K-means聚类方法在疟疾患儿死亡率预测中的性能表现分析
2021-09-10冉恩慈李坤赵维祥王康王晨星
冉恩慈 李坤 赵维祥 王康 王晨星
摘要:疟疾患儿眼底OCT图像中出血点的面积及相对位置,抽取成为一个48维的特征向量。K-means聚类方法是常用的经典无监督学习方法,计算各样本在特征空间内的位置,根据样本点的相对位置关系自动聚类,形成不同的分类。通过在此特征向量空间应用K-means聚类方法,对所有样本进行聚类操作。实验结果表明,单纯分析聚类的效果还不错,但与实际治疗效果相比较,则分类准确率较低。这说明,K-means聚类方法的适应能力不强,更适合不同类样本在特征空间内的聚类中心差距较大的情况,若不同类样本在特征空间内混叠比较严重,则聚类结果与真实的分类结果可能存在较大偏差。
关键词:K均值聚类;无监督学习;眼底OCT;疟疾;空间建模方法
1.引言
疟疾是一种因疟原虫感染引发的虫媒传染病,寒战、出汗和发烧等症状会周期性发作,存在一定的死亡风险。目前,已有治疗疟疾的特效药,可以获得较好的治疗效果,但在医疗条件较差、药品短缺的非洲部分地区,疟疾依然是儿童早夭的主要原因之一。因此,研究预测疟疾患儿的方法,将有限的医疗资源用在最需要的人身上是非常有意义的工作。
K均值聚类算法[1]是解决聚类问题的一种无监督学习方法,对处理大数据集问题具有可伸缩性和高效性的特点,当簇接近高斯分布时效果较好。在K均值聚类算法中,首先需要根据初始聚类中心来确定一个初始划分,然后对初始划分对聚类进行优化。Bu等人[2]主要研究K均值聚类算法在动态问题中的性能表现并取得一定的成果。Liu等人[3]将K均值聚类算法和SVM支持向量机结合起来,在其中引入核的概念,并取得了较好的效果。Nguyen等人[4]将启发式算法融合到K均值聚类算法中,研究改进型的启发式K均值聚类算法并取得了一定的成就。Qin等人[5]将K均值聚类算法应用到传感器网络上,并取得了较好的效果。陈吉成等人[6]将K均值聚类算法应用在社区检测领域,将多关系网络解读为三阶张量,再将应用Rescal分解得到的结果作为进化K均值聚类算法的输入。张鸿雁等人[7]为避免初始聚类中心陷入局部最优,孤立点影响聚类准确性,结合分裂式思想,提出一种基于密度加权的K均值聚类算法。周玉等人[8]为了提高神经网络分类器的性能,提出一种基于K均值聚类的分段样本数据选择方法。
本文的工作是将患儿眼底OCT图像的规格化数据直接作为K均值聚类方法的输入,再将聚类结果与真实的治疗结果进行比对,从而得出分类的准确率。第2节先对问题进行描述,并介绍如何处理眼底OCT图像,以及将处理结果带入K均值聚类算法的过程。第3节对实验结果进行分析。第4节给出本文的研究结论及展望。
2.问题描述
在临床实践中,疟疾患儿多伴有眼底出血。通过患儿入院时的眼底OCT图像,可对其眼底出血的情况有一个大致了解。Gabriela Czanner等[9]提出了一种空间建模方法,用以标识患儿眼底出血情况的空间分布和严重程度。在此空间模型下,计算患儿眼底OCT图像中的出血点面积占其所在区块的比例,进而将每一幅图像规格化为一个48维向量,且每个维度上的取值范围都是[0,1]。目前已有的132个患儿数据对应的最后治疗结果分为三类:完全康复、留有后遗症和死亡。
K均值聚类方法的主要参数有:聚类数目N,距离定义和初始聚类中心的产生方法。聚类数目是一个正整数,本文中采用三种不同的分类设置方法:I.按照实际治疗结果分为3类,N=3;II.分为两类:生还(包括完全康复和留有后遗症)和死亡,N=2;III.分为两类:完全康复和未完全康复(留有后遗症和死亡),N=2。距离定义:欧氏距离、曼哈顿距离和余弦距离。初始聚类中心产生方法:引入已有的聚类中心、随机生产聚类中心。
3.实验结果及分析
测试数据集共有132个病例,其中90个病例完全康复,24个病例留有后遗症,18个病例死亡;生还病例114个,死亡病例18个;完全康复病例90个,未完全康复病例42个。实验通过调用MATLAB的内置函数kmeans( )实现K均值聚类算法,按照前述3种不同的分类设置方法分别进行聚类,并要求每组参数设置重复10次取最优结果,然后进行对比分析。实验结果如下:
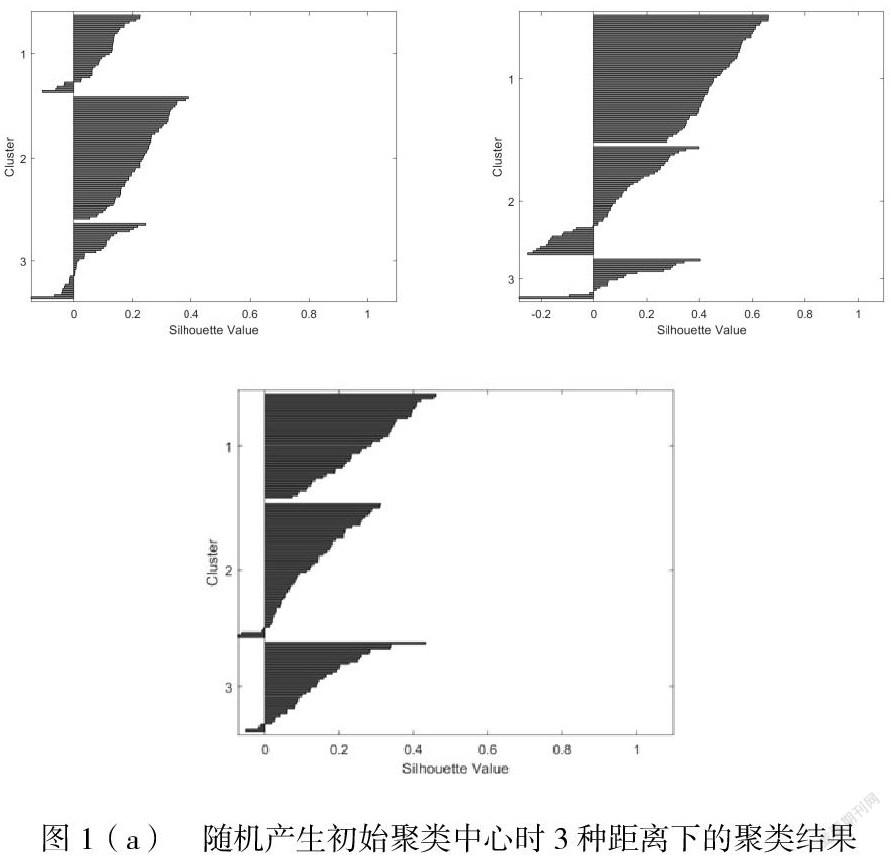
I. 在前述第(I)中分类设置方法下,根据初始聚类中心是否随机产生分两类情况进行测试。初始聚类中心随机产生的前提下,分别测试样本集在欧氏距离、曼哈顿距离和余弦距离下的聚类结果,如图1所示。
此外,分類准确率和最佳距离总和如表1所示:
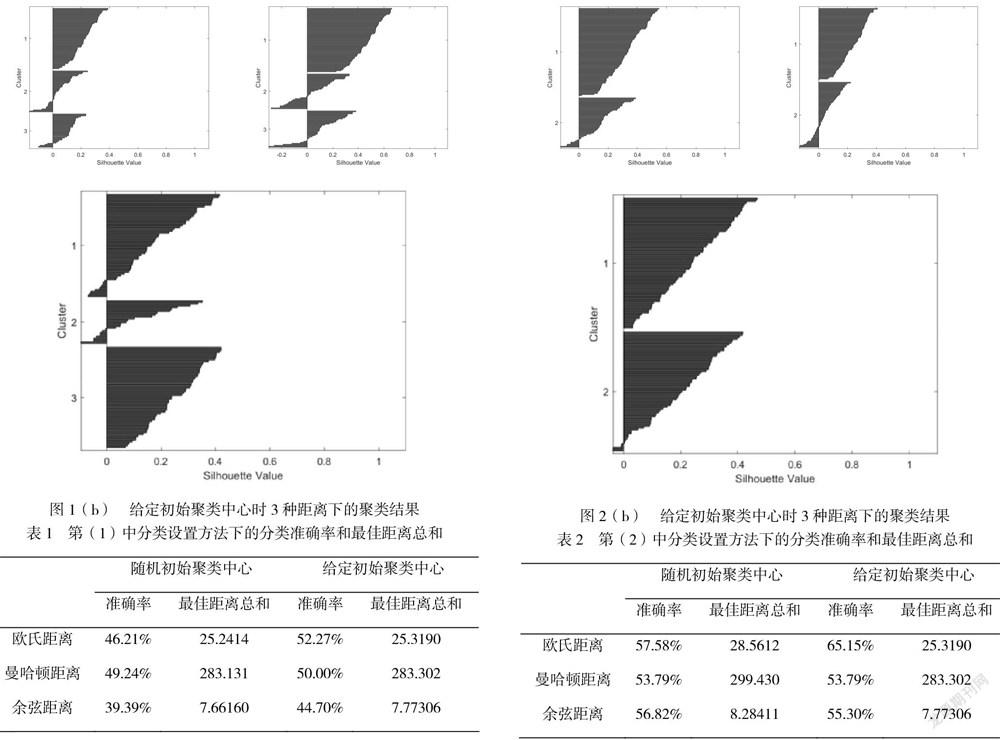
II. 在前述第(II)中分类设置方法下,根据初始聚类中心是否随机产生分两类情况进行测试。初始聚类中心随机产生的前提下,分别测试样本集在欧氏距离、曼哈顿距离和余弦距离下的聚类结果,如图2所示。
此外,分类准确率和最佳距离总和如表2所示:
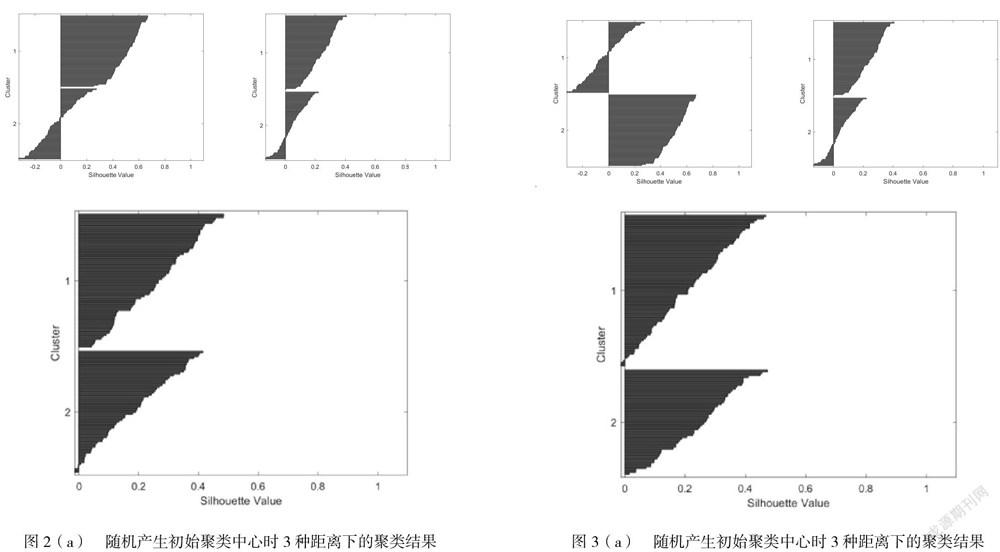
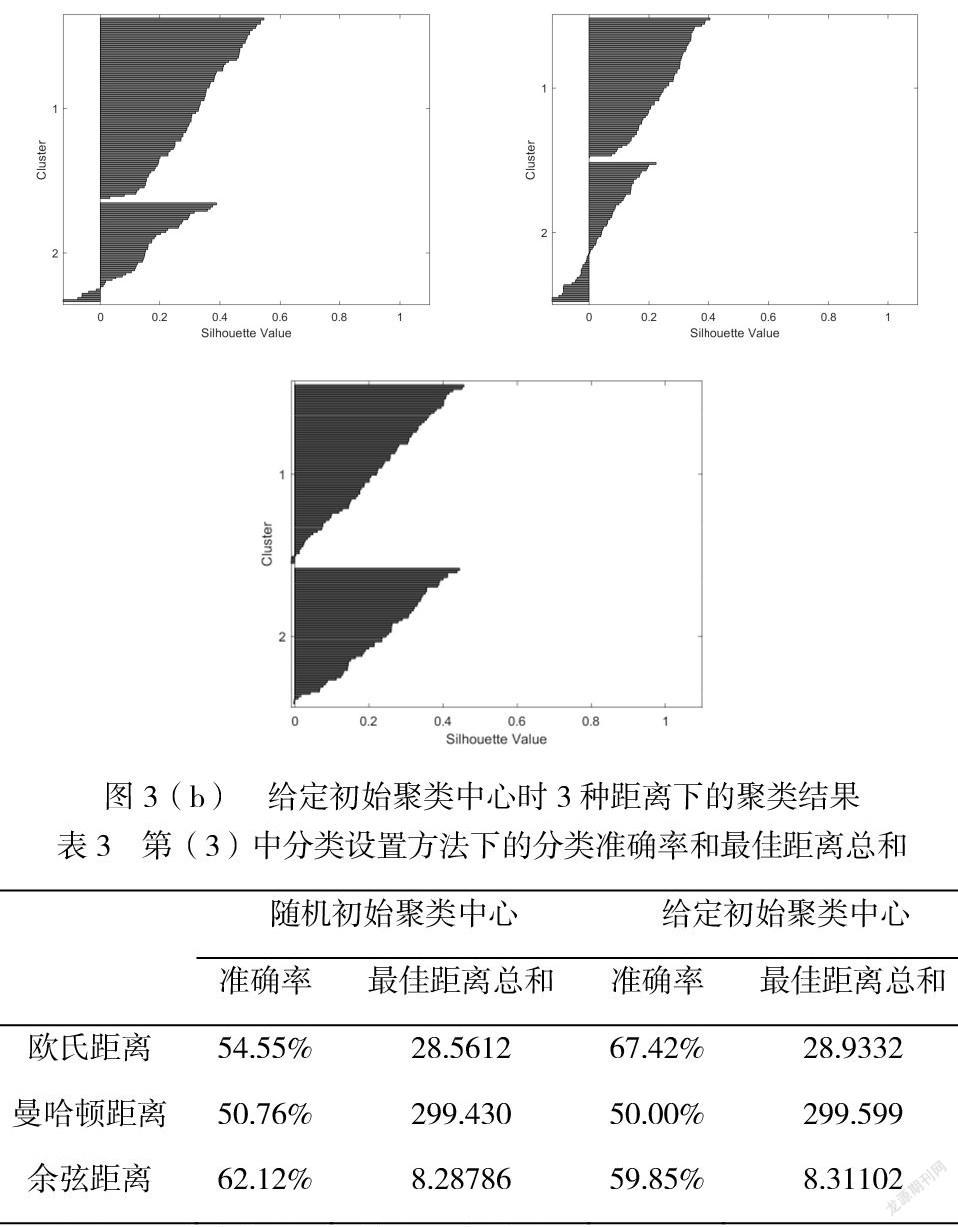
III. 在前述第(III)中分类设置方法下,根据初始聚类中心是否随机产生分两类情况进行测试。初始聚类中心随机产生的前提下,分别测试样本集在欧氏距离、曼哈顿距离和余弦距离下的聚类结果,如图3所示。
此外,分类准确率和最佳距离总和如表3所示:
针对以上实验结果需要做出几点说明:
第一、图1至3中的Silhouette Value是衡量某个样本点与它属聚类相较于其它聚类的相似程度的指标。其数值本身是被规格化的,取值范围[-1,1],值越大(趋近1)表明这个结点更匹配其属聚类而不与相邻的聚类匹配。但是,Silhouette Value是可以根据任意距离度量,如:欧氏距离、余弦距离等。
第二、K均值聚类算法是将所有样本进行聚类,聚类结果1、2、3与实际治疗的效果并无确定的对应关系。本文在计算表1至3的准确率时采用的是按照遍历所有可能的对应关系,然后取准确率最高的一项作为本次聚类结果的准确率。
第三、表1至3中的最佳距离总和是在各自距离定义下进行计算,在不同的距离定义之间,最佳距离总和不具备可比性。
第四、所谓随机初始聚类中心是指聚类中心坐标随机产生,按照K均值聚类算法的要求依次迭代,直到取得符合要求的聚类效果为止。给定初始聚类中心是指将已知的各类样本的聚类中心坐标计算出来,作为初值输入到K均值聚类算法中,但后面仍需按要求迭代,直到取得符合要求的聚类效果为止。
根据以上实验结果可知,在第(I)种分类设置方法下,无论是聚类效果(Silhouette Value)还是分类准确率,都不如第(II)和(III)种分类设置方法,这个主要是因为三分类的难度远大于二分类所致。此外,在歐氏距离、曼哈顿距离和余弦距离这三种不同的距离下,可以看出无论是哪种分类设置方法,余弦距离的聚类效果最好(Silhouette Value数值整体最高)。然而,在比较分类准确率时,无论在哪种分类设置方法下,余弦距离的表现都不好。这是因为聚类方法是一种无监督学习的方法,其按照既有的标准(最佳距离总和最小)来判断聚类效果,而分类是有明确的分类目标的,聚类结果与分类结果的差异在于两者之间的标准不同。
4.结论与展望
综上所述,K-means聚类算法比较适合不同类样本在特征空间内的聚类中心差距较大的情况,若不同类样本在特征空间内混叠比较严重,则聚类结果与真实的分类结果可能存在较大偏差。对已有实际分类结果的问题而言,如在现有的距离定义下,难以解决样本混叠的问题,可以考虑开发一种新的更灵活的距离定义,使距离定义自身具备自适应调整的能力,根据已有信息进行自适应调整,使之可以解决样本混叠的问题,取得较好的分类效果。
参考文献:
[1]Govender,P,Sivakumar,V,Application of k-means and hierarchical clustering techniques for analysis of air pollution:A review(1980-2019)[J],ATMOSPHERIC POLLUTION RESEARCH,2020,11(1):40-56
[2]Bu,Z,Li,HJ,Zhang,CC,Cao,J,Li,AH,Shi,Y,Graph K-means Based on Leader Identification,Dynamic Game,and Opinion Dynamics[J],IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING,2020,32(7):1348-1361
[3]Liu,XW,Zhu,XZ,Li,MM,Wang,L,Zhu,E,Liu,TL,Kloft,M,Shen,DG,Yin,JP,Gao,W,Multiple Kernel k-Means with Incomplete Kernels[J],IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE,2020,42(5):1191-1204
[4]Nguyen,H,Bui,XN,Tran,QH,Mai,NL,AF Hoang Nguyen,Xuan-Nam Bui,Quang-Hieu Tran,Ngoc-Luan Mai,A new soft computing model for estimating and controlling blast-produced ground vibration based on Hierarchical K-means clustering and Cubist algorithms[J],APPLIED SOFT COMPUTING,2019,77:376-386
[5]Qin,JH,Fu,WM,Gao,HJ,Zheng,WX,Distributed k-Means Algorithm and Fuzzy c-Means Algorithm for Sensor Networks Based on Multiagent Consensus Theory[J],IEEE TRANSACTIONS ON CYBERNETICS,2017,47(3):772-783;
[6]陈吉成,陈鸿昶,基于张量建模和进化K均值聚类的社区检测方法[J],计算机应用,2021,1-8,@ 1001-9081
[7]张鸿雁,杜文锋,武丽芬,基于密度加权的分裂式K均值聚类算法[J],计算机仿真,2021,38(04):254-257
[8]周玉,孙红玉,朱文豪,任钦差,基于K均值聚类的分段样本数据选择方法[J],计算机应用研究,2021,38(06):1683-1688
[9]AU MacCormick,IJC,Williams,BM,Zheng,Y,Li,K,Al-Bander,B,Czanner,S,Cheeseman,R,Willoughby,CE,Brown,EN,Spaeth,GL,Czanner,G,Accurate,fast,data efficient and interpretable glaucoma diagnosis with automated spatial analysis of the whole cup to disc profile[J],PLOS ONE,2019,14(1):
通讯作者,讲师,博士,国家大学生创新创业训练项目(S202010439003)指导教师,山东省自然科学基金联合专项(ZR2016FL05)主持人。
(本文工作在国家大学生创新创业训练项目(S202010439003)和山东省自然科学基金联合专项(ZR2016FL05)的资助下完成。)
