复杂环景下的文本检测与识别算法的研究
2021-09-03吴继安杨超宇
吴继安 杨超宇
(安徽理工大学经济与管理学院 安徽淮南 232000)
通过使用计算机视觉,大大提高了工业生产的生产效率。并且在一些特定的生产环境下,将字符识别技术应用到商品标签识别中,可以识别并读取出包装上的文字信息。其中包括:产品名称、配料、生产商、产地和生产日期等用于描述该商品相关的信息。通过利用这一技术,可以将商品进行快速分类,并将不合格的产品分离出来。通过应用字符识别技术,不仅可以提高信息的精准度,同时也极大的降低了人力成本[1]。
一、字符检测
文本检测是图像信息分析和提取过程中的重要技术,其关键在于如何区分和定位复杂的文本区域和背景区域。传统的图像文本检测主要利用人工设计特征检测图像中的文本,传统的字符检测需要经过图像预处理、字符定位、字符分割、字符识别操作完成[2],如图1。
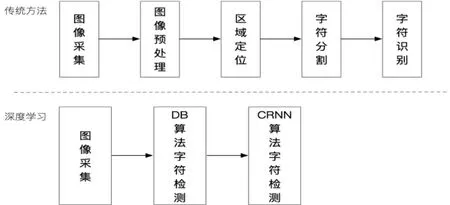
图1 字符识别方法对比
工业商品标签检测属于复杂场景下的文本检测,不同的商品包装上包含不同尺寸、颜色、形状、对比度的标签文本,并且商品标签的背景相较于印刷文档更加复杂,传统的文本检测方法受到人工设计特征的局限性,难以满足复杂的食品标签文本检测需求。
通过使用深度学习技术,能够有效避免人工设计特征存在的局限性,目前已经广泛应用于目标检测领域。本文借鉴经典算法的思路,提出基于DB算法的文本检测方法,对于其检测结果使用基于CRNN的文本识别的方法。
(一)基于DB算法的文本检测。近年来,基于分割的方法被广泛应在场景文本检测领域,这使得字符识别过程中对各种形状(曲线、垂直、多向)具有较高的检测精度。可微二值化(Differentiable Binarization)是基于分割场景文本的字符检测[3]。其主要原理是使用分割方法生成的概率图转化为边界框和文本区域,其中包括二值化的后处理。二值化在字符识别中起到了非常关键的作用,而传统的通过设置固定的阈值的二值化操作难以适应复杂多变的检测场景。本文使用的DB算法是通过在分割网络中插入二值运算进行组合优化,最终实现了整个热图的自适应阈值,如图2。
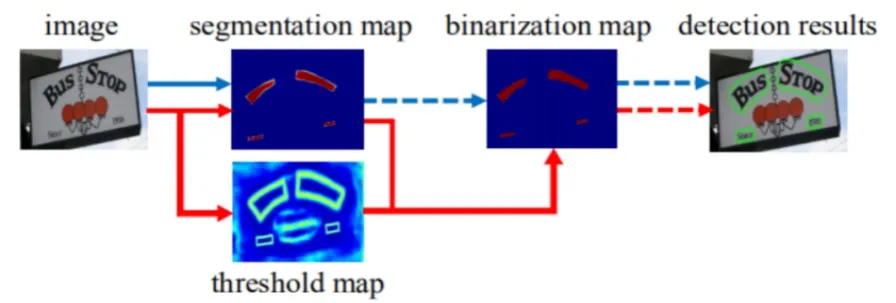
图2 DB算法网络结构
可微二值化的基本步骤为:首先提取输入图像的主干和特征;然后将图像传到特征金子塔,采集到相同尺寸的图片的同时进行特征关联;对采集得到的主干和特征进行分析,并计算出预测概率图(Probability map)和阈值图(Threshold map);最后根据预测概率图和阈值图得到最后的近似二值图,并生成文本边缘框。因为标准的二值处理是不可微的,而且在训练过程中分割网络不能得到优化[4]。所以使用可微二值,用于更好的计算反转值。
在训练阶段,通过得到二值化后的图片得到概率图,然后根据一个阈值推导出二值图,同时获得连接区域。最后,通过公式(1)的补偿计算,在样例区域通过膨胀再收缩得到文本框,如图3。


图3 产品信息检测
(二)基于CRNN算法的文本识别。早期的OCR(optical character recognition)算法是将单字分割后再进行识别的。如常见的车牌识别,先把车牌图片使用投影方法切割出单个字体,再送入SVM(support vector machine)或者CNN(Convolutional Neural Networks)里完成文字分类。CRNN(Convolutional Recurrent Neural Network)算法是将识别任务转化为序列建模问题,避免了文字分割这一不必要的工作。它规避了输入图像尺度必须一致的限制,经过卷积层、循环层,输出阶段经过特定算法转录后,便完成了不限长文本识别任务[5]。如图4所示,CRNN模型的第一个层次是CNN层。卷积层的目的是提取特征图。CNN网络部分有7个卷积层、2个BN(Batch Normalization)层、4个最大池化层[6]。需要注意的是池化层的卷积核尺寸在长宽方向上不一致,最终导致输出长宽比例变化的不一致。

图4 CRNN网络结构
CRNN模型的第二个层次是RNN层。文本识别任务可建模成基于时序的字符序列识别问题,利用CTC(Connectionist Temporal Classification)损失函数实现字符位置的软对齐。LSTM(Long-Short Term Memory)的预测结果连接CTC层,去除冗余的字符,将CNN提取到的特征适配到RNN层合,并成最终的识别结果[7],如图5。

图5 生产编号识别
二、系统实现
(一)图像预处理。本文主要研究复杂环境下颜色信息的处理与识别,大致可分为图像处理与识别两步。图像预处理是是图像识别的基础,在不同的场景下,结合自己的算法和程序,通过设定和调节参数将图片进行一系列的处理,使该图片更宜于被识别[8]。图像处理主要包含:去噪处理、图像增强、彩色图像转变成灰度图、灰度图转化成二值图、边缘检测、分割和直方图匹配、轮廓匹配。图像预处理的主要的任务就是弱化图像中多余的干扰信息,增强图像中所要识别信息的局部或者全部的特征,扩大图像中不同信息的特征差别。通过改善图像质量、丰富信息量,加强对图像后续的识别效果[9]。
1.图像预处理。由于摄像机采集到的图像都是彩色的,识别过程中需要对图片的R、G、B三个通道依次处理,这会对识别速度有很大的影响[10]。所以我们需要对图片进行灰度化处理。图像的灰度化可以大大减少图像中所包含的信息,并且计算量也会大大减少,有利于后续的运算和计算。根据不同颜色的重要性和其他的一些不同的指标,对R、G、B三个分量进行加权平均,如公式(2)。根据公式对彩色图片灰度化处理,得到合理的灰度图像,如图6。
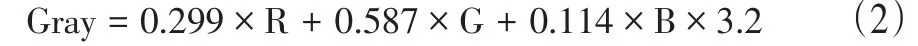

图6 图像灰度化
2.二值化。大津法(OTSU)又称最大类间方差法或最小类内方差法,即二值化图像阈值的选取。将彩色图片上的像素点的灰度值设为0或255,使图片背景和目标一分为二,呈现出明显的黑白效果,如图7。按照图像的灰度特效,二值化后的前景与目标会产生一个类间方差值,即二值化的过程需要取的一个阈值[11]。当图片背景和目标错分时,会使两部分的差别减小,从而导致错分概率变大。如公式(3),记H为图像的总平均灰度,a为目标文字、h为平均灰度值。

由式(2)可见公式中a1表示目标文字所占图像的比例;a1=1-a0为图片背景点数占比;h0表示w0对应的平均灰度值;h1表示w1对应平均灰度值。当方差N最大时,被处理图片中的目标和背景被错分的概率最小,此时的得到的灰度值为最佳阈值[12],方差N可由式(4)表示。
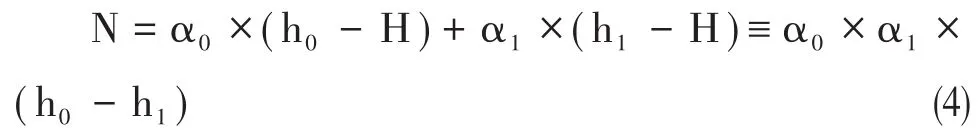
(二)标签检测与识别。经过图像预处理的操作后,如图8。经过通过灰度化和二值化后的图片可以更好的被DB文本检测算法和CRNN文本识别算法更好的被识别出来,可以大大提高识别和检测效率。然后使用预先编写好的程序进行文字识别:首先打开处理好的图片;用鼠标标记好要识别的区域,点击确定后系统开始进行文字的提取和识别;识别结束后,将识别的字符打印到控制台;最后可以在指定区域输入要识别的文字与系统识别的字符进行对比判断。经过以上步骤,识别成功或失败都将给出相应提示。
三、结果分析
(一)实验步骤与环境。本字符识别软件采用Python、OpenCV.js和Pyqt5进行编写,并实现了字符检测的可视化操作。实验使用的电脑配置为:英特尔i9处理器、16g运行内存和Nvidia GTX2080ti显卡。图像采集装置,如图9。

图9 图像采集装置
实验共分为:图像采集、图像预处理、划分识别区域、字符分割和字符识别5个步骤,如图10。将需要标签识别的物品放到图像采集装置上。当传感器感应到物品,相机就会进行拍照并将图像传到软件进行预处理;用鼠标选择好识别区域,并输入要检测的字符。系统自动会对被标记的识别区域进行字符分割和识别;最后将识别结果与输入的字符进行对比,把匹配和不匹配的图片分别存入到2个不同的文件夹内。
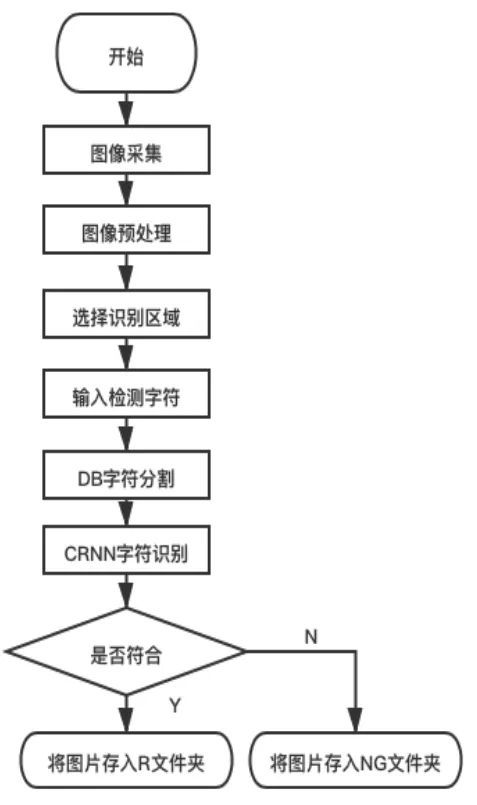
图10 实验流程
(二)实验数据分析。如表1中记录了10个不同的商品标签的检测结果。每个标签都有着不同的背景和不同的字符,并且全部在相同的灯照条件下进行检测。通过上述实验步骤进行识别,并分别记录其识别时间和字符识别准确率。经过分析与对比,本组实验的平均识别准确率为98.78%,平均识别时间为903ms。通过使用基于深度学习的字符检测方法,检测速率和识别准确率都有着极好的表现。通过对算法进一步优化和训练,识别的速率和准确率还会进一步提升,并且可以在更多复杂的环境中进行字符的检测与识别。
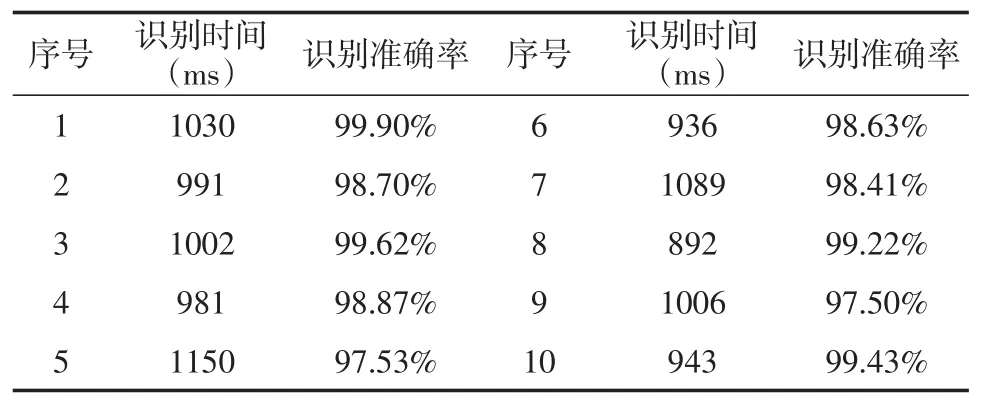
表1 识别数据结果
四、结论
通过使用基于深度学习的文本检测方法,即通过将DB文本检测算法对图片进行可微二值化处理,再利用CRNN文本识别算法进行字符检测。实验过程中,在不同光照和遮挡条件、都有着较好的表现。并且针对不同的形状、方向和颜色的文字都有着较高的识别准确率。与传统的字符识别算法相比,本实验使用的算法不仅可以应用到更多的场景,而且克服了多种字符形态上的限制。经过大量的实验与测试,DB算法和CRNN算法具有良好的稳定性和扩展性。通过将这两种算法相结合,文本检测的准确率和识别速度都有着明显的提升。
