CiteRank算法在文献多指标排序中的应用
2021-09-01杨赛军
张 勇 杨赛军 黄 华
(1.中国科学技术信息研究所,北京 100038;2.北京万方数据股份有限公司,北京 100038)
0 引言
信息检索系统能够帮助文献查阅者快速查找目标文献,检索系统在收到用户的检索请求时,根据用户输入的检索词,使用倒排索引技术查找到所有符合用户检索语句的文献,然后使用预先设定的指标对这些文献计算分值并排序返回。面对用户不同的文献搜索需求,检索系统需要结合引证关系、时间因子、实时热度等各类指标,计算出每一篇文献的分值,对命中文献进行实时排序。具体指标包括出版时间、被引用次数、相关度、下载次数等。搜索引擎按照一定的规则对文献进行排序,以帮助用户精准发现所需的文献。
万方数据的搜索引擎收录有近3 亿篇的文献,包含中外文期刊、学位、会议、专利等,如果仅使用PageRank值进行排序,不是所有文献都能找到引证关系,尤其是新文献,因此无法有效计算PageRank值。如何使用更有效的评分指标对海量文献进行排序,满足用户搜索文献需求,已成为万方数据搜索引擎首要解决的问题。本文研究了基于引证关系的PageRank算法和引入时间衰减因子的CiteRank算法,同时加入其他归一化的指标,包括出版年份、下载次数等,对文献进行评分,以提升新文献和热门文献被阅读的概率。
经典的文献排序算法包括PageRank和CiteRank。PageRank算法的核心是PageRank值,假设用户在浏览网页时,会随着这篇网页的链接引导一直点击进入下一层引用的页面,直到完成浏览关闭页面、或随机打开了一个新的网页。这里有两个假设:数量假设和质量假设[1]。数量假设是指在网页链接图模型中,一个页面节点接收到的其他网页被指向的入度数量越多,则这个页面就会越重要;质量假设是指页面的入度质量不同,质量高的页面会通过链接向其他页面传递更多的权重。基于以上两个假设,PageRank算法起初为网页分配相同的重要性得分,使用递归计算方法去更新各页面的PageRank值,直到该值达到稳定的状态为止。搜索引擎对于不同的查询语句,召回候选页面,优先排序PageRank值高的页面。某一个页面i的PageRank值计算公式如下:

在式(1)中,PR(pi) 表示页面pi的PR值,C(pk)表示引用页面pj链出的页面总数,d为阻尼因子。
在使用PageRank算法通过引证关系计算文献分值的时候,有以下两个特点:一是网页链接可以是双向的,而引证关系是单向的,在时间上只能是后发表的文献引用先发表的文献;二是网页链接是动态的,而引文是静态的,文献的引证关系在发布后不再改变。对于发布时间久远的文献,被引次数往往大于新发表的文献。在评估新文献价值方面,孙泽锋等[2]提出了一种改进的文献排序算法,结合PageRank思想以及常用的被引量,并将出版时间作为阻尼因子,使得新文献和旧文献在价值评估时分别有不同的权重。张光前等[3]使用阅读价值衡量一篇文献的重要程度,阅读价值由文献所在期刊、文献作者、文献内容等的重要程度决定。刘松涛[4]提出了一种使用相关强度对引文进行排序的方法,用于对学术期刊文献的引用和被引用关系进行定量分析。
文献检索系统根据用户输入的查询语句,在索引中查询文献,并根据预设的评价指标对查询到的文献进行统一排序。在实际应用中,有的用户更关注新文献和热门文献,而基于PageRank的文献排序算法,更适用于发现年代久的文献,在发现新文献和热门文献方面不占优势。CiteRank算法改善了PageRank的这种局限性,在计算文献权重时引入了时间因素。其计算原理是,对于一个更合理的模型应该是优先从最近的文献开始浏览,并通过引用链接逐步浏览发布时间越来越久的文献。
本文研究了一种多指标混合排序模型,将搜索结果文献相关度得分和PageRank、CiteRank、出版时间、下载次数等指标进行归一化处理,并分配不同的权重,从而对命中文献进行混合排序,使得搜索结果更契合用户的需求。
1 研究方法
本文首先研究了引入时间衰减因子的CiteRank算法对于提升新文献被访问概率的可行性,然后提出使用TF-IDF为命中文献进行相关度评分的方法,最后提出一种基于CiteRank值、文献相关度、下载次数等指标的混合排序算法。
1.1 文献的CiteRank计算
CiteRank模型中定义了两个参数Tdir和α。Tdir是文献的特征衰减时间,即某一学科领域的热度衰减;α是每一次浏览后满意并退出的概率。那么每次不满意并点击引用链接的概率是1-α[5]。
CiteRank模型的转移矩阵如下:

表示文献j的被引用次数。用ρi表示最开始时选择文献i的概率:,通过初步选择可发现文献的概率为,点击该文献的引用链接发现文献的概率为:(1 − α)W·。
CiteRank可用式(3)计算得出:

t年前的一篇文献的CiteRank为Ttot(t),它主要由以下两部分组成:
一是直接的(direct)访问Tdir(t),表示t年前所有文献的初始选择为:

二是间接的(indirect)访问Tind(t),既通过引用列表点击跳转的访问:

表明进入t年前的文献的链接可以来自所有可能的中间时间的文献。Pc(t′,t) 表示从t′年前文献中引用t年前文献的比例,这是一个经验值[2],它可以被近似为
对Ttot(t)=Tdir(t)+Tind(t)进行傅利叶变换可以得到式(6):

解析Ttot(ω)并进行傅利叶反变换得到式(7):

从式(7)中可以得出,对于大的α,小的τdir表示最新的文献会被更大的概率访问;对于小的α,大的τdir表示会相应提高旧文献的访问量。
1.2 文献相关度得分
文献相关度得分是评价搜索结果与查询语句匹配程度的重要指标。搜索引擎根据查询语句与命中文献的匹配程度计算相关度得分,但并不是所有的文献都包含查询语句中的词,并且每个词的重要程度不同,因此一个文献的相关度评分取决于每个查询语句在文献中的权重[6]。
万方数据的文献在索引过程中使用了倒排序索引技术[7],搜索引擎使用布尔模型(Boolean model)查找与输入词条相匹配的文献,并用TF/IDF(term frequency/inverse document frequency)公式来计算文献相关度得分。搜索引擎使用TF表示词条t在文献d中出现的频率,即。如果词或短句在某一篇文献中出现的频率比较高,并且在其他文献中很少出现,则可以认为该词或者短句具备很好的类别区分能力,适用于解决分类问题,一些通用的词语对于文献主题并没有太大的作用,反倒是一些出现频率非常少的词才能够更多地表达文献的主题,所以仅仅使用词频是不合适的。因此在计算文献相关度得分时,必须考虑词的权重。一个词预测主题的能力越强,则权重越大;反之,权重越小。
在倒排序索引中,如果文献的一些词只是在少数几篇文献中出现,那么这些词对文献主题的贡献作用会很大,这些词和短句的权重应该被设计得大一些。IDF就是词的权重,即,此时IDF为逆向文献频率(inverse document frequency),如果包含词条t的文献少,则IDF会越大,表明词条t具有非常好的类别区分能力。如果一些文献中含有词条t的文献数量为m,而其他文献中含有词条t的文献数量为k,那么可以得出所有包含t的文献数量为n = m + k。当m越大时,n也会越大,按照IDF公式得到的IDF值就会越小,说明该词条t的区分类别的能力不强。但是在实际情况中,如果一个词条或短句在一个类别的文献中经常出现,则可以说明这个词条能够很好地表示这个类别的文本特征,这些词条应该被赋予更高的权重,并用来作为该类别文本的特征词,用以区别于其他类别的文献。
在给定的文献里,词频(term frequency,TF)表示的是某一个给定的词语或短句在该文献中出现的频率。这个数值是对词数量的(term count)归一化,用于防止该值偏向比较文字较多的文献。但是在实际使用过程中,会根据不同的命中属性(标题、摘要、关键词)预先设计不同的权重wz。如标题命中时权重会更高,摘要则会赋予相对低一些的权重。因此,可得词i命中文献j的z字段时分值为式(8):

文献的相关度得分Sr即为所有词在文献所有字段中的分值之和Sr=∑Si,z
1.3 混合排序原理
文献的最终分值将由相关度得分Sr、Cite-Rank分值Sc、下载次数Sp等指标乘以相应的权重得出。

其中,Sc为Ttot(t)归一化后的结果,下载次数Sp可以在文献进入索引库时预先计算为0 到100 之间的值,这两个指标根据数据进入索引的周期,会定期进行更新。这种预先计算分值的方式,可以避免在排序时进行大量的实时计算,使用存储空间换取计算时间,节省了大量的计算资源,提升了排序性能。在用户使用搜索引擎时,输入检索词,检索集群会为数百万命中文献进行排序。为了有效节省内存资源,将排序时的资源消耗限定在合理的范围内,搜索引擎只在内存中保存分值最大的N个值(top N)。
2 实验
2.1 数据集
本文以万方数据收录的文献和2020年被下载数据作为实验数据,对混合排序算法进行验证,文献数据集合符合标准定义[8],包含标题、摘要、关键词、刊物收录情况、作者、作者单位等字段[9],以及文献的引证关系[10]。本文在计算CiteRank时,使用了不同的α和τdir来预测文献被访问到的概率,并由此比对了PageRank和CiteRank分值的区别。最后基于万方数据的用户搜索行为日志,分析使用混合排序前后,用户对搜索结果前三条的点击率变化,来验证混合排序算法的有效性。
2.2 CiteRank参数估计
使用公式(7)可以计算各出版年份下文献被访问到的概率,本文使用了3 组不同的τdir和α参数进行计算,对比结果如图1所示,x轴表示文献发布年份与2020年之间的差距,数字越小表示文献越新。由数据结果可以得出:对于小的τdir,大的α,表示最新的文献相比旧的文献有更高的概率被访问到;对于大的τdir,小的α,表示则会相应提高旧文献被访问的概率。为了契合部分用户访问新文献的需求,万方数据使用了CiteRank作为文献排序的一个指标。通过对比3组参数的计算结果,本文选择τdir=2.1,α=0.7 作为计算CiteRank时的参数,从而可以做到以更大的概率将较新的文献排在前面。

图1 α和τdir参数模拟各年份文献被访问的概率
2.3 CiteRank和PageRank对比
本文选择使用万方数据收录的2000年至2020年文献元数据和这些文献之间的引用关系作为数据集,分别计算每一篇文献的PageRank和CiteRank值。表1截取了部分近5年的数据,包含典型的权威文献和流行文献,对比了同一篇文献的CiteRank和PageRank。由于PageRank值在计算过程中仅使用文献之间的引用关系,体现了文献之间权重的贡献值,反映了文献的经典权威程度;而CiteRank为文献的贡献关系加入了出版时间作为衰减因子,出版时间越久远的文献获得的贡献值越少,反之则会获得更大的贡献值,从而反映了文献的流行度。
表1中文献按照CiteRank值从高到低进行排序,文献1 和文献2 的发布年份大于2019,被引数分别为360 和556,文献3 的年份为2015年,被引数为4 832,虽然文献3 的被引次数远远大于文献1 和文献2,但是根据CiteRank算法特性,年份相对久远的文献获得的贡献会根据年份进行相应的衰减,所以文献3 的CiteRank值会低于文献1 和文献2。对于文献的PageRank值,文献3、文献9、文献10 被引数最高,PageRank值也是最高,仅仅反映了的文献的被引关系。从表1得出,PageRank可以用于经典文献优先排序,优先列出权威的文献(不考虑出版年份),CiteRank则可以用于新文献优先排序(默认排序),优先列出新的文献(考虑出版年份)。
2.4 历年出版文献被访问次数
本文统计了各出版年的文献在2020年被访问次数。数据显示,用户更倾向于选择访问新的文献,这与万方数据选择使用CiteRank作为默认的排序指标相符合,使用CiteRank可以为用户提供偏向新文献的排序结果,如图2所示。
2.5 使用混合排序前后点击率对比
本文使用单一指标排序和混合指标排序两种场景下10 天内用户对搜索结果的点击行为数据进行分析。分别统计出两种排序场景下用户点击搜索结果的总点击数,以及点击前三条结果的点击数(top 3 点击数),从而计算出点击率(top 3点击数/总点击数)。表2显示了这两种排序场景下的数据对比,可以得出混合排序算法能显著提升用户点击排序结果top 3 文献的几率,该算法在搜索引擎中更加契合用户默认的文献搜索需求。
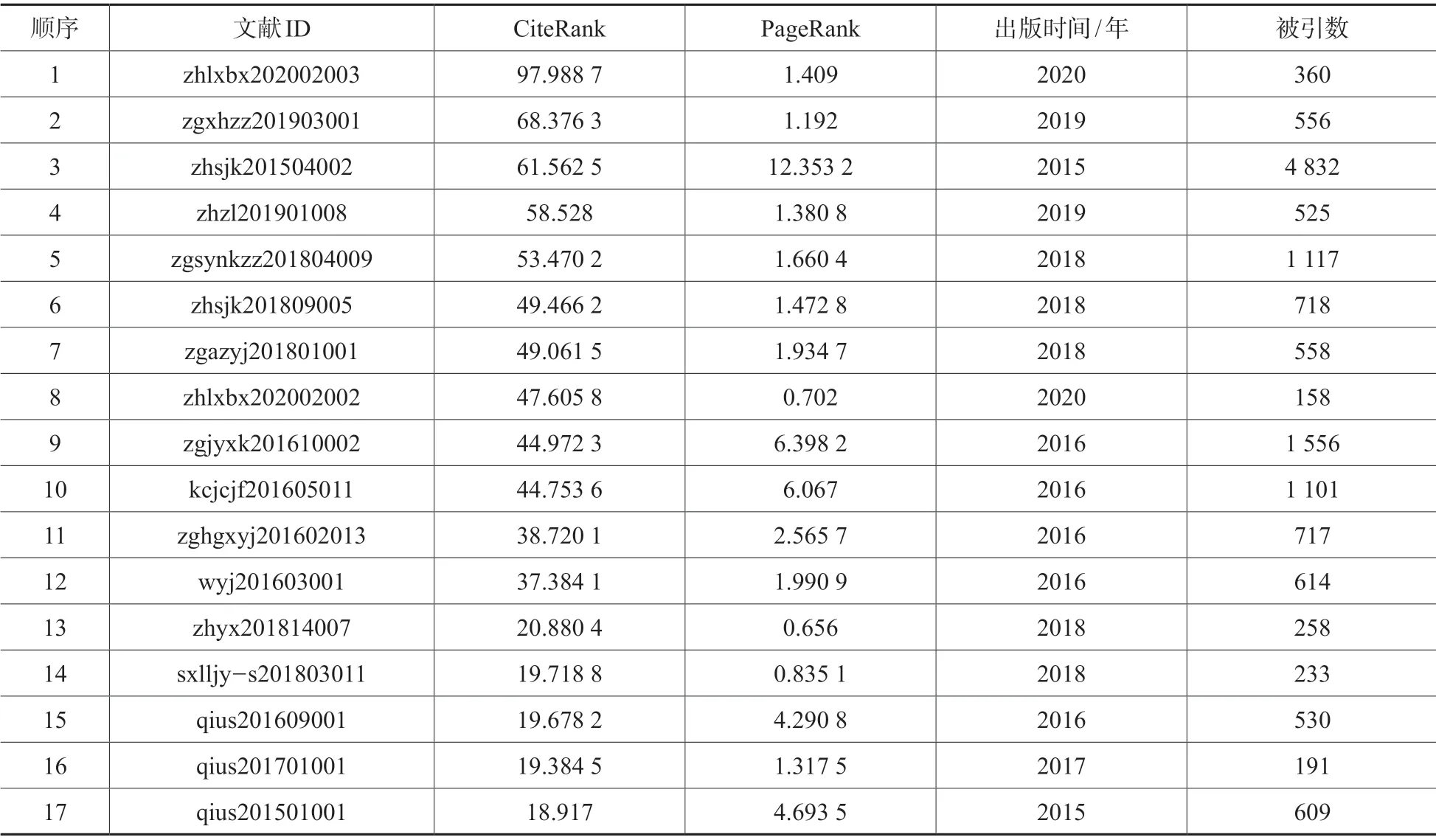
表1 PageRank值和CiteRank值对比

图2 历年文献在2020年被下载次数统计

表2 各排序场景下用户点击率对比
3 研究结论
万方数据搜索引擎中收录有近3 亿篇的文献,单纯地使用PageRank或CiteRank对文献进行排序,会导致权重倾向于单一的指标,不能精准地契合大数据环境下用户对新文献和热门文献的搜索需求。本文研究了基于CiteRank的混合排序算法,引入出版时间、下载次数等归一化指标进行加权平均。实验结果表明,混合排序算法能够提升新文献和热门文献在排序上的优势。最后通过分析用户的搜索行为数据,进一步验证了在搜索引擎中应用基于CiteRank的混合排序算法更能契合用户搜索文献的需求。
