基于改进的LeNet网络手写体字符识别技术的研究
2021-08-26郁岩
郁 岩
(江苏安全技术职业学院 机械工程学院,江苏 徐州 221000)
0 引 言
传统的光学字符识别(OCR)在数据场景单一的背景中虽有较好的识别率,但是面对复杂、多干扰的自然场景时,OCR识别效果不佳。SVM、Boosting等算法需要人工定义特征信息,由特征提取器从图像中提取相关特征,再由分类器对这些特征进行分类。而深度学习只需输入原始图像模型就能够自主学习图像特征,然后输出分类结果[1]。
随着移动支付技术的更新,传统卷积神经网络LeNet_5进行动态字符识别时仍存在问题:现有网络深度不足,影响字符识别精度。多数研究人员认为深度神经网络的深度到了尽头,这是由于超深层网络在进行反向传播时,靠近输入层的梯度会出现消失或爆炸的现象[2],但2014年由Christian Szegedy提出的GoogleNet网络可以有效缓解该问题[3]。据此,本文提出了一种加宽网络以创建超大型网络的方法,此类方法不仅能够获得足够复杂的网络,还能避免不断加深网络造成的梯度消失问题。
1 字符识别数据库
通过收集物流和支付等环节的字符数据,分析整理得到不同字迹及位置字符信息数据,并基于数字图像预处理方法对数据进行滤波去噪、信息分割等操作,构建字符分析数据样[4]。
1.1 MNIST数据集
MNIST是训练数据集包含60 000个样本和测试集包含10 000个样本的手写数字数据集[5],该数据集基于重新混合NIST(National Institute of Standards and Technology, NIST)的特殊数据集(Special Database)SD-3和SD-1创建。其中SD-3来自人口普查局的工作人员笔迹,SD-1来自大学生笔迹,其样本结构见表1所列。训练集和测试集分别由250个不同的人编写,由此确保训练集和测试集的编写者相互独立不相交,避免非样本差异外的干扰因素,数据集均经过归一化预处理。

表1 MNIST数据集
图1为MNIST测试集的部分样例,可以看出,不同人员书写的字体形状差异较为明显,而且相比印刷字体,手写字体较容易变形、歪扭,例如图中第3排8列的数字和4排4列的数字4等,这极大考验了模型识别字体的能力。
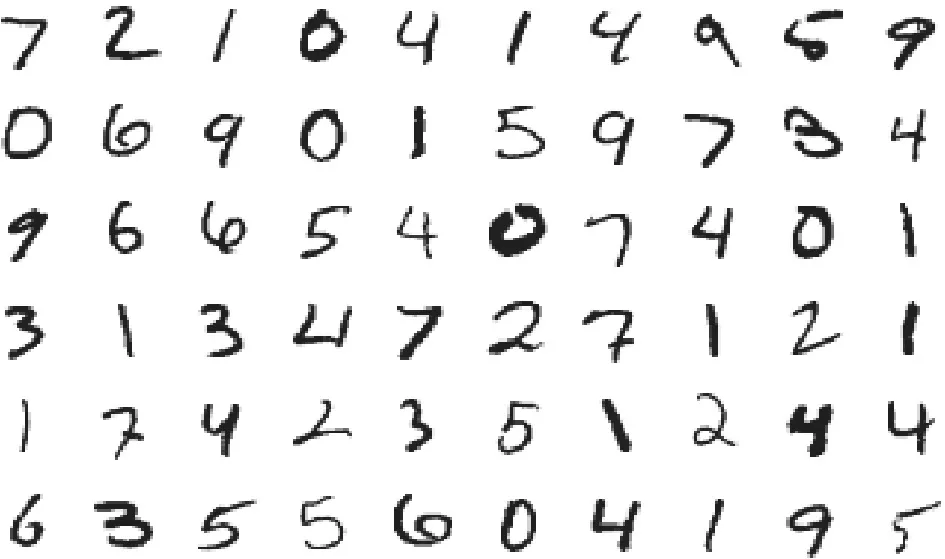
图1 MNIST数据集手写体数字样例
1.2 激活函数
在神经网络中,输入值经过权重层后进行非线性变换。由于现实中的复杂问题均为非线性,若神经网络无非线性函数机制,无论堆叠了多少层网络,它仍然等效于一个单层的神经网络,即它仍是单个线性变换。因此,只有引入非线性变换才能解决问题[6]。理想中的激活函数是阶跃函数,所以神经网络发展初期经常使用Sigmoid函数作为激活函数,Sigmoid函数能够将输入值变换为0到1范围内的数值,其表达式如下:

Sigmoid函数如图2所示。

图2 Sigmoid函数
研究人员通过研究发现,Sigmoid函数会出现梯度消失、收敛缓慢等问题[7]。因此,本文利用ReLU激活函数替代Sigmoid函数。ReLU函数具有运算简单、计算复杂度低等特点,其表达式如下:

ReLU函数如图3所示。

图3 ReLU函数
由公式和函数图可以看出,ReLU函数中,输入为负,则映射为0,若输入为正,则取其本身的值。正是由于这种简单机制,使得其计算速度极快。
2 深度卷积网络模型
LeNet结构由LeCun等人于1994年提出,经过多次迭代,于1998年完成了最终变体[8],并命名为LeNet_5。该网络设计之初,主要用于手写数字的识别,网络结构如图4所示。
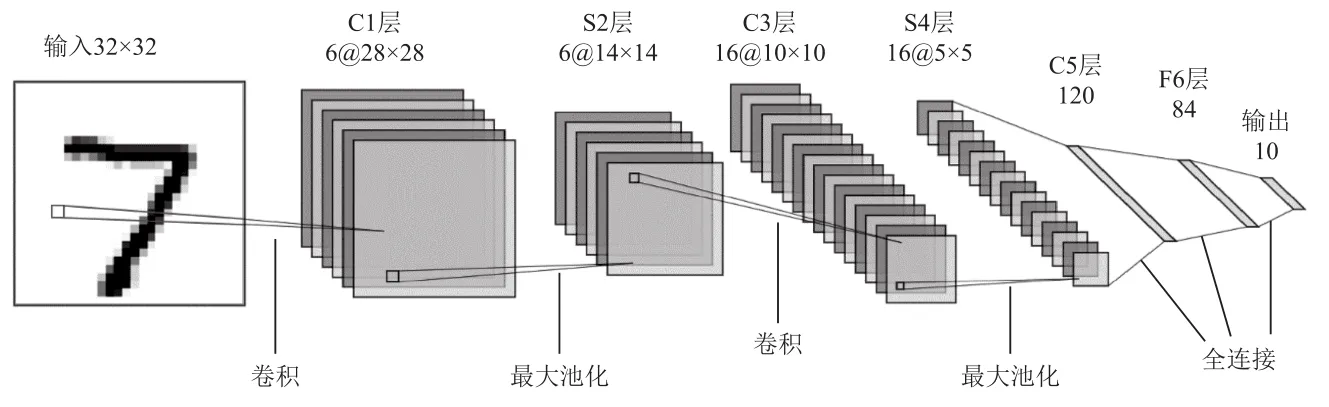
图4 LeNet_5网络结构
由于LeNet_5表征学习能力弱,特别在移动工况下模型识别数字的错误率高。因此本节将在LeNet_5模型基础结构上设计出新的模型,改进内容主要包括模型收敛速度和模型识别性能2方面。
模型收敛速度。在新设计的模型中,将LeNet_5模型的Sigmoid激活函数替换成ReLU激活函数。模型权重参数初始化中使用Xavier进行初始化,然后引入批量归一化[9]。当模型开始训练时,会对输入数据进行标准化处理,前几层网络的输出一般不会出现剧烈变化,而随着模型的逐层训练及前一层参数的更新调整,将导致后一层被累计放大,最终使后层的数据分布发生变化,降低网络的训练速度。批量归一化能够将每层数据归一化到相同的分布,加快收敛速度[10],避免出现网络不稳定等问题。
模型识别性能,增加模型深度。现有网络模型中具有先进性能的网络均为深层网络,通过堆叠卷积核加深模型深度,使模型在视觉任务上获得更好的性能。其次,用2个小的卷积核替换1个大的卷积核,以减少参数数量。同时,此举也能够加深网络深度,增强模型的复杂度。
改进模型命名为Model_A。Model_A的改进之处是用ReLU激活函数替换原LeNet_5模型的Sigmoid激活函数,并在LeNet_5模型基础上增加模型的“复杂度”及深度。在原LeNet_5的基础上增加一层卷积层,将所有卷积设为3×3,将C1,C3,C4层的卷积核数分别设为 6,12,24,其网络结构如图5所示。
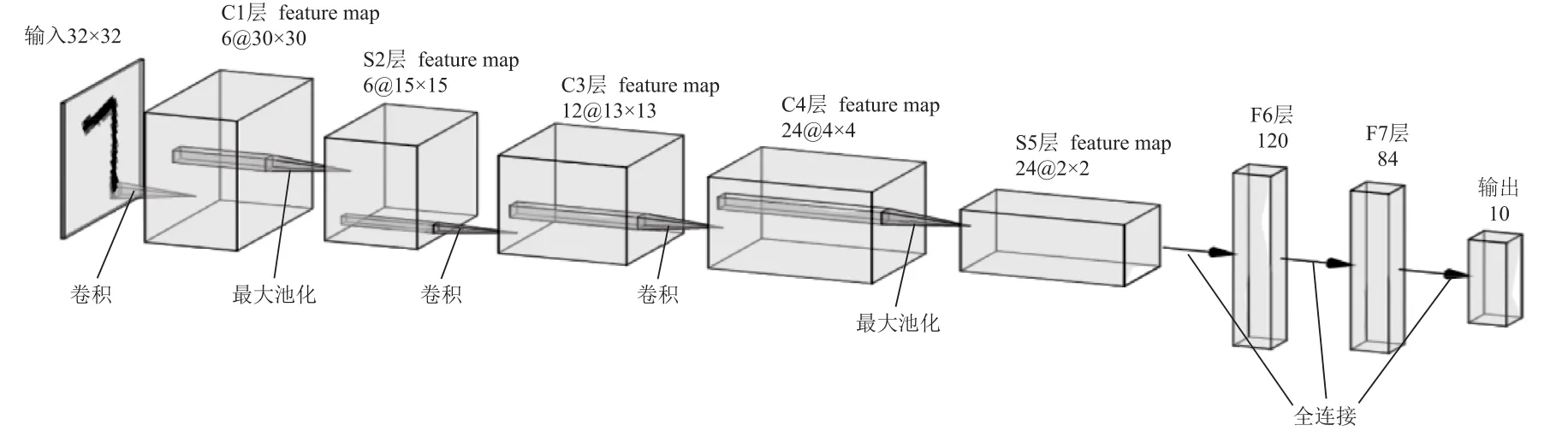
图5 Model_B网络结构
3 模型训练过程与结果分析
(1)将采集的数据经过图像预处理后,保留感兴趣区域,并将图像转换为二维矩阵数据样本(x,y),设置图像训练周期,进行样本预处理、权重初始化操作;
(2)构建卷积数据迭代器训练网络;
(3)计算损失误差、反向传播,并反馈更新权值参数后再次迭代计算;
(4)保存网络权重函数;
(5)网络训练结束。
图6所示为网络训练流程。
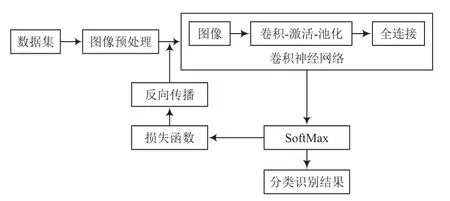
图6 训练流程
实验使用LeNet_5网络和Model_A网络分别在MNIST数据集上训练, 其中LeNet_5网络的初始学习率设为1,初始学习率会在网络训练的过程中,每30个周期衰减一次,学习率衰减(Learning Rate Decay)系数为0.1。Model_A的初始学习率设为0.01,学习率为每30个周期衰减一次,学习率衰减系数为0.1。通过实验观察2个网络分别在MNIST测试集上的准确率和网络收敛速度。
从图7可以看出,Model_A网 络的训练过程分为2个阶段,LeNet_5网络训练过程分为3个阶段。在网络训练开始时,Model_A的损失函数为0.339 1,LeNet_5的损失函数为2.328 9。随着网络训练的进行,Model_A网络在第10周期时损失函数下降至0.020 0后趋于平缓,LeNet_5网络则经过30个周期损失函数下降至0.027 6之后趋于平缓。由此看出,Model_A网络能在极短的周期内收敛,而LeNet_5网络需要耗费数个周期才能收敛,因此ReLU函数在加快网络训练和收敛速度上优于Sigmoid函数,在模型训练初期就能使网络提早进入合适的优化方向。
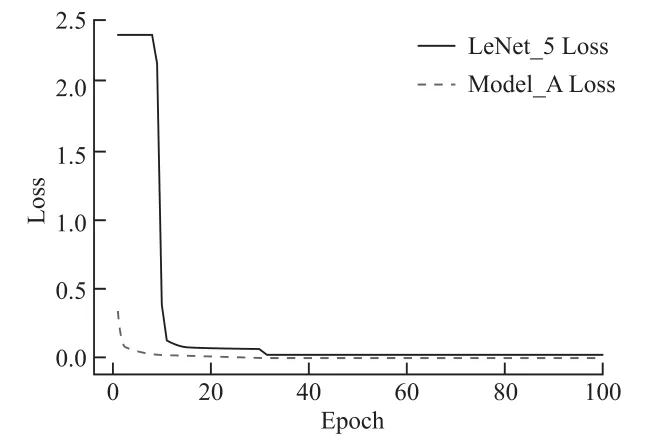
图7 Model_A及LeNet_5损失函数
图8为Model_A和LeNet_5在测试集上的分类准确率,图中实线为LeNet_5的分类准确率,虚线为Model_A的分 类准确率。观察图8发现,Model_A在训练初期就学习出合适的优化方向,使网络能快速收敛。网络训练第一个周期结束时,在测试集上有97.23%的准确率。随着网络的训练,在第24个周期时达到99.02%的准确率,而最终在训练100个周期结束后在测试集上分类准确率为99.26%,错误率为0.74%。LeNet_5网络在训练前10个周期处于初始化阶段,期间网络在测试集上的准确率仅约为17%,而从第10个周期开始,网络的准确率先急剧上升,到达96%左右之后开始平缓上升,最后网络训练100个周期结束时,在测试集上的分类准确率为98.20%,分类错误率为0.80%。

图8 Model_A和LeNet_5分类准确率
4 结 语
本文研究了深层网络在数字字符识别上的应用,以LeNet_5网络为基准网络,对其进行改进,并对改进得到的新网络继续优化完善,得到新的网络变体。通过分析发现,在保持LeNet_5基础网络结构不变的情况下,ReLU函数相比Sigmoid函数具有加快网络收敛特性,可以使用较小的学习率来训练网络等优势。随着网络的加深,将 网络每层输出的数据归一化到相同的分布会使网络更稳定、更易训练。
