ARP交织器在Turbo码全并行译码算法中的应用研究
2021-09-09任宪文
任宪文 张 琰
1.海装上海局驻南京地区第四军事代表室;2.南京熊猫汉达科技有限公司
0 引言
Turbo码于1993年被提出,对信道编码产生了革命性的意义,使信道编码理论研究进入了新的阶段。Turbo码凭借优异的译码性能,在各个领域中得到了广泛应用。Turbo码在速率较低的3G和4G移动通信中得到了很好的实践,但是受限于其译码算法固有的串行性,在译码时延和吞吐量等方面有较大的劣势,越来越难以满足未来通信发展的需求。因此,进一步研究Turbo码的并行译码算法、提高译码效率、降低译码时延,有重要的现实意义和工程价值。
Turbo码 全 并 行 译 码(Fully-Parallel Turbo Decoding,FPTD)算法的提出,将整个码块的每个子块大小分割成了1 bit,获得了最大的并行度,并采用奇偶交织的操作,实现了Turbo码的完全并行译码。长期演进技术(Long Term Evolution,LTE)系统中,使用二次项置换多项式(Quadratic Permutation Polynomials,QPP)交织器,实现了Turbo码的分块并行译码。FPTD算法使用QPP交织器能够完美适用于LTE系统,大幅减少了Turbo码的译码时延,提高了吞吐量。但QPP交织器是固定的,不会随码率变化而自动适配,因而极大限制了FPTD算法的性能。
随着Turbo码并行译码技术的不断发展,构造相应的并行交织器一直是Turbo译码领域研究的重点。2016年,一些公司和研究机构提出了“Turbo码2.0”,即“增强型”Turbo码,其采用更长的码长和更低的码率,设计了新的打孔方式和并行交织器,获得了较好的译码性能。对于并行交织器的设计,“增强型”Turbo码采用的是近似正则置换(Almost Regular Permutation,ARP)交织器,并能跟随码率进行相应变化,可以有效应对突发干扰,实现较高的并行度。
为进一步提高FPTD算法的性能,对ARP交织器的性能进行具体分析,并将其应用于FPTD算法中,可以进一步提升FPTD算法的译码性能。本文先简要介绍了Turbo码的FPTD算法,再详细描述“增强型”Turbo码的ARP交织器的定义和最大无争用性,并进行了性能仿真和对比分析。
1 Turbo码的全并行译码
1.1 Turbo码的编码器
经典的Turbo编码器由两个分量编码器并行级联而成,因而又被称为带交织的并行级联卷积码(Parallel Concatenated Convolutional Code,PCCC)。PCCC编码结构主要由两个分量编码器、内部交织器以及删余和复用结构组成。LTE系统中Turbo码的分量编码器采用的编码结构如图1所示。

图1 LTE中的Turbo码分量编码器
相对于常规的Turbo码,LTE的Turbo码各个分量编码器使用各自的尾比特来进行状态终结,即图1中的虚线部分,在编码之后利用开关使寄存器归零。状态分量编码器的传输函数为:
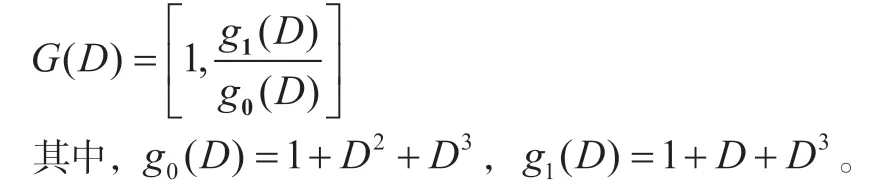
1.2 FPTD译码架构
FPTD算法的基本译码架构如图2所示。与LTE Turbo码的分块译码架构相比,全并行译码架构相当于把每个子块的大小减小到1,分别对应一个译码单元并进行译码,将码块分为上下两路。

图2 全并行译码架构
编码交织器采用QPP交织器,作为确定型交织器,其采用两个二次多项式进行交织和解交织运算。对于码长为K的码块中第i个比特,交织后的顺序变为:
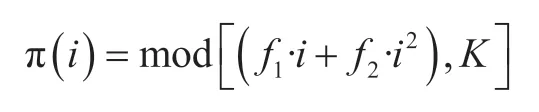
其中,f1和f为交织参数,均小于K。交织地址可以采用递归来计算,无需乘法或者取模运算。较为简单地生成多项式使其复杂度低,易于实现。QPP交织器可以实现并行译码的无冲突交织,大大增强译码器的并行处理能力,给LTE中Turbo码提供更高的译码速率。
为进一步减小译码时延,FPTD算法充分利用了QPP交织器的奇偶特性。译码时,将整个数据分为两组,上路奇数位置和下路偶数位置的数据为一组(图2中白色译码块);上路偶数位置和下路奇数位置的数据为另一组(图2中阴影译码块)。一次迭代过程就分为了两个半次迭代过程,在上半次迭代过程中,第一组白色译码块进行计算,并交换外信息和传递状态度量值到阴影块;下半次迭代过程中,第二组阴影译码块进行计算,并交换外信息和传递状态度量值到白色块,每次操作上下两路都有50%的码字进行译码。按照这种操作,在一次迭代过程中,所有码字完成译码只需要2个时钟周期,并且实现了完全并行的操作。传统的Log-MAP算法在一次迭代过程中完成所有码字的译码,需要的时钟周期与码块长度有关,码长越长,译码时钟周期越长,译码本质上仍是串行操作。
2 增强型Turbo码中的ARP交织器
2016年,Orange公司提出“增强型Turbo码”,采用ARP交织器。LTE的QPP交织器是固定的,不会随码率变化;而提出的ARP交织器能根据不同的码率进行设计,可以更有效地进行交织。其基本交织公式为:

其中,S是大小为Q的集合,P,S (0),S (1)… S(Q−1)取决于码长为K的大小和编码的码率。
2.1 ARP交织器的最大无争用性
ARP交织器具有最大无争用性。假定qQ可以被K整除,对于任意窗长度W为qQ的码块而言,都不会产生内存争用问题。可以求得:

其中,WqQ= ,内存器个数为KqQ,对于每个码块第i个位置,未交织码块地址为:

式中,交织后的地址分别被分配到K/qQ个不同的内存器中,不会出现内存争用的现象。
若码块的长度K=8 000,打孔掩码的长度Q=16,则交织器允许的并行度为{2,4,5,10,20,25,50,100,125,250,500}。
2.2 ARP交织器的参数设计
对于P,Q,S(0),S(1)…S(Q−1)的选择步骤:(1)P的选择,P值选择与规则交织器(ππ(i) =P×imodK)中方式一样,确保更大的最小距离。(2)Q的选择,对于长度Q的打孔方式中,数据的位置按照被保护的等级来排序,按照排序顺序需求确定Q值。(3)S(0),S(1)…S(Q−1),确保打孔模式下具有较高保护级别的数据位置和较低保护级别的数据位置能够产生关联,选取相关数值。
设计参数时,只保留具有最大的最小距离和强关联围长的交织器,并计算其最小汉明距离。码长K=1 504时,在不同编码码率条件下的参数取值如表1所示。

表1 ARP交织器在K=1 504时的交织参数
ARP和QPP交织器都是奇偶交织器,即输入位置为奇数的比特数据,交织后的输出位置仍为奇数。和传统交织器相比,其可以提供更大的最小距离。两种交织器在LTE系统竞争中,QPP交织器最后被选用,主要原因是在最大无争用条件下,QPP交织器适用于更多的并行度,具有完全代数的表示方式,同时需要更少的交织参数的存储。ARP交织器具备的优势:(1)具有更好的最小距离;(2)其解交织器同样是ARP交织器,而QPP的解交织器不一定是QPP。
为了更清晰地对比,以码长K=1 504为例,给出QPP交织器和ARP交织器交织前后的位置关系(见图3—4),其中,横轴为交织前的位置,纵轴为交织后的位置,此时,ARP交织器采用2/3码率条件下的参数。可以看出,QPP交织器和ARP交织器交织前后位置都均匀分布,交织性能较好。
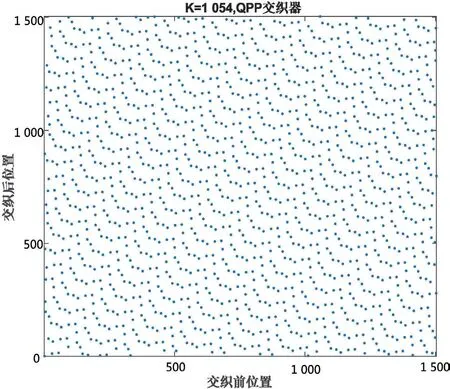
图3 QPP交织器前后位置关系图
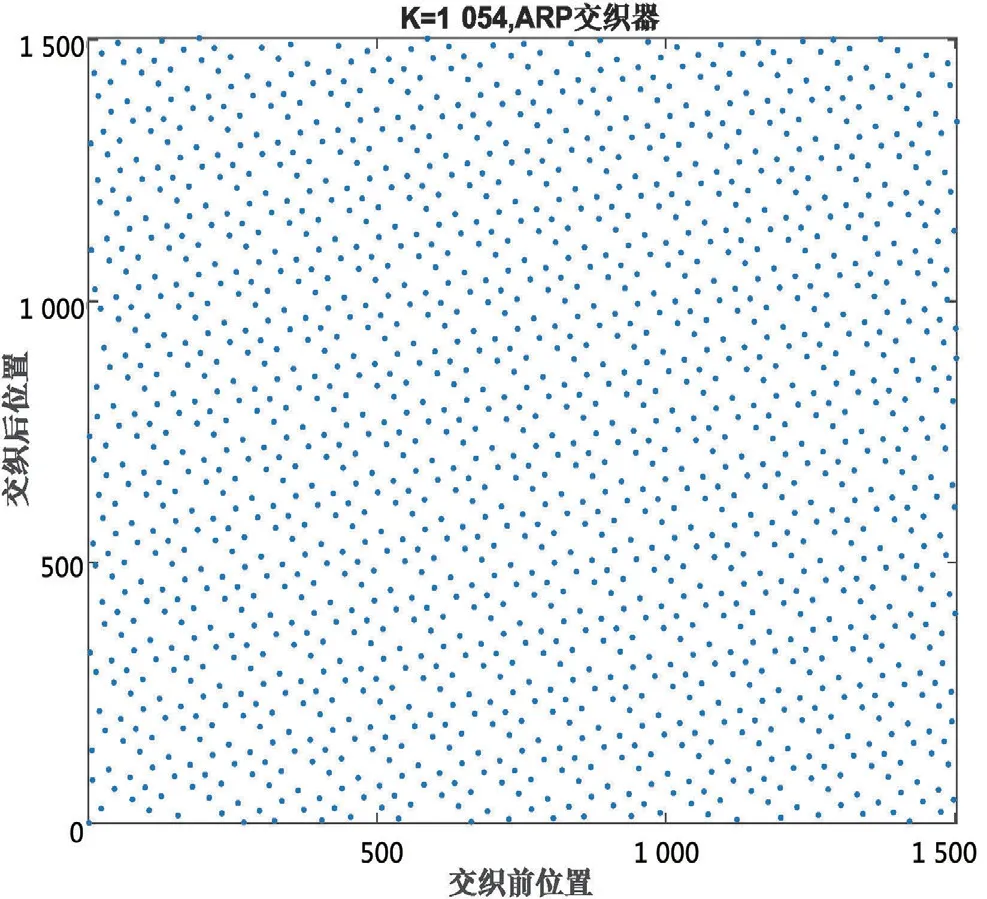
图4 ARP交织器前后位置 关系图
3 仿真对比
在AWGN信道、BPSK调制下进行Matlab仿真。为了便于对比,均采用LTE标准下的2/3码率的Turbo码(15/13)8,仿真码长K=1 504。此时,ARP交织器的交织公式为π(i)=[651⋅i+S(imod8)]modK,集合S的取值为{0,89,528,8 52,1501,1396,688,490}。为了实现2/3码率,编码后系统比特和校验比特分别按照01111110/11000001进行打孔操作,其中,0表示比特被删余,1表示比特被保留。
译码性能对比如图5所示,其中,BER表示误码率,Eb/N0为信噪比,仿真次数分别为10次、12次。仿真结果表明,在LTE标准2/3码率的情况下,采用特定的打孔方式,使用ARP交织器的FPTD算法性能好于使用QPP交织器的FPTD算法。迭代次数为10次、BER=10-5时,使用ARP交织器的FPTD算法性能比使用QPP交织器的FPTD算法要好约0.1 dB;迭代次数为12次、BER=10-5时,使用ARP交织器的FPTD算法性能比使用QPP交织器的FPTD算法要好0.2 dB左右。ARP交织器的应用,使得FPTD算法在性能上获得了提升。

图5 译码性能对比
4 结束语
本文首次将ARP交织器应用于Turbo码FPTD算法中,将ARP交织器与打孔方式进行联合设计,对FPTD算法的译码性能进行研究讨论。与QPP交织器进行仿真对比发现,使用ARP交织器的FPTD算法的译码性能获得了提升,能更好地适应不同的码率条件。但是,在将ARP交织器应用于FPTD算法时,需要将交织器与打孔方式进行联合设计,增加了设计难度和计算量,这一点需要研究改进。
