基于深度学习的矿井下作业人员安全帽佩戴检测
2021-09-01石永恒杨超宇
石永恒 杨超宇
(安徽理工大学经济与管理学院 安徽淮南 232001)
煤矿员工在矿井下进行生产作业时,佩戴安全帽是有效保护员工生命安全、有效降低事故危害的防护措施;但根据近年来所发生的种种煤矿安全事故来看,由于未佩戴安全帽行为导致事故危害升级的案例屡见不鲜;因此,对煤矿员工安全帽佩戴进行检测十分重要。目前来看,煤矿企业中对于是否佩戴安全帽的检查方式主要包括两种:一是通过对监控视频的回放查看,发现作业人员未佩戴安全帽的违规行为;二是通过人工实时检查的方式,发现未佩戴安全帽的违规行为。但上述两种检测方式存在滞后性和低效性的问题,并不能在事故发生前及时消除安全隐患;因此,运用深度学习的方法对煤矿员工的安全帽佩戴情况进行实时检测具有十分重要的现实意义和实用价值。
传统的目标检测都是通过手工设计特征来实现对目标对象的检测,这就导致了在进行实际的目标检测时,出现目标检测准确率低的问题且模型的泛化性较差,不具备鲁棒性。近年来,随着卷积神经网络(CNN)的提出,使得深度学习在进行特征提取时有效地解决了手工设计特征的缺陷。基于此,一些学者提出了一系列的基于深度学习的目标检测算法。Girshick等[1]在2014年提出了R-CNN(区域卷积神经网络)算法,采用Region Proposal(候选区域)方法实现目标检测问题,代替了传统目标检测方法中手工设计特征的方式,使得基于深度学习进行目标检测的方法获得了巨大进步。随后,Girshick[2]和Ren等[3]在2015年进一步提出了Fast RCNN和Faster R-CNN算法,在提高检测率的同时也提高了检测速度,同时Faster R-CNN的提出算是真正实现了网络的端到端训练。Redmon J等[4]在2015年提出了YOLO v1算法,进一步提高了目标检测的速度,并且能够对视频进行目标检测。W Liu等[5]在2016年提出了SSD(Single Shot MultiBox Detector)算法,SSD相较于YOLO v1来说有着更好的表现,在保持较快运行速度的同时,在检测精度方面能够达到两阶段目标检测算法的水平。同年,Redmon相继提出了YOLO v2[6]和YOLO v3[7]检测算法,显然YOLO v3对目标检测的效果更佳,根据作者所述,YOLO v3在COCO数据集上的实验表现为51 ms时间内mAP达到57.9%,与RetinaNet在198 ms时间内mAP达到57.5%相当,在速度提高了近3.8倍的基础上还保持了相似的精度,由此显示了YOLO v3在深度学习目标检测算法中,具有较好的检测速率和检测准确率。
而针对安全帽佩戴这一目标检测问题,国内也有越来越多的学者进行深入研究。刘晓慧等[8]在2014年运用肤色检测和Hu矩的方法进行安全帽佩戴识别。施辉等[9]在2019年以YOLO v3算法为基础,结合图像金字塔的多尺度特征获取,进而构建了一种改进YOLO v3算法的安全帽佩戴检测方法。徐先峰等[10]在2020年利用MobileNet网络结构代替SSD算法中的VGG网络结构,形成一种改进SSD算法的安全帽佩戴检测方法。近两年,国内逐渐开始有学者利用深度学习的方法进行安全帽佩戴检测研究,但是很少有针对煤矿员工安全帽佩戴检测的研究。主要是因为煤矿井下作业的环境较为复杂,井下监控视频数据质量不高。
本文主要以煤矿井下监控视频数据为基础,对视频数据进行相应地预处理,制作形成训练数据集;使用YOLO v3算法进行数据集的训练,以获取能够满足煤矿井下环境需求的安全帽检测模型;通过实验结果表明,本文所使用的算法能够在实验精度以及实验速率上满足现实需求。
一、YOLO v3算法原理
(一)算法网络结构。YOLO v3算法是一种单阶段目标检测算法,它的网络结构如下图1所示。YOLO v3算法融合了FPN(特征图金字塔网络)网络结构、残差网络等创新思想,使得整个网络具有较好的识别速度和准确度。YOLO v3算法使用DarkNet-53网络实现对目标的特征提取,该网络由53个卷积层构成,包含一系列的3×3和1×1的卷积层,并借鉴了ResNet网络中的残差思想。DarkNet-53网络中的残差组件如下图2所示,每个残差组件有两个卷积层和一个快捷链路;先通过步长为2的3×3卷积,获得特征层x,随后通过一次1×1的卷积使得通道数缩减为原先的一半,之后再经过3×3的卷积加强目标特征的提取并使得通道数重新扩充,获得Fx,最后利用残差组件将Fx和x进行堆叠,DarkNet-53网络使用残差的跳层连接,有效的降低了池化带来的梯度负面效果。
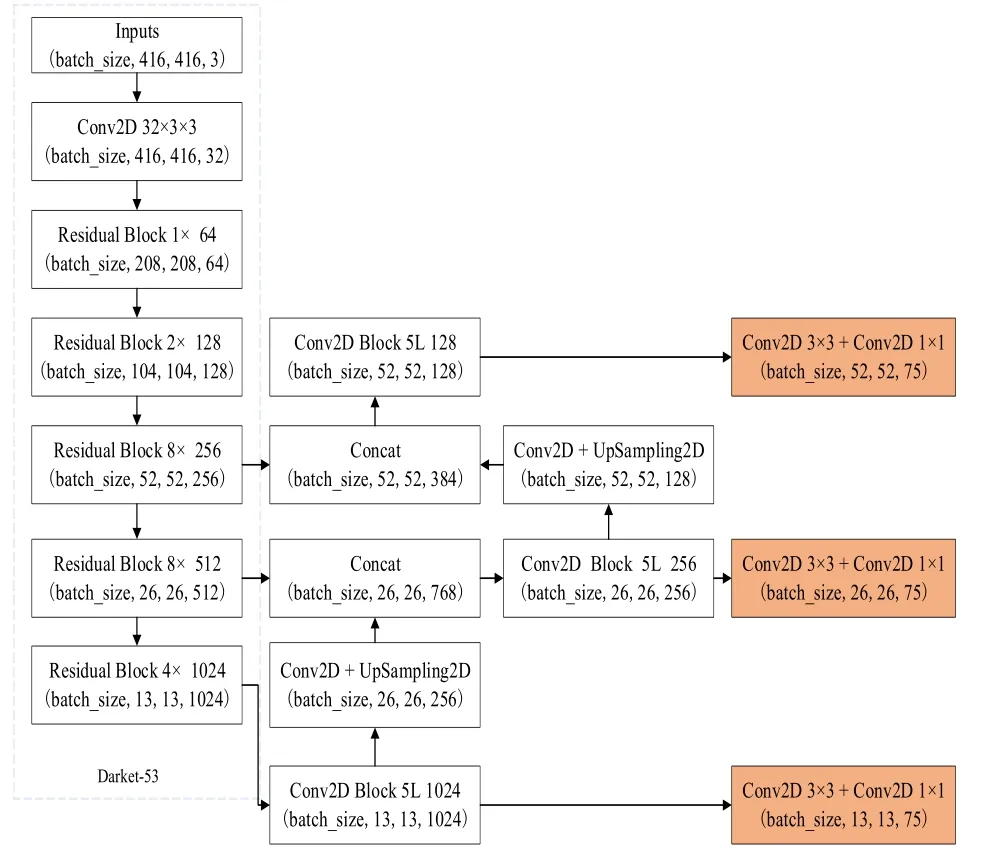
图1 YOLO v3网络结构
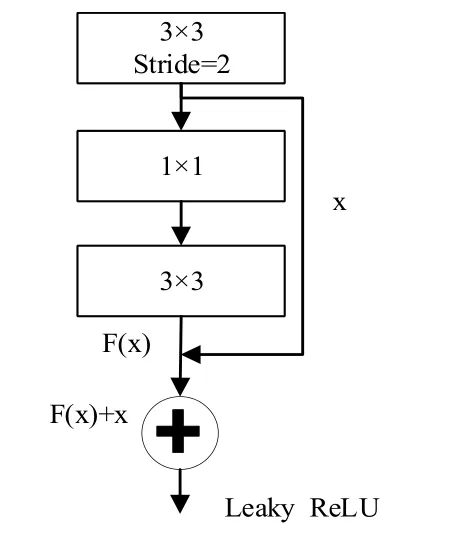
图2 Darket-53网络中的残差单元
(二)边框预测及选择。
1.边框预测。对于检测目标的边界框预测,YOLO v3算法沿用了之前YOLO算法中所采用的维度聚类的方式固定锚框(anchor box)来选定边界框;通过K-means聚类获得3种不同尺度的先验框,对于每个预测边框会通过算法中的神经网络预测出边框的坐标信息,预测边界框的坐标计算方式如下:
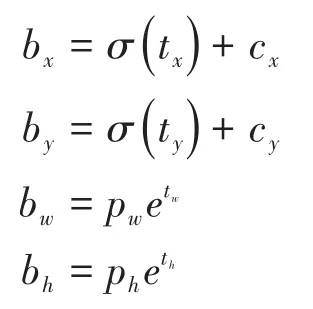
式中bx、by为预测边界框的中心点坐标,bw、bh为预测边界框的宽度和高度;cx、cy为网格距离图像左上角的边距;tx、ty、tw、th为算法学习的目标;pw、ph为预先设定的锚框维度。
对于预测边界框中的类预测,YOLO v3算法每个框使用多标签分类来预测边界框可能包含的类,并且不再使用Softmax的方式进行分类,而是使用独立的逻辑分类器;在算法训练过程中,通过二元交叉熵损失的方式进行类别预测,通过多标签的方法可以更好地模拟数据。
2.IoU及NMS(非极大值抑制)。IoU即预测框与真实框的交并比,用来反应预测框与真实框的重合度,即:

IoU值越大说明预测框与真实框的重合度越高,则预测框就能更好地反应出真实框内的信息,对目标检测的准确度就会越高。在边界框之后,每个预测边界框会产生一个置信度(Confidence值),这个值反应了预测的边框内含有检测目标的置信度,置信度的表达式如下:
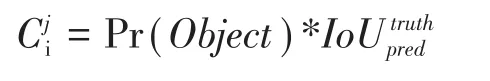
式中Pr(object)是判断是否有检测目标包含在网格内,表示预测框与真实框的交并比值,其中值越高则表明所预测的边界框内含有检测目标且位置准确。
在YOLO v3算法中,在预处理及训练过程中会产生多个预测框,因此算法会根据每个预测框与真实框的IoU值的大小,通过NMS算法来最终确定一个与真实框重合度最高的预测边界框。首先针对所有预测边框,将置信度低于设定阈值的预测框剔除掉,针对同类检测目标每次选取置信度最大的Bounding Box,然后从剩下的BBox中与选取的BBox重合度较高(即IoU值较高)的预测框,这些与选取的边界框有着较高重合度的预测框将会被抑制(即剔除)。通过这种方式选取出来的BBox会被保留下来,并且不会在下一次的选取中出现;接着开始下一轮,重复上述过程;选取置信度最大BBox,抑制高重合度的BBox。采用这种方式,最终对于同一个检测目标,最终只会保留一个置信度最高的边框,不会出现同一目标进行多次检测的重复行为,从而提高检测速率。
(三)损失函数。YOLO v3算法的损失函数一共包含四个方面,分别是中心坐标误差、宽高坐标误差、预测边界框的置信度误差和分类误差,损失函数计算方式如下:
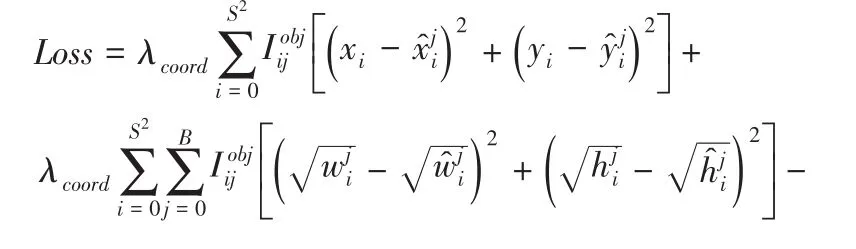

式中第一项、第二项的中心坐标误差和宽高误差坐标反应了预测边界框的坐标误差情况;第三项、第四项表示预测边界框的置信度,反映了预测边框内含有检测目标的情况;第五项反映了对检测目标的分类情况。
二、实验流程及结果分析
本文在Linux系统上搭建实验平台,使用NVIDIA GeForce GTX 1660Ti用于GPU加速,实验环境为CUDA10.1+CUDNN7.6,本实验在PyTorch1.6.0深度学习框架下对模型进行训练及测试。
(一)数据集制作。本文主要是针对煤矿员工安全帽的佩戴检测,故采用煤矿井下作业现场监控视频作为数据来源;利用OpenCV4.4.0版本开发库将所采集的视频数据转换为图片格式的数据,再经过进一步的图片筛选共获得了6892张有效图片数据,数据集包括佩戴安全帽的作业人员和未佩戴安全帽的作业人员两类,自建数据集能够较好地反映出煤矿井下作业的真实环境。
1.数据集标记。本文根据的实验需要,在制作数据集过程中使用LabelImg标注工具,进行数据集的标注工作,所标注的数据集类别分为戴安全帽和未戴安全帽两类;在进行数据集标注时,根据实验需求对数据集中的对象进行有效标注,标注工具自动生成相应的配置文件,以数据集中的一张图片标注为例,展示如下图3所示。

图3 数据集标注图例
2.数据集划分及数据预处理。为了确保训练模型的合理性,本文按照9:1的比例,将数据集划分为训练集和测试集两部分。为了将自建数据集转化为适用于YOLO v3识别的数据格式,需要对自建数据集进行格式转换;同时,为了提升模型的收敛速度和模型的精度,对数据集进行归一化操作。
(二)模型训练及测试。由于所使用的数据集与YOLO v3原始数据集不同,因此,需配置实验所需的yolov3-helmet.cfg文件;更改学习率、批次大小等配置参数,使得YOLO v3网络能够有效的对模型进行训练。本文使用PyTorch版本的YOLO v3权重文件进行模型参数的训练。其中部分重要参数设定如下表1所示。

表1 模型训练部分参数设定
按照上表所示的参数设置,对模型进行训练,经过100次迭代后,获得相应的模型评价指标,以及一个最优模型权重,并进行模型测试。
(三)实验结果及分析。
1.实验结果分析。通过上述的实验过程,可以得到本文所使用的YOLO v3算法对自建的安全帽数据集的检测能够获得一个比较好的结果,具体的识别效果图见下图4所示:
根据图4-1可见本实验对于单目标简单环境下具有更好的识别效果,在多目标以及较复杂环境下精度稍低,但识别精度也处于较高的水平。

图4-1 单目标及多目标识别结果
根据图4-2能够反映出本文实验所获取的检测模型对于不佩戴安全帽的情形,也能够有着较好的检测效果。

图4-2 未佩戴安全帽检测结果
根据图4-3可见,本文实验所获的检测模型对存在一定干扰项的情况下(比如佩戴帽子等类似安全帽的情形),也能够获得较好的识别精度。由上示图例可以清晰的看出,本文所研究的安全帽佩戴检测方法,能够很好的满足实际的检测需求,在多目标以及存在干扰项等等情形下,都能够进行有效识别。

图4-3 存在干扰项的安全帽佩戴检测识别
2.与其它算法对比实验。为了更好的体现本文所使用的YOLO v3算法在安全帽识别上的表现,使用其它单阶段检测算法进行对比试验,具体的实验对比见下表2所示。
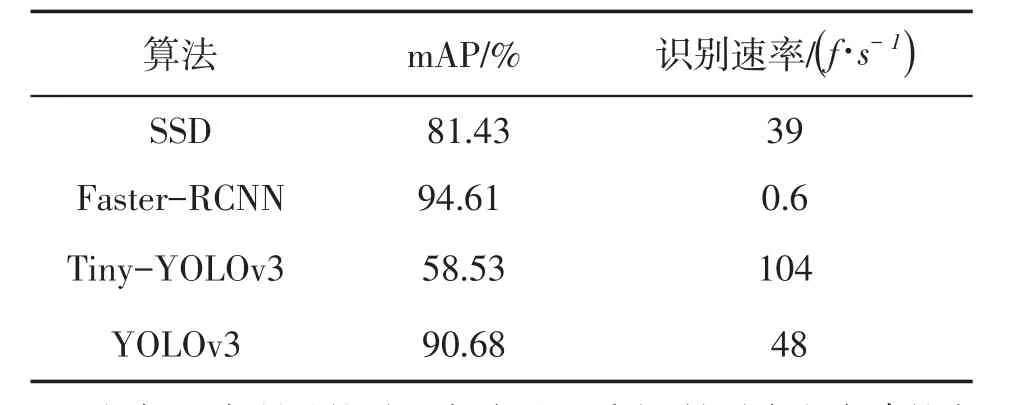
表2 不同算法实验结果对比表
根据上表所示的对比实验可以看出,针对本文自建的安全帽佩戴检测数据集的检测来说,本文所使用的YOLO v3算法,相较于其他目标检测算法来说,具有更加优越的检测性能,虽然在检测精度上低于Faster-RCNN,但是在检测速率方面本文算法更能满足对实时视频流的检测需求,更加适合实际环境中的检测任务。
三、结语
本文使用YOLO v3算法作为安全帽检测的基础,通过对煤矿井下数据的训练,获得一个较稳定的模型,能够对井下的作业人员的安全帽佩戴情况进行有效检测,实验所取得的检测精度以及算法的检测速率均能满足实际的需求,能够对实时的视频流进行有效检测;但是,算法还存在一定的不足之处,对于较小目标的检测还存在一定的问题,因此下一步需要在现在的基础上对算法进行有效改进,完善算法对较小目标的检测功能。
