融合多维度信息的中文事件时序关系识别方法
2021-08-31李婧李培峰朱巧明
李婧,李培峰,朱巧明
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
0 引言
事件时序关系识别是关系抽取中的一个子任务,目的在于判别两个目标事件在时间上的发生顺序(例如:前(BEFORE)和后(AFTER)等)。例如在句子S1 中,事件“卖出”发生在“凶杀案”之前,因此“卖出”和“凶杀案”的时序关系是“BEFORE”。
S1:而警方今天也找到了凶刀,来源是苗丽一家大卖场所卖出,证实这是一件预谋的凶杀案。
事件时序关系识别获得越来越多研究者的重视,该任务对叙述性文本中时间线的构造有很大帮助。另外,该任务对特定领域的相关研究工作也有帮助。例如在医疗领域中,根据某些疾病在不同时间不同程度的状态和变化可更准确地选择治疗方案。总之,事件时序关系识别可推动很多其他自然语言处理任务,如问答系统[1-2]、文本摘要[3]、文本蕴含[4-5]和知识图谱构建[6]。
随着深度学习的兴起,该任务的研究开始转向使用神经网络代替传统的特征学习方法,可不必依赖大量手工标注的特征。然而,由于多数相关的语料库中只标注了同句和邻句的事件时序关系,因此,在该任务中研究者们更多聚焦于同句和邻句中的时序关系研究,忽略了跨句间的事件时序关系。在同句和邻句时序关系研究中,基于两个事件触发词(Trigger,表示一个特定事件的核心词,一般用触发词来表示事件。事件时序关系识别可以映射到识别事件触发词之间的时序关系,如上例中的触发词“卖出”和“凶杀案”的时序关系)的最短依存路径(Shortest Dependency Path,SDP)被广泛用来表征事件句,并用于时序关系识别。然而,跨句的事件之间相隔较远的距离,句子内的句法信息失去了其连续性和传递性,仅仅通过SDP 进行跨句事件时序关系识别是远远不够的。跨句时序关系的识别更加依赖于句子本身的语义信息和事件发展的脉络。
由于语料库的限制,目前绝大多数有关事件时序关系识别方法研究的语言是英文,对中文事件时序关系识别的研究还处于起步阶段。相对英文句子结构严谨,中文由于是一种意合语言,表达方式多样化,缺省情况严重,句间连接词更少,使得中文时序关系识别更加具有挑战性。为此,本文将研究中文事件关系识别方法,研究对象包括同句、邻句和跨句的中文事件时序关系。
为了解决上述难点,本文提出一种融合多种信息的中文事件时序关系识别模型TRIMI(Chinese Event Temporal Relation Identification on Multi⁃di⁃mensional Information),从三个维度来获取更有效的事件语义信息:1)完整事件句的语义信息:保留完整的句子作为最底层模型的输入。为了更好地获得完整的语义信息,使用BERT⁃wwm 作为语义编码器;2)目标事件对属性信息:通过额外加入目标事件对的五种属性信息,与输入端的句子一起进行编码,从而获取潜在的、更丰富的语义信息;3)句法信息:在以上两种信息的基础上融合优化的SDP信息,利用交互信息优化同句事件时序关系的识别。使用上述三个维度的信息主要是因为事件时序关系识别需要依靠语义来判别,而在中文中,一些省略和隐晦的表达使得语义信息并不完整,因此使用句法信息和时间词本身的属性进一步丰富所需信息,有助于时序关系识别。在基于ACE2005 的中文时序语料库上的实验表明,本文方法的性能优于现有最好的方法。
1 相关工作
目前,多数事件时序关系语料库都是英文语料库,使用较多的有TimeBank[7]。该语料库标注了14种事件时序关系,但该语料库中事件时序关系的标注较为稀疏,在118 篇文档中仅标注了6 418 个时序关系。在此基础上,Cassidy 等人[8]提出了一种新的标注机制,将相邻句子中所提及事件的所有时序关系均标出。他们在TimeBank 的基础上标注了36 篇文档,有12 715 对时序关系。但是,该语料库和TimeBank 一样,也只有同句和邻句的时序关系。该语料库简化了时序关系的种类,从TimeBank 的14 种 关 系 简 化 为6 种。Do 等 人[9]在ACE2005 英 文语料库的基础上标注了一种由特定事件驱动的时序关系。该语料库规模较小,只标注了20 篇文档。但这是第一个具有跨句事件关系的时序关系语料库。
相比英文,中文时序关系语料库更少。Li 等人[10]创建了一个由700 多条句子组成的中文时序关系语料库。此外,在TempEval[5]中也包括了一个中文事件时序关系数据集,但也只标注了700 多个实例。这种小规模的语料库无法应用于机器学习的模型。Li 等人[11]在ACE2005 中文事件语料库的基础上,标注了一个由事件驱动、全连接的中文事件时序关系语料库。该语料库包含了同句、邻句和跨句的事件时序关系。而且,该语料库是一种全连接的语料库,每个文档中特定事件类型的所有事件两两之间都标注了时序关系,形成一个稠密型语料库。和Do 等人[9]一样,该语料库为了降低标注难度,将事件时序关系分成粗粒度的4 种,分别为:前(BEFORE)、后(AFTER)、交叉(OVERLAP)和未知(UNKNOWN)。
绝大多数的事件时序关系识别方法针对的语言是英文。传统方法主要是依赖于规则和特征构造的统计方法。Verhagen 等人[12]融合事件对的相关属性特征(如时态,极性等),使用最大熵分类器分类。词性和WordNet 中的上下位词语也被纳入相关特征。Do 等人[9]按照时间发生顺序把一个文档中的事件构成事件链,使用整数线性规划的方法进行全局优化。目前,神经网络方法在自然语言处理 任 务 中 表 现 出 色。Xu 等 人[13]使 用SDP 作 为LSTM 的输入获得实体间的关系。受其启发,Cheng 等人[14]将其应用到时序关系分类任务中,提出邻句虚拟根假说,将两条SDP 输入到Bi⁃LSTM进行时序关系分类。Ning 等人[15]通过添加外部概率信息增强分类效果。接着,Ning 等人[16]又将时序关系和因果关系相结合,同时改进两个任务的分类性能。Dai 等人[17]使用图卷积神经网络(GCN)促进最短依存路径上不同词之间的依存关系传递。Vashishtha 等人[18]使用ELMo 作为编码器,微调后应用注意力机制和感知机预测文档中两个连续句子中事件的开始和结束时间。
中文事件时序关系识别的研究工作较少。Cheng 等人[19]用动词属性识别动词间的时序关系。Li 等人[10]在一个小型中文语料库上通过协同概率决策树和朴素贝叶斯两种方法加强识别正确率。Li等人[12]在传统规则方法上融入时序关系特有的传递性和自反性等进行篇章级别的全局优化,分类效果得到较大提升。神经网络方法中,Wang 等人[20]基于SDP,使用Bi-LSTM 和交叉Attention 同时对中文和越南语进行事件时序关系抽取。
2 中文事件时序关系识别模型TRIMI
本文提出了一种融合多维度信息的中文事件时序关系分类模型TRIMI,模型的总体架构如图1所示。该模型不仅提高了同句时序关系分类效果,还对跨句的事件进行预测,解决了此前多种神经网络模型结构中的跨句无法识别问题。另外,通过将学习到的不同类别的信息进行融合,进一步提升了模型性能。
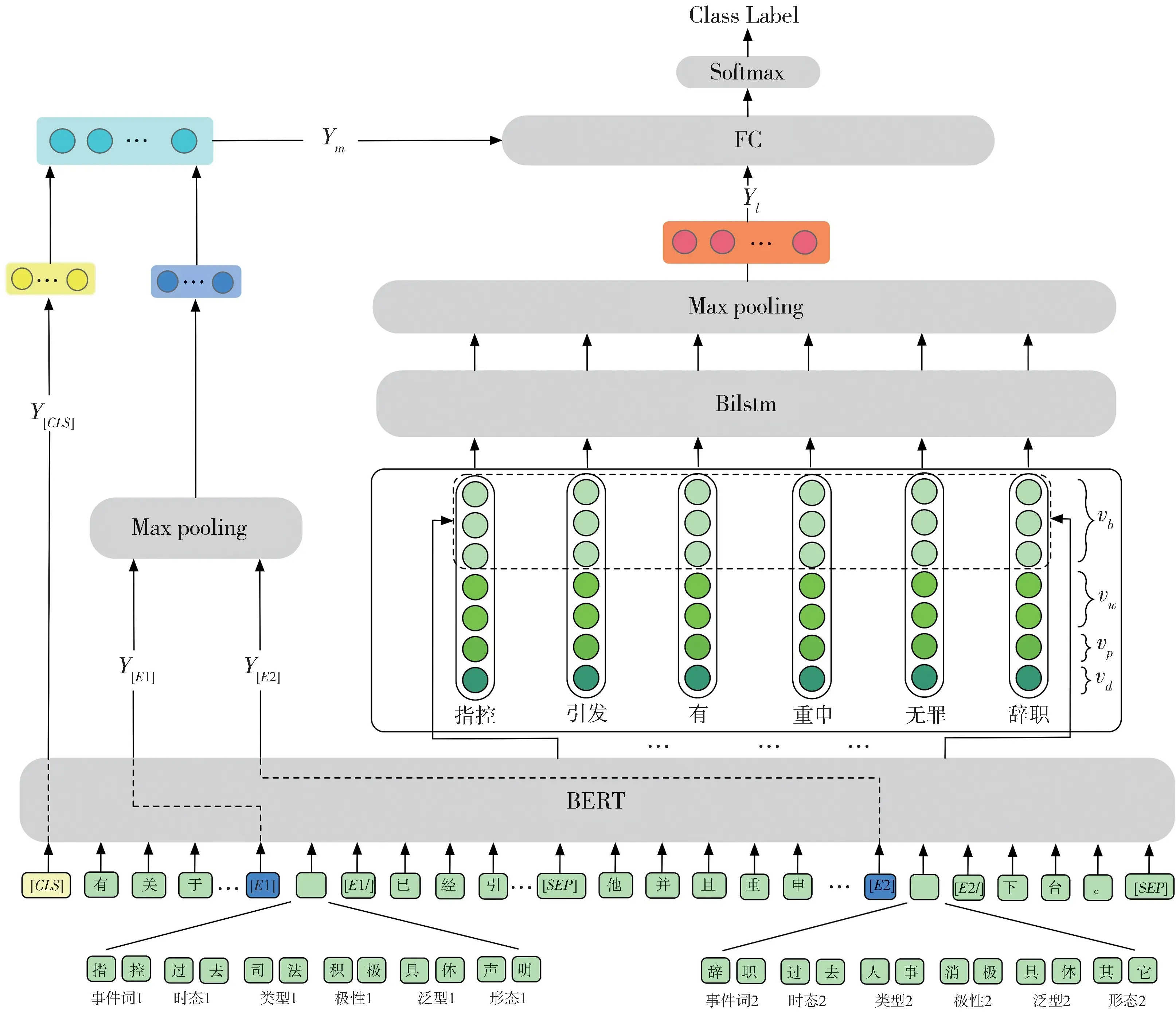
图1 模型的整体结构图Fig. 1 Overall structure of the model
该模型TRIMI 主要包含以下几层:(1)融合语义和事件对信息的编码层:将事件所在句子添加相关的事件标签并与事件对的一些属性信息拼接后输入到BERT-wmm 中进行编码,学习句子的语义信息和事件对属性相关的隐性信息。(2)基于联合最短依存路径的交互层:该层的输入主要有三部分:词语、词性、依存关系。词语的嵌入使用字符粒度和词粒度两种映射方式,其中,字符级别的映射取上层对应的编码输出。由于Bi-LSTM 可以捕获长期依赖关系的特性,本文将其作为本层的编码器,以获得两个事件所在句的句法信息。(3)多特征相结合的时序关系分类层:该层主要是将前两层学习到的相关语义信息,事件对属性信息,句法交互信息三者进行融合,再使用Softmax 对其进行时序关系的分类预测。下面将针对模型的相关层进行详细的说明。
2.1 融合语义信息和事件对特征的BERT 编码层
BERT[21]是谷歌提出的一种功能强大的预训练模型,使用双向Transformer[22]作为编码器,该模型在处理序列相关的任务上展现出了较优的性能。Cui 等人[23]针对中文对BERT 的预训练方式进行改进,使用全词覆盖(whole word)的方式来mask 序列中的词语,提出了BERT-wwm 模型,该模型在中文相关的任务上表现出了比原始BERT 更好的性能。因此,本文采取BERT-wwm 模型作为最底层的编码器。
在本文中,BERT-wwm 编码层的输入为两个事件所在的句子,使用BERT-wwm 的特殊分隔符[SEP]分割,保留事件句可以让编码器获得完整的语义信息。英文与中文一个很大区别是英文更加注重整个句子的句法结构,而中文侧重的是句子的语义信息。因此,在中文跨句的事件时序关系识别中,事件句的语义信息对关系提取起着决定性作用。此外,本文在原始句子中添加了用来区分两个事件触发词的开始和结束标记,如图1 中所示,(输入句子实例见图2(b))。其中,[E1]和[E2]分别表示两个事件触发词的开始,[E1/]和[E2/]则分别表示结束。该标记的作用是让BERT-wwm 在学习语义特征时可以更好地区分开这两个事件触发词与句子中的其他词语。考虑到中文词语的状态无法通过词性变化或者加前后缀来表示,本文使用五种ACE2005 中文语料库中所预定义的事件触发词相关的属性特征,分别是:时态(Tense),类型(Type),极性(Polarity),泛型(Genericity),形态(Modality)。通过这五种属性特征来进一步扩充事件触发词的潜在信息。将这五种事件对属性特征拼接到两个待分类的事件触发词后面。开始和结束标记之间囊括了事件触发词本身的信息以及五种属性信息。如图1 中所示,输入端的句子为图2(b)跨句的例子。其中第一个句子中事件触发词“指控”的五种事件属 性 分 别 为:“过 去”“司 法”“积 极”“具 体”“声 明”;第二个句子中事件触发词“辞职”的五种属性分别为:“过 去”“人 事”“消 极”“具 体”“其 他”。将 事 件 对的属性分别拼接在各自的后面,在事件触发词的前面插入开始标签(图中输入端蓝色部分),事件触发词和五种属性的最后插入结束标签(图中绿色的[E1/]和[E2/])。
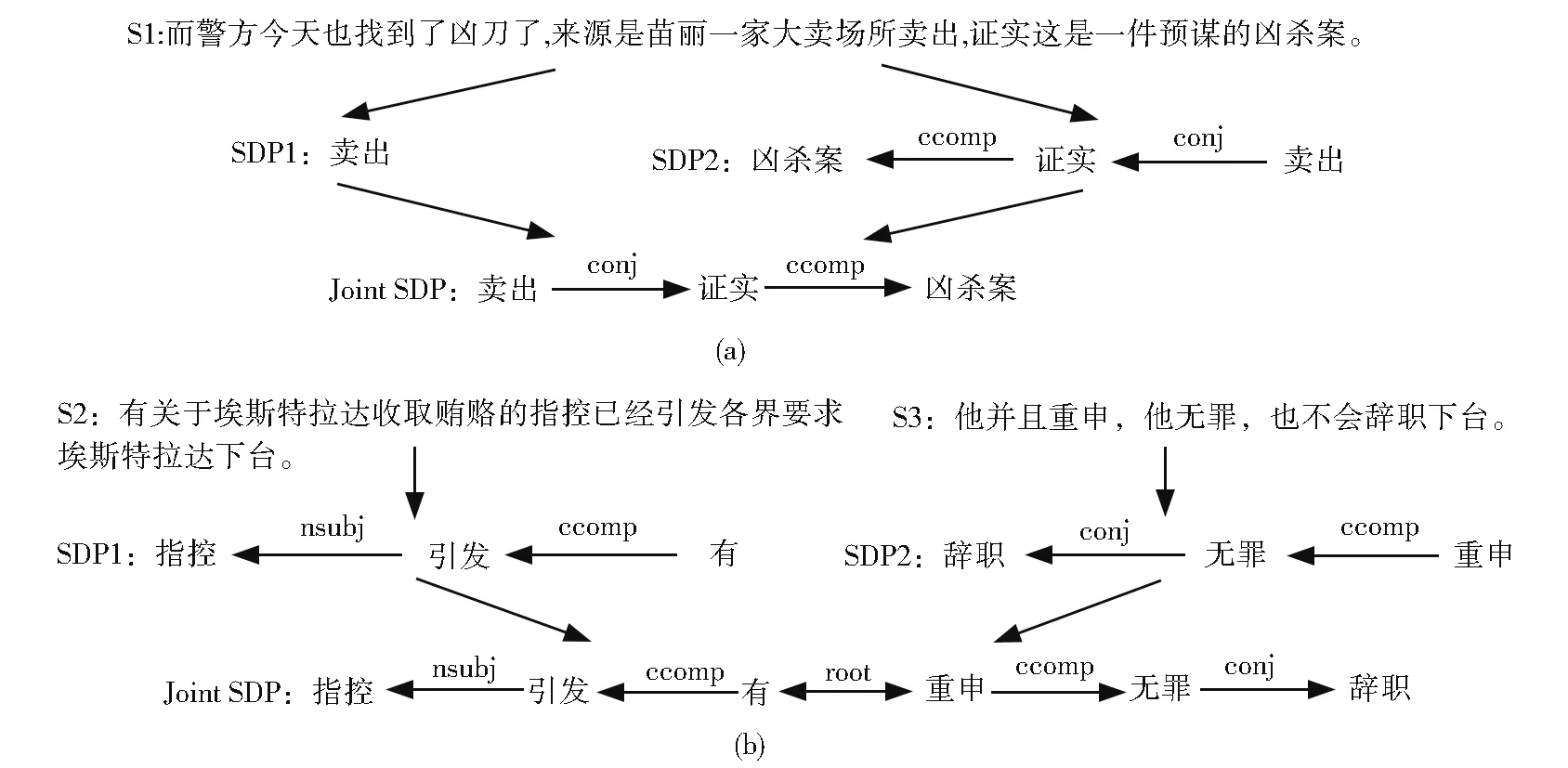
图2 同句(a)跨句(b)联合最短依存路径Fig. 2 Intra(a)and inter(b)joint Shortest Dependency Path
本 文 使 用{w1,w2,w3,…,wm},{t1,t2,t3,…,tn}表示两个原始事件句,其中m,n分别为两个句子的长度,两个事件触发词分别表示为序列{wi,…,wj}(i≥1,j≤m),{tk,…,tl}(k≥1,l≤n),事件触发词的长度分别为j-i+1,l-k+1。在未添加事件对属性信息和事件始末标签时,BERT-wwm 输入端表示如下(1)所示,其中[CLS]表示句子的开始,[SEP]用来分隔两个句子:
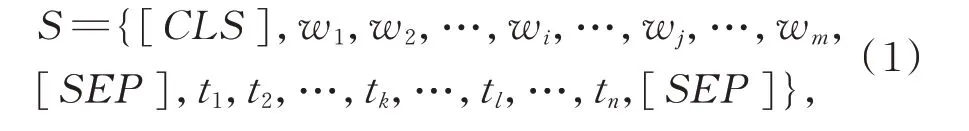
接着将上述两个事件触发词的五种属性信息表示为features1={e1,e2,…,e5},features2={f1,f2,…,f5},将其分别拼接在两个事件触发词的后面。两个事件开始标签[E1],[E2]分别添加在事件触发词之前,[E1/]和[E2/]分别添加在五种属性序列后面。输入端的表示进行改进后如下:
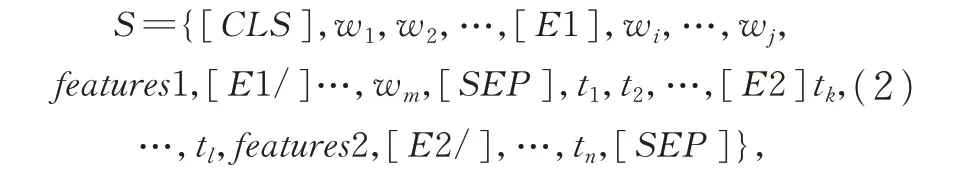
BERT-wwm 最后一层的输出序列中,选取[CLS]对应的编码表示Y[CLS],它包含整个输入的语义信息。根据输入端[E1]和[E2]索引位置获得对应的编码向量Y[E1]和Y[E2],将其进行MaxPooling 后与Y[CLS]融合,得到包含语义信息和事件对属性信息的向量编码Yb,其计算公式如公式(3)所示:
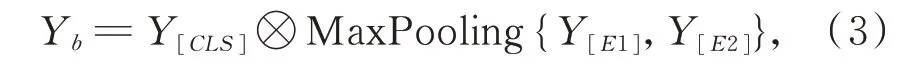
其中⊗表示逐元素相乘。在融合方式上,本文将Baldini 等人[24]对目标词的不同处理方式进行组合并实验。比较了对Y[E1]和Y[E2]使用AveragePool⁃ing 和MaxPooling,以及与Y[CLS]采用点乘和拼接(concatenate)这些不同的处理方式,实验结果表明,以上公式中的融合方法可以获得更好的效果。
2.2 基于联合最短依存路径交互层
最短依存路径(SDP)是句法树中两个特定词之间连接到某个相同结点的最短路径。Cheng 等人[15]提出公共根的假说,假设分布在邻句中两个事件触发词各自所在的最短依存路径可以通过一个虚拟根相连。但在进行训练时,他们使用两个神经网络分别对两条路径进行训练,并未真正将两条路径进行相连。
本文采用虚拟根的假说,但本文的不同在于:在输入端将两条最短依存路径拼接成一条联合最短依存路径(JSDP,Joint SDP),使用同一个Bi-LSTM 对该路径进行训练,而不是像之前方法那样使用两个神经网络分别对两条路径进行训练。同句和跨句(包括邻句)的拼接方式分别如图2(a)和图2(b)所示,事件触发词分别位于Joint SDP 两端。这样的好处在于:对于同句,可以更彻底地发挥Bi-LSTM 捕获长期依赖的能力,获得两个词之间直接双向相连的依赖关系;对于跨句和邻句,更加直接地通过虚拟根来连接两条最短依存路径。
在Bi-LSTM 的输入端,JSDP 上的每个词语向量vi由四种向量拼接而成,如公式(4)所示:
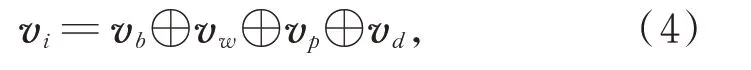
其中,⊕表示拼接(concatenate),vb是由BERT⁃wwm 编码后的词语表示,由于BERT⁃wwm 是字符级别的编码方式,本文将词语拆成字,根据每个字在BERT-wwm 输入端的索引位置获得其对应的BERT 编码向量,将每个词的向量序列平均池化后作为整个词的表示vb。除了使用BERT-wwm 对词语编码外,还使用了另一种Word2Vec 方式来表示词语。Li 等人[25]针对中文词向量表示所受因素的影响,提出了一个新的标准CA8 用来综合衡量词向量的好坏程度。他们在大量语料库上训练出了多个中文词向量,本文采用在他们CA8 下性能最优的一个词向量集合,将联合最短依存路径上的每个词语通过该向量集合映射为实值向量vw,与vb拼接作为词语的完整表示。vp和vd分别是词性和依存关系采用随机初始化后的特征表示。v={v1,v2,v3,…,vs},其中s为联合最短依存路径的序列长度,将序列向量v作为Bi-LSTM 的输入。
Bi-LSTM 输 出{h1,h2,h3,…,hs},其 中hi为hforward和hbackward的拼接。对h的处理上,本文也通过实验对比了三种处理方式:直接使用最后一个时间步的表示、使用事件触发词对应的向量表示、对所有时间步的表示进行最大池化。经实验结果发现使用第三种处理方式获得的Ys可以获得更优的性能,YS计算如公式(5)所示:
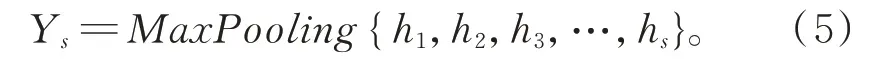
2.3 多特征相融合的时序关系分类层
该层主要是将编码后的句子语义特征、事件对属性特征、句法结构交互特征进行全连接融合,使用激活函数ReLu 后再使用Softmax 对其进行分类得到预测结果P。计算方法如公式(6)所示。其中W和b为全连接层的权重矩阵和偏置。
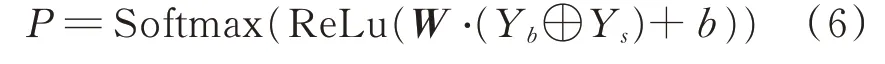
3 实验
3.1 实验设置
本文采用Li 等人[11]标注的基于ACE2005 中文事件语料库的事件时序关系数据集。他们选择ACE2005 中文语料库中的163 篇文档。其中包含1 166 个事件,标注四种事件时序关系:“BEFORE”“AFTER”“OVERLAP”和“UNKNOWN”。样 本统计如表1。其中“BEFORE”和“AFTER”数目相等,由于任意两个事件都双向标出了对应的时序关系,例如句子S1 中,“卖出”和“凶杀案”的关系为“BEFORE”,则“凶杀案”与“卖出”的关系即为“AF⁃TER”。相较于英文语料库TimeBank-Dense 中的12 715 个时序关系,该语料库中所标出时序关系更加稠密。且通过表1 对同句和跨句(包括邻句)的统计可以看出,跨句占比远远高于同句。
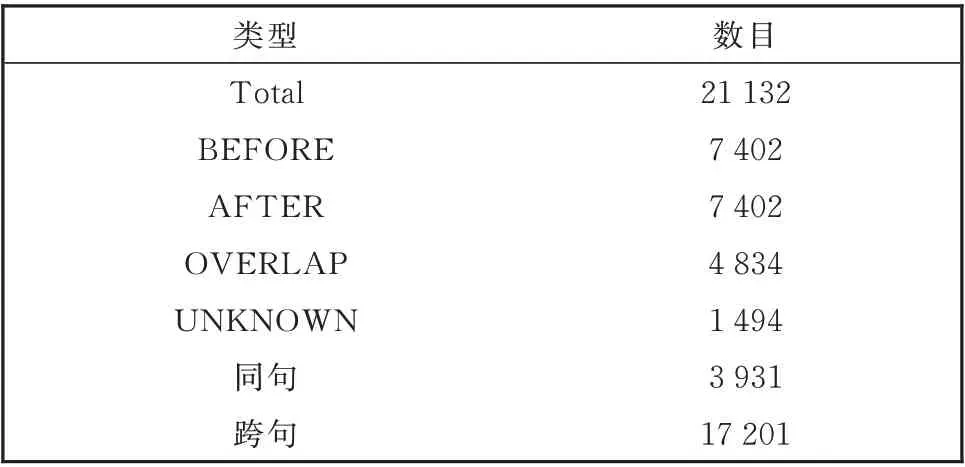
表1 基于ACE2005 中文事件语料库的时序关系样本数统计Table 1 Numbers of event temporal relation samples on ACE2005 Chinese corpus
为了公平地对本文所提出的模型进行评估测试,采用和Li 等人[11]一致的评测标准:把所有文档划分5 份(具体划分和Li 等人[11]一致),采用5 折交叉验证法,每折训练50 个epoch,包含大约4 000 个事件对,Batch 大小为16,取5 折的平均值。使用StanfordCoreNLP 工具构造SDP。使用Accuracy 作为评估标准,该指标在此任务中与Micro-F1 相同,因为每对事件间的时序关系必属于四种关系中的一个。通过外部词向量映射的维度为300,通过BERT-wwm 获取的词向量维度为768。词性向量和依存关系向量的维度为50。Bi-LSTM 中单元大小设置为64,在全连接层中使用Dropout 防止过拟合,比率为0.3,且使用Early Stopping,其大小设置为8。使用交叉熵损失函数,使用BertAdam 优化器,学习步长设置为3×10-5。
3.2 实验结果
为了评估TRIMI 模型的性能,本文将其与四个基准系统比较,具体如下:
(1)GIM:由Li 等人[11]提出的使用传统机器学习进行时序关系推理的方法,输入端使用多种特征,结合自反性和传递性进行全局优化。
(2)DGIM:由Li 等人[11]提出,在GIM 基础上融入了事件相关性约束、连接约束、事件同指约束等全局优化方法,是目前在ACE2005 上中文事件时序关系分类任务效果最优的方法。
(3)CHENG:由Cheng 等人[15]提出,在该任务中使用神经网络的经典方法之一,使用TimeBank-Dense 语料库,将SDP 上的词语、词性、依存关系拼接作为输入。本文将其模型复现后在中文语料库上进行实验。
(4)BERT-wwm:将两个事件句作为BERTwwm 的输入,不加入其他额外的信息,直接使用BERT-wwm 在下游分类任务中的处理方法对时序关系进行预测。该模型对应于图1 中使用BERT 层的输出Y[CLS]进行分类。
(5)TRIMI:即本文所提出的融合语义信息、事件对属性信息、句法交互信息的多维度信息时序关系分类模型。
表2 给出了各个模型总的准确率以及在不同时序类别上的准确率。由表2 可以看出,本文所提方法TRIMI 与传统方法GIM 和DGIM 相比,获得了更优的性能,在总体准确率上分别提高了5.99%和1.75%。由此可以看出,基于神经网络的深度学习方法比使用了大量特征的传统方法更加有效。虽然DGIM 融合了多种约束进行全局优化,TRIMI 的性能也比之更好。如果本文也将这些全局优化与TRIMI 进行融合,效果也将进一步提升。

表2 模型整体性能对比Table 2 Comparison among the overall performance of different models
与神经网络方法CHENG 相比,TRIMI 在准确率上提升非常大(17.21%)。主要原因是CHENG对同句的事件时序关系识别效果较好,但对跨句(包括邻句)的事件时序关系的识别性能较差。这是因为SDP 只能捕获句内的依存关系,无法捕获句间,特别是跨句的依存关系。结合表1 同句和跨句的样本占比可知,在该语料库中81.40%的事件关系是跨句关系。另外,中文词语间的依存关系不如英文清晰和明确,依存分析性能较差。BERTwmm 采用原始事件句作为输入,根据学习到的语义信息进行时序关系分类,效果较之于CHENG 提升有限。TRIMI 与BERT-wmm 相比,效果提升了16.19%,足以说明本文在输入端对事件句的处理方法以及所融合的事件对属性信息的有效性。
另 外,TRIMI 在“BEFORE”“AFTER”“UN⁃KNOWN”都获得了最好的预测效果。其中,“UN⁃KNOWN”的提升较为显著。比之前最好的效果提高了2.97%。这个结果说明神经网络方法对小类的识别性能较好。
3.3 实验分析
为了验证本文所提出的不同信息对整体、跨句和邻句的影响,本文设计了对比实验,其对比结果如表3。其中,各个对比模型说明如下:
BERT-wwm+SDP:在BERT-wwm 中 加 入SDP。即将TRIMI 模型中的JSDP 替换成SDP,且不在输入端添加额外的事件标签和属性信息。
BERT-wwm+JSDP:在BERT-wwm 中 加 入本文提出的JSDP。该模型等同于TRIMI 模型删除事 件 对 属 性 信 息,事 件 标 签[E1][E1/]和[E2][E2/]。
BERT-wwm+JSDP+Lab:在BERT-wwm+JSDP 模型基础上,在事件触发词前后加入事件标签[E1][E1/]和[E2][E2/]。即在TRIMI 模型中移除事件属性feature1 和feature2。
BERT-wwm+JSDP+Attr:在BERT-wwm+JSDP 模型基础上,在事件触发词后加入属性信息(feature1 和feature2)。即在TRIMI 模型中移除事件标签[E1][E1/]和[E2][E2/]。
对比 表3 中CHENG、DGIM 和本文模型TRI⁃MI,同句事件时序关系的识别性能优于跨句(包括邻句)事件时序关系的识别性能。充分说明了识别跨句时序关系更具挑战性。而TRIMI 不论在同句还是跨句时序关系识别上,性能都优于两个基准系统。这是由于本文提出的JSDP 能更好地利用句法结构捕获同句事件信息,还利用了事件属性更好地识别跨句时序关系。
SDP 在同句事件时序关系识别中已被证实有效,如表3 所示,在BERT-wwm 的基础上加入SDP后(BERT-wwm+SDP),同句和跨句分别提升5.81%和1.56%。在此基础上,本文强调联合的作用,BERT-wwm+JSDP 相 比BERT-wwm+SDP在同句时序关系识别的性能进一步提升了4.1%。在图2(a)中,两条SDP 分别为[卖出]和[凶杀案,证实,卖出]。在未联合时,该样本会被错误预测为“OVERLAP”。但将两条路径联合后变成[卖出,证实,凶杀案],Bi-LSTM 可以获取到“凶杀案”是“卖出”的一个子结点,再结合依存关系,可正确地将其关系预测为“BEFORE”。
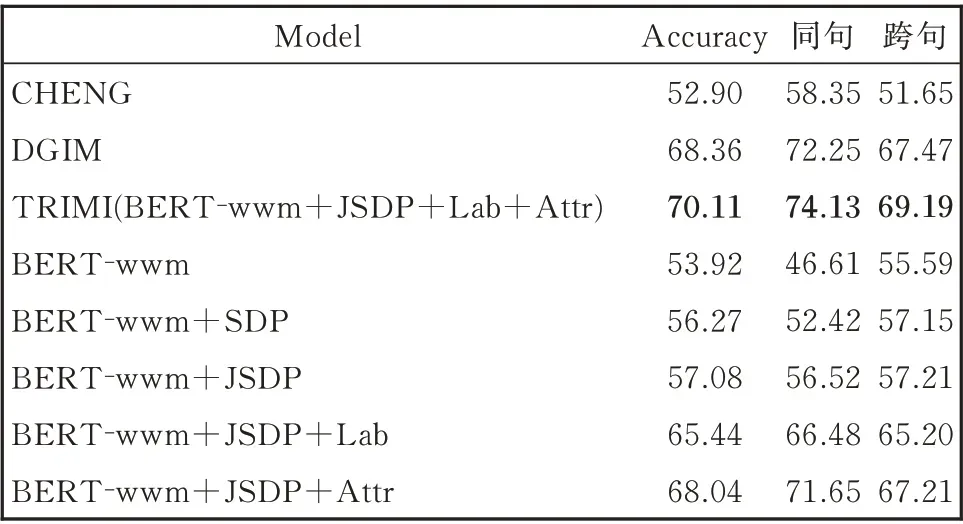
表3 不同维度信息及跨句同句效果比较Table 3 Effects comparison of different dimension information and performance of the intra-sentence and inter-sentence
BERT-wwm+JSDP+Lab 和BERT-wwm+JSDP 相比,事件始末标签使得性能在同句跨句中明显提升(+9.96 和+7.99)。由于一个句子中会有多个事件,[E]和[E/]可以让BERT 编码器获取有针对性的语义信息。
BERT-wwm+JSDP+Attr 和BERT-wwm+JSDP 相比,加入事件属性信息后,在同句和跨句上性能明显提升(+15.13 和+10.00)。该属性进一步丰富了两个事件之间的区别和联系,一定程度上弥补了相隔较远的事件句之间语义不连续的缺陷。例如,在句子S4 和句子S5 中,未添加事件对属性的情况下,目标事件对会被错误判断为“OVER⁃LAP”。这两个句子中间还相隔了其他的句子,连贯性差,无法仅通过语义信息正确判断出正确的时序关系。而事件属性对识别时序关系有帮助,“抓获”的时态为“现在”,“受伤”的时态为“过去”,这是一个明显的信号。通过将事件对的潜在信息与两个句子的语义信息相融合,即可很容易地将时序关系判断为“AFTER”。
S4:巴警方目前尚未抓获任何嫌疑犯。
S5:巴基斯坦旁遮普省27 日下午连续发生3起炸弹爆炸事件,造成至少1 人死亡、22 人受伤。
4 结论
本文提出了一种融合多维度事件信息的事件时序关系识别模型TRIMI。该模型利用BERT 挖掘事件句的语义信息,利用JSDP 来表示句内两个事件在句法信息上的关联性,利用事件属性进一步抽取跨句事件在时序上的差异。实验表明,不论在同句还是跨句情况下,TRIMI 均取得了最佳性能。
虽然本文提出模型使用多种语义信息尽量多地获取与事件相关信息,从而一定程度上有助于识别跨句事件时序关系。但与同句相比,跨句的识别效果还是有一定差距。今后的研究中,考虑进一步丰富输入端的信息。此外,可以考虑如何更好地利用事件时序关系的自反性和传递性,以提升识别的性能。
