基于热图和放射环的关联层次数据可视化研究*
2021-09-04张静
张 静
(六安职业技术学院 安徽六安 237158)
热图在数据可视化表达方面的应用频率较高,基于颜色数值大小在地图上表征数据分布的空间规律,是数据分析领域常用的高性能数据可视化分析方法[1]。放射环利用空间填充原理对数据实施层次可视化处理,以圆环形式表达事物数据分布规律[2]。当前大数据时代对海量数据关联层次分析提出了崭新要求,既要保证数据分析的可视化水平,又要加强数据分析的精准度。为此,结合热图与放射环形成一种新的关联层次数据可视化分析方案,在体现事物在地理空间分布规律的同时明确各区域间存在的相似关联性,使用户通过肉眼观察得到更多的可视化信息[3]。文章基于Spark集群环境执行热图计算,以并行化的方式提高了单次数据计算量,大幅提升热图生成的效率,满足了大数据时代的高速数据处理需求。
1基于热图和放射环的关联层次数据可视化技术
1.1并行式大数据热图生成算法
大数据关联层次数据分析是当前数据分析的热点,海量信息增长速度亟需并行式数据热图算法解决海量数据可视化分析的不足。该研究基于地理信息绘制数据可视化分析热图,其优点是可以利用热图表现事物规律分析时间与空间特征[4],为此进行以下准备:为避免并行化计算模式产生的边缘现象,借助Spark大数据集群运算热图数据、执行热力值算法。
该研究遵循以上并行式大数据热图生成原理,其中生成热图的基本步骤如下:
Step 1:以离散的数据为对象生成圆形缓冲区,半径定义为r;
Step 2:利用程度不同的灰色填充缓冲区颜色,规律是深→浅、外→内;
Step 3:通过随机通道叠加填充交叉缓冲区颜色,叠加缓冲区数量越多、叠加值和热值越大,颜色显示则越亮;
Step 4:最后,基于色卡标准为灰色区域赋予彩色值,得到热图。
1.1.1网格层次数据聚类预处理 为得到更加精准的热力值计算结果,基于网格层次聚类算法对离散的数据实施聚类预处理,进而生成层次清晰、数据精准的可视化热图。网格层次聚类算法分为两个阶段,第一阶段:将数据区域划分成若干网格,每个网格分摊到一定的数据,在网格数据范围内实施微聚类[5]。在n维数据空间中,将每维空间网格分为l份,由此数据空间中将存在ln个长方形单元,且大小一致;微聚类过程中存在一个数据集J,定义O表示点的数量,将J划分到合适的单元内,若单元内对象在O之上则定义为原始簇,将簇代表点间距较小的二者合并,下一轮继续运算簇的代表点,基于上述规律合并簇,合并终止的条件是簇的数量超过簇邻近度最小值。第二阶段:对网格聚类结果进行层次聚类。定义聚类对象为H个数据,H×H则为对象的相似矩阵。层次聚类的簇则为H个数据中的每个数据,簇间相似度即数据对象间的相似度,首先合并相似度最高的的两个簇,簇总量相应减一;其次,求取新簇与旧簇的相似度值;最后,循环操作以上两步骤,层次聚类运算终止条件是只剩一个簇,该簇内部含有若干对象。
1.1.2 热图热力值计算 基于网格层次聚类算法预处理后的新簇中心点即为热图的热点,以体现事物分布规律与信息,可使用公式(1)所示的高斯函数求取热点对其周围作用范围的大小。
(1)
式(1)中,λ为实数常数,是高斯函数的尺度因子,λ越大作用范围越大;影响比例因子采用ε表示,作用机理与λ一致;另外,采样点和热点间距采用x表示。公式显示,热点半径与作用范围为反比例关系,外部作用影响力最小[6];区域热力计算结果为附近全部热力值的总和。
利用矩形点阵表示一个原图,各采样点具有特定的经纬度信息,为此基于高斯函数求取采样点热力值。期间定义矩形点阵区域范围的纬度、经度分别为:p1、q1;M×M表示点阵大小,公式(2)、(3)则为r行c列采样点的经纬度信息:
(2)
(3)
公式中,采样点的经纬度值为q、p,经纬度范围下限值分别采用qmin、pmin表示。基于公式(1)求取热点对采样点的热力影响,目标热力值计算即求取热力影响值的总和,由此得到的热力值即为地理坐标中热图的热值。
1.2 基于层次聚类的放射环生成算法
一般的放射环算法仅能表达数据集的属性、共用户查询数据集层次关系,不具备描述数据关联关系的功能,为此在传统放射环算法基础上引入层次聚类算法理顺环节点顺序,层次聚类可以良好表征数据点排列趋势状况,且不会由于聚类数量误差影响可视化结果,因此基于层次聚类算法的放射环节点关联操作,可以提升数据集表达的关联可视化水平[7]。
算法生成放射环的过程如下:①构造数据节点的状态矩阵,在此基础上生成杰卡德距离矩阵;②基于聚类矩阵完成层次聚类,基于该结果排序关联数据节点;③生成可视化节点放射环。
1.2.1 生成杰卡德距离矩阵 杰卡德距离矩阵属于对称矩阵,用S表示;在待整合数据集中定义存在n个对象集合F,维数为i,结合张鑫跃的相关研究集合F的杰卡德距离矩阵S如公式(4)所示[8]:
(4)
式(4)中,随机对象Fi与Fj的杰卡德距离用aij表示,即(Fi,Fj);如果i值与j值相等,则有aij为0,此时说明各对象集合同自身的关联程度最高,因为距离值最小。
1.2.2层次聚类排序节点 此处层次聚类原理与热图数据预处理的层次聚类原理一致,均通过合并最小距离簇的方式完成数据聚类。利用1.2.1小节求取的数据对象杰卡德距离矩阵n×n为基础,对n个对象实施层次聚类处理。
Step 1:还原数据类获得n个类别对象,个体对象内存在唯一的类,利用距离矩阵求取得到类间距;
Step 2:合并距离最小的两个类,此时总的类别数目减一,并重新求取新类与旧类的距离;
Step 3:循环操作Step 2,算法终止条件是全部簇归为一个类别。
根据聚类结果对节点对象集合{F1,F2,…,Fn}进行排序,最终生成秩序良好的节点放射环,以表达数据间的关联特征。最后,热图虽然能够快速呈现地理位置层面的事物分布规律,但是获取的信息量有限,尚未达到关联属性获取的目的,所以将热图生成的热图内置在放射环内部,并基于直线连接热图节点与放射环节点,以示二者间的关联。
2实验分析
为了验证文章提出的基于热图与放射环的关联层次数据可视化方法的有效性及优越性,在Win7系统上进行热图与放射环绘制测试,计算机CPU为Intel E5系列,内存大小为16G。数据聚类处理环境为python语言,基于C/S架构开发关联数据可视化分析系统。研究以数据可视化分析的经典数据集“农药残留数据”作为测试样本,以分析文章方法的关联数据可视化水平。
2.1放射环算法性能分析
文章方法使用层次聚类算法排序节点得到具有关联性的放射环,如图1所示。
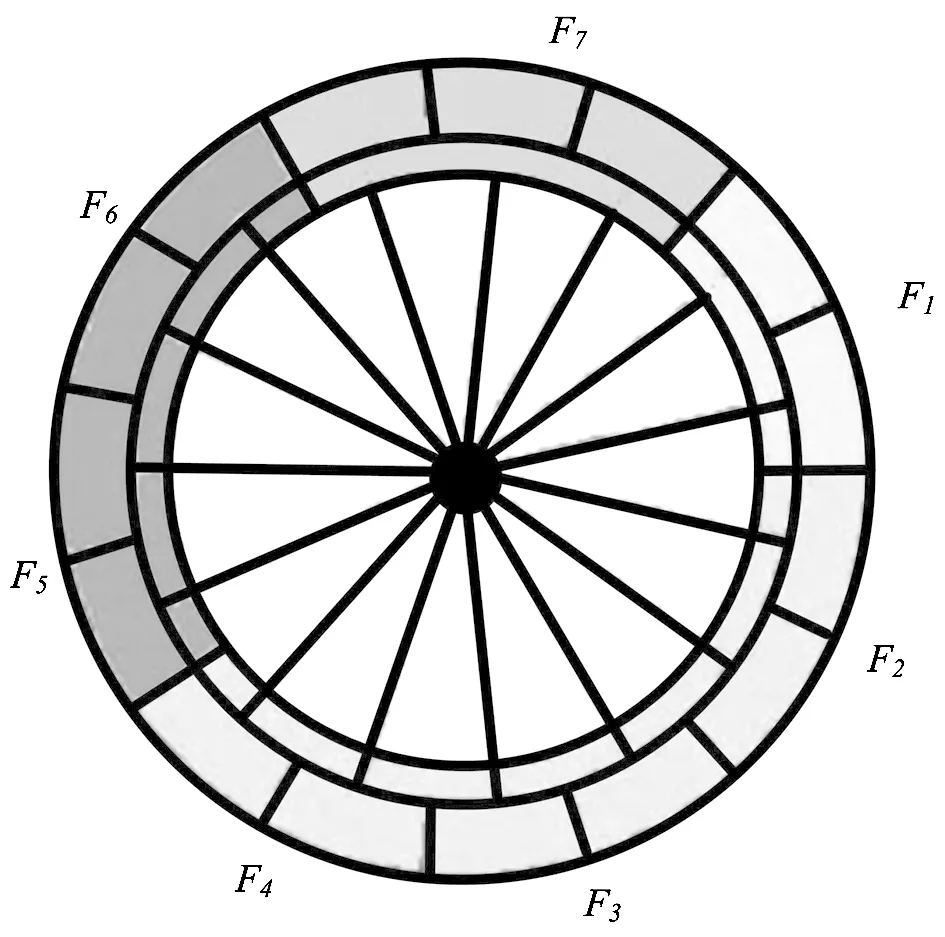
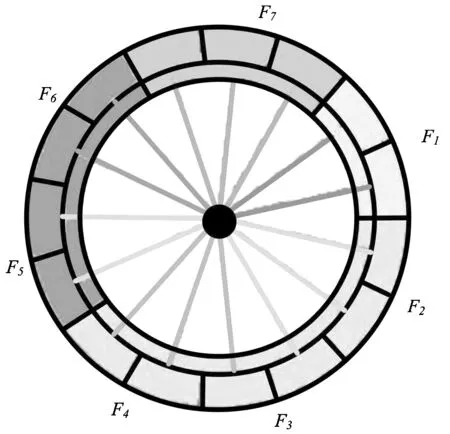
(a)传统放射环算法 (b)文章放射环算法
图1(a)为仅使用传统放射环算法生成的农药残留检测放射环,该图能够展示热点与各农药之间存在关联,但是不能表征存在何种关联,此为传统放射环算法的局限;图1(b)是基于文章方法得到的节点放射环绘制结果,利用不同颜色点短连接热点与农药放射环,颜色相同的连线表示它们之间存在农药相似之处,指出了热点与农药间的具体关联内容,满足了当前关联层次大数据分析的可视化需求,弥补了传统放射环算法的不足。
2.2 热图与放射环关联层次数据可视化效果分析
基于文章方法绘制了区域性农药残留超标可视化图像,如图2所示。
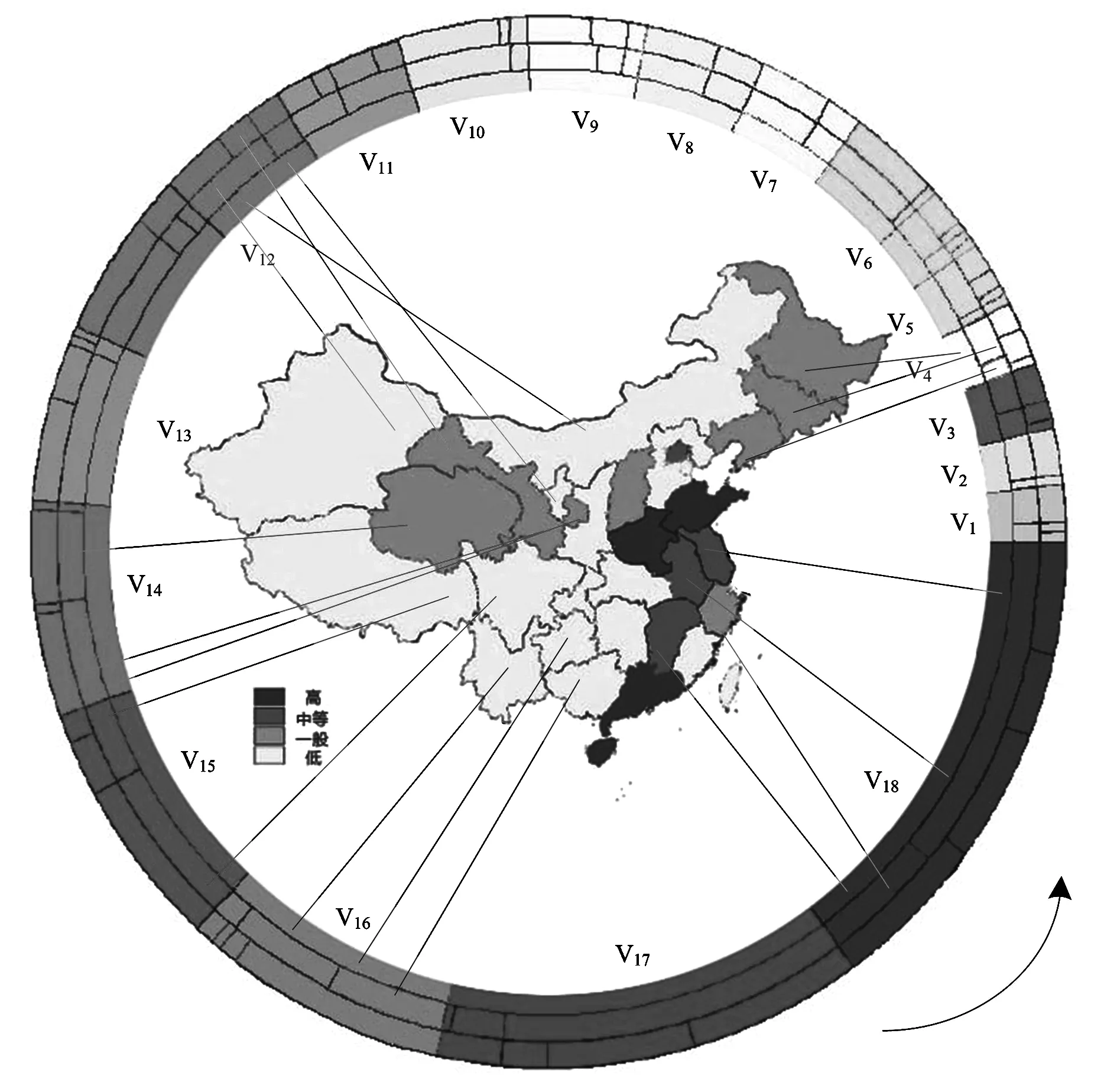
图2 基于热图与放射环的关联层次数据可视化展示
图2内部为地理性分布的农药残留热图,外部为农药超标农产品分布情况,直线表示二者之间存在的关联性信息。热图展示了农药在各地区残留超标情况,颜色越深表示地区农药超标的程度越高,颜色越浅表示农药超标的程度越低。外部放射环中第一层Vi表示农产品的名称;第二层表示农药的类别;第三层表示农药的危害程度(毒性),安装箭头方向由左向右表示毒性由低至高。热图与放射环间颜色相同的直线表示它们之间存在相似性,即二者的关联关系。由此可见,文章方法可以描绘出准确的地理信息热图以及农药与地区间的关系,表征不同地区间农药残留检测的关联性,为进一步研究区域性农药残留问题提供可视化数据依据。
3结论
文章结合前人成功案例将热图与放射环数据可视化技术融合,形成一种新的层次关联数据可视化方案,在放射环内部嵌套热图信息,使放射环展示更多的地理空间分布信息,加强了区域间信息关联性。文章特点是在热图与放射环生成环节均使用了层次聚类算法,在前者中的作用是对离散实施预处理,减少无效数据参与热力值计算;后者基于层次聚类算法合理排序放射环节点,使节点以关联关系存在。文章方案同样可用于金融、等分析领域,对于管理者而言是一种多功能、较理想的数据可视化分析工具。
