Stochastic maximum power point tracking of photovoltaic energy system under partial shading conditions
2021-08-24BushraIqbalAliNasirandAliFaisalMurtaza
Bushra Iqbal, Ali Nasir and Ali Faisal Murtaza
Abstract A large portion of the available power generation of a photovoltaic (PV) array could be wasted due to partial shading,temperature and irradiance effects, which create current/voltage imbalance between the PV modules.Partial shading is a phenomenon which occurs when some modules in a PV array receive non-uniform irradiation due to dust, cloudy weather or shadows of nearby objects such as buildings, trees, mountains, birds etc.Maximum power point tracking (MPPT) techniques are designed in order to deal with this problem.In this research, a Markov Decision Process(MDP) based MPPT technique is proposed.MDP consists of a set of states, a set of actions in each state, state transition probabilities, reward function, and the discount factor.The PV system in terms of the MDP framework is modelled first and once the states, actions, transition probabilities, and reward function, and the discount factor are defined, the resulting MDP is solved for the optimal policy using stochastic dynamic programming.The behavior of the resulting optimal policy is analyzed and characterized, and the results are compared to existing MPPT control methods.
Keywords: Maximum power point tracking, Markov decision process, Photovoltaic energy systems, Partial shading
1 Introduction
Renewable energy is of tremendous importance because of environmental protection, limited availability of fossil fuel, and increasing demand for electricity.Owing to technological advancements, the performance and reliability of renewable energy systems have improved significantly.Improvements in energy storage systems have further enhanced the trend of alternative energy sources.Photovoltaic (PV) based energy systems are one of the fastest growing forms of renewable energy.PV energy is clean, simple in design and requires very little maintenance.Moreover, PV systems can also be constructed as stand-alone systems to give wide output power ranging from microwatts to megawatts.Therefore, PV systems are suited for urban installation as they are noise free and can be set up in any places where sunlight is available.
Partial shading is a natural phenomenon which occurs when a PV array or a part of it is shaded due to the shade of nearby buildings, dust, cloudy weather or bird droppings.With partial shading, several modules in the PV array receive non-uniform irradiation, and therefore the current through each series string is no longer constant.As a consequence, the shaded portion of the array may consume instead of generating power.This results in heating or hot-spots in the PV panel.This problem, if it remains untreated, can result in permanent damage of the PV panel in the long run.In addition, the efficiency of the PV system can be degraded by up to 70% due to hotspot heating.
A major issue associated with partial shading is its impact on the current–voltage characteristics of a PV system.Because of partial shading, the current–voltage relationship becomes highly nonlinear and it becomes difficult to find the value of the voltage at which the PV system delivers maximum power.Many researchers have proposed methods to tackle this problem.A recent review of maximum power point tracking (MPPT) methods under partial shading condition (PSC) is presented in [1].The solutions proposed for MPPT under PSC can be broadly categorized into six main groups [1], i.e., conventional algorithms, metaheuristic algorithms, hybrid algorithms, mathematically based algorithms exploiting the characteristic curves of PV system, artificial intelligence-based algorithms, and hybrid algorithms.The conventional algorithms for MPPT are the simplest in their structure but can be easily trapped in a local maximum power point (MPP).
Metaheuristic algorithms such as the bio-inspired mimetic salp swarm algorithm [2] and the dynamic leader- based collective intelligence algorithm [3] can effectively achieve the global MPP.However, the tuning of the parameters for achieving the best trade-of f between local and global explorations is difficult.
Figure 1 shows the change in MPP of a PV when irradiance is decreased [4].It is noted that when the irradiance changes, both the maximum available power of the PV and the voltage at the maximum power change.A technological review on soft computing methods for MPPT is presented in [5].Compared to the current voltage curves in Fig.1, the curves in Fig.2 [6] indicate the generation of local MPP (Fig.2c) which makes it difficult for the conventional MPPT techniques to find the global MPP.Hence there has been significant work on MPPT techniques under PSC [1, 7].
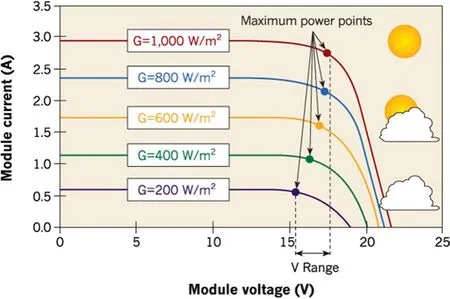
Fig.1 MPP shifts vertically down when irradiance is decreased [4]

Fig.2 Operation of PV array a under uniform irradiance, b under partial shading, c the resulting I–V and P–V curve for (a) and (b) [6]
Among the wide range of methods for MPPT under PSC discussed earlier, some use nature-inspired methods [8] while others are based on effective utilization of power electronic circuitry [9].
Among the direct methods are the perturb and observe based incremental conductance, particle swarm optimization based [10, 11], and parasitic capacitance methods[10, 12].Some of the artificial intelligence based methods include a back-propagation neural network based method, a two-stage off-line trained artificial neural network based MPPT technique using two cascaded artificial neural networks [13], an artificial neural networkbased duty cycle estimation of the boost converter in PSC[14], a genetic algorithm to detect the MPP of a photovoltaic system [15].A comparison among different MPP tracking techniques based on the annual performance has been reported in [16].A bio-inspired flower pollination algorithm for MPP tracking has been discussed in[17] which has been shown to effectively handle partial shading condition however, some time is required before the duty cycle is adjusted according to the changes in the shading condition.Another interesting recent approach for MPP tracking is adaptive perturb and observe that has been reported in [18] but the model of uncertainty has not been incorporated in the design of the MPP tracking algorithm.
Based on the above discussion, it can be inferred that although many works have been done on the MPPT under PSC for PV systems, none of the existing methods uses the mathematical model of uncertainty involved in the shading patterns for developing MPPT technique.In addition, the existing methods do not use pre-calculations of the MPP under various shading conditions.Hence, this paper discusses a Markov Decision Process(MDP)-based MPPT control which belongs to the class of artificial intelligence-based methods.MDP consists of five elements, i.e., a set of discrete and finite states, a set of actions (or control decisions), a set of state transition probabilities, a state dependent reward function,and a discount factor ranging between zero and one.Once a problem is formulated as a MDP (by defining all five elements), the optimal control policy (optimized with respect to the expected value of the discounted reward function) is calculated using a stochastic dynamic programming technique such as value iteration or policy iteration [16, 19].The optimal policy is a mapping that provides an optimal action for each state.
The main advantage of using a MDP-based control over existing approaches is that the uncertainty in the irradiance level is incorporated directly in the calculation of control policy.Another advantage is that the control policy is optimized with respect to the expected discounted value of the reward function.The disadvantage, however, is the computational complexity involved in calculation of the optimal policy.This disadvantage is less of a concern for two reasons.First, the computations are performed beforehand (in an offline manner) and the calculated policy is stored in the memory associated with the embedded system.Second, with modern computational capability and development of approximate dynamic programming approaches, complex problems can become computationally tractable.
There is one additional task associated with the proposed approach compared to the existing methods, i.e.,the collection of statistical data.In order to develop state transition probabilities, statistical data related to the irradiance levels at the location of PV panel installations needs to be collected beforehand.The solution of this problem is beyond the scope of this paper.However, machine learning and iterative policy improvement are existing tools that can enable the implementation of the proposed method without accurate statistical data to begin with.Such development is an avenue of future research.In the rest of the paper, the formal problem formulation is presented in Sect.2 and the proposed MDP model is given -n Sect.3.Calculation of the optimal MPPT policy using the proposed MDP model is described in Sect.4.A simulation-based case study and qualitative and quantitative comparison with existing approaches is provided in Sects.5 and 6, respectively.Finally, findings and future directions are summarized in Sect.7.
2 Problem formulation and solution approach
When different modules in the PV array receive non-uniform irradiation, multiple local maxima occur in the I-V characteristics of the PV array (see Fig.2).Consequently,the PV array fails to operate at MPP.In order to operate the PV array at MPP, it is required to track the maximum operating region of the PV plant according to changing weather conditions and shift the operating point of the plant according to environmental conditions in the presence of uncertainty.
Our proposed solution involves multiple steps including the formulation of a MDP model and its use for calculation of optimal control policy.Figure 3 shows the flowchart of the solution process.Note that once the optimal control policy is formulated, it is used to dictate the duty cycle of the DC-DC converter and hence the operating voltage is changed to track the MPP.Details of the MDP model are presented in the next section.
3 Markov decision process model for MPP tracking
As mentioned earlier, a MDP consists of a set of states, a set of actions in each state, a state transition probability functiona reward function R(s), and a discount factor (γ) that is a number between zero and one.The discount factor describes the preference for current rewards over future rewards [16].Consequently, the MDP model is formulated as:
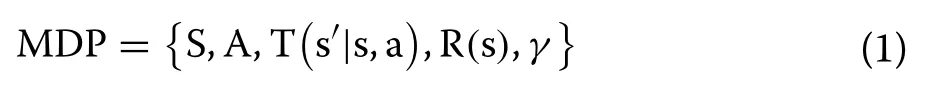

Fig.3 Flowchart of the proposed methodology
where S is the set of states, A is the set of all possible actions,is the transition probability function expressing the probability of being in state s′∈S when control (action) a ∈A is taken in a state s ∈S .R(s) is the reward function that defines the value of immediate reward for a state s ∈S .Each ingredient of the model for stochastic control of the MPPT of a PV energy system is presented below.
3.1 States
State-space is the collection of information regarding the MPPT.Each state variable has its own domain.Union of domains of all state-variables constitute state-space.After careful deliberation and literature survey, the states and state variables are defined as follows:
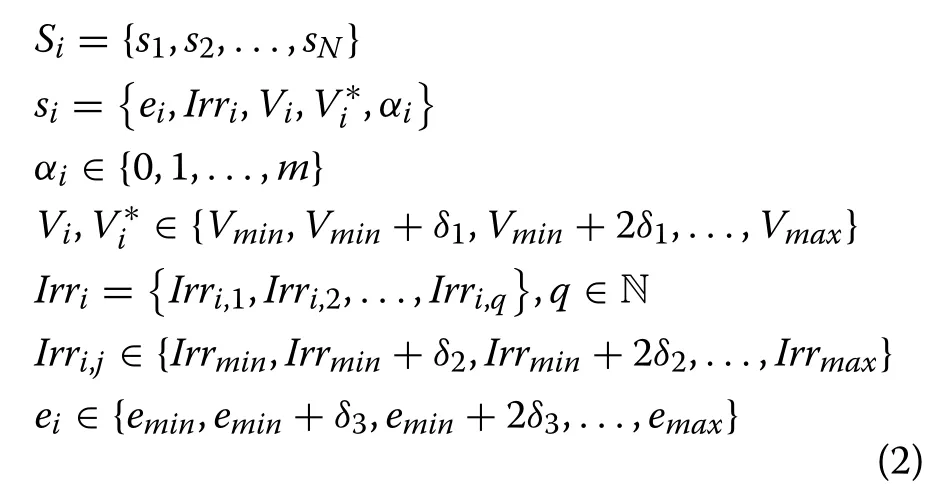
In (2), there are a total of N states, and each state has five variables and consequently five types of information among these variables.Variable eiis the error between the maximum expected power at a given voltage and the actual power received at that voltage.It is assumed that the maximum expected power at each voltage is known.The error variable ranges from emintoemaxand the interval between any two values of eiis δ3, which can be any positive constant and is chosen according to its suitability to the problem.A small δ3will result in large state space while a large δ3will result in small state space.Irradiance Irriis the irradiance vector containing the irradiance of every panel in state i .Each panel has different ranges of irradiance, defined in (2) as Irri,jwhere j ranges from 1 to q and q is the total number of solar panels in the system.Viis the current PV output voltage determined by the selection of the duty cycle, whileis the last value of voltage V in the last m actions which has achieved a minimum value of e .Variable αiindicates the number of actions executed for searching the MPP ( αiranges from 0 to m , counting up to m actions).
With the above selection of state space, it is possible to determine whether the current voltage is achieving maximum expected power or not, while the irradiation level at each panel (or group of panels) is also determined.In practice, irradiation measurement sensors are required to provide such information.In addition,information about the best possible voltage ( V∗) within the last m voltage values that yields lowest error is also obtained.This information is incorporated in the state space because, in practice, the irradiation measurement may not be accurate or there may be some anomaly causing the MPP to shift from the expected value.Under such circumstances, it would be impossible to make the error( e ) equal to zero.Therefore, V∗is the voltage that may be adopted by the system if the error remains nonzero for more thanmconsecutive steps (or decision epochs).Once the error becomes zero, the value of αiis reset to zero.
3.2 Actions
Actions basically refer to all the available decisions in each state for the MPPT of the PV system.Based on selected state variables, actions include the selection of voltageVfor the PV system.If no change in the current value ofVis desirable, a no-operation (NOOP) can be selected as an action.This usually happens when the value ofeis either zero or smaller than a threshold.
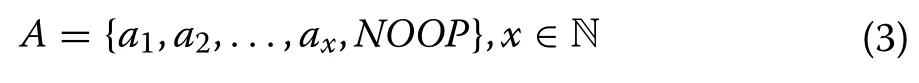
Each action in (3) (except forNOOP) corresponds to a particular value of V (assuming there are x possible values for V ).Once a value of V is selected, the duty cycle is then adjusted accordingly to achieve the value of V .Note that the subscript i is used with V when it refers to the value of the voltage in a particular state si.Otherwise, the subscript is not used.
3.3 Reward function
Reward function is a measure of how good or bad a state is, and can be regarded as a negative of cost function.In the MPPT problem, it is preferable to drive the error to zero.Hence the reward must be inversely proportional to the error.In addition, it is also desirable to make the value of V equal to V∗especially when it is not possible to reduce the error to zero.Therefore, a reward for making V equal to V∗is required that should be inversely proportional to the value of αi.
Based on the above discussion, the reward function is given as:
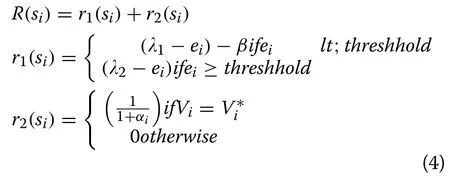
In (4), the first term ( r1) is to endorse the fact that desired power must be equal to the maximum expected power.It means that if it is not operating at MPP this term will have a value, while e will be zero or close to zero if operating at MPP, and then a high reward is obtained.Note that β , λ1, and λ2are positive constants to be selected by the user.The second term ( r2) in (4) is to endorse the need for the system to be operating at the best possible voltage and further actions are discouraged.If the system is not operating at maximum possible voltage, this whole term will be zero so further actions taken to improve the voltage will have no reduction in reward.In the second term α is the action executed since the last time when Vi=.
3.4 Transition probabilities
When modeling real-world decision-problems in the MDP framework, it is often impossible to obtain a completely accurate estimate of transition probabilities.The MPPT problem consists of multiple states, and a state is an assignment to multiple state variables.Therefore, joint probability distribution can be involved in determination of full state transition mapping.In this regard, a Bayesian Network (Bayes Net) is used, which helps simplify the probabilistic representations.It can capture uncertain knowledge in a natural and efficient way.Independence and conditional independence relationships among variables in Bayes Net can greatly reduce the number of probabilities that need to be specified in order to define the full joint distribution.Bayes Net basically represents dependencies among variables and a Bayes Net is a directed graph in which each node is annotated with quantitative probability information [10].Bayes Net of the proposed stochastic control for MPPT of PV energy system is shown in Fig.4.
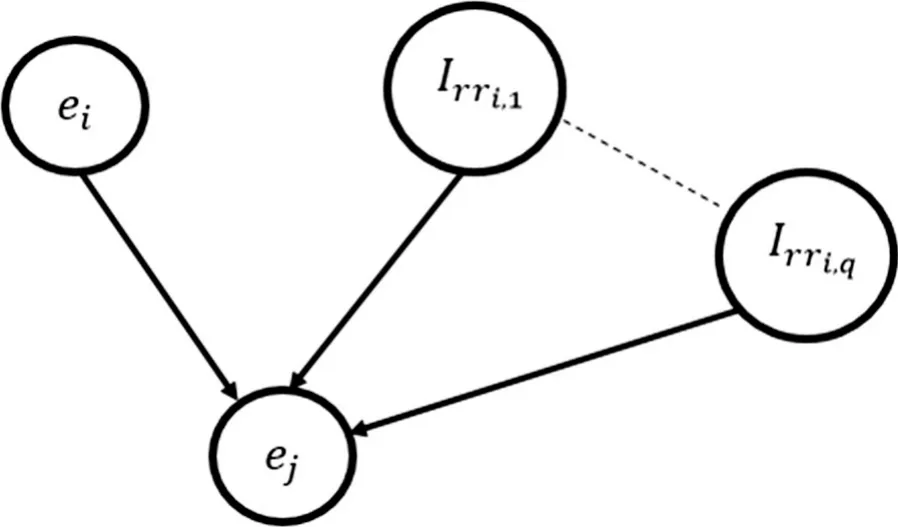
Fig.4 Bayes Net for the stochastic control of MPPT
There is only one random variable which is the error ( e )in the power.This variable is random because shading is random.It depends upon the irradiance value received from the panels and its own previous value.
The expression for the state transition probability is presented as:
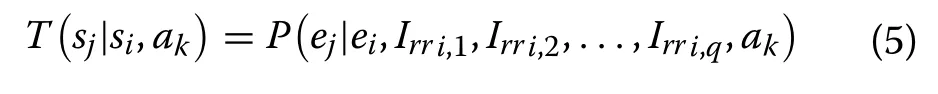
where ejis the value of error in state sjand Irri,∗are the values of irradiation in state si.Note that besides the stochastic transitions, there are also deterministic transitions in the state variables.For example, the values of αi,Vichange deterministically depending upon what action is taken.Also, the value of V∗either remains the same or becomes equal to the value of Vjdepending upon the value of ej.
To facilitate the calculation of the transition probabilities, a function-based approach is proposed.The intuition behind the proposed approach is that the error ( ei)can either increase, decrease, or stay the same.Therefore,at each state, it needs to characterize three probability values, i.e., the probabilities of increase, decrease and no change in ei.The functional form can be written as:
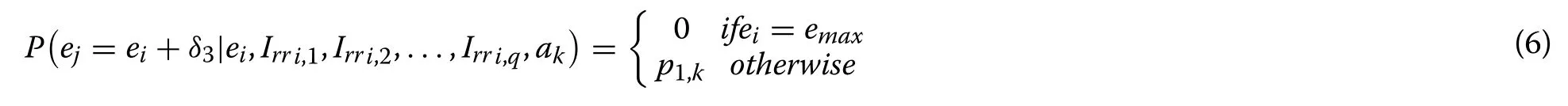
Similarly,
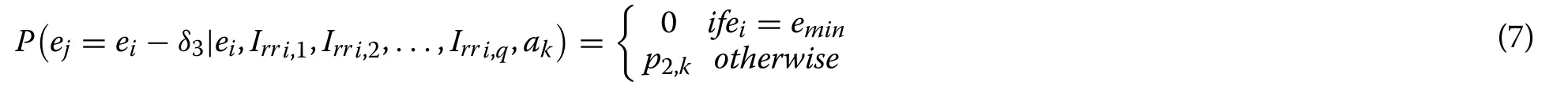
Also,

Here p1,k,p2,k∈(0,1] are the probability values that depend upon the action to be executed.For example,the probability of increase in error would be large if an action results in Vjbeing far away fromNote that the above equations take into account only one unit change in the error, while the probabilities for two or more unit changes can be defined in a similar manner.
3.5 Discount factor
The discount factor ( γ ) is a number between zero and one indicating the depreciation in the value of reward with respect to the decision epochs.If γ is close to zero,only the immediate rewards have significant value and the rewards in the distant future have insignificant value.On the other hand, if γ is selected to be close to one, the distant rewards have almost the same value as that of the immediate rewards.For the MPPT problem, the discount factor is selected to be close to one so that the resulting optimal control policy is ‘far sighted’, i.e., distant future states are given significant value (and not just the near future states) while calculating optimal action.
4 Solution of the MDP model for optimal policy
Once the problem is formulated as an MDP as in Sect.3,any standard approximate dynamic programming algorithm can be used to solve the model for optimal policy.Here the value iteration method is used, and the Bellman equation is the basis of the value iteration algorithm for solving MDPs, expressed as:
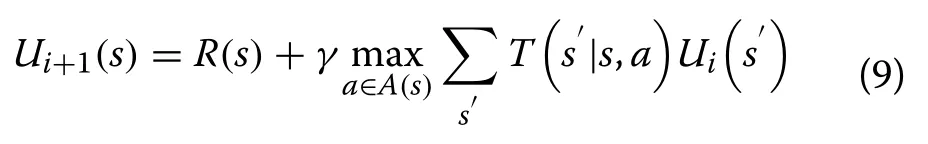
where R(s) is the reward of states,is the utility of the next state after executing action a and γ is the discount factor.If there are n possible states, n Bellman equations will be available, one for each state.The n equations contain n unknown utilities of states.The equations are non-linear, because of the max operator, so the iterative approach is used.The iteration step, called a Bellman update, is given as:

where the update is assumed to be applied simultaneously to all the states at each iteration.The iterations are carried out until the utilities of all the states reach a steady state, i.e., Ui+1(s)=Ui(s),∀s ∈S .Once the steady state utilities ( U∗(s) ) are calculated for all states, the optimal policy is calculated as:

where π∗(s) is the optimal policy obtained by using the principle of maximum expected utility by which agent chooses the action that maximizes the expected utility of the subsequent state.
It is important to point out that the solution of an MDP in general involves the computational complexity of the order N2x where N is the number of states and x is the number of actions [20].In the MDP proposed here, the number of states does increase with the decrease in step size ( δ1,δ2,δ3in (2) above).A decrease in step size may be desirable for achieving high precision in MPPT.Therefore, if MDP is used alone (without any additional small scale duty cycle tuning algorithm), there may be an issue of computational complexity.On the other hand, since all of the calculations involved in the determination of the optimal policy using MDP are carried out offline, larger computational complexity is affordable.At the PV plant site, there is minimal computational requirement, and all responses (in the form of pre-computed optimal policy)can be saved in the digital signal processing kit included in the DC-DC converter.Therefore, as the real-time data on the current/irradiance is fed into the MPPT controller, all it needs to do is set the duty cycle (instantly) at the corresponding value suggested by the optimal policy.Figure 5 shows the breakdown of the online and offline calculations and computing-related activities.It is evident that most calculations are performed beforehand(offline) and only a single calculation in real-time (online)is required, i.e., calculation of the index of the state that has occurred according to the sensor readings.
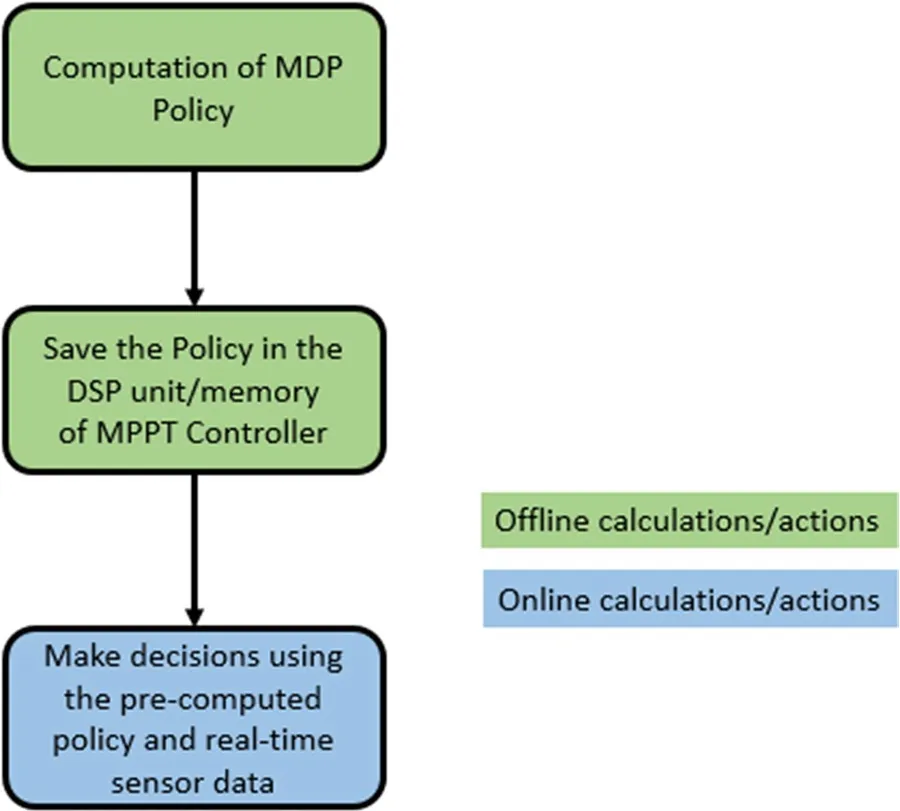
Fig.5 Depiction of online and offline calculations and activities
5 Simulation‑based case study
The overall design of the case study is based on three steps: 1) study of the MPP under various shading conditions using the SIMULINK-based model of a 2 × 2 PV array; 2) formulation of the MDP for MPPT of the array based on the obtained maximum power points; 3)calculation of the optimal control policy using the value iteration algorithm (implemented in MATLAB).The value of discount factor in value iteration is set to 0.95 in order for the MDP policy to consider the rewards of the states in the long-term.Also, the termination criterion is set asUi+1−Ui∞≤10−6.The results for different scenarios using the MDP-based MPPT control policy are then reported to indicate the effectiveness of the proposed approach.The subsections below explain each of the above mentioned steps in detail.
5.1 PV system model
The model of the PV energy system is given in Fig.6.In this model, there are four modules and three variable constants, i.e., temperature, irradiance and partial shading.More than four modules could be used but four are selected to reduce the complexity of the model and the MDP conditions.The range of irradiance can also be changed according to the MDP model, while different partial shading patterns are used to achieve the maximum power.

Fig.6 PV model with 2 × 2 array
The main purpose of this work is to improve the energy harvesting of the PV system and to determine MPP by detecting the shaded portion of the array especially under dynamic weather conditions while avoiding complex control techniques.Thus, the only uncertainty present in this power point tracking problem is shading, which changes under different weather conditions, temperature etc.The shading is considered to be equal to the irradiance absorbed by a PV module.
Change in voltage (ΔV) is incorporated through change in duty cycle (ΔD) of the DC-DC converter in the detected MPP region.The perturb & observe (P&O) algorithm is also implemented in order to precisely detect the MPP.In this way the technique is further optimized in order to harness maximum energy from the PV.
5.2 Evaluation of shading patterns
For different possible partial shading scenarios, the shading patterns are segregated into the following:
1.Horizontal shading pattern
2.Vertical shading pattern
3.Diagonal shading pattern
Comprehensive tests are conducted in order to analyze particular cases of each shading pattern.Results are gathered on the basis of different tests for the 2 × 2 array for horizontal and vertical shading patterns.Lower and upper diagonal shadings are tested for the diagonal shading pattern.
The horizontal shade is considered row-wise and the vertical shade column-wise.The diagonal shading pattern is tested by giving low-shade at upper and lower diagonal entries simultaneously.For both lower and upper diagonal cases, initially, the first row is shaded while keeping the other two rows unshaded with 1000 W/m2, and then the second row is shaded in the same pattern as the first row and the corresponding current–voltage (I-V) and power-voltage (P–V) curves are obtained.Three different irradiation values are considered for this purpose.For dark shade (D), the irradiation value is set as 200 W/m2, while for light shade (L), it is set as 500 W/m2.The module that has been considered as unshaded (U) has an irradiance value of 1000 W/m2.The results indicating the MPP and the corresponding voltage are presented in Table 1.From these results, the MDP states are formulated.

Table 1 List of cases for a 2 × 2 PV array under shading combinations with voltage regions
5.3 Definition of MDP state space and actions
The variables involved in this problem are V,V∗,Irr1....Irrn,e,α .The state space parameter values for the MDP model are defined as:

Note that the state space is defined for a four-panel system, and the irradiation range is from 200 to 1000 W/m2.Values of the irradiation levels and the voltages have been selected based on the results of Table 1 that have been generated using the system in Fig.6.
Based on the above state space, seven actions are defined, with one for each possible value ofVin (12).The numbering of the actions is such that a1corresponds to V =26 , a2corresponds to V =30 and so on until a7which corresponds to V =50.
5.4 Selection of reward function
In the proposed reward function (4), the rate of change of reward with respect to error has two segments.The first segment is when the error is between the acceptable ranges.In this range the rate of change of reward is increased so that the error would remain zero.If the error increase above the threshold, maximum reward cannot be achieved regardless of the error.So in this paper the main task is to achieve maximum reward for this error should it be below the threshold.
Reward function is selected so the MPP can be achieved.When the error increases from a low value, the reward drops rapidly whereas when the error is increased from a high value, the reward drops slowly.The expressions used in the simulations are as follows:

5.5 Calculation of transition probabilities
Calculation of the transition probabilities is not straightforward.The Bayes Net approach presented in Fig.4 helps determine the transition probabilities.In the case study presented here, a function-based approach is adopted as described in (6), (7), and (8).The probability values with respect to the sum of total irradiation on the solar panels are defined in Tables 2 and 3.The probability values in Table 2 are assigned based on how far the action is takingVfrom V∗.The values of p1,∗and p2,∗in Pr0correspond to V being at the same value as V∗, while the values of p1,∗and p2,∗in Pr1correspond to V being four volts different than V∗.In Table 3, the action-wise assignment of the probability values is presented.Note that these probability values are consistent with the simulation based results in Table 1 that depict the voltages corresponding to the maximum power for different partial shading scenarios.

Table 2 Statistical data based assignment of transition probability values for the case study
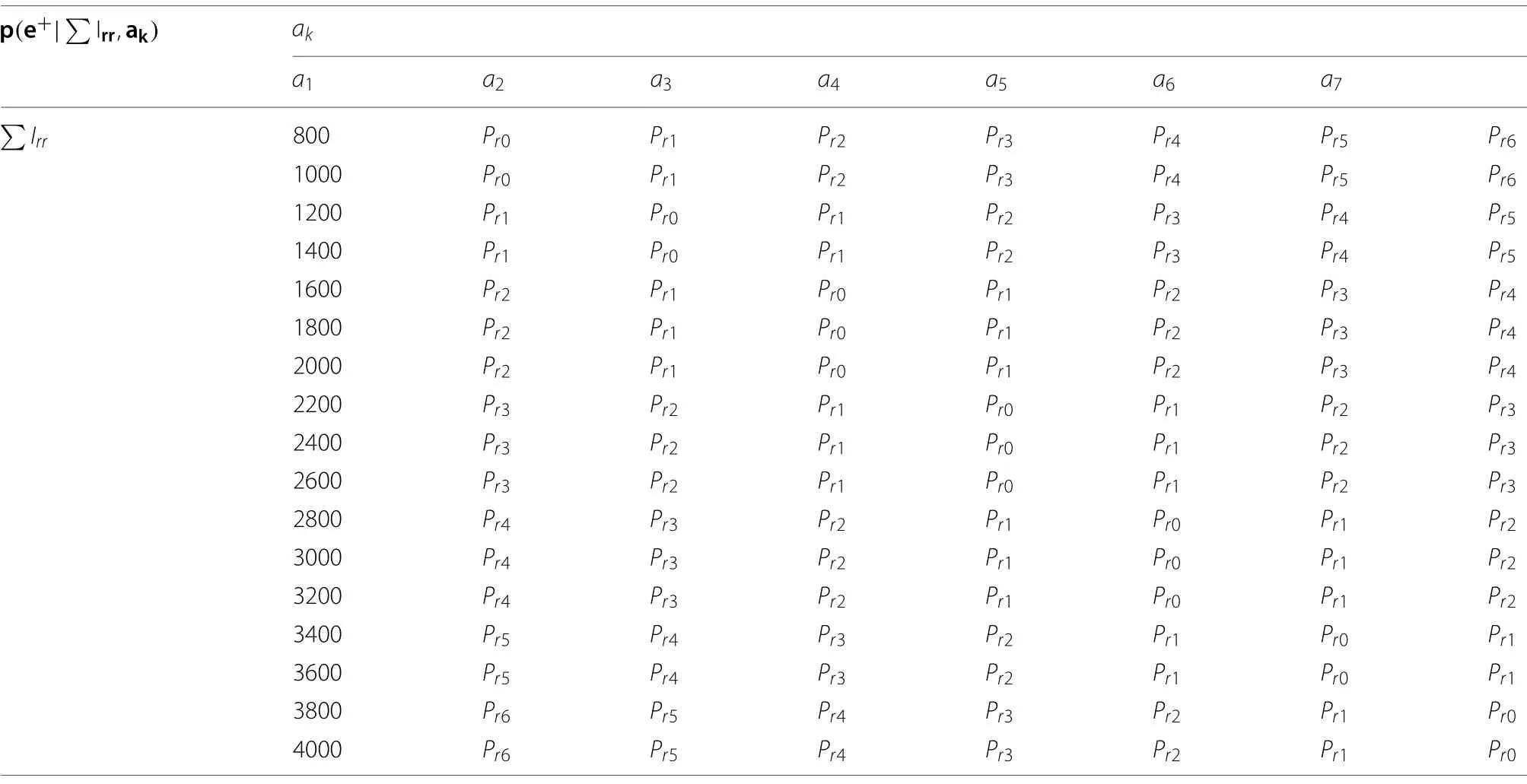
Table 3 Action-wise mapping of the transition probability values for the case study
5.6 Simulation results
The simulation results presented in this section are generated using the proposed MDP-based technique with the parameter values discussed in Sects.5.2 to 5.5.The parameter values are selected based on the simulation of the 2 × 2 PV array under various PSC as discussed in Sect.5.1.The MDP policy is generated using the value iteration algorithm implemented using MATLAB as discussed in Sect. 5.
Along with the results from the proposed method, the results from the existing methods, i.e., modified incremental conductance (Modified INC) [21] and dynamic leader-based collective intelligence algorithm [3] for MPPT under partial shading are also presented.It is important to note that the techniques in [21] and [3] use online computation (search) of the MPP whereas the proposed method uses a precomputed policy for identification of the MPP.Therefore, when plotted against the number of decisions, as in Figs.7, 8, 9, the proposed method is able to reach the MPP within a single decision whereas the dynamic leader-based approach and the incremental conductance-based approach take some time to converge.The results from the dynamic leaderbased approach are optimized by assuming that it finds the correct MPP in a single cycle which is equivalent to three decision steps as described in [3].For optimized results from the incremental conductance method, it assumes that the increment is always in the correct direction.
In order to test and compare the performance of the proposed approach, three different scenarios of variations in the irradiance are considered.As irradiance changes the PV voltages will also change and follow theuncertainty in irradiance as shown in Fig.7.The first graph in Fig.7 is the output power of the PV system, in which the output power with the proposed scheme is compared to the two other methods.The comparison indicates that the proposed approach is able to track the MPP relatively quickly (mainly because of the calculations performed beforehand).The second graph in Fig.7 shows the voltages of the PV energy system.As shown,at the beginning, the voltages are close to zero, and as the irradiance varies, the voltages change according to the irradiance.Again, the comparison indicates quicker response from the proposed approach compared to the others.As shown in Fig.7, when the irradiance is constant the PV voltage is also constant, while variation of irradiance changes PV voltage accordingly.
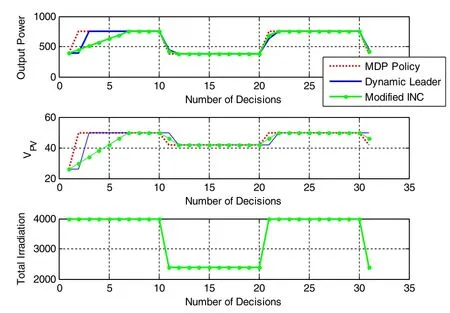
Fig.7 Irradiance versus photovoltaic voltage under low frequency variations
If shadow occurs due to bird droppings, dust, clouds or weather conditions, the irradiance can change more frequently as shown in Fig.8.As seen, the PV voltages change according to the variation of the irradiance.Note that the advantage of the proposed approach over the dynamic leader-based and incremental conductancebased approaches is more pronounced with frequent changes in the irradiance.
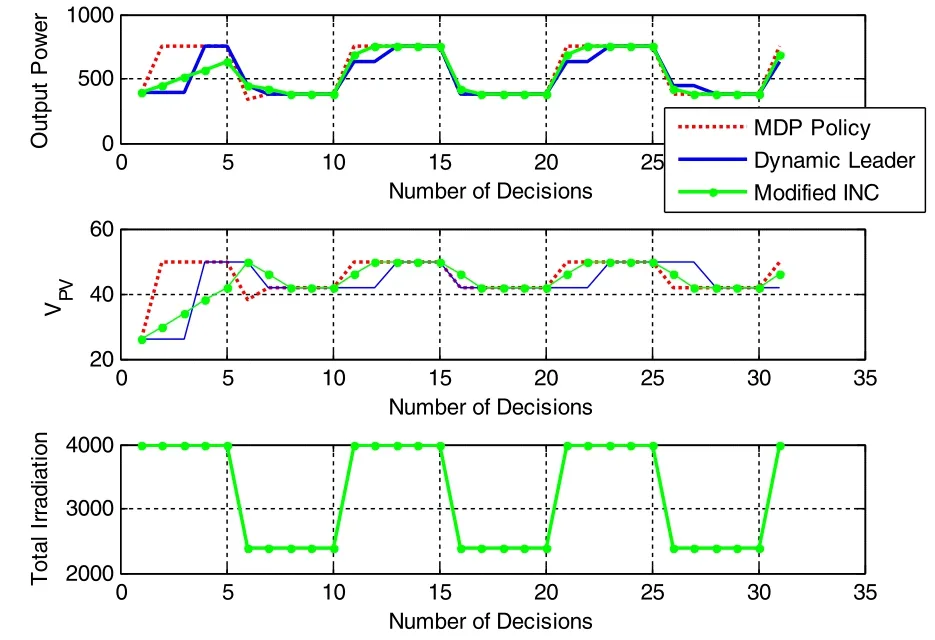
Fig.8 Irradiance versus photovoltaic voltage under medium frequency variations
Finally, even more frequent change in the irradiance is considered in Fig.9 and the results reinforce previous findings that the advantage of the proposed approach increases with the increase in the frequency of change in the irradiance.Such dynamic conditions may occur in real life when the solar panels are installed on top of a moving vehicle, a boat or a low flying UAV in the case of cloudy conditions.

Fig.9 Irradiance versus photovoltaic voltage under high frequency variations
Table 4 summarizes the results from the three cases shown in Figs.7, 8, 9.Note that the advantage of the proposed approach over the dynamic leader-based approach in terms of the total power delivered to the load varies from 1.78% (for the low frequency variations in the irradiance) to 3.62% (for the high frequency variations in the irradiance).It may however be noted that the difference in the generated energy may not be that great because of the fast computation available onboard with the electronics associated with the PV system.
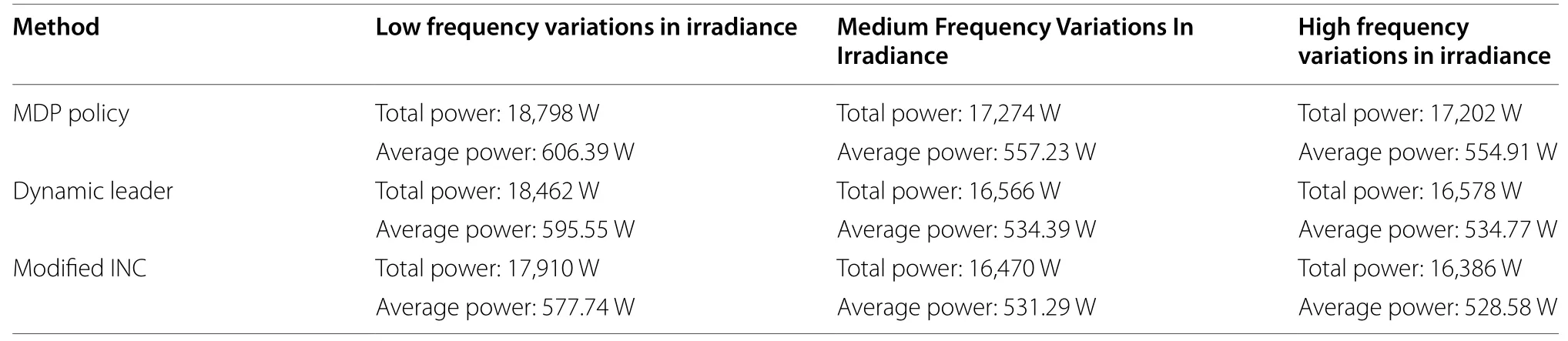
Table 4 Comparison of power delivered to the load under different irradiance variations
6 Qualitative comparison with existing approach
In the previous section, it was shown that the proposed approach is quicker to respond to the change in the irradiance than the others.This is mainly because of the calculations performed beforehand in the proposed approach.This section highlights the main reason for the superiority of the proposed approach using analytical comparison.Although the proposed approach has only been compared to the incremental conductance based approaches, the conclusions from the comparison apply to all other existing techniques not based on precomputations and not catering for the stochastic model of the variations in the irradiance.The tracking of MPP of a PV panel through the implementation of MDP is more effective than the existing online and offline methods.The proposed technique is efficient in the sense that, unlike offline methods, there is no need to interrupt the supply to load in order to track the MPP.Moreover, some existing offline methods are unable to track the MPP under varying weather conditions.In addition, unlike online methods, the complexity of this technique is low and it can be implemented in low cost microcontrollers.
The proposed technique is cost-effective in the way that it takes statistical data of a PV array, which is then processed in MATLAB and the shaded module is detected on the basis of low irradiation.Also, the algorithm is efficient as it is able to differentiate between light and dark shades.Using the concept of MDP, the faulty portion of a PV array can be detected and the portion that is producing maximum power in a particular shading scenario can also be identified.Thus, with the sophisticated control technique the PV array can operate on the voltage corresponding to the maximum power-producing module in order to harness maximum energy in a particular weather scenario.
Lastly, the implementation of the MDP algorithm has narrowed down the scanning in order to detect MPP.Once a particular case of an identified shading pattern is detected, instead of scanning all the regions of the I-V curve, it only needs to scan one region in order to track the MPP.
The proposed model accuracy is compared with the existing modified incremental conductance (MIC)model.As shown in Table 5, both models can operate under PSC, though only the proposed model deals with uncertainty.MIC also has over 25 online calculations whereas the proposed method only requires one online calculation.However, the MDP approach requires statistical data for implementation.

Table 5 Comparison of MDP with MIC
7 Conclusions and Future Directions
Solar energy is one of the most promising sources of energy among all renewable energy sources.The demand for and investment in solar energy have increased significantly because of the gradual reduction in the cost of PV panels and almost negligible maintenance cost.In order to harvest maximum energy from PV plants, maximum power point trackers are employed.These constantly track the MPP of the PV panel under various weather conditions.
In this research, a novel technique has been introduced which tracks the MPP of a PV array under the unavoidable phenomenon of partial shading.The proposed technique does not cut off the load from the power supply as required in some existing hardware or offline techniques.Moreover, no complicated controller nor complex mathematical operations are employed.There is no need to scan the I-V and P–V curves of the PV array.In this technique, the data of irradiance is calculated.This is then processed in a MATLAB code to obtain the shading information.The effectiveness of the proposed method is compared with the existing methods.The proposed model can be used with any MPPT techniques to detect MPP.The proposed model works at different irradiance levels, while it can also be further modified to cater for different temperature levels.In addition,computations in the MDP-based model are fully offline so there is no online computational complexity in the presented model.In addition, the MDP-based model is completely discrete so offline computations are relatively fast.The results of the presented control are tested in all shading conditions.The simulation results of the MDP control show significant maximum power as compared to traditional approaches because none of them dealt with shading uncertainties.
The authors believe that the proposed approach is one of the very first approaches that considers the modeling of uncertainty in the MPPT problem in the form of transition probabilities.Another unique feature of the proposed technique is pre-calculation of the responses which enables quick response to rapidly changing irradiance.These unique features enable future extension of the proposed approach to MPP tracking in PV systems mounted on moving vehicles such as yachts, ships,ground vehicles and low flying unmanned aerial vehicles.Another relatively simple extension of the proposed approach is the incorporation of temperature variation in the MDP model.
Abbreviations
MPPT: Maximum power point tracking; MDP: Markov decision process; PV:Photovoltaic; DC: Direct current; I-V: Current–voltage; P–V: Power-voltage; INC:Incremental conductance; PSC: Partial shading condition.
Acknowledgements
There are no associated acknowledgements.
Authors’ contributions
BI has written the first two sections and has created block diagrams throughout the paper.AN has contributed in the development of the mathematical equations and the solution of the MDP model.AFM has contributed in the results section, the qualitative comparison and the conclusions.All authors read and approved the final manuscript.
Funding
There is no funding associated with this research.
Availability of data and materials
There is no associated data to be shared.The programing code used for generating the results can be requested via email from the corresponding author.
Declarations
Competing interests
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
杂志排行

Protection and Control of Modern Power Systems的其它文章
- A comprehensive review of DC fault protection methods in HVDC transmission systems
- Application of a simplified Grey Wolf optimization technique for adaptive fuzzy PID controller design for frequency regulation of a distributed power generation system
- A critical review of the integration of renewable energy sources with various technologies
- Operational optimization of a building-level integrated energy system considering additional potential benefits of energy storage
- An integrated multi-energy flow calculation method for electricity-gas-thermal integrated energy systems
- Sliding mode controller design for frequency regulation in an interconnected power system