基于语义分割的工单标签数据自动分类标注系统
2021-09-05刘晓伟刘科学谢枫王莉巩冬梅
刘晓伟,刘科学,谢枫,王莉,巩冬梅
(国网冀北电力有限公司营销服务中心(计量中心),北京 100045)
随着电网企业的不断壮大,在日常运营活动中,运营商每天将获取海量的文本数据,这些文本数据涉及机械、电子、信息等多个领域,种类多样,数量庞杂,缺乏规范的整合处理操作。为此,不少研究学者针对工单标签数据的特点对其进行自动分类标注操作,提升这些数据的分辨率,便于高效地识别[1-2]。
由于工单标签数据自动分类标注系统在数据操作的过程中需获取完整的工单标签数据信息,并不断审核系统内部的操作空间结构,因此,在操作的同时需调整系统硬件元件与软件程序间的结构关系,管理硬件与软件的数据存储方式[3-4]。目前的研究选用数据分类的方式整合工单标签数据信息,简化操作步骤,缩减操作所需的数据数量,避免了复杂的系统操作。
传统基于文本挖掘技术的工单标签数据自动分类标注系统,利用文本挖掘方式对工单标签数据进行深度挖掘,在掌控系统数据的基础上执行数据挖掘命令,有效缓解操作系统的内部压力,并调整自动分类标注系统的内部结构,具有良好的操作性[5]。传统基于预训练BERT模型的工单标签数据自动分类标注系统根据标准模型管理操作中产生的操作问题,训练基础数据,并调节基础数据的传输方式,获取准确率较高的基础数据信息,确保数据的良好传输,提升自动分类标注的操作效率。但传统系统在实际操作中将产生一系列的数据操控问题,对于部分隐藏数据的查找能力有限,无法获取隐藏数据的信息资源,导致最终获取的结果精准率较低[6]。为此,针对上述问题,文中提出一种新的基于语义分割的工单标签数据自动分类标注系统。
1 系统硬件设计
文中利用语义分割的数据识别性能调整内部系统硬件元件的关系,并结合相关的硬件结构将工单标签数据录入基础空间中,执行硬件系统操作指令,并构建指令传导图,如图1所示。
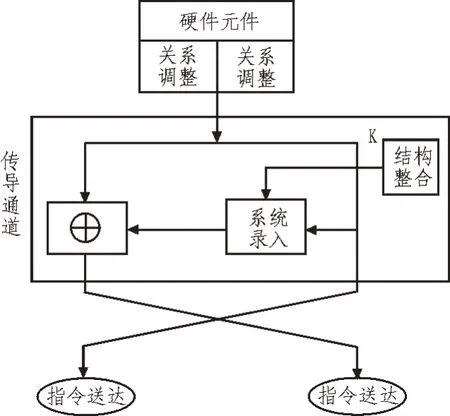
图1 指令传导图
选用内部存储性能较高的数据存储器作为工单标签数据的基础存储元件,以实现数据的标准存储。该存储器具有较强的工作效率,内部连接口连接分类单元芯片,将数据分类功能与存储功能隔离,避免相应功能的碰撞,减少外部数据因素的影响。该存储器的内部容量为2 GB,能够确保数据的完整性存储,并在存储的同时可进行存储通道拓展操作,转变数据的存储模式,构建良好的数据存储环境[7-8]。
在实现对数据的存储后,利用数据传导器将工单标签数据进行精准传导操作,文中数据传导器可在较为复杂的数据操作环境下使用,能够在传导命令下达的同时进行数据分析,减少数据操作失误,并随时进行数据分类操作,转化数据类型,内部设有记忆芯片,可对传导的数据进行数据记忆,提升数据操作的可靠性[9]。
2 系统软件设计
语义分割作为计算机算法的基本任务,需要将数据分为不同的语义可解释类别进行输入,并利用这些类别特征执行数据操作指令,文中在系统接收层输入数据组,调整数据组内部的数据信息,确保数据信息的完整性[10]。利用梯度下降算法进行数据学习,并训练基础数据的操作性能,扩展数据操作范围,便利数据的基础操作[11-12]。
标定特征数据,并设置数据标定公式[13-14]:
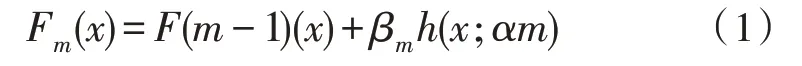
式中,Fm(x)为标定结果参数,F(m-1)(x)表示内部维度特征数据参数,βm表示内部整合条件参数,h为相关度匹配数据,x表示基础标定函数,α表示内部相关性分析指数,m为标定条件参数。经过以上数据操作后,管理标定的数据信息。将标定的数据信息完整存储于相应的操作空间中,等待空间软件平台处理[15]。
在实现平台处理后,执行系统软件操作命令。输入基础工单文本数据,在内部平台中进行文本预测处理操作,并构建预处理公式:

式中,T表示预处理结果参数,S表示软件系统操作指令,k表示内部平台操作规则,l表示空间软件处理信息任务。
由此获取预处理数据,并根据预处理数据构建数据调节模型,取得较为精准的操作数据[16],并执行数据训练指令,下达训练任务,对文本数据进行效果评估。调节中心软件的平台信息,在评估结果中查找自动分类标注性能,并将此性能结果作为操作的最终结果,由此实现对工单标签数据的自动分类标注系统设计,并构建分类标注流程,如图2所示。
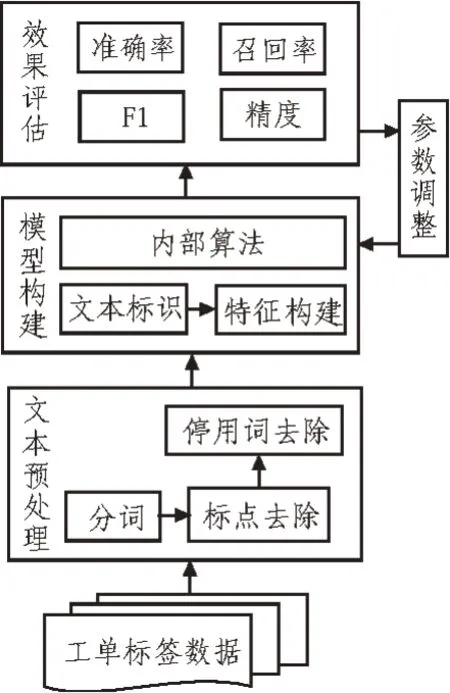
图2 分类标注流程图
3 实验与研究
文中将研究的系统数据进行整理,控制整理界面信息数据,管理不同空间结构的数据信息,时刻分配系统的分类标注项目,按照分类标注结果整合操作数据,获取相应的实验研究参数,并构建实验参数表,如表1所示。

表1 实验参数1
在表1中,选用代表性较强的实验操作数据,按照系统功能管理的标准查询分类标注界面,匹配界面信息,构建较为宽广的界面结构,执行内部操控指令,将实验参数空间数据与内部系统界面数据相结合,并监控数据界面信息,掌握不同的信息功能。根据信息功能系统分析自动分类标注结果数据追踪结果数据位置,将位置数据与条件数据相结合,审核此刻的结合数据信息,查找结合数据信息与内部自动分类标注信息的相似性。分类数据信息,将数据按可能性进行排序,并构建数据信息分布式表示,如图3所示。
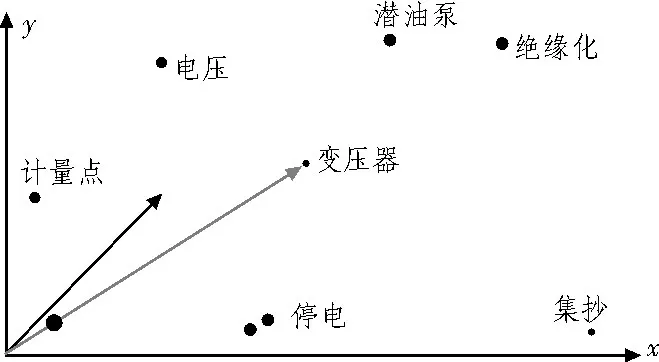
图3 数据信息分布式表示图
按照相似性顺序排列自动分类标注数据结果,执行结果数据。标准化控制整合的实验信息,采用所设计系统与基于文本挖掘技术的标注系统、基于预训练BERT模型的标注系统对自动分类标注参数进行查询,整合查询信息,获取完整的实验结果数据,3种方法的自动分类标注准确率对比结果如图4所示。
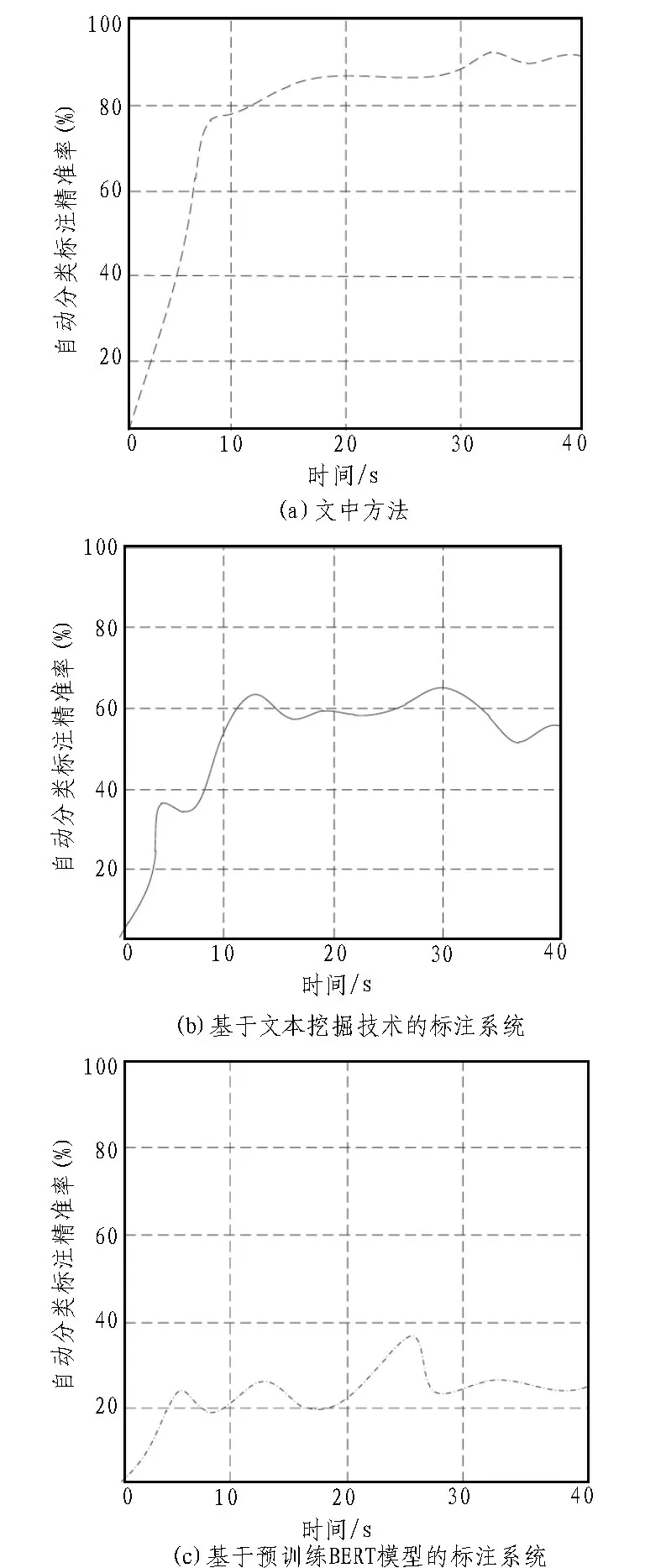
图4 自动分类标注精准率对比图
根据图4可以分析出,文中基于语义分割的工单标签数据自动分类标注系统的自动分类标注精准率均高于两种传统自动分类标注系统。基于文本挖掘技术标注系统的自动分类标注精准率较高,基于预训练BERT模型标注系统的自动分类标注精准率较低。由于文中系统在设计过程中调整了系统的设计范围,并查询整体自动分类标注的数据信息,调配自动分类标注系统信息,并缓和硬件与软件系统间的操作矛盾,强化外部系统管理性能,因此具有较强的数据操控性,收集的初始数据精准程度较高,其最终的自动分类标注精准率较高。传统基于文本挖掘技术的标注系统利用文本挖掘的优势进行数据挖掘,同时匹配功能信息查询不同区域的数据状况,对工单标签数据的了解程度较深,能够达到良好的数据操作效果,并及时控制数据的流向,具有较高的自动分类标注精准率。传统基于预训练BERT模型标注系统虽完善了系统的内部结构,但对于外部数据分析的力度较小,无法掌控工单标签数据的基础性能,且操作投入较大,消耗高,导致其最终研究过程中的数据产生一定的偏差,自动分类标注精准率较低。
在实现以上实验操作后,对实验过程中将产生的数据转化因素进行监控,时刻保持实验操作的正常状态。标定基础信息数据,将工单标签数据整合至一个密闭的操作空间中,避免无关数据的侵入与影响,并构建网络模型结构图,如图5所示。

图5 网络模型结构图
整理操作的数据信息,并按照获取的信息内容提升操作的技术性。构建网络监管模式,将硬件平台信息全部录入平台系统中,便于后续实验操作辨识,并设置实验参数,如表2所示。

表2 实验参数2
收集不同区域的工单标签数据信息,将数据信息的分类标准添加至操作应用程序中,缓解应用程序的内部压力。缩减操作所需步骤,将操作时间控制在系统操作允许范围内,并标定范围信息。利用标定的范围信息管理工单标签数据的自动分类标注模式,对比3种系统的数据分类标注时间,如图6所示。
由图6可知,传统基于文本挖掘技术标注系统的数据分类标注时间较长,传统基于预训练BERT模型标注系统的数据分类标注时间较短,文中基于语义分割的工单标签数据自动分类标注系统的分类标注时间均短于其他两种传统系统。
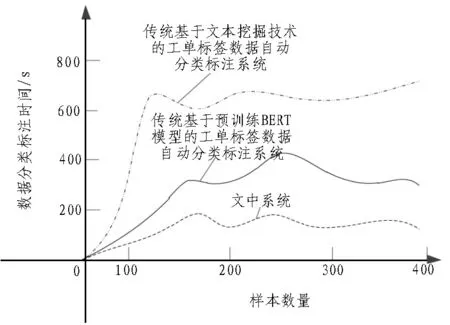
图6 数据分类标注时间对比图
造成此种差异的原因在于文中系统设计在数据收集的初级阶段构建了信息管理空间站,标定了收集的工单数据信息。同时,管理不同位置的数据信息状态,加强对信息数据的集中处理力度,获取了良好的操作效果,完善了内部系统机制,减少了不必要的操作浪费,缩减操作所需时间与分类标注时间。传统基于预训练BERT模型标注系统能够利用预训练BERT模型对不同平台的工单标签数据进行程序训练,在数据管理的同时及时控制外侧信息的录入,具有良好的数据系统操作性,能够更好地符合数据分类标注的标准,降低了操作的困难程度,由此缩短了其分类标注时间。传统基于文本挖掘技术标注系统虽配置了一系列文本挖掘协议,但对于工单标签数据的调整力度较小,造成工单标签数据无法得到系统的有效传输,在传输途中将产生不可避免的操作危机,导致其最终的分类标注时间较长。
4 结束语
文中在传统工单标签数据自动分类标注系统的基础上设计了一种新的基于语义分割的工单标签数据自动分类标注系统,该系统不断调节系统软件与硬件间的操作关系,转变操作条件,并提升操作过程中的工单标签数据的数据收集精准度,获取可靠的操作数据,缩减操作所需时长。实验结果表明,文中系统的自动分类标注效果明显优于传统系统。
