基于串联深度神经网络的Chl-a浓度短期预报方法研究
2021-09-09何恩业李尚鲁杨静季轩梁高姗王丹
何恩业,李尚鲁,杨静,季轩梁,高姗,王丹
(1.国家海洋环境预报中心自然资源部海洋灾害预报技术重点实验室,北京 100081;2.浙江省海洋监测预报中心,浙江杭州 310007)
1 引言
叶绿素a(Chl-a)作为一个生物量指标可以表征水体初级生产力状况,研究Chl-a的变化趋势对赤潮早期预警和海水富营养化潜势研究具有重要意义[1]。众多学者针对Chl-a含量的预报和研究开展了大量工作。预报方法有很多种,大体可以归纳为4类:(1)单要素指标预测法。如郭文景等[2]利用有滞后变量参与的格兰杰因果关系检验和向量自回归模型,分析了太湖水质参数对浮游植物生物量的影响;阮华杰等[3]对赤潮发生前后生态浮标各监测要素的变化进行分析,认为可以通过监测要素指标进行藻华预测。(2)传统统计学预测法。如金衍健等[4]利用舟山近岸水质监测数据建立了Chl-a多元线性回归方程;林祥[5]利用主成分线性回归分析方法建立了诏安湾Chl-a统计方程。(3)数值模拟方法。如杨德周等[6]基于POM(Princeton Ocean Model)模型模拟长江口Chl-a分布状况;崔玉洁[7]利用CE-QUAL-W2模型对三峡库区藻类水华生消过程进行模拟。(4)人工智能预测法。如张娣等[8]建立了自回归滑动平均-反向传播(AutoRegressive Moving Average-Back Propagation,ARMA-BP)模型对太湖藻类Chl-a浓度进行预测;石绥祥等[9]根据海洋各要素与Chl-a浓度之间的长短期依赖程度构建了长短期记忆网络(Long Short Term Memory network,LSTM)预测模型,预测精度大幅提高。
由于Chl-a变化成因复杂,其与环境因子之间模糊和不确定性的高度非线性关系,造成传统统计方法预测效果较差,而数值模拟对具体站点Chl-a含量预测的精确度不高,难以应用于预报实践。随着计算机技术的飞速发展,神经网络模型的智能预报方法逐渐体现出独特的优势。神经网络是一种对人脑结构和功能进行模拟的数学模型,它是由大量且互相连接的处理单元组成的复杂系统,具有分布式存储和处理以及自组织自学习的能力,特别适合处理因素众多、机制不明晰和信息缺失的复杂问题[10]。神经网络诞生至今主要经历了感知器、浅层学习和深度学习3个阶段。Taylor等[11]研究发现大脑具有逐层处理信息的能力;人工智能之父Hinton等[12]提出具有多层次的深度神经网络(Deep Neural Networks,DNN)更易从低层信息提取高层语义特征。但是由于DNN参数众多,造成模型运算效率较低,甚至难以收敛于全局最优,陈旭伟等[13]提出了一种串联BP神经网络结构,不但可以减少模型参数,实现对多个非线性函数的拟合,还可以实现特征信息逐级提取和传递,在实验中取得了较大成功。Sutskever等[14]针对DNN容易陷入局部最小的缺陷提出了优化调整方案。这些研究成果极大地促进了深度学习的长足发展。近几年来,基于深度学习智能模型,如卷积神经网络(Convolutional Neural Network,CNN)、循环神经网络(Recurrent Neural Network,RNN)和DNN的各种研究应用已逐渐成为最热门的课题。但是当前针对Chl-a浓度预报的智能模型大都以浅层学习为主,鲜有将深度学习应用于预报研究之中。本文以浙江海洋保护区生态浮标监测数据为依据,建立了一种串联式DNN的Chl-a短期预报模型,并针对预报结果进行了检验。
2 数据来源和研究方法
2.1 数据来源
本文采用2019年5月浙江省海洋保护区3个生态浮标NB03、TZ01和WZ02的连续监测资料作为样本数据进行建模分析(见图1)。浮标监测数据主要由浙江省近岸海域浮标实时监测系统省级数字化监控平台提供。海上浮标系统由浮体、标架、供电设备、防护设备、锚系、传感器和数据采集传输等部分组成。浮体上加载的水质多参数传感器(置于水面以下0.5~0.8 m处)可获取间隔1 h的水温、盐度、pH、溶解氧及其饱和度、Chl-a浓度、浊度和电导率等常规水质参数数据,以及间隔4 h的氨氮、硝酸盐氮、亚硝酸盐氮和磷酸盐等数据。海上浮标系统每月1次例行维护,不定期开展应急维护,保证浮标系统运行稳定性,定期开展人工采样比对监测,确保监测数据质量。

图1 2019年5月浙江沿海生态浮标位置()和赤潮发生时间及中心位置()
2.2 基于DNN的Chl-a短期预报模型构建方法
DNN是具有多个隐层的神经网络,层与层之间采用全连接的结构,隐层中的任一神经元与前后层任一神经元相连。DNN具有优异的特征学习能力,对复杂函数的逼近能力极强,具有能够从少量样本集合中挖掘高阶本质特征的优势[12]。在DNN架构研究方面,Wang等[15]基于两阶段深度学习的综合推荐框架,利用潜因子向量作为深度学习推荐模型的输入,不仅捕捉到高阶交互特征,而且减轻了隐层的负担,避免了模型训练陷入局部最优。结果表明串联结构的DNN在预测精度、参数空间和训练速度等方面都体现出更好的性能。本文采用5层神经网络为基本单元,以串联方式构建了24 h和48 h的Chl-a浓度预报模型。
“你怎么能干这样的事?”关小美哭着责备郭启明。郭启明说:“还不是被你爸爸逼的?我真的是不知道怎么办才好才会这样……那些钱我一分也没敢拿。”关小美说:“赶快去自首吧……”郭启明摇头:“抢银行是重罪,我还捅了人,弄不好要被判死刑。我先回老家看看老人再说……”“要走我们一起走,我要陪着你。”糊涂的关小美在惊慌中也跟着郭启明踏上了逃亡之路。两人从后门匆匆逃出,来到长途汽车站,准备逃往西安。路上,关小美还接到关云飞的电话,问她交了房款没有。关小美哭着说:“爸爸,闯大祸了,郭启明抢银行了……”说完,她就关了手机。
2.2.1 子神经网络
损失函数的值即为网络模型误差,若其值达不到目标值ε(期望损失),则进行误差反馈,对网络耦合权值按照损失函数负梯度方向从输出层至输入层进行全局调整,调整量为:

图2 具有5层结构的DNN

其一阶导数函数为:f'(x)=f(x)⋅(1-f(x))。设wij为任意两个神经元之间的耦合权值,g为神经元的输入,h为神经元的输出,则有:

输入层按照实验方案设置输入节点数(变量x或者变量x与干扰变量的组合),3个隐层均配置10个神经元节点,输出层为预测变量y,模型损失函数目标值为3×10-4,4套测试实验方案为:
平房第十栋附近,有一间厕所。生活区最大的厕所,你应该还记得那间厕所。和厕所相连,有一间小房子大约五平米,清洁工放桶子,扫把用的工具房。
2.2.2 模型损失函数和参数的优化调整方案
48 h预报方案:在24 h预报因子基础上加入T24h时刻Chl-a预报值作为48 h预报因子,对T48h时刻的Chl-a浓度进行预测。
设DNN模型期望输出为T=(t1,t2,…,tm)T,共有α个仿真训练样本,第p个样本输入模型后的输出方差为,α个样本输入模型后的输出总方差为,定义模型损失函数为:

具有5层结构的子神经网络模型包含1个输入层、3个隐层和1个输出层(见图2)。输入层有n0个变量输入节点,隐层分别有n1、n2和n3个神经元节点,输出层有m个神经元节点。前后层节点之间通过耦合权值矩阵进行全连接,上一层神经元的输出作为下一层神经元的输入,神经元采用单极性Sigmoid激活函数处理信息,在输出层采用线性方式输出预测变量。Sigmoid激活函数为:

式中,η为学习率,大取值可以加快学习速度,但易导致wij调整量过大造成模型震荡难以收敛,小取值会导致模型运算时间加长,效率变差。本文对算法进行了优化,采用可变学习率,网络每迭代100次η乘以系数0.98,且设置η最小值为0.01以保证学习速度,优化后的网络模型可以在初期采用较大的学习率加快收敛速度,在后期以较小的学习率解决参数调整过大产生的模型震荡难题。此外,为了进一步提高模型运算效率和稳定性,本研究引入可变动量项mcΔw,其作用在于记忆上一次wij的调整方向,mc为动量系数,若本次调整与上次调整方向一致,增大为1.1×mc,加快收敛速度;若调整方向相反网络产生了震荡,则减小为0.9×mc,起到平滑作用。设n为迭代次数(调整次数),经过优化后各层之间的耦合权值调整公式可表达为:

2.2.3 Chl-a短期预报模型结构和参数设置
本文采用前后串联的方式将两个5层结构的神经网络进行桥接建立了一个DNN(见图3),该网络拥有1个前端输入层、1个中间桥接层、6个隐含层和1个终端输出层。该模型将24 h预报日期前2 d的生态浮标Chl-a敏感性理化因子作为自变量进行信息输入,前一个子神经网络输出未来24 h Chl-a浓度预报结果,并将该结果作为后一个子神经网络的输入参与运算,模型终端输出未来48 h Chl-a浓度预报量结果。
Cite this article as:HAN Xue-Ying, WANG Ya-Nan, DOU De-Qiang. Regulatory effects of Poria on substance and energy metabolism in cold-deficiency syndrome compared with heat-deficiency syndrome in rats [J]. Chin J Nat Med, 2018, 16(12): 936-945.

图3 基于串联DNN的Chl-a短期预报模型结构设计
模型设置所有耦合权值wij的初值为随机小量,以保证单极性Sigmoid激活函数处于灵敏区间,加快调整速度。设置初始学习率η为0.2,初始动量系数mc为0.8。
中共十一届三中全会的召开是提出宪法适应性问题的时间节点,改革开放政策的确立和法治发展,是宪法适应性问题产生的主要推手。改革凸显“变”,宪法贵在“稳”,而宪法修改作为最重要的宪法适应机制,既为宪法保持先进性提供了途径,又凸显出其不足,宪法为适应社会急剧变革,开始呈现出妥协性特征,发展方向也有所偏离。
3 结果与分析
3.1 DNN模型验证
不同的数据预处理方法会导致模型预测结果差距较大[10]。本文利用目标函数y=x3评价几种不同样本处理方法对网络模型预测效果产生的差异,设计了4套实验方案对子神经网络模型的相关特性进行测试验证,根据测试结果优劣为后续Chl-a短期预报模型提供最优样本数据处理方式。目标函数y=x3的样本选取见表1,(xp,yp)表示样本对,p为样本序号,自变量x取值间隔为0.1。自变量方面额外增加了3个随机干扰变量(ν1、ν2和ν3),共选取36条样本。

表l目标函数y=x3测试样本集合
式中,θ为偏置量,表示神经元的阈值。
方案a:所有样本按照顺序排列,自变量x不加入干扰变量,取前30个作为仿真训练集,剩余后6个作为预测检验样本集,测试模型对未涉猎知识领域的预测效果。
方案b:打乱样本集顺序作类间交叉处理,自变量x不加入干扰变量,随机取6个样本进行预测检验,其他30个样本作为仿真训练集,测试样本类间均衡对模型预测效果产生的作用。
为让易地搬迁对象“搬得出,稳得住,有事做,能致富”,争取到2018年所有搬迁对象全面脱贫,湖南省汝城县三措并举,不断强化监管力度,确保了全县易地扶贫搬迁工作的顺利推进。截至10月31日,全县所有集中安置点的搬迁对象均已分房到户。
方案c:在方案b的基础上,对自变量x加入3个随机干扰变量v1、v2和v3,测试神经网络模型容错能力和剔除噪音的能力。
方案d:在方案c的基础上大幅减少仿真训练样本至20个,预测检验样本不变,测试学习样本多寡对预测效果的影响程度。
方案a实验结果显示(见图4a),由于仿真训练集未包含自变量x的所有区间,模型丧失了对后部区间学习的机会,系统学习不完整,对于未涉猎的知识处理缺乏经验,导致预测效果不理想。预测检验显示,给定自变量x值,其值偏离训练集样本区间越远,则对因变量y的预测能力就会变得越差。
方案b实验结果显示(见图4b),样本集合进行了类间交叉处理后,仿真训练样本基本包含了所有自变量区间,模型学习信息较为系统,因此在预测检验时,随机给定自变量x,模型能够根据仿真训练建立的知识库对变量y做出较准确的预测,效果提升明显。
林业作为我国的重要资源,在我国的经济建设和发展中发挥着重要作用。林区的造林改造正在继续进行。然而,在长期的改革过程中,除了上述造林成本不足和造林方法的不足之外,不可避免地会遇到一些困难。除了林区经营管理不善外,树种结构比例失衡、地方资源利用不合理、分类不清等问题也不容忽视。此外,近年来我国沙尘暴、干旱、暴雨、水土流失等气候灾害的频繁发生,对更新造林工作产生了很大影响,这就要求我们从提高更新造林的成本、改善更新造林入手。加强林区管理,分类经营,加强育苗、育苗、灌浆。为了促进林业的可持续发展,应充分利用当地环境和资源的优势,合理利用资源,丰富知识,创新技术,转变观念。
方案c实验结果显示(见图4c),虽然在自变量信息中随机加入了v1、v2和v3等干扰变量,但是DNN经过自学习能够有效的剔除噪音信号,对关键信息提取效果较好。对比来看,预测效果好于方案a,相较于方案b的预测误差略有增大。该实验结果表明DNN特别适合对变量之间映射关系模糊不清或充满各种干扰噪音的复杂问题进行建模研究。
方案d实验结果显示(见图4d),减少训练样本后,模型整体预测误差稍有增大,较大误差主要分布在仿真训练集中学习类别较少的区间,对于学习样本密集度较高的区域,模型对于预测的能力仍然较强。该实验结果表明即使仿真训练样本较少,但只要做到样本类间均衡,仍能有效减小预报误差。

图4 不同方案DNN对目标函数模拟和预测结果比较
表2为4种实验方案的仿真训练和预测结果的均方根误差(Root Mean Square Error,RMSE)和平均绝对误差(Mean Absolute Error,MAE)的对比,4种方案模型的仿真RMSE差别较小,说明DNN对任何训练样本都能做到较高的拟合精度。但是从预测检验来看,4种方案表现出了明显的差距,即使没有加入干扰变量,方案a的预测效果仍然最差,表明样本类间均衡对于模型最终执行效果起到最为关键性的作用。虽然方案b最优,但是在解决实际问题方面,变量之间的映射关系并不清晰,很难准确界定因变量是由哪种或哪几种自变量引发,所以方案c和d成了现实中最多的选择。

表2 各实验方案的DNN模型误差对比
针对方案c和d变量过多导致的模型参数增加、学习缓慢和预测效果变差的问题,国内外众多学者也提出了多种解决方案,如利用相关性分析法、聚类算法和小波分析法等对模型输入信息进行降维去噪和特征提取,DNN的预测准确率得到了较大提高[16-18]。本文选用Pearson法筛选Chl-a含量相关的敏感性因子作为模型的自变量输入信息。
3.2 基于DNN的Chl-a短期预报模型仿真和预测结果分析
3.2.1 原始数据处理和相关性分析
由于原始数据存在大量的噪音、冗余和不完整的信息,所以在输入模型之前需要进行清洗以达到改进数据质量的目的[19-20]。本文采用如下方案对生态浮标原始数据进行处理。
对于异常值的剔除采用3σ准则:

式中,x表示观测要素变量;σ、μ分别为标准差和均值,观测要素值超出区间[(μ-3σ),(μ+3σ)]的离群点只占0.3%,以异常值处理。对于缺失值采用五点等权滑动平均滤波法(Moving Average)进行插值填充:
5)AR技术运用范围广阔,军事、销售、娱乐、教育、技术、传媒、旅游、医疗等八个领域,都是AR增强现实的发展方向。

式中,fk为5个相邻数据yk-2、yk-1、yk、yk+1和yk+2的平滑数据,yk为等效监测数据。
根据以上内容分析可以看出,以后现代理论为基础的后现代图书馆学对马克思主义的现实理论批评提出了严峻的挑战。后现代图书馆学对中心论的解构促使马克思主义思想权威受到很大影响。后现代图书馆学所主张的反本质、反基础、反中心的观点与马克思主义的基本原则大相径庭。另外,后现代图书馆学所提倡的差异性方法论也对马克思主义理论关于政治、经济及阶级的划分提出了质疑。可以说,在分析和解释后现代图书馆学的理论根据时,传统的马克思主义面临着诸多问题。然而作为新马克思主义,并没有左派思想那样悲观失望的情绪,而是自觉承担起维护马克思主义的历史责任,同时也为后现代图书馆学提供了科学的理论批评工具。
由于各要素监测频率不一致以及部分监测要素值变化剧烈,其瞬时值与其他要素的步调性并不好。为了利于后续分析和应用,我们对各要素进行日平均处理,共形成93条记录(见图5)。Chl-a浓度的变化直接表征浮游植物数量变动状况,例如:2019年5月9日在生态浮标WZ02海域发现以东海原甲藻为优势种的赤潮,2019年5月15日在生态浮标NB03毗邻水域发现以东海原甲藻和夜光藻等为优势种的赤潮。图5显示出WZ02和NB03浮标的Chl-a浓度监测值分别在赤潮发生日期有较明显的大幅度上升,而未有赤潮发生海域的TZ01浮标处Chl-a变化较为平稳,波动不大。3个浮标监测数据既包括赤潮发生前后各理化要素的连续记录,同时也涵盖了正常水体Chl-a含量变化的连续记录,具有明显的样本均衡特性,特别适合神经网络建模样本数据。
本文主要介绍了利用java爬虫技术的票务查询系统的开发,从需求分析、相关技术分析、框架搭建、具体设计等几个方面进行了介绍,并且对使用的技术进行了详细的分析与解释。本次开发有以下几个技术要点:
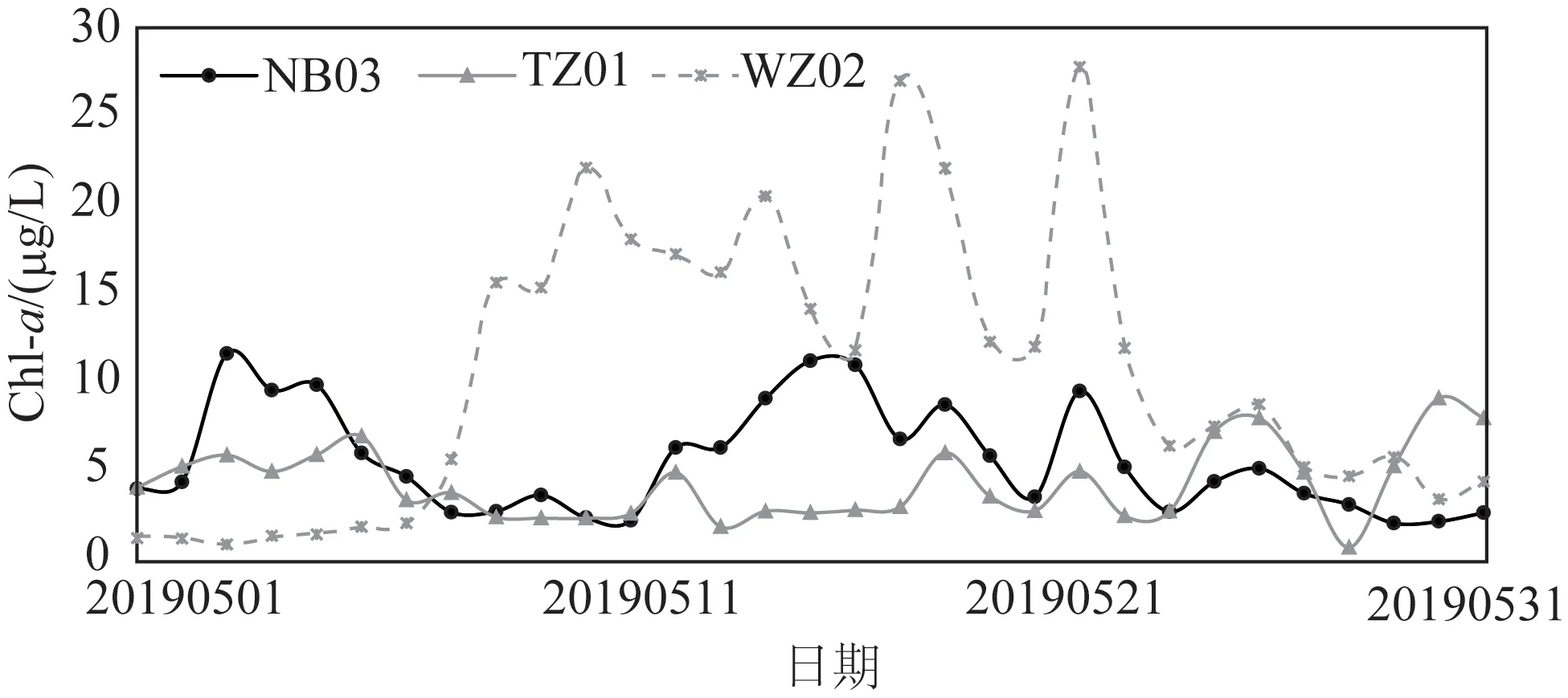
图5 2019年5月浙江海洋保护区各生态浮标Chl-a浓度日变化
采用与Chl-a浓度变化具有显著相关性的环境因子作为预报因子,Chl-a浓度作为预测变量,两者分别作为模型的输入和输出信息在进入学习之前进行类间交叉处理。一般要求预测检验样本占总体样本的10%左右[10],因此本文随机预留10个样本作为预测检验集,剩余样本做仿真训练集。
本文采用Fortran软件进行数学建模与编程,利用SPSS和Excel软件分别进行统计学分析和绘图。

利用IBM SPSS Statistics21进行相关性分析,结果见表3。分析发现研究海域T0h时刻Chl-a浓度与T-24h和T-48h(-24 h、-48 h表示0 h时刻前1 d和前2 d)时刻溶解氧浓度、pH值和Chl-a浓度在P=0.01水平上均呈现显著性正相关,且时间越接近相关性越强,说明Chl-a浓度变化与这3种要素的变化具有较好的同步性;T0h时刻Chl-a浓度与T-24h和T-48h时刻的硝氮和磷酸盐在P=0.05水平上均呈现显著的负相关,且过去2 d的相关性整体高于当天,说明营养盐对浮游植物生长的影响具有滞后性效应;Chl-a浓度与其他水质和营养盐要素在5月的相关性不大。相关性分析结果表明,监测样本偏赤潮发生初期,处于藻类密度不大、爆发性增殖前或开端时期,藻类生物量繁殖增长时吸收表层CO2释放氧气,而营养盐无机态也处于被消耗状态,氮和磷成为浮游植物生长的关键性限制因子[22-23]。所以,建立的模型更适用于赤潮早期或将发生期的预测。

表3 T 0h时刻Chl-a与不同时刻理化因子的相关性
3.2.2 模型仿真和预测结果分析
相关性分析是机器学习样本数据预处理的核心工具,本文采用Pearson相关法分析Chl-a与各环境因子的相关关系,以此衡量各要素变动的一致程度,为预测模型的输入信息筛选敏感性因子。Pearson相关法不但可以做到数据降维、减小模型参数提高学习速度,还可以有效改善预测效果,提高预测准确率[21]。Pearson相关系数公式为:
24 h预报方案:选取T-24h和T0h时刻的溶解氧、pH、硝氮、磷酸盐和Chl-a作为预报因子,对T24h时刻的Chl-a浓度进行预测;
本文以船舶应用需求为根本出发点,提出船舶分布式数据网络管理平台,根据智能船舶系统的固有特点进行针对性研究。该平台不仅能弥补传统数据管理平台的缺陷,而且具有全面感知、可靠传递和智能应用的优势,应用于远洋船舶运输管理中,可建立集航运企业各部门和远洋船舶于一体的安全监控平台。此外,船舶分布式数据网络平台可大大提高船岸定时交互数据和协作管理业务的效率,增强远洋船舶物资运输、航行、机务系统和油耗监测管理等方面的安全性、可靠性和高效性,为船舶智能管理业务和应用提供有力的数据支撑。
变量之间由于量纲和数值大小不同,各度量之间的特征很难具有可比性,同时对目标函数影响权重也不一致。为了消除这些影响,本文对输入变量统一进行标准归一化处理:
小草,没有牡丹花的绚丽多彩,没有月季花的亭亭玉立,没有菊花的婀娜多姿……但它的足迹踏遍了整个世界,无论是城市,还是农村,都能找到它的踪迹。一层层、一批批的小草,没有索求,只有奉献,它们争先恐后地用那顽强的生命力,编织成一望无际的绿,染遍了平原、染遍了山川……
工作人员选取了刘磊家的1亩路边田为试验示范地,使用云天化复合肥14-8-20,示范田周围田地使用其他品牌复合肥15-15-15,面积为1亩,并均根据农户常年种植习惯与用肥习惯进行相同施肥与管理。观测棉花的长势和产量,同时与对比田进行对照。

式中,σ为变量标准偏差,yi和zi分别为变量xi标准化和归一化数值。经过处理后所有变量处于同等地位,也符合神经网络Sigmoid激活函数定义域的要求。
网络神经元节点数设置过少会造成信息的挖掘能力不足,设置过多又因为出现过拟合现象,即将原始数据的噪音转变为特征信号,而造成预测误差偏大[24]。通过对隐层神经元节点不同设置的实验可知(见表4),前一子网络结构为10-9-9-9-1,后一子网络结构为11-6-6-6-1时,模型预测效果最优,24 h Chl-a浓度预报RMSE达到最小值1.25μg/L,MAE为1.03μg/L,48 h预报RMSE达到最小值2.43μg/L,MAE为1.99μg/L。
四是狠抓任务落实,强化督导检查。省政府与各试点市签订责任书,明确了地下水超采综合治理的时间表、路线图。各市也将任务进一步细化分解到各县,落实到项目和具体责任人。加强对试点项目的监管,严格财经纪律,严格工程监督检查。各试点市县确保资金专款专用,确保工程质量,确保施工安全,真正把地下水超采综合治理工作打造成经得起历史检验的优质工程、群众满意的民生工程、阳光透明的廉洁工程。

表4 不同节点设置的DNN模型预测效果对比
此外,实验过程中发现,虽然DNN能够对仿真训练集进行任意精度的拟合,但是过于拟合会将原始数据中的噪音转变为网络学习特征,导致模型测试集预测精度降低(泛化效果变差)。本研究中当目标损失值(训练集拟合误差RMSE)为0.5~1.0μg/L时,测试集的损失较小,预测效果达到较高的精度(见图6)。

图6 串联DNN模型的Chl-a浓度仿真训练和预测结果
为了对比深层学习与浅层学习在预测效果上的差异,本文构建了经典的单一隐层BP神经网络模型。经过同样方法进行测试,BP模型的前一子网络结构为10-8-1,后一子网络结构为11-11-1时,模型预测效果最优,24 h Chl-a预报RMSE达到最小值1.78μg/L,MAE为1.42μg/L,48 h预报RMSE达到最小值3.09μg/L,MAE为2.20μg/L(见表5)。

表5 浅层ANN与深层DNN模型对Chl-a浓度的预测结果对比(单位:μg/L)
对比显示,深层DNN相比浅层人工神经网络(Artificial Neural Network,ANN),24 h Chl-a预报的RMSE减小了0.53μg/L,MAE减小了0.39μg/L;48 h Chl-a预报的RMSE减小了0.66μg/L,MAE减小了0.21μg/L,一定程度上反映了深度学习在挖掘高阶特征上比浅层学习更具有优势。另一方面,无论是深层DNN还是浅层ANN,48 h预报的RMSE比24 h的RMSE大幅增加,深层DNN增加了1.18μg/L,浅层ANN增加了1.31μg/L,显示出神经网络对于临近预报更有优势,随着时间跨度的加大不确定因素也会增加。该模型未将气象和水动力等对Chl-a含量产生重要影响的因素加入考虑,一定程度上也降低了模型在较长时间预测方面的精度。
4 结论
本文尝试建立一种串联DNN的Chl-a短期预报模型,通过对目标函数的测试验证了DNN的相关特性,利用浙江海洋保护区生态浮标数据对Chl-a浓度进行了仿真和预报实验。结果表明:
(1)对训练样本进行类间均衡处理比单纯增加样本数量更为有效,且具有更好的预测效果。采用传统统计方法对输入信息进行去噪和降维预处理,有利于提升预测精度。
(2)2019年5月浙江海洋保护区生态浮标水质和营养盐要素相关性分析结果显示,T0h时刻的Chl-a与T-24h和T-48h时刻的溶解氧、pH和Chl-a在P=0.01水平上均有明显的正相关,与T-24h和T-48h时刻的硝氮和磷酸盐在P=0.05水平上均有明显的负相关,氮和磷是浮游植物生长的关键性限制因子。
(3)本文所建立的串联DNN Chl-a浓度短期预报模型24 h预报的RMSE为1.25μg/L,MAE为1.03μg/L,48 h预报的RMSE为2.43μg/L,MAE为1.99μg/L,预报精度比浅层学习提升明显,体现了深度学习从原始数据中挖掘高阶语义特征的优势。该方法不但可以减少模型参数,实现对多个非线性函数的拟合,还可以实现特征信息的逐级提取和传递,具有一定的通用性和可移植性。
本研究只考虑了水质和营养盐要素对Chl-a浓度变化的影响,实际上淡水输入、环流形势和上升流等水动力因子以及气温、光照和风等气象因子都会对Chl-a浓度产生重要影响,如果将这些影响因子一并考虑无疑会提高预测的精度,这也是未来进一步研究需要开展的工作[25-28]。此外,DNN虽然具有很强的仿真和预测性能,但是网络不同的参数设置也会对结果产生不同影响,如模型大小、结构和训练细节等设置目前没有统一的标准,仍需要不断优化[29]。总之,随着人工智能技术的不断完善和发展,基于深度学习的Chl-a预报模型将具有广阔的应用前景。
