一种基于卷积神经网络的快速识别朱墨时序方法
2021-09-04李福坤周治道魏源松孙彤尹伟石
李福坤,周治道,魏源松,孙彤,尹伟石
(长春理工大学 理学院,长春 130022)
目前在我国只有加盖了印章的正式文书才具有法律效应,依据正常的顺序,应该在写好了相关的文字后进行审核,经过审核的合格的文件就可以用印章,也就是应该先墨后朱。但是在一些造假的文件里面都是事先盖好章,等需要时候再签上字。这就带来了在进行案件处理时文件真伪性的问题。在近几年中,由于经济的飞速发展,人们法律意识的增强,以及对知识产权重视程度的加深,各种刑事、民事及知识产权纠纷案等案件的出现和增加,使得在进行法律诉讼的过程中,会出现很多纸质等证明材料,对于这些纸质的证明材料,对其真伪就要进行科学准确的判断,以保障最终评判的正确公正性。
通过查找文献和调研可知,目前在我国朱墨时序的检测方法主要有显微镜检测、荧光检测和光谱检测;显微镜检测是将朱墨样本放在显微镜下放大观察,依据朱墨重叠出的字迹脉络和印文的脉络变化,加之一些印文和字迹融合现象判断朱墨的时序[1]。荧光检测是借助荧光的方法,先将样本做荧光处理,然后得到荧光图像,再利用朱墨重叠处的荧光特征进行分析,如果朱红的荧光在上,则为先墨,如果墨的荧光特征在上,则为先朱[2]。2017 年,陶玉等人[3]用荧光法判断激光打印文件朱墨时序;柳彬[4]利用激光共聚焦扫描显微镜对朱墨时序进行了实验研究。但这两种方都有很大的局限性,显微检测对人的经验依赖度高,而且现在主要使用光敏印油和原子印油,使得朱墨重叠处的印文和墨迹的物理特征在大多数情况下并不明显,这种检测方法基本失效[5];对于荧光检测而言,并不是每种色料都具有明显的荧光特征,所以,这种检测的局限性很大[6]。而光谱法的监测过程较为繁琐,对于印油的浓淡程度,则是影响检测结果准确性的重要因素,印油印文越淡,结果越容易出现误差,准确率也越低,因此这种方法也同样有很大的局限性。
在国外的相关研究中,对于朱墨时序检测也有着显微检测、光化学显微检测和光谱法检测等方法。印度德里大学化学系的Ali Raza,Basudeb Saha[7]采用了拉曼光谱法,以研究拉曼散射作为法医分析及印版油墨的可疑文件的工具的可行性。Lombardi Jr,Leona M,Vo Dinh T,Antoci P 等人[8]开发拉曼光谱法和数据库评价微量证据和对质疑文件的审理。Joong Lee等人[9]使用原子力显微镜法来调查墨粉和冲压墨水的时间顺序。Kim,J等人[10]聚焦离子束(FIB)和扫描电子显微镜/能量分散X射(SEM/EDX)的组合可用于确定线交叉的顺序。这些方法同样都有着各自的局限性。
本文通过运用卷积神经网络对朱墨时序进行快速准确的识别,解决了时序检测难、效率低、检测结果不准确的问题。可以对不同时序的签字盖章图像进行快速实时处理,提高了朱墨时序图像识别的准确性和稳定性。
1 方案设计
基于不同时序的朱墨样本在朱墨重叠处图像色素点的区别,通过卷积神经网络(CNN)做有监督训练,再运用训练好的模型对朱墨时序快速鉴定,达到提高鉴定效率、准确率和减轻人劳动强度的目的,从而保证了文件检测和司法公正时鉴定的正确公正性。
1.1 功能描述
该方法可以在拍照取得待测样本照片后输入到测试系统中,经过所编写的截图软件截出有效区域后,即可以自动识别出待测样本的朱墨时序,方便快捷,准确度高。
1.2 方案的设计
根据朱墨时序检测,分为先签字后盖章和先盖章后签字,分别制作样本图样。然后将制作好的样本进行拍照取样,获得不同时序的朱墨图像并将其分开存放,并对图样进行裁剪压缩。对不同时序的图片命名,贴上对应的标签值。接着对CNN进行训练,达到规定的阈值即停止训练。检测时的待检测样本处理方法和样本相同,将其放入训练完成后的CNN系统中检测得到对应的标签值。具体流程如图1所示。
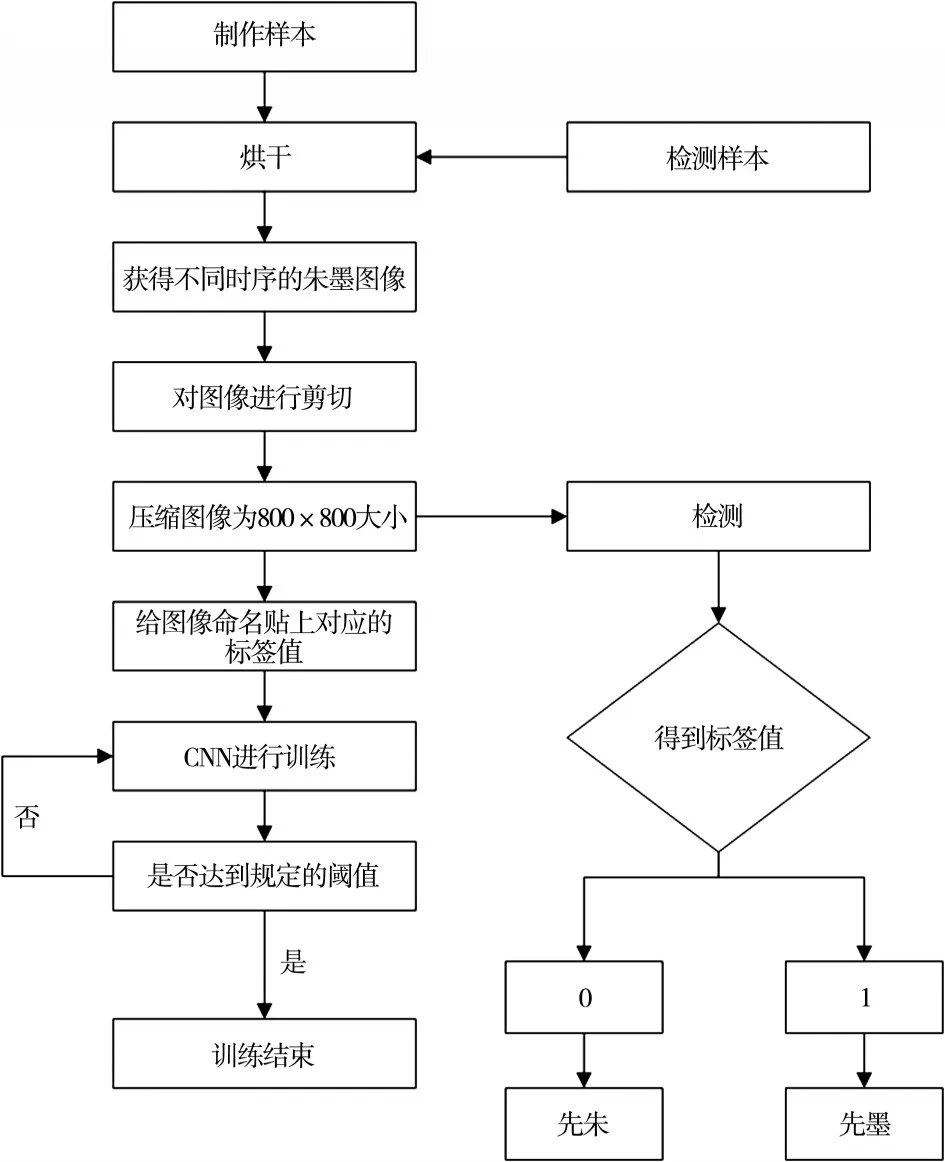
图1 方案流程图
该方案的主要部分是算法及代码程序,即图像处理,再者就是获取样本图样的装置以及在图像采集时各种因素对图片RGB值的影响。同时对于深度学习来说,样本的数量需求较高,需要制作一个较为大型的样本集。
2 实验原理
通过建立CNN模型并对算法模型进行设计和修正,最后调用训练好的模型运行和预测。
2.1 CNN模型
卷积神经网络(CNN)是一种包含了卷积计算的前馈神经网络,能够对输入的信息进行平移不变分类,被广泛应用于图片,语音的识别分类模型。一般的CNN模型主要包含五个部分:输入层、卷积层、池化层、全连接层、输出层。
(1)输出层:输入的二维信息,输入的信息必须先进过预处理,达到统一标准。
(2)卷积层:卷积层是卷积神经网络模型中最重要的部分,对二维信息做卷积运算,可以提取二维的特征,随着卷积层的增加,特征将越来越接近真实语义。
(3)池化层:池化层是卷积层之间的一种下采样层,目的是为了减小模型的参数,从而减少需要的内存和算力。一般使用平均池化和最大池化两种池化方式。
(4)全连接层:主要连接分类器和特征图,通过将二维特征图映射成一维的特征向量来向分类器输送数据。
(5)输出层:一般使用softmax分类器,输出最后的分类结果。
2.2 CNN算法模型设计
在CNN的算法模型设计过程中,首先需要对数据进行预处理,然后根据实际算力和模型精度进行模型设计。
2.2.1 数据预处理
由于输入层要求输入的数据的大小,通道数统一,并且为了提高模型的鲁棒性,需要加入数据预处理。将输入图像一致缩放到[800,800,3],并对输入数据进行归一化处理,将RGB数据缩放到[0,1]范围内。再进行标准化处理,输入的数据除以自身的标准差。
处理后的图片如图2所示。将带有误差扰动的图像转换成矩阵后加高斯噪声,处理后的图片如图3所示。

图2 规范化处理后图片
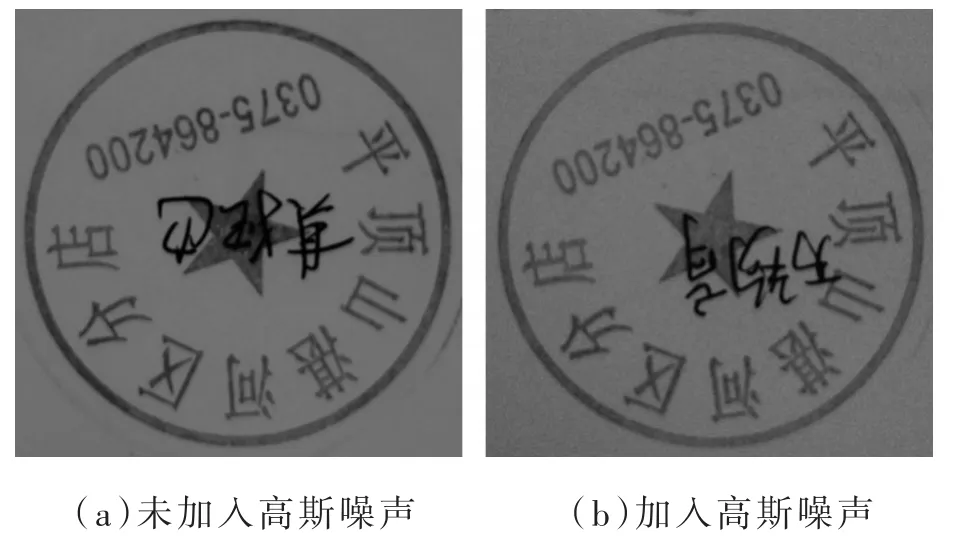
图3 高斯噪声效果加入对比
2.2.2 模型设计
综合考虑实际运算速度、内存限制与模型精度,模型如下:输入层[800,800,3],传入第一个卷积层,卷积幅步为1,16个大小为[3,3]的卷积核,输出为[798,798,16]的特征图,第三层为池化层,使用max-pooling降采样,输出为[266,266,16]的特征图,上一层的输出经过参数为0.25的dropout层传入第二个卷积层,卷积幅步为1,16个大小为[3,3]的卷积核,输出为[264,264,3]的特征图,第五层为第二个池化层,使用maxpooling降采样,输出为[88,88,16]的特征图,上一层经过参数为0.25的dropout层再压缩为123 904维的向量,传入第一个全连接层,输出256维的向量,最后经过输出层,使用softmax分类器,最终输出为2维的向量。过程如图4所示。

图4 算法处理模型
2.3 模型的运行与预测
数据集总共分为先盖章蓝色笔,先盖章黑色笔,后盖章蓝色笔,后盖章黑色笔,共四类,每类215张图片。以下给出算法具体流程:
(1)将数据集分成两部分,80%为训练集,20%为测试集。
(2)对输入图像进行随机上下翻转,左右翻转,特征图标准化处理,增强图像。
(3)使用增强图像训练CNN。
(4)使用交叉熵损失函数,并且使用随机梯度下降(sgd)优化。
(5)使用反向传播算法更新模型权重。
(6)使用测试集进行模型的测试,如果性能达标,保存模型,如果性能不达标,进行下一代训练。
(7)使用保存的模型对输入图像进行识别,得到识别结果。
由图5可知,模型的训练步骤如下:

图5 算法具体步骤流程图
训练代数过低模型欠拟合,训练代数过高模型过拟合,选择适中的训练代数非常重要,发现以下设置为最佳:优化器使用随机梯度下降(sgd)学习率(lr)为 0.01,动量项(momentum)为0,损失函数为交叉熵损(categorical_crossentropy)batch_size为16,训练20代(epoch)。
对样本图片分别进行了以下训练方式:
(1)使用蓝色笔训练集训练,测试蓝色笔。
(2)使用黑色笔训练集训练,测试黑色笔。
(3)使用蓝色笔训练集训练的模型测试黑色笔。
(4)使用黑色笔训练集训练的模型测试蓝色笔。
3 样本图样的获取
在样本图样的获取过程中分析出多重因素的影响,并分析出RGB值的影响因素,确定了样本图样的获取方法。
3.1 RGB值影响因素的分析
CNN是基于不同时序的朱墨样本在朱墨重叠处图像色素点的区别,做有监督训练,最终达到识别图像朱墨顺序的目的。但在最初的实验中,发现光源和拍照角度的不统一对实验结果影响较大。其次是样本制作完成后静置与烘干的区别,经过烘干后的数据样本的效果最好。烘干和静置主要是为了模仿文件签署时间久的特点。
3.2 样本图样的获取
3.2.1 样本制作
在考虑到RGB值的影响因素的情况下,找到解决影响因素的方法,减少各类因素对RGB值的影响。对于样本的制作,采用同一纸张和不同颜色不同材料的蓝黑色笔,制作先盖章和先签字的两种样本。因为考虑到目前的文件签字用的是蓝黑色两种笔,实验所用的笔只用了蓝色与黑色两种,分别使用了不同的材料。制作后对其进行烘干。
3.2.2 暗箱制作
(1)暗箱箱体为正方形结构,其材料为木制,密闭遮光。
(2)在木箱的顶部即样品放置区的正上方有一摄像头,保证其对文件进行垂直俯拍,通过USB与电脑相连后,使用S-EYE控制相机进行拍照。
(3)摄像头前加一550 nm滤光片,降低亮度,防止由于光源离摄像头距离太近而造成的过曝。
(4)在箱体两侧加两个12 W LED光源,目的是保证在拍照的过程中光源统一,同样是为了减少对RGB值的影响。
(5)箱体前开一小门,在拍照时把小门关上,以防止外界光源和其他因素的干扰,再通过S-EYE软件即可拍照获得照片。其结构如图6所示。
3.2.3 样本图样获取
将制作好的样本烘干后放入暗箱中,通过照相机连接电脑,用S-EYE软件对所放入的样本进行拍照。这样所获得的照片都是在同一光源下的样本,最大程度上减少光源对RGB值的影响。考虑到目前签字采用的是蓝色和黑色笔,需要制作不同时序,蓝色和黑色笔的样本。还需要制作同一颜色不同材料的笔的样本。因为笔的材料,中性、碳素等对RGB值的影响也是不同的。再利用编写的截图软件对样本图片进行精准截图。并对图片进行压缩处理,每张图片压缩至800×800大小,成品如图7所示。截图软件的主界面如图8所示。

图8 软件界面展示
4 实验结果分析
为了验证模型的鲁棒性和泛化能力,使用加高斯噪声的方式模拟实际应用场景,分别对未加入高斯噪声和加入高斯噪声的实验结果进行了处理分析。
4.1 未加入高斯噪声
对比表2和表4,使用黑色笔制作的数据表现明显优于蓝色笔,观察制作的数据集后发现在使用蓝色笔制作的数据中存在部分图像亮度与其它不同的情况,在制作蓝色笔的数据时可能由于人为因素出现了暗箱未完全封闭的情况,导致环境光影响了数据集的制作。这同时导致了表2的损失明显低于其它其余表。表2出现了预测结果100%的情况,是验证集样本数量不够大造成的,未测试模型精度,还需进一步提升验证集容量。
通过表2及表4可以看出,使用对某一支笔制作的数据进行训练得到的模型预测此支笔制作的其他数据时,准确率可以达到93%以上,在可以控制笔的型号的情况下,本方案可以为朱墨先后顺序的判断提供可靠的结果。针对表1及表3,当使用某一只笔制作的数据进行训练得到的模型预测其它笔制作的数据时,准确率在86%以上,且针对图像随机反转的数据集,模型的预测结果会出现较大不同,说明当笔的型号足够多,且样本量足够大时,此方案可以得到一个针对不同笔种的高泛用性、高准确率朱墨时序分类模型。

表1 黑色笔迹预测蓝色笔迹

表2 黑色笔迹预测黑色笔迹

表3 蓝色笔迹预测黑色笔迹

表4 蓝色笔迹预测蓝色笔迹
4.2 加入高斯噪声
在对图片加入高斯噪声处理后,用原来的模型对加高斯噪声的图片进行测试,从而得到新的实验数据。
对比表5和表7,同样可以发现黑色笔的数据表现也明显优于蓝色笔。在加入高斯噪声后,两组实验的准确率都相对于未加高斯噪声的准确率下降了百分之十几左右,但准确率仍有82%以上。这说明即使在有外界环境干扰的情况下,预测的结果依旧有很高的准确性。对于表5和表8,当使用某一只笔制作的数据进行训练得到的模型预测其它笔制作的数据时,准确率在80%以上,可以发现即便是污染过的样本,模型也具有较准确的识别能力,通过上述实验,不难看出神经网络模型在识别朱墨时序上拥有较好的应用前景。
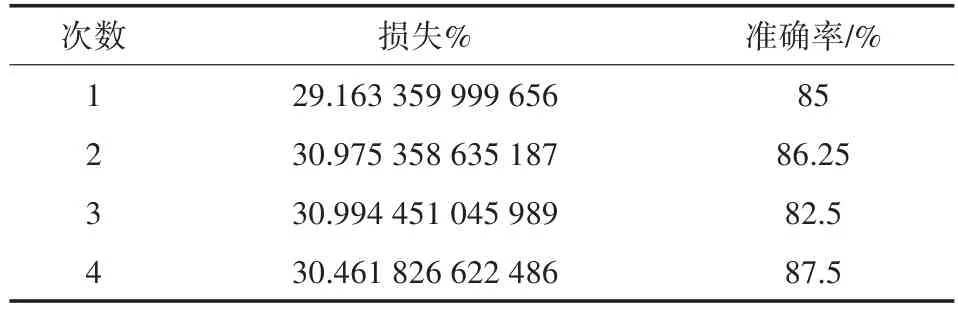
表5 黑色笔迹预测黑色笔迹
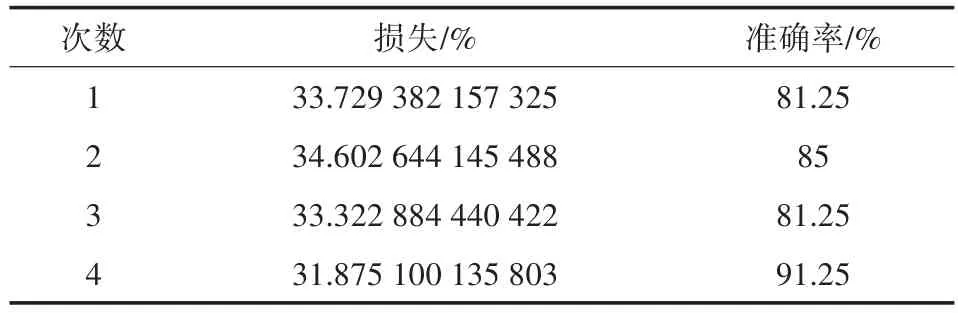
表6 黑色笔迹预测蓝色笔迹
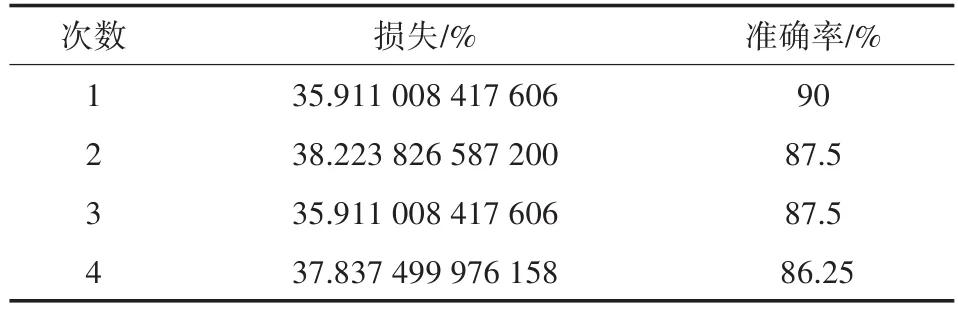
表7 蓝色笔迹预测蓝色笔迹

表8 蓝色笔迹预测黑色笔迹
5 结论
提出了一种全新的基于卷积神经网络的朱墨时序检测的方法,为朱墨时序检验提供一种新思路、新方法。解决了现有的朱墨时序检验的准确性低、人工经验依赖性高、操作过程繁琐等问题。实验和结果分析表明本方法具有很强的可行性,因此在司法公正文件检验等领域有很大的发挥空间,从而保障在法律诉讼案件或司法公证最终评判的正确公正性。在应用层面,可以在使用大数据集训练好的模型的基础上,再制作新出现的目标笔种的少量数据集进行迁移训练,使此方案的准确率在使用过程中保持稳定。
