改进的基于多尺度融合的立体匹配算法
2021-09-07陈星张文海候宇杨林
陈星, 张文海, 候宇, 杨林
1.重庆文理学院 智能制造工程学院, 重庆 402160; 2.重庆交通大学 机电与汽车工程学院, 重庆 400074;3.重庆长安工业(集团)有限责任公司 特种车辆研究所, 重庆 400023
双目立体视觉如今广泛地应用在虚拟现实、巡线无人机作业、智能车、非接触测距等诸多领域。立体匹配是双目立体视觉的核心技术之一,其难点表现在:①搜索匹配点时,一般会存在多个对应点,尤其是在重复纹理区域;②由于实际场景中的各个物体空间关系复杂、相互遮掩等噪声的影响,造成了一些特征点不能找到正确的匹配点;③场景中存在反光、弱纹理区域、透明物体和深度不连续等问题。
现有的立体匹配技术算法大致可以分为局部算法、全局算法和半全局算法。局部立体匹配算法的主要思想是通过支持窗口获得聚合代价,从而获得单个像素的视差,具有模型复杂度低、效率高的优点,但存在匹配精度相对较差的缺点。半全局立体匹(semi-global-matching,SGM)[1],是基于一种逐像素匹配的方法,具有在保证近似于全局匹配算法匹配准确率的条件下,大幅度降低算法复杂度,提升计算速度的特点。全局立体匹配的主要思想是构造能量函数,通过最小化能量函数来得到匹配结果,主要有动态规划(DP)[2]、置信度传播[3]等算法,这类算法优点是精度高,但具有时间复杂度高、实时性差的缺点。
近年来,深度学习发展迅速,因此有学者通过训练卷积神经网络来完成图像块的匹配计算。Žbonta等[4]提出了(stereo matching by CNN,MC-CNN),首次将卷积神经网络应用于匹配成本的计算,利用卷积从一对立体图像获取更为抽象鲁棒的特征,计算两者的相似性作为匹配成本。Shaked等[5]提出了对文献[4]的改进方法。但很多基于卷积神经网络的立体匹配算法只是对深层网络的特征进行计算,而忽略了浅层网络的信息。深层网络更注重于语义信息,而浅层网络更注重细节信息,只采用深层网络的语义信息进行预测对小物体的匹配效果差。因此,有学者采用了一种结合图像金字塔的方法[6],将原图像采用高斯下采样构造出图像金字塔,在图像金字塔每层进行计算,得到不同尺度的视差图进行融合,从而提高匹配精度,然而这种算法的缺点是计算量大、需要大量的内存。还有学者在不同特征层分别计算匹配成本[7],这样做可以获得不同层的特征,但是没有将特征进行融合,获得的特征不够鲁棒。
基于上述问题,本研究提出了一种结合特征金字塔结构(feature pyramid networks,FPN)[8]和卷积神经网络(CNN)的立体匹配算法,试图建立一个将深浅网络特征进行叠加融合的网络。本研究的优点是将深层特征和低层特征进行融合,即可以充分利用低层特征所提供的准确位置信息,又可以利用深层特征提供的语义信息,融合多层特征信息,且分别计算,再融合多组计算结果,可以得到较优的匹配结果。
1 算法描述
根据Scharstein等[9]提出的立体匹配算法分类和评价,立体匹配的步骤通常分为4个部分:①匹配代价计算;②代价聚合;③视差选择;④视差后处理。本文也遵循此步骤。
1.1 特征金字塔(FPN)
识别不同尺寸的物体是机器视觉的难点之一,通常的解决办法是构造多尺度金字塔。如图1a)所示的图像金字塔,由原图像进行一系列的高斯滤波和下采样构造而成,文献[6]采用此结构,该做法虽然可以提高精度,但存在复杂度高、浪费内存的问题。图1b)则在原图像上进行一系列卷积池化,获得不同尺寸的特征图,然后使用深层特征进行计算,这种做法速度快、需要内存少,但精度有所下降,且只使用深层特征,而忽略了浅层特征的细节信息。因此有了图1c)的改进方法,分别对每一层特征进行计算,同时利用浅层和深层特征的信息,这样做一定程度可以提高精准度,但是它获取的特征不够鲁棒。

图1 各多尺度方法框架
因此,本研究采用特征金字塔结构(FPN),架构如图1d)所示,首先对原图像进行卷积池化,获取不同尺寸的特征图,接着对深层特征图进行上采样,次一层进行下采样使上下特征具有相同尺度,进而将2张特征图进行融合,融合后的特征用来第一次计算;接着将融合特征再进行上采样,再次一层特征下采样,融合两组特征,再进行一次计算,往复直至较浅层网络,得到多组计算结果。该结构将浅层特征和深层特征融合,既获得浅层特征的细节位置信息,又可以利用深层特征的语义信息,使得特征鲁棒,计算结果准确。
1.2 基于FPN的网络架构
根据以上介绍的FPN结构特点,本文设计了基于FPN的孪生[10]卷积网络(FPN Siamese CNN,FS-CNN)来计算初始代价。网络结构如图2所示,整个网络结构分为2个部分:

图2 FS-CNN网络结构
1) 第一部分用于图像的特征提取,由2个结构相同的子网络构成。每个子网络首先对输入的15×15的图像块分别经过4个卷积层,每一层都跟随着批归一化层(batch normalization layer)和ReLU激活函数,其中除了第一层步长为1,其余层步长均为2,经过4层卷积后,获得了具有不同尺寸特征的网络结构。接着采用FPN结构,首先对C4卷积层特征图进行上采样,使得尺寸和C3卷积层特征图一致,把2个特征图进行相加(add)处理得到融合特征,为了消除采样后的混叠效应,在融合之后加入卷积核大小为3×3的卷积层。左右子网络将分别得到的融合特征图进行拼接(concatenate)处理,即可得到1个待匹配的融合拼接特征,重复以上的结构,就可以得到3个待匹配的融合拼接特征。值得注意的是需要在C2和C1卷积层特征图融合前加入卷积核为1×1卷积层,目的是进行通道数降维,使得特征图维度相同。
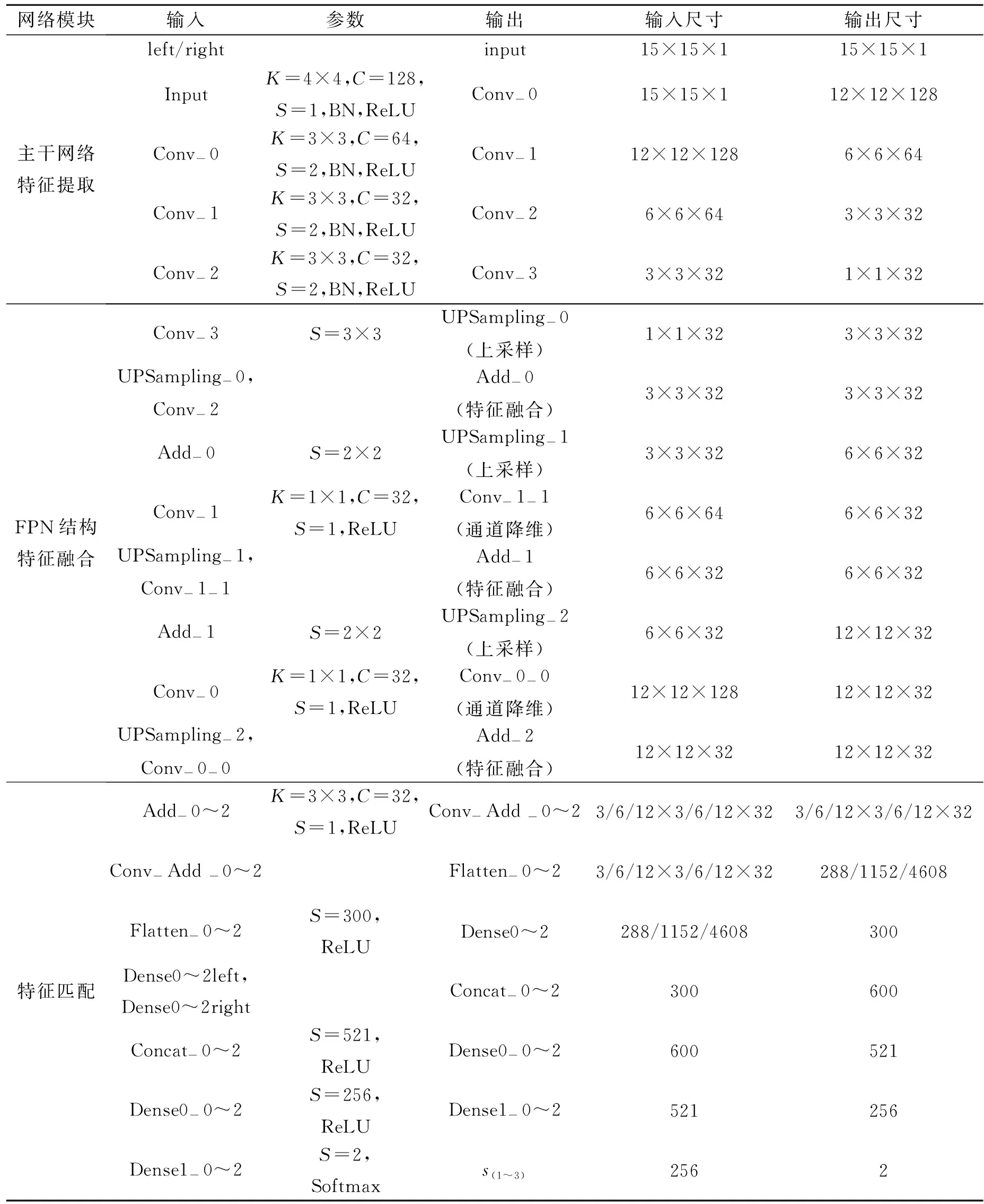
表1 FS-CNN网络结构参数表
2) 第二部份用于特征匹配,为3层全连接层。将3个待匹配的融合拼接特征分别输入,得到3个匹配结果s1,s2,s3作为在不同尺度下计算的匹配相似度。除了全连接层最后一层采用Softmax激活函数,其余层均采用ReLU激活函数,上采样均采用双线性插值算法。网络参数由表1给出,其中Add-0~2表示Add-0或Add-1或Add-2,其余Conv-Add-0~2等同符号意思相同;3/6/12×3/6/12×32表示3×3×32或6×6×32或12×12×32,其余同符号意思相同。
1.3 匹配代价的计算
设以(i,j)为中心的左图像块为ρL(i,j),相应视差为d时的右图像块为ρR((i,j),d),由于本文设计的网络有3个输出,即可得到3个初始匹配代价
(1)
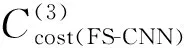
(2)
式中:x,y是代价空间DSI上像素点坐标;d为对应的视差值,d≤dmax,dmax=W×r为最大视差;W为原图像的宽;r为一常数,取0.16;α为参数常量,取0.2。
1.4 代价聚合
代价聚合就是通过一定的规则在得到初始匹配代价的局部区域中进行累加聚合。一定角度上看,局部区域的代价聚合可以看做在代价空间DSI中的进行滤波,即

(3)

引导图滤波技术是一高效有效的滤波技术,相比双边滤波器,引导图滤波的计算复杂度仅为O(N),N为输入图像大小,因此引导图滤波仅与输入大小有关,与支持窗口的大小无关。采用引导图滤波器进行代价聚合即就是在代价空间DSI上进行滤波,输入的p即为各个视差值所在代价空间层DSI(:,:,d),引导图I则为左右原立体图像。
1.5 视差的选择
在视差选择阶段传统的做法一般采用贪婪算法(WTA)进行简单的视差选取。虽然WTA快速有效,却忽略了相邻像素的视差容限。因此有学者采用动态规划(DP)的全局思想来进行视差的选择,首先构造能量函数M(x,y,d),采用DP最小化能量,并保存能量最小值所对应的视差位置,可表示为
(4)
式中:Cagg(x,y,d)为像素点(x,y)在视差为d时的代价值;d′为相邻像素点(一般指前一个像素点)的视差选取;γ为参数常量。
但是采用这样的做法,相邻像素的视差选取为0~dmax,该算法的复杂度为O(WD2),W为图像宽,D为选取视差范围。所以,本研究采用改进的动态规划的方法来进行视差选择:①首先缩小相邻像素点视差选取的范围,将视差范围0~dmax缩小为{d,d+1,d-1};②接着结合WTA算法,将WTA获取的视差值dWTA也作为格外的视差候选值。
改进后的算法复杂度仅有O(WD),该算法的核心是结合WTA,提供格外的视差候选值,可以有效地避免出现过度平滑的现象,改进后的算法可以表示为
(5)
1.6 视差后处理
由1.5节获得的初始视差图中还存在一些误匹配,需要进行视差精细化。本文采用左右一致性检测来检测遮挡点,接着进行遮挡点填充,最后采用加权的中值滤波器对视差图进行平衡滤波,获得最终的视差图。
2 结果与分析
2.1 实现细节
FS-CNN网络采用Tensorflow进行训练,训练采用小批度(mini-batch),批度大小(batch size)为64,使用Adam优化器,学习率为1×10-4,训练周期为50,动量为0.9,匹配窗口为15×15。其余超参数neg-low=4,neg-high=8,pos=1,γ=2,ωk支持窗口为5×5,ò=0.01,参数具体意义可参考文献[4]。运行平台为Windows10×64位系统,CPU为Intel Core i5。
2.2 Middlebury 2014数据集
本研究采用Middlebury 2014数据集[11]。该数据集提供了30张立体图像,图像内容多为室内场景。其中包含15张带有真实视差值训练图像,15张未带真实视差值的测试图像。
训练数据集的构造本研究采用在15张带真实视差图的图像对上,对于每对图像对,在左图像随机截取15×15的图像块,在右图像上根据正负样本对应截取。正样本表示右图像在左图像块偏移真实视差值[+1,-1]对应的位置下截取的右图像块,负样本表示右图像在左图像块偏移真实视差值[-4,+8]对应的位置下截取的右图像块。接着随机组合左图像块与右图像像块,对于左图像块与正样本右图像块的组合设定标签为(1),对左图像块与负样本右图像块的组合设定标签为(0)。
2.3 消融实验
对FS-CNN网络的每个结构的作用进行分析。在接下来的研究中,以与本研究提出的网络最为相似的Dense-CNN网络作为参考。实验的评判标准采用算法得到的视差值与真实视差值的差值绝对值小于3像素或小于真实视差的 6% 时,认为该点所得视差值是正确的,否则将该点计为视差错误点,即
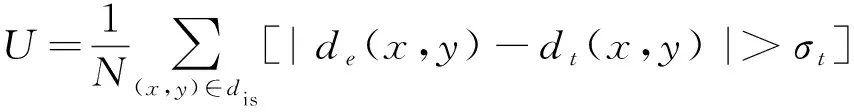
(6)
式中:N为视差图像素点总数;de(x,y)为算法得到视差图的视差值;dt(x,y)为真实视差图的视差值;σt为设定的误差限,本研究设置为3。
首先对主干特征提取结构进行测试,通过增加结构的卷积层数,测试对结果的影响。接着对FPN特征融合结构进行实验。最后测试特征匹配结构,通过改变全连接层数。实验结构如表2所示。

表2 不同网络结构的评估结果
从表2的实验结果发现,增加特征匹配结构的全连接层数量对结果的精度影响不大;增加主干特征提取结构的卷积层数,在一定程度下能降低误匹配率,但是降低的程度有限,而且增加了运算成本;FPN特征融合结构的引入,可明显提高匹配精度,降低误匹配率,精度超过了参考网络Dense-CNN。
2.4 不同算法的对比试验和结果展示
对比算法本文采用:SGBM[1](参数:Sblock=9,Ndisparities=64,p1=200,p2=800);BM(参数:Sblock=9,Ndisparities=64);NCC算法;同等条件处理的Dense-CNN[4]。图3为不同算法生成的图像对视差图,从上到下依次是Adirondack,Recycle,Sword1,Piano,PianoL,Playtable,Sword2。

图3 图像对在各类算法生成的视差图
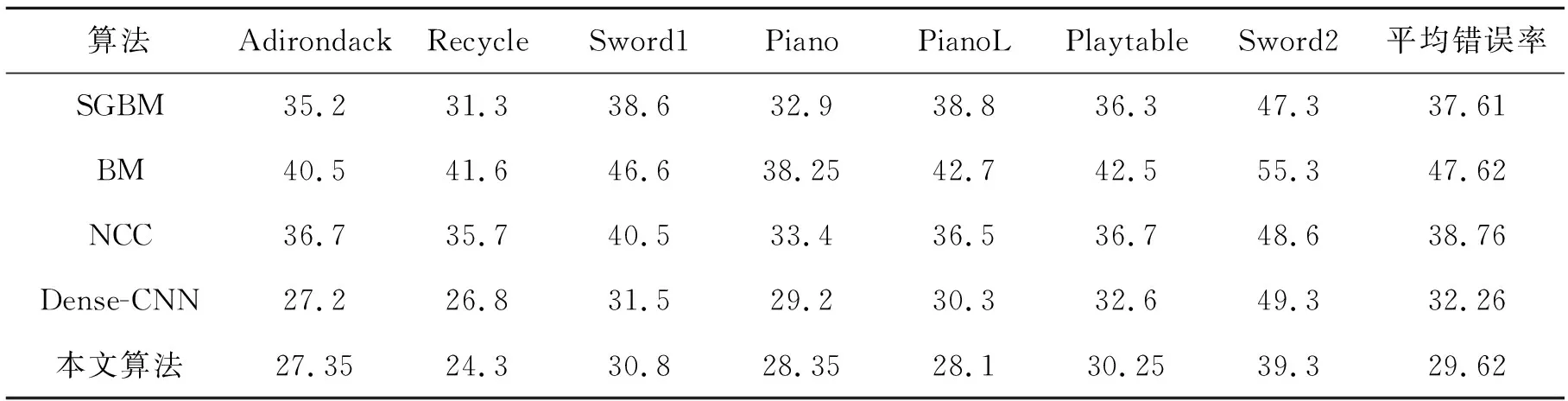
表3 图片误匹配率U%
由表3观察到,本研究提出的算法在不同场景的匹配精度明显都高于半全局算法SGBM,且远高于BM、NCC局部算法。在同等条件下本研究算法误匹配率低于传统的Dense-CNN。值得注意的是,在PianoL场景中,由于左右图像具有不同的光照条件,SGBM、BM、NCC 3个算法误匹配率明显变高,而Dense-CNN算法和本研究算法误匹配率并无显著变大,可以看出基于神经网络的匹配算法对光照影响具有一定的鲁棒性。在场景Sword2中,传统的Dense-CNN算法具有较高的误匹配率,而本研究提出的改进方法可以显著地降低误匹配率。
3 结 论
提出了一种结合特征金字塔(FPN)卷积神经网络的立体匹配算法,该算法在卷积网络(CNN)基础上,应用了特征金字塔结构,自上而下地融合不同尺度的特征图,且分别进行特征匹配计算,得到3组特征匹配结果,再计算得3组匹配成本,融合3组匹配成本获得最终匹配成本,利用引导图滤波器进行快速有效的代价聚合,在视差选择阶段采用改进的动态规划(DP)算法,结合DP和WTA,既提高了匹配精度,又降低了复杂度。结果表明,所提算法精度优于现有部分优秀的匹配算法。目前该算法仅在CPU上实现,今后可利用GPU的并行运算来提高算法的效率。
