基于改进的BERT-CNN模型的新闻文本分类研究
2021-09-08张小为邵剑飞
张小为,邵剑飞
(昆明理工大学 信息工程与自动化学院,云南 昆明 650031)
0 引 言
互联网上的数字文本日益增多,从应用程序到拥有数百万数据的网站,都存在大量计算机难以甄别的文本数据。由于数据量大且文本语义错综复杂,导致文本分类成为一项难题。因此,如何使计算机对大量文本数据进行分类,正成为研究者感兴趣的话题。一般来说,文本分类任务只有很少的类。当分类任务有大量的类时,传统的循环神经网络(Rerrent Neural Network,RNN)[1](如 LSTM 和GRU)算法准确率表现不佳,因此本文引用谷歌大脑发布的基于transformer的来自变换器的双向编码器表征量(Bidirectional Encoder Representations from Transformers,BERT)[2]模型来对中文新闻文本进行分类,数据集采用新浪新闻RSS订阅频道2005年至2011年间的历史数据筛选过滤生成的THUCNews中文文本分类数据集,共有金融、房产、股票、教育、科技、社会、时政、体育、游戏及娱乐10个类别。
1 相关研究
深度神经网络由于其强大的表达能力和较少的实用技术要求,正成为文本分类的常用任务。尽管神经文本识别模型很有吸引力,但在许多应用中,神经文本识别模型缺乏训练数据。近年来,人们提出了多种中文文本分类方法。由于中文文本本身的特点,与英语等其他语言相比,中文文本分类比较困难。为了提高中文文本分类的质量,Liu等人[3]提出了一种分层模型结构,可以从中文文本中按顺序提取上下文和信息,这种方法是LSTM和时间卷积网络的组合。而LSTM用于提取文档的上下文和序列特征。Shao等人[4]提出了一种大规模多标签文本分类的新方法。首先将文本转换为图形结构,然后使用注意机制来表示文本的全部功能。他们还使用卷积神经网络进行特征提取。与最新的方法相比,该方法显示了良好的结果,并且使用了4个数据集进行实验。在CRTEXT数据集上进行的结果表明,与其他数据集相比,他们的模型取得了最好的结果。本文利用BERT自注意力的优点,将BERT当做embedding[5]层接入到其他主流模型,并在同一个新闻数据集进行训练和验证。最后将各个模型与BERT拼接的模型进行比较。
2 研究方法
2.1 BERT
2.1.1 BERT的基础架构
BERT使用的是transformer的encoder的部分,是由多个encoder堆叠在一起的。6个encoder组成编码端,6个decoder组成解码端。一个encoder具有输入、注意力机制以及前馈神经网络3个部分。BERT的基础结构如图1所示。

图1 BERT的基础结构
BERT编码器需要一个token序列。处理和转换token的过程如图2所示。[CLS]是插入在第一句开头的特殊标记。[SEP]插入在每个句子的末尾。通过添加“A”或“B”区分句子来创建embedding。另一方面,还在序列中添加每个标记的位置来进行位置嵌入。
图2中,3个embedding的总和就是BERT编码器的最终输入。当一个输入序列输入到BERT时,它会一直向上移动堆栈。在每一个块中,它会首先通过一个自我注意层再到一个前馈神经网络之后再被传递到下一个编码器。最后,每个位置将输出一个大小为hidden_size(BERT_Base=768)的向量。
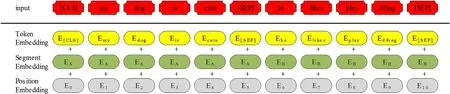
图2 token转换过程
2.1.2 掩码语言模型(Masked Language Model,MLM)
在新闻文本序列中,通过标记[MASK]来替换它们随机屏蔽一定百分比的单词。在本文中屏蔽了15%的输入词,然后训练剩下的输入词,最后让解码器来预测被屏蔽的输入词。例如:
调查显示:29.5%的人不满意当年所选高考专业
调查显示:29.5%的人不满意当年所选[MASK]专业
这里的一个问题是预训练模型将会有15%的掩码标记,但是当微调预训练模型并传递输入时,不会传递掩码标记。为了解决这个问题,将用于屏蔽的15%的token中的80%替换为token[MASK],然后将10%的时间token替换为随机token,其余的保持不变。
由于BERT在预训练的时候使用的是大量无标注的语料,因此要使用无监督(无标签)的方法,本文采用的无监督目标函数是AE自编码模型。它可以从损坏的输入数据进行预测并重建原始数据,也就是利用上下文信息的特点来进行重组。另外一种无监督目标函数是AR自回归模型。下面从一个句子(我喜欢小狗)来比较两种无监督模型。
AR:

由式(1)可知,AR自回归模型只用到了文本的单侧信息,且依赖于两个相邻词的依赖关系。
AE:

由式(2)可知,AE用mask掩盖掉某些词,优化目标是:在“我mask小狗”的条件下出现“我喜欢小狗”的概率,而这个概率等于在“我小狗”的条件下,mask=“喜欢”的概率,据此预测出mask的词。对比AR自回归模型,AE自编码模型的优点很明显:充分利用了上下文词与词的关系而不依赖于相邻的两个词的关系。因此本文BERT采用AE自编码模型。
2.1.3 NSP(下一个句子预测)
在BERT训练过程中,模型接收成对的句子作为输入,并学习预测成对中的第二个句子是否是原始文档中的后续句子。在训练期间,50%的输入是一对,其中第二个句子是原始文档中的后续句子,而另外50%的输入是从语料库中随机选择的一个句子作为第二个句子。为了帮助模型区分训练中的两个句子(正样本和负样本),输入在进入模型之前先按以下方式处理。
(1)在第一个句子的开头插入一个[CLS]标记,在每个句子的末尾插入一个[SEP]标记。
(2)将表示句子A或句子B的sentenceembedding添加到每个token中。
(3)将Positional embedding[6]添加到每个embedding以表示其在序列中的位置。
为了预测第二个句子是否确实与第一个句子相关联,按照以下步骤进行预测。
(1)整个输入序列经过Transformer模型。
(2)[CLS]标记的输出使用简单的分类层(权重和偏差的学习矩阵)转换为2×1形状的向量。
(3)用softmax[7]计算IsNextSequence的概率。
在训练BERT模型时,MLM和NSP是一起训练的,目标是最小化两种策略的组合损失函数。
2.2 TextCNN
CNN首次被提出是被用在图像处理上的,而后YoonKim提出的用于句子分类的卷积神经网络使得其对于句子分类更加有效。TextCNN[8]模型主要使用一维的卷积核以及时序最大池化层。如果输入的新闻文本序列由k个词组成,而每个词的词向量为n维,那么输入的样本宽度等于输入的句子序列词个数k,高为1,输入的通道数等于每个词的词向量n。以下是TextCNN的主要计算步骤。
(1)先定义多个一维的卷积核,再通过这些卷积核对输入分别进行卷积计算。不同宽度的卷积核会得到个数不同的相邻词之间的相关性[9]。
(2)对所有输出部分的通道一一进行时序最大池化操作,再将池化后的结果连接为向量。
(3)使用全连接层将第2步连接好的向量变换为有关各个标签(本文使用的数据集标签一共有10个)的输出。为了防止出现过拟合,本文还在这一步骤使用了丢弃层[10]。
下面用一个例子解释TextCNN的原理。采用本文所用的数据集中的一个样本:“某公司收费遭投诉引关注,用户抱怨账单不明”,分词结果为“某公司收费遭投诉引关注用户抱怨账单不明”,词数为11,每个词的词向量设置为6。因此输入的序列宽度为11,输出的通道数为6。然后设置2个一维的卷积核,卷积核尺寸为2*4,设置输出通道分别为5和4。因此,经过一维卷积核计算后,5个输出通道的宽为11-4+1=8,4个输出通道的宽为11-2+1=10。接着对各个通道进行时序最大池化操作,并将9个池化后的输出连接成一个9维的向量。最后,通过全连接层将9维向量转化为10维输出,也就是新闻文本类别的标签个数。具体过程如图3所示。
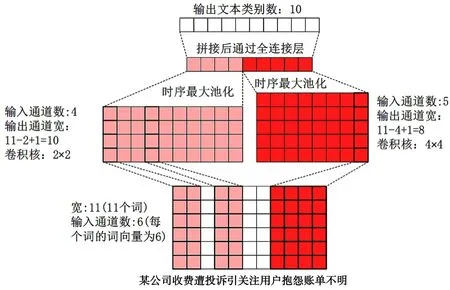
图3 TextCNN原理
3 实验与结果
3.1 实验数据集
在监督学习中,模型的性能主要依赖于数据集。神经网络的学习也依赖于数据集,如果数据集的数量较少,学习就会不足。为了为模型训练和模型结果评估提供合适的数据集,本文使用一个名为THUCNews的大型新闻语料库。这个数据集主要爬取2005-2011年间新浪新闻的RSS订阅频道新闻标题,一共有74万篇新闻文档(2.19 GB),均为UTF-8纯文本格式。该语料库已在Github上公开。本文主要抽取其中的20万条新闻标题,一共有10个类别:金融、房产、股票、教育、科技、社会、时政、体育、游戏及娱乐。每个类别有2万条,平均文本字符长度为20~30。采用其中的18万条作为训练集,1万条用来做验证集,剩下的1万条做测试集。
3.2 实验环境设置
本实验采用的计算机处理器为AMD R5 3600六核十二线程CPU,显卡为NVIDIA GTX 1060(6 GB),基于python3.8,深度学习框架主要用的是pytorch1.9.0+cu102 GPU版本,运行内存16 GB。由于显存容量限制,batch_size设置为16,Epoch设置为3。编程软件使用的是pycharm社区版。
本次实验采用的是BERT在Github的公开开源版本,并通过新闻数据集的特点微调BERT,以提升BERT的下游任务的效果。然后将BERT作为embedding输入到CNN、RNN模型,最后进行BERT、BERT-CNN、BERT-RNN的效果对比。
3.3 评价指标
为了评估各个模型的性能,本实验使用“提前停止(earlystopping)”技术(一旦训练效果停止改善,立即自动停止训练过程),这可以更好地避免过拟合问题。主要采用3种常用的评估指标:Precision精准率、Recall召回率以及F1。最后使用测试准确率Test_accuracy进行比较。3种指标的计算方法为:

式中:TP表示预测10个标签(0~9)当中的指定标签被正确预测的个数;FP表示预测为指定标签但实际上是其他标签的个数;FN表示预测为其他标签但实际上是指定标签的个数。
3.4 实验结果与分析
3.4.1 实验结果
BERT、BERT-CNN、BERT-RNN的试验结果分别如表1、表2及表3所示。平均Test_accuracy实验结果如表4所示。3个模型在1万条测试数据中的表现如图4所示。

图4 3个模型在1万条测试数据中的表现

表1 BERT实验结果

表2 BERT-CNN实验结果

表3 BERT-RNN实验结果

表4 平均Test_accuracy实验结果
3.4.2 结果分析
从表1、2、3可以得出:识别的标签不同,各个模型的评价体系得分也不同。10个标签共30个评分项,BERT-CNN一共有17个得分最高项,BERT有8个得分最高项,BERT-RNN有5个得分最高项。其中,BERT-CNN所有标签平均得分为0.941,BERT所有标签平均得分为0.938,BERT-RNN所有标签平均得分为0.936。可见BERT-CNN表现最佳。
从表4和图4可以看出,BERT-CNN无论是在平均测试准确率还是测试准确率的表现都要优于BERT和BERT-RNN。
实验结果证明,本文提出的基于改进的BERTCNN模型在新闻文本测试的表现,测试精度94.06%比原来的BERT模型高出了0.31%,且更为稳定。
4 结 语
本文的模型主要运用于文本的多分类场景中,未来可以尝试在电影影评进行分类(二分类,积极或消极),各个模型的表现可能会不尽相同,且在相同条件下可以考虑运行时间的长短,将其添加进模型的评级体系。
目前在文本分类问题中,通过各大阅读理解竞赛榜单可以看到,深度学习的成绩已经超过人类阅读理解的能力,但是各个模型量都过于庞大,训练周期时间长,且对硬件的限制较大。希望未来研究者能够提出一种轻量级的、能够运用于各个文本分类器的语言模型。
