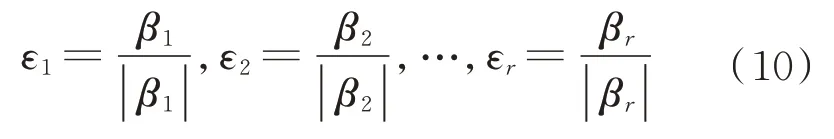
式中:|β1|为向量β1的模。
联立式(10)求得单位化后的向量,KLT 矩阵即为所求,记 做AT=[ε1ε2…εn],(n=1,2,…,P),那么A为

上面就是KLT 的全部步骤,使用变换矩阵A去谱间相关性的公式如下,假设输入的高光谱图像数据如下公式的形式,依旧记为X,记去谱间相关性后的数据记为Y,变换公式为

2.2 近零符号编码
近零符号编码是FLIF 算法数据存储块(包含像素值数据)的一种数据表示形式[7]。任意整型数据都能用近零符号编码表示,近零符号编码由零位、符号位、指数位和尾数位这几个部分组成,其中,指数位部分采取简单的一元编码(Unary Code)。所谓一元编码,即使用n-1 个二进制数据1 与末位尾数0(或者使用n-1 个二进制数据0 与末位尾数1)来表示存储正整数n。在FLIF 里的近零符号编码中,一元编码只用于表示指数位数据部分[8]。对于任意整数数据x,所需的指数位二进制比特数目为:e=(结果如果有小数,往上取整)。因此,假设采取一元编码表示16 位的图像数据,近零符号编码的指数位部分二进制长度有上限,即最多需要16 个bpp(bit per pixel)。
近零符号编码表示的每个bpp 都有它自己的上下文环境,所以每个bpp 的概率相互隔离,能够自动适应数据。在FLIF 里的近零符号编码中,指数位数据部分bpp 的概率不仅取决于它们所在的位置,还取决于它们的符号。
近零符号编码针对每个bpp 都建立独立的上下文环境,每个bpp 的可能值只能是要么为0,要么为1。由于FLIF 的核心是算术编码,近零符号编码使用一个12 位的整型数据存储每个bpp 的概率。12位的无符号(概率不可能为负数)整型数据能表示的整数范围是0~4 095,所以概率值为1 时表示该bpp 为1 的概率接近于零(该bpp 为1 几乎是不可能事件),当概率值为4 095 时表示该bpp 为1 的概率接近于1(该bpp 为1 是必然事件)。
FLIF 首先对该通道的图像数据逐行从左向右扫描得到预测误差值,扫描时比较存储当前通道图像预测误差值的最大值与最小值。在获得该通道图像预测误差值的最大值与最小值之后,这时我们就能确定k的上限值为
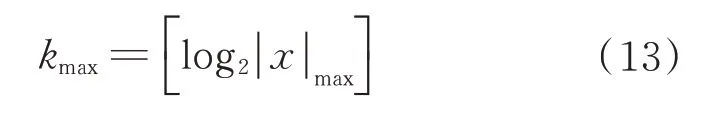
式中:[x]为向下取整,注意这里x一定取的是绝对值最大的值。
为了说明近零符号编码表示指数位的方法,下面以正整数1 000 为例说明,假设kmax=12,先计算k=[log21 000]=10,因 此 exp(k,sign)(k=0,1,…,9) 这 10 个 bbp 都置为 1,同 时exp(k,sign)(k>9)也就是剩下的bpp 都置为0。其实近零符号编码表示指数位exp(k,sign)的本质是记录数据有二进制位的长度,假如kmax=12,说明该通道图像的预测误差值最多有12 位。根据实际的像素预测经验情况,预测误差值范围通常为正太分布,预测误差值的典型值一般为几百左右,到exp(6,sign)即误差值为128,此时概率值达到最大值2 800。相反exp(k,sign)高位的概率值一般给较小的值(认为预测误差特别小的发生概率小),到从表3 的初始概率值可以看出,exp(k,sign)从高位(k=0)到低位(k=kmax)的初始概率值基本上是先逐渐增加然后减小的趋势。
近零符号编码的尾数部分用MANT(k),k=1,2,3,…表示,正如上所述近零符号编码表示的指数部分记录数据的二进制长度,所以数据的最高位必为1,数据尾数用MANT(k) 表示,尾数MANT(k)中的k值一定比数据的二进制长度少一位,故近零符号编码的尾数部分MANT(k)中的k值等于指数部分exp(k,sign)中的k减1 位。即:kmant=kexp-1。
2.3 自适应MANIAC 树
MANIAC(Meta-Adaptive Near-zero Integer Arithmetic Coding)即元自适应近零整数算术编码[9]。所谓元自适应,是指FLIF 编码器的上下文模型能够自动适应数据的特点。
FLIF 算法使用CABAC(Context-Adaptive Binary Arithmetic Coding)的一种变种方法作为其核心编码器[10]。因此,本文先简要地介绍CABAC 方法的核心原理。CABAC 算法的基础也是算术编码器,其中的概率模型是自适应的。CABAC 算法逐bpp 压缩图像数据,所以其中的算术编码器针对bbp进行建立概率模型,bpp 只有两种可能值1 或0,CABAC 算法对bpp 的初始概率各赋值为50%,即认为bpp1 或0 位出现的概率相等。CABAC 每压缩一个bpp,其概率模型就会相应地更新。这种概率随着压缩进程动态调整的策略有利于模型学习到数据的真实概率分布情况,从而提升算法的压缩性能。
CABAC 算法本质上还是只有一个上下文环境模型,如果有多个上下文环境模型信息,那么就能给每个上下文环境分配一个独立的概率模型[11]。参考FFV1 中的静态上下文环境设计,其上下文环境的数量为属性域的乘积,所以很难得到一个合适的上下文环境数量值。过多的上下文环境不利于压缩,因为模型的自适应能力是有限的(假设极限情况,一个或几个像素共用一个上下文环境)。同理,过少的上下文也不利于压缩,因为处于不同环境条件下的像素,其像素值的分布规律不同却共用同一个上下文环境也是不科学的。此外,固定数量的上下文环境数量会导致很多上下文环境被闲置,完全没被利用上。
与CABAC 算法相比,FLIF 使用一种动态数据结构作为其核心上下文环境模型。这种动态数据结构的本质是一颗决策树,决策树会随着压缩过程不断地生长。典型的MANIAC 树示意图如图3 所示,MANIAC 树内部节点与叶子节点的放大图如图4 所示。MANIAC 树的每个内部节点(非叶子节点)都有一个测试条件:判断一个上下文属性值(FLIF 含有多个)是否大于(或小于等于)阈值。类似二叉树的数据结构,MANIAC 树的内部节点也有左右两个分支。在压缩图像数据过程中,每个叶子节点包含一个实际的上下文环境,同时叶子节点还包括很多属性条件,每条属性拥有两个虚拟的上下文环境。而在解压图像数据的过程中,FLIF 只会用到实际的上下文环境。
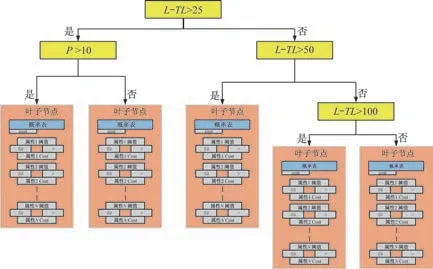
图3 典型的MANIAC 树示意图Fig.3 Schematic diagram of a typical MANIAC tree
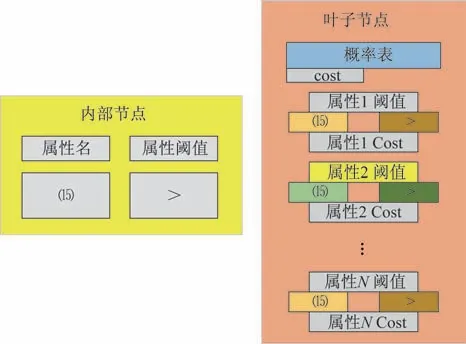
图4 MANIAC 树内部节点与叶子节点的放大图Fig.4 Enlarged view of the internal nodes and leaf nodes of the MANIAC tree
所谓自适应MANIAC 树,下面详细说明MANIAC 树的动态调整生长过程,也即自适应过程[12]。对于每个输入的待压缩像素数据,FLIF 首先计算每条属性条件值,结合计算好的每条属性值开始遍历MANIAC 树直到抵达叶子节点。叶子节点包含一个实际的上下文环境,利用其输出压缩比特流,以及一个损失值(输出bbp 的个数)。FLIF 取每条属性值的平均值作为其比较阈值,该条属性下小于阈值的有一个虚拟的上下文环境,而大于等于阈值的也有一个虚拟的上下文环境。压缩完一个像素值后,每条属性下的两个虚拟的上下文环境会分别更新各自的概率表与损失值。损失值也含义是该上下文环境压缩了多少个像素值。
MANIAC 属性向量组成了FLIF 算法的上下文环境,MANIAC 树里叶子节点所包含的上下文环境的主要成分也是这些MANIAC 属性组。假设当前待压缩的像素为X,X周围像素值的位置关系如图5所示。
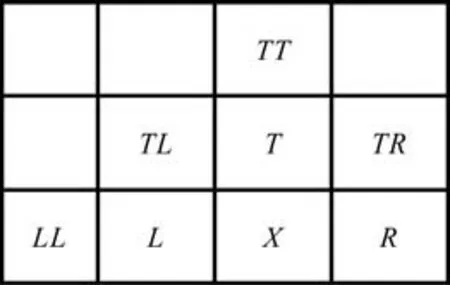
图5 像素X 周围像素的位置关系Fig.5 Positional relationship of pixels around pixel X
FLIF 定义了一些属性条件,见表1,这些属性条件构成了FLIF 算法至关重要的上下文环境。
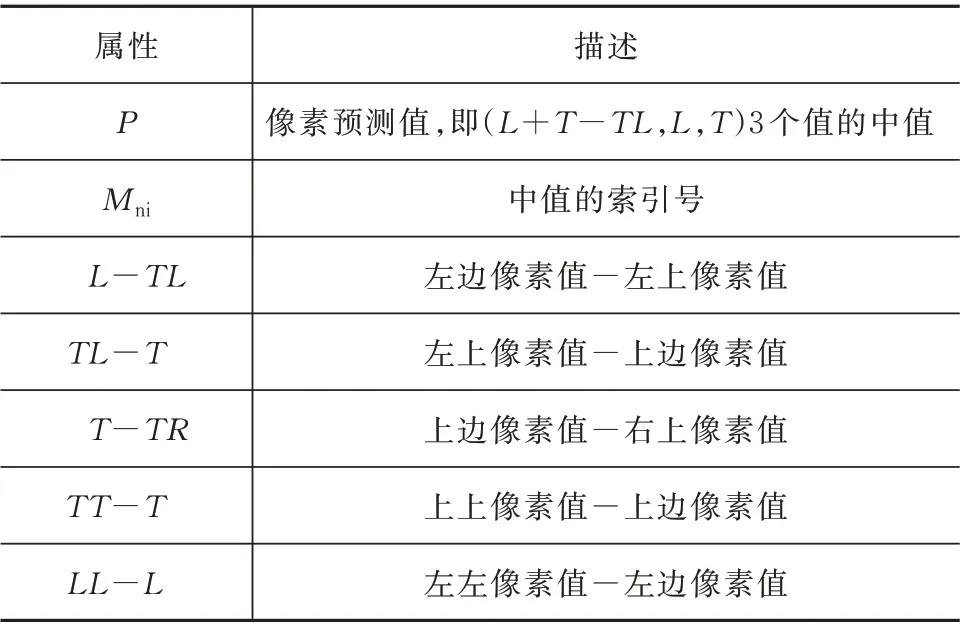
表1 MANIAC 属性表Tab.1 Attribute table of MANIAC
上表中Mni为像素预测使用哪个预测器,因为像素预测最终取的是(L+T-T,L,T)3 个值的中值,故Mni定义为

计算上下文环境里的损失值其实是在评估哪条属性对压缩任务帮助最大。如果该条属性是无关紧要的,那么该属性下的两个虚拟上下文环境的损失值之和就会大于等于实际上下文环境的损失值。相反,如果该条属性十分关键,那么使用两个不同上下文环境来编码数据将会更有利于压缩。通过比较叶子节点中实际上下文环境的损失值与属性下两个虚拟上下文环境的损失值,当某个属性下两个损失值的差值大于某个阈值的时候,此叶子节点就变成为一个决策节点,此决策节点的测试条件就是本属性。上述的叶子节点转变决策节点的过程,其实也是MANIAC 树生长的过程,如图6 所示,叶子节点一分为二,裂变为两个新的叶子节点。
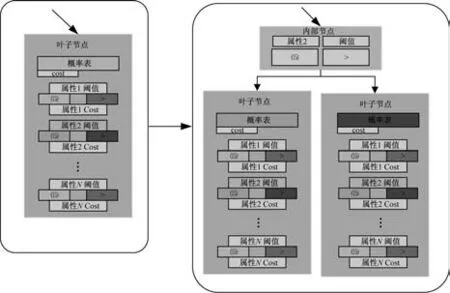
图6 MANIAC 树生长过程示意图Fig.6 Schematic diagram of the growth process of the MANIAC tree
2.4 提高压缩速度的方法
考虑到KLT 能分离出大部分噪声数据的特点,这里提出了针对FLIF 压缩器的优化加速方法。FILF 压缩器属于复杂压缩系统,压缩性能强,但是内部算法复杂度高,耗时长;而哈夫曼编码器属于简单压缩系统,速度快,但是压缩能力弱。本文提出了根据图像均匀程度灵活地在FILF 压缩器与哈夫曼编码器之间切换的策略,对均匀图像应该选择FILF 压缩器以提升压缩能力;但是对于噪声大的非均匀图像FILF 压缩器与哈夫曼编码器性能相当,此时选择更快的哈夫曼编码器以缩短压缩时间。本文综合图像行间相关性与列间相关性作为图像均匀性指标,图像行间相关性与列间相关性的权重各取一半(即50%)。计算出图像所有相邻行之间的相关系数并取均值作为全图的行间相关性,运用相同的方法计算出全图的列相关系数。定义图像均匀度指标SR 为(+)/2,其最小值 为0,最大值为1,根据统计学知识,一般认为相关系数0.8 以上表明具有强的相关性;相关系数0.3~0.8 之间认为数据间具有一定的相关性;而相关系数0.3以下则认为数据间没有相关性。相关系数区间含义如下:

本文通过灵活地切换复杂压缩器(FLIF)与简单压缩器(哈夫曼编码器)来加速压缩过程,关于切换压缩器的时机如何选择的问题,结合上述的相关系数区间含义,本文设置图像均匀度指标SR 的阈值为0.3。当图像均匀度指标SR 大于0.3 时,说明图像具备较强的空间相关性的特点,故采取FLIF 压缩这类图像;当图像均匀度指标SR 小于0.3 时,说明图像受噪声污染严重,故切换到哈夫曼编码器来压缩这类图像以缩短压缩时间。
哈夫曼编码属于变长编码技术,能够有效地消除数据的编码冗余,是一种基于二叉树的实现输出最短二进制码长度的方法。哈夫曼编码需要数据分概率的先验信息,故要先统计图像所有像素值的频率,为了节省存储空间,频率信息使用一个无符号的16 位整型数据存储,16 位无符号整型数据所能表示的范围仅为0~65 535,因为可能存在频率超过65 535 的情况,频率表最后会统一归一化到0~65 535 之间。为了减少先验频率分布信息的体积,本文仅对该图像存在的值存储统计的频率分布信息,即仅存储像素值最小值到最大值之间的频率分布信息。有了数据频率分布之后,先建立哈夫曼编码树(数据结构是一颗二叉树),再遍历哈夫曼树得出每个数据的二进制编码,哈夫曼树会为高频率的数据分配较短的编码,进而实现最优编码过程,接下来根据编码表对待压缩像素重新生成二进制码,消除编码冗余。解码方法跟上述的压缩过程基本相同,也是先建立哈夫曼树,然后根据压缩码流逐位读取遍历哈夫曼树直到遍历到叶子节点便恢复出一个像素数据,接着继续取压缩码流重复遍历过程直到读尽压缩码流(或者恢复出最后一个像素)便停止。
3 仿真试验及结果分析
3.1 仿真结果
本文的实验数据来自高分五号卫星高光谱数据,数据分两部分:可见光近红外(VN)和短波红外(SW)。VN 有150 个波段,SW 有180 个波段,总共330 个波段。
VN 波段范围0.39~1.03 μm 左右,5 nm 一个间隔。SW 波段范围1.0~2.5 μm 左右,10 nm 一个间隔。空间分辨率30 m。试验数据选取北京某机场,选取6 组数据,分别为VN①~VN③,SW①~SW③,如图7 所示。

图7 VN①(第50、60、70 波段合成)高光谱实验测试图像Fig.7 Hyperspectral experimental test image for VN ①(integrated 50th,60th,and 70th waveband)
压缩结果指标统一采取每个像素所占的bpp 指标,本文对多组高光谱图像测试用例进行压缩实验,见表2。
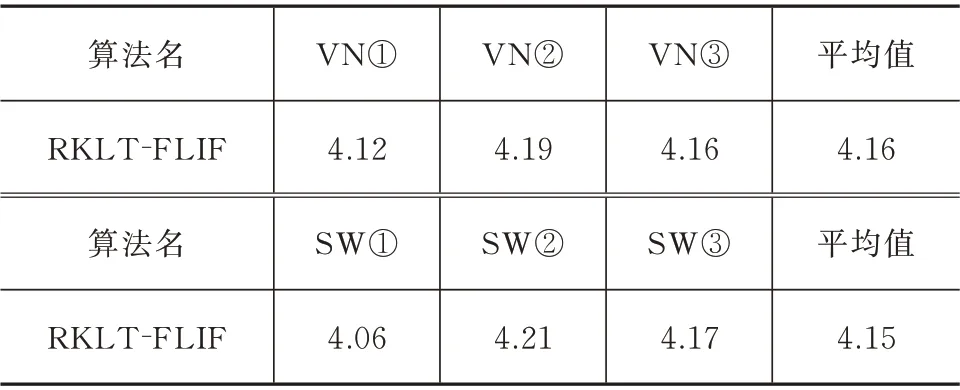
表2 高光谱测试图像的无损压缩实验的bpp 结果Tab.2 The bpp results of the lossless compression experiment of hyperspectral test images
本文提出的RKLT-FLIF 方案的另一个优点是能够根据图像的均匀程度(噪声情况)在复杂FLIF与简单哈夫曼编码器之间切换,从而加快压缩速度,缩短压缩时间。本文增加了一个对照实验组来分析自适应切换压缩器策略的效果,对照实验组禁用了哈夫曼编码器。针对上述的高光谱图像测试样本,在相同的测试实验平台上,本文做了相关实验统计出了RKLT-FLIF 方案与RKLT-FLIF(无哈夫曼编码)方案完成压缩所耗费的时间,见表3。
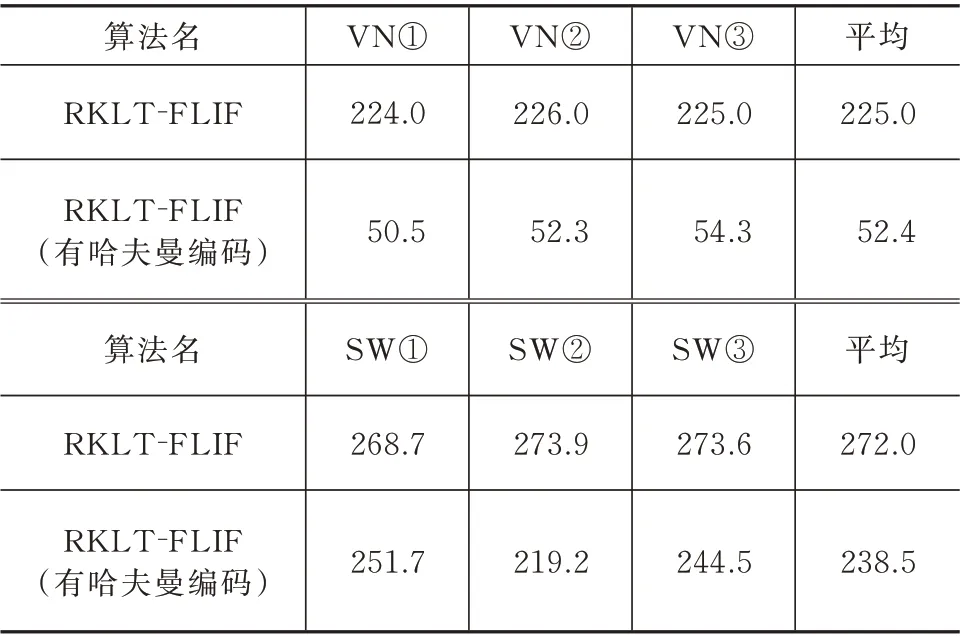
表3 高光谱测试图像的压缩实验耗时结果Tab.3 Time-consuming results of the compression experiment for hyperspectral test images
3.2 结果分析
通过表2 中的bpp 结果,实验结果表明,针对可见光bpp 达到4.16,短波红外bpp 达到4.15。据文献[13]显示,本文算法相比于C-DPCM 更具通用性。C-DPCM 算法的原理是先对高光谱bpp 图像进行聚类,聚类算法通常是k-Means 或LBG 聚类算法,再针对不同的类别的图像块分别进行预测压缩[14]。然而,图像聚类算法有个明显的缺陷,难以确定合适的类别数,过多或过少的类别都会降低压缩性能,C-DPCM(order 20)括号里的order 20 表明算法的聚类数目为20[15],20 类的数量是经过多次试参才确定的,这意味着若更换测试样本,C-DPCM 类算法性能可能会出现下滑,与C-DPCM 类算法相比,本算法的优点是无须根据输入图像特点手动调整任何参数,通用性更强。
本文提出的RKLT-FLIF 方案的另一个优点是能够根据图像的均匀程度(噪声情况),在复杂FLIF与简单哈夫曼编码器之间切换,从而加快压缩速度,缩短压缩时间。本文增加了一个对照实验组来分析自适应切换压缩器策略的效果,对照实验组禁用了哈夫曼编码器。针对上述的高光谱图像测试样本,在相同的测试实验平台上,本文做了相关实验统计出了RKLT-FLIF 方案与RKLT-FLIF(无哈夫曼编码)方案完成压缩所耗费的时间,见表3。从表3 可以看出:针对可见光波段图像,RKLT-FLIF(无哈夫曼编码)的耗时平均值接近于RKLT-FLIF的5 倍;针对短波红外波段图像,RKLT-FLIF(无哈夫曼编码)的耗时平均值接近于RKLT-FLIF 的1.14 倍。因此,实验结果表明,自适应切换压缩器策略的加速效果可以,加快了压缩速度,同时又没有降低压缩质量。
4 结束语
本论文提出了基于KLT 和FLIF 算法的高光谱图像无损压缩方法,高光谱图像先经过可逆整数KLT 去除图像的谱间冗余信息,再由谱内压缩器FLIF 去除图像空间冗余信息得到压缩码流。FLIF算法中的MANIAC 决策树能够在压缩过程中适应输入图像的特征,MANIAC 决策树的每个叶子节点都维护着一个实际上下文环境和两个虚拟上下文环境,每编码完一个像素便更新一次上下文环境,叶子节点随着压缩进度逐渐分裂从而增加了上下文环境的数量,谱间去相关变换与多上下文环境的设计使得方案取得的实验结果还是不错的。C-DPCM 类算法需调参确定合适聚类数目,而多上下文环境设计的自适应能力使得本算法更具通用性和实用性。本文还提出了多压缩器灵活切换的策略,通过逐通道计算图像均匀性指标SR,针对高SR 图像使用复杂的FLIF 压缩器,对低SR 图像切换到简单的哈夫曼编码器,在可见光波段将压缩时间平均缩短为原来的1/5。
