知识库问答系统研究进展
2021-08-24王守会
王守会,覃 飙
(中国人民大学 信息学院,北京 100872)
1 知识库问答系统概述
随着网络资源的不断丰富,人们获取信息和知识的方式越来越多,如何从海量的信息中快速、精准的获取用户所需要的信息是一个巨大挑战,智能问答系统的出现使得该问题得到了部分解决.问答系统(Question Answering,QA)在接收到自然语言问题后,通过解释大量的结构化和非结构化数据返回一个精准的答案[1].在QA的发展过程中,出现了以下几种问答形式:1)基于知识的问答.该方法将自然语言问题映射为数据库上的结构化查询(如SQL、SPARQL),然后经查询后得到问题的答案.BaseBall系统[2]是最早的发布于1961年的问答系统,主要用于回答在美国联赛中一个赛季内的有关棒球比赛的问题.该系统通过人工定义一些模板和规则,将自然语言问题进行结构化语义表示,进而查询数据库并返回问题答案;2)基于信息检索的问答.基于用户输入的关键字或短语,从大量语料库中检索出与之相关的文档或段落,并使用相关算法(如阅读理解算法)来理解文本并返回最相关的答案[3,4].如文本检索会议(Text Retrieval Conference,TREC)(1)http://trec.nist.gov发起的问答跟踪系统;3)基于混合方法的问答.该方法通常使用文本数据集和结构化知识库相结合来回答问题.如IBM沃森的DeepQA系统[5],首先从知识库和文本资源中找到很多的候选答案,进而使用知识资源(如地理空间数据库、文本资源)为每个候选答案打分.
谷歌在2012年提出知识图谱(Knowledge Graph,KG)的概念后迅速得到了广泛的关注和应用.知识图谱是以图的形式来表示客观世界中的实体及其之间关系的知识库,能够更好地组织、管理和理解互联网的海量信息[6],其应用包括语义理解、精准搜索、智能问答、辅助决策.基于知识库的问答系统(Knowledge Base Question Answering,KBQA)是随着知识库(如WordNet[7]、Freebase[8]、YAGO[9]、DBpedia[10]等)的不断发展而产生和发展起来的,通过对自然语言问题进行语义分析、知识抽取、知识推理等操作使得用户能够更精准、更直接的得到问句的答案.
知识库中的每条知识以SPO(Subject,Predicate,Object)三元组的形式存储在知识库中,也被称为事实.其结构为
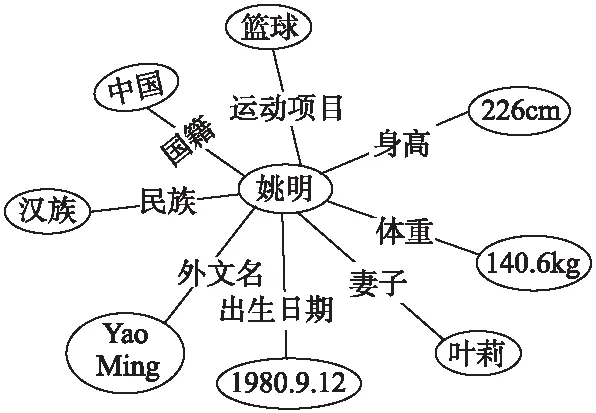
图1 知识库示例
基于知识库的问答是指给定一个由n个单词组成自然语言问题Q,Q={w1,w2,…,wn}.问答系统通过对自然语言问题进行语义分析和理解,并在给定的知识库中进行查询和推理,最后得到该问题的答案.例如对于自然语言问题“What is christinagabrielle′s profession?”,其中 Christina Gabrielle为实体,profession为属性.其目的是利用短语检测、资源映射、语义组合等方法,最终对知识库进行查询并用一个事实(christinagabrielle,/people/people/profession,singer &writer)来回答该问题,那么singer&writer即为该问题的答案.KBQA任务通常被划分为命名实体识别(Named Entity Recognition,NER),实体链接(Entity Linking,EL),关系检测(Relation Detection,RD),以及查询生成(Query Generation,QG)几个子任务.目前KBQA的主流方法有1)基于模板的方法;2)基于语义解析的方法;3)基于深度学习的方法.
接下来在第2部分我们将对KBQA现有的主流方法进行介绍并对目前的研究进展情况进行总结,在第3部分我们将对KBQA任务所面临的问题和挑战进行总结,第4部分对本文进行总结.
2 知识库问答研究方法
2.1 基于模板的方法
基于模板方法(Query Template)的知识库问答其最终目的是将自然语言问题映射为能够在知识库中执行的查询模板(如SPARQL),进而根据查询语句在知识库中进行查询、排序并返回最终的查询结果.之前的问答系统是将问题转换为三元组,然后将其与知识库中的数据进行匹配以检索答案.该方法主要依赖于相似度的度量,不能很好的表示问题的语义结构,且不能对复杂问题进行有效回答,因此Unger等[11]提出了一种新的方法TBSL.该方法通过对问句进行语义解析,构建一个能够完整映射问题语义结构的SPARQL查询模板,然后使用实体识别和谓词检测操作进行模板实例化,最后利用该查询在知识库中进行查询排序并得到答案,其处理过程如图2所示.TBSL方法的主要弊端是需要手工制作海量模板,代价巨大且模板覆盖范围有限.那么能否通过学习来自动生成模板呢?Abujabal等[12]针对这一问题提出了QUINT方法,该方法利用问答对结合依存树来自动学习utterance-query模板,而且该方法能够利用语言的组织特点来回答复杂问题,无需为整个问题提供模板.同样的Cui等[13]从一个百万级的QA语料库中去学习模板,基于这些模板使得KBQA无论在二元事实性问题或是复杂问题上都取得了较好的效果.
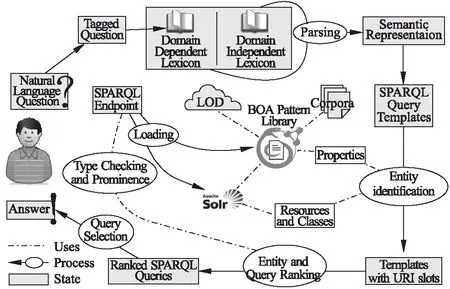
图2 基于模板的SPARQL查询[11]
目前基于模板的方法人工成本高且处理问题单一,基于神经网络的方法通过向量化的方式来表示一个问题虽然比较灵活,可以理解各种各样的问题,但其解释性较差.因此Cui等[14]提出一种兼备两者优点的方法,通过从QA语料库中来自动学习模板,其中大量的QA语料也保证了模型可以理解不同的问题.此外作者还提出了一个生成模型(概率图模型)来解释如何为一个问题找到答案.
现有KBQA方法需要大量的标记数据集且无法对训练集中未涉及的领域进行有效回答.为了克服这些局限性,Abujabal等[15]提出了KBQA的持续学习框架NEQA.在离线训练过程中,NEQA会从少量训练集(问答对)中自动学习出能够将句法结构映射到语义结构的模板.在线问答过程中,当遇到模板未覆盖的问题时,会触发持续学习模型,对训练集中未覆盖问题的语法结构进行学习得到新的模板,通过不断扩充模板库来提高模板的覆盖范围.
2.2 基于语义解析的方法
基于语义解析方法(Semantic Parsing)的知识库问答是指将自然语言问句解析为相应的逻辑表达式(如Lambda-DCS[16]等),再将该逻辑表达映射为能够在知识库上支持的结构化查询(如SPARQL、SQL等),最后从知识库中查询并得到答案,基本步骤如图3所示.目前流行的语义解析方法包括组合范畴语法(Combinatory Categorical Grammar,CCG)解析[17-22]和语义成分解析(Dependency-based Compositional Semantics,DCS)[23,24].
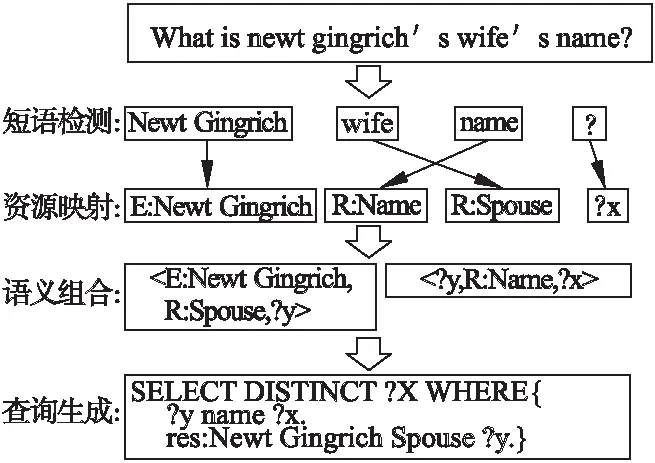
图3 传统语义解析方法基本步骤
语义解析器的训练需要标注大量的逻辑表达并进行有监督学习,如果遇到未学习过的样本时会导致系统的表现很差,特别是在限定领域中逻辑谓词数量较少的情况下[25,26].为了解决解析器在监督学习中遇到的问题,Cai等[21]提出了基于标准监督学习算法、模式匹配算法和模式学习算法的大型知识库语义解析器开发技术.该方法虽然相较于纯监督学习方法有了提高,但仍然无法完全摆脱对人工标注数据的依赖.学习一个可扩展到大型开放领域问题的语义解析器可能存在逻辑表达与知识库中的本体概念无法匹配的情况,Kwiatkowski等[22]提出了一种新的方法来学习两阶段语义解析器,使得该解析器支持可扩展的、动态的本体匹配,解决了在本体上可能存在的不匹配问题.解析器首先使用CCG将问句映射为一个领域无关的逻辑表达,进而使用本体匹配模型将该表达转换为目标领域的能够与知识库中的本体相匹配的逻辑表达.Berant等[23]提出一种不依赖大量标注数据而是从问答对中学习逻辑表达.自然语言短语到逻辑谓词的映射,之前是通过手工规则、远程监督、模式匹配相结合的方法[27].文中使用大量的文本语料和知识库来构建短语到逻辑谓词的粗略映射语料库,并提出桥接(Bridging)操作来克服一词多义、轻动词和介词难以对齐的问题.Berant等[24]随后又对该问题做了进一步研究,给定一个问题先通过简单语义分析生成一些候选逻辑表达式.其次为每个候选逻辑表达式生成一个自然语言问句.最后利用候选逻辑表达及其对应的生成问句来训练模型,以寻找最优的逻辑表达.Reddy等[28]通过引入Lambda算法从依存树中推导出neo-Davidsonian逻辑形式,使用该逻辑形式对自然语言问句进行语义解析.最后在Free917和WebQuestions数据集上进行验证,结果表明该方法优于原始的依存树,并且比基于CCG方法得到的逻辑表达更健壮.
此外针对Freebase知识库精度高但覆盖范围低,而基于开放信息提取(Open Information Extraction)的知识库其覆盖范围广但精度普遍较低的问题,Fader等[29]提出了同时利用了两种类型知识库的开放式问答系统(Open QA,OQA).OQA通过将完全开放的QA问题分解为更小的子问题(包括问题释义和查询重构)来实现系统的鲁棒性.Bao等[30]通过引入CYK解析方法,将自然语言问题到语义表达的转换和从知识库中检索答案两个任务在统一框架内解决.大多数的KBQA任务都只针对一个知识库,但实际情况中单一知识库往往不能覆盖所有的问题,如果问题集属于多个领域则需要多个知识库.考虑到对齐结构和查询结构是相互作用的两个部分,Zhang等[31]使用整数线性规划(Integer Linear Programming,ILP)将对齐结构和查询结构整合成统一框架.
2.3 基于深度学习的方法
自2006年Hinton等[32]提出深度置信网络(Deep Belief Network,DBN)以来,深度学习得到了快速发展,涌现了诸多深度学习模型.如卷积神经网络(Convolutional Neural Networks,CNN)[33]和循环神经网络(Recurrent Neural Network,RNN)[34]等,并在多个领域得到了广泛应用[35-37].在知识库问答领域,将深度学习用于KBQA任务成为当今的研究热点[38].包括利用深度学习对传统KBQA方法进行提升和完全基于深度学习的端到端(End-to-End)的研究方法,且都取得了较好的研究进展.
2.3.1 深度学习与传统KBQA方法相结合
在KBQA任务中需要用到很多自然语言处理技术,包括命名实体识别、实体链接、关系检测等.该方法主要利用深度学习对KBQA任务中的某一环节进行提升,如利用深度学习进行实体识别、关系检测、实体链接等[39-45],从而提高知识库问答的整体效果.Zhang等[42]提出了基于注意力机制的字词级(Word-level)交互模型(ABWIM)用于关系检测以缓解在比较前将序列聚合为固定纬度大小的向量时所造成的信息丢失问题,从而提高了关系检测的准确率.在KBQA子任务的处理过程中,Petrochuk等[46]使用BiLSTM-CRF进行命名实体识别,利用BiLSTM进行关系分类.Wu等[47]将FOFE编码和深度神经网络相结合提出了FOFE-net算法用于KBQA任务.Yu等[48]提出一种新的关系检测模型Hierarchical Residual BiLSTM(HR-BiLSTM),实现了问题与关系之间的分层匹配.在关系检测模型中,作者将问句与关系的字词层面(Word-level)和关系层面(Relation-level)两个维度进行编码并计算两者之间的相似度,提高了关系识别的准确率.Zhang等[49]提出了一种改进的多路径多尺度的关系检测算法AdvT-MMRD,以提高KBQA任务的性能.其中作者将Bi-GRU用于语义相似度匹配,将CNN用于学习问题和关系之间文字层面的相似度.Qu等[50]针对大规模知识库中的简单关系问题提出了AR-SMCNN模型,其利用RNN和CNN的优势互补来获取语义和文字层面的相关信息.
此外针对传统语义解析方法可能存在的逻辑表达与知识库中的本体无法匹配的问题,Yih等[51]提出了一种基于知识库的新型语义分析框架,其可以将查询图直接映射到逻辑形式.因此语义解析过程被简化为查询图生成,并被表述为分阶段搜索问题.作者通过实体链接系统和卷积神经网络来提升自然语言问题到知识库中谓词序列的映射.Luo等[52]使用神经网络将复杂的查询结构编码成统一的向量化表示,从而能够成功捕捉复杂问题中各语义成分之间的相互作用,以此来解决复杂的KBQA任务.Yang等[53]提出了基于词嵌入技术的新方法,利用词嵌入技术将问句和候选逻辑表达映射为低维向量,通过对二者之间的相似性进行排序,最终使用选定的逻辑表达从知识库中检索答案.
由于自然语言问题表达的灵活性,理解自然语言并回答一些事实性问题仍面临着挑战,Dai等[54]针对大规模知识库的单事实问题提出了CFO(Conditional Focused Neural-network-based)方法.对于单事实问题,只需从问题中提取相应的实体和关系,即可利用找到的和对去知识库中寻找答案.因此作者将该问题转换为在给定问题时,找出最大化条件概率的实体关系对,并利用神经网络模型对该问题进行了处理.Zhao等[55]提出了一种子图排序和联合评分的方法以提高KBQA的性能.在子图排序中作者综合考虑了文字和语义层面的相似度,进而使用联合评分CNN模型在子图中寻找正确事实.Lukovnikov等[56]选择BERT作为用于微调的预训练模型并在KBQA任务中进行了应用.Gupta等[57]不再将KBQA任务分解为几个子任务(实体检测、实体链接、关系预测)进行处理,而是基于信息检索的思想将任务分为两个阶段,即候选答案的产生和候选答案的排序.Wu等[58]针对现有的KBQA算法无法对具有隐含时间约束的问题进行建模,提出了通过引入外部知识从问题中获取时间信息的方法.该方法基于双向注意力记忆网络模型,通过注意力机制和外部知识获取问题中的时间信息,以增强在具有隐含时间约束问题上的性能.
2.3.2 基于深度学习的End-to-End方法
该方法首先通过命名实体识别技术得到问题的实体词,并通过实体链接找到其在知识库中所对应的实体,以该实体为中心向外扩展(一跳或多跳)后得到知识库子图,子图中的实体即为候选答案.其次分别将问题和候选子图映射为低纬向量,经过不断训练使得正确答案与问句之间的相似度(计算两者点积)要大于错误答案与问句之间的相似度.最后在模型训练完成后则可根据候选答案和问题两者之间的得分进行筛选,并得到最终答案.
在端到端的知识库问答中比较经典的是Bordes等[59]提出的方法.该方法首先通过实体链接得到问句中所识别到的实体在知识库中所对应的实体.然后从该实体出发通过一跳或二跳扩展后得到知识库子图,其中子图中的每个实体都是候选答案.最后将问题和答案子图分别映射为向量表达,并通过点积操作获得问题和候选答案之间的相似度分值.其中作者分别从单一实体、路径表示和子图表示3个方面出发更加细化和全面的表示了候选答案的低纬向量,整体思路如图4所示.
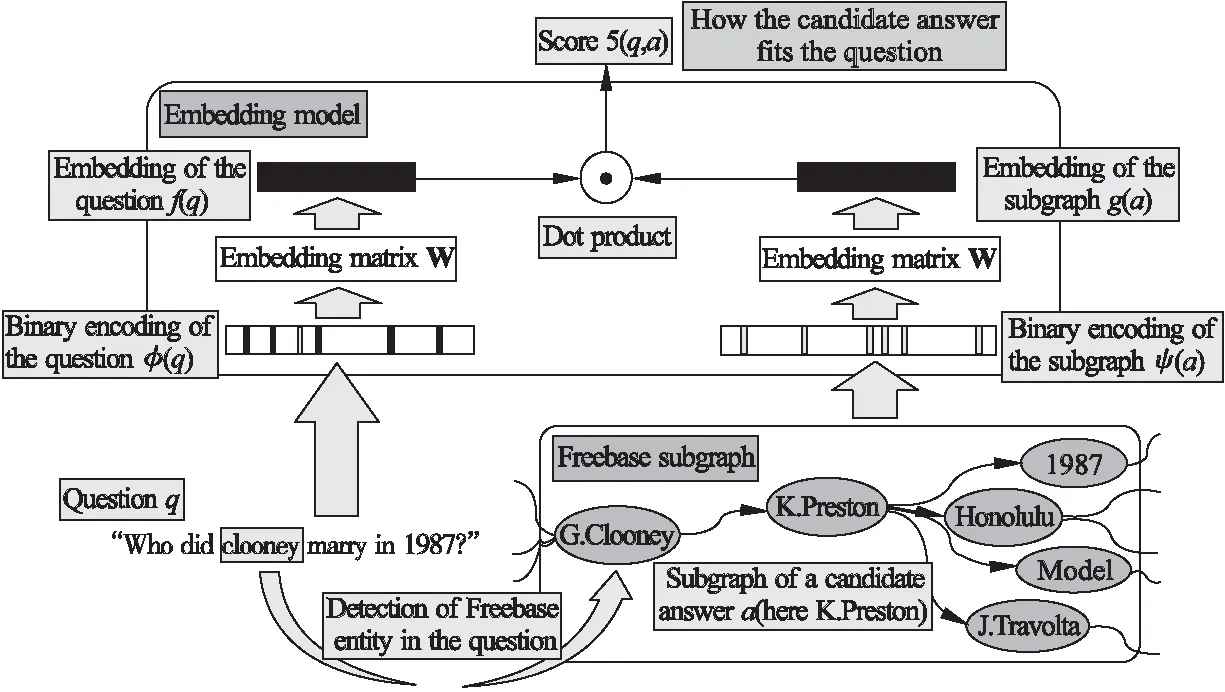
图4 子图嵌入模型[59]
Li等[60]在文献[59]的研究基础上提出了一种多列卷积神经网络的模型,并分别从候选答案实体的关系路径(Answer Path),上下文关系(AnswerContext)和答案类型(AnswerType)3个不同的方面来比较问题和答案的相似性.最后分别计算问题与候选答案3个方面的得分并将结果相加,综合得分最高的即为最佳答案.通过对文献[60]的实验结果分析发现答案类型和候选答案实体的关系路径对最终的结果影响较大,而候选答案实体的上下文关系对最终的结果影响较小.因此Hao等[61]在此基础上做了进一步研究.首先对神经网络模型进行了调整,使用了Bi-LSTM模型.其次因为候选答案实体的关系路径、上下文关系和答案类型对最终结果的影响是不同的,因此引入了交叉注意力机制,对答案的不同部分给予不同的权重.最后作者从候选答案的实体、关系、答案类型、答案上下文关系4个方面进行了考虑.Chen等[62]也从多个方面进行考虑提出了一个新的双向注意记忆网络BAMnet.通过注意力机制捕捉问句与知识库信息两两间的相关性,并利用此相关性增强问句的表示,希望能够结合到更多的知识库信息,以提升复杂问题的处理能力.
由于利用神经网络模型在对问题和答案进行建模时往往忽略背景信息的重要性,导致错误答案的得分会高于正确答案的得分,于是Shen等[63]提出了具有知识感知能力的双向长短记忆模型KABLSTM,通过引入背景知识来丰富问答的表征学习.该方法使用上下文引导的带注意力机制的CNN模型将背景知识嵌入到句子表示中,同时使用知识感知注意力机制将问答对的各部分进行相互关联.Huang等[64]针对简单问答提出了基于知识嵌入的问答系统框架(KEQA).KEQA的思想是在知识嵌入空间中联合恢复问题的头实体、谓词、尾实体的向量化表示,并根据作者提出的联合距离度量标准,将与知识库中的事实最接近的3个学习到的向量作为答案返回.由于自然语言的灵活性、多样性和模糊性,很难将问句的语义信息与答案进行匹配,Wang等[65]提出了一种基于知识图表示学习的问答方法TransE-QA,以端到端的方式来解决简单问答.该方法一共分为3个模块:问题模块、实体模块和关系模块.它将知识图表示学习算法(TransE)和问题分布式表示方法(TextCNN)相结合对问题和知识图进行联合训练.最后使用文中设计的评分函数,将排序后的Top-1实体作为问题的答案返回给用户.Tan等[66,67]针对知识库问答任务建立了基于双向长短期记忆网络(Bi-LSTM)的问题和答案的嵌入,并通过余弦相似度来衡量它们之间的相似度.Lukovnikov等[68]使用GRU网络并以端到端的方式来训练模型,只是作者在做词嵌入时采用了单词级别(Word-level)和字符级别(Character-level)两种级别的编码.He等[69]提出了一个字符级的编码框架用于KBQA任务中,并针对学习过程中遇到的3个关键问题进行解决.首先对于同一个问题有多种解释的问题,作者使用LSTM来对问题进行编码.其次使用字符级的编码方式来解决训练过程中可能出现的未登录词的问题.最后为了处理大规模知识库中数以百万计的实体和谓词,作者没有使用大的输出层来直接预测实体和谓词,而是将问题和KB的语义相似度作为结果输出.
2.4 常用数据集及研究进展
目前在知识库问答中使用较多的标准数据集是SimpleQuestions和WebQuestions数据集[70].由于之前的问答数据集比较小且问题的类型比较局限,于是Bordes等[71]构造了一个新的数据集SimpleQuestions.该数据集包含了10W多条问答对并被分成了训练集(79590条)、验证集(10845条)、测试集(21687条),该数据集只包含简单问题,也称为single-relation问题.WebQuestions是由Berant在2013年提出的[23],其中训练集包含3782条问答对,测试集包含2037条问答对.由于SimpleQuestions和WebQuestions数据集中都是相对简单的问题,于是在2016年Bao等[72]提出一种将多限制问题转换为多限制查询图的KBQA方法,并提供了一个多限制问题的数据集ComplexQuestions,用以测评复杂问题的KBQA系统性能,其中包含了2100条问答对.对目前KBQA系统在不同数据集上的研究进展进行总结,如表1所示.

表1 不同KBQA方法在标准数据集下的性能比较
2.5 KBQA研究方法总结
对KBQA目前比较流行的3种方法进行总结,如表2所示.

表2 KBQA方法优缺点总结
基于模板的KBQA方法最大的优点是查询响应速度快、准确率高,只要能够为自然语言问句编写模板就能够对问题进行回答.但是由于自然语言的灵活性和多样性,一个问题可能有多种表述方式,若尽可能对所有问句进行匹配,则需要构建庞大的模板库,这样不仅耗时耗力而且会降低查询效率.基于语义解析的方法也能够回答较为复杂的问题,但为了尽可能提高KBQA系统的表现,需要人工编写规则和标注大量的逻辑表达并进行有监督学习,否则如果遇到没有学习过的样本时就会导致系统的表现很差.基于深度学习的方法其优点是大大降低了人工成本,但对于简单问题(单边关系问题)表现较好,对于复杂问题不如前面两种方法.而且对一些时序敏感性问题也无法进行很好的处理,例如对于问题“who is johnny cash′s first wife?”,最终答案可能是第2任妻子的名字,模型只关注到了wife而忽略了first的含义.基于深度学习的方法是如今的研究重点,克服了传统知识库问答中的很多弊端,但如何将其用以解决复杂问答和提高问答系统的最终效果仍需要做进一步研究.
3 KBQA面临的问题与挑战
基于知识库的自动问答系统仍然存在着一些亟待解决的问题,接下来我们分别从以下几个方面对KBQA所面临的问题和挑战进行总结.
1)问题与知识的理解与匹配.由于自然语言问题具有灵活性和多样性,而知识库中的知识是以结构化存储的.因此将多样化的自然语言问题和结构化的知识库之间进行语义匹配是知识库问答所面临的一个挑战.在语义解析的方法中,先要通过对问句进行语义理解和解析并将其转换成为一种逻辑表达,进而将逻辑表达转换为可在知识库中执行的查询语句.但是在问句和知识库中的表达之间存在差异,并不是从问句中得到的所有信息(实体、关系)都能和知识库中的相关表达完全匹配,甚至对于一些概念在知识库中可能存在多种表达方式.比如对于问句“Where was Johannes Messenius born?”,问题是问“Johannes Messenius”的出生地是哪里,在知识库中对应的关系表示是“people/person/place_of_birth”.关键字“where ……born”和“place_of_birth”虽然在字符层面没有完全匹配,但其语义表达是相同的,因此在自然语言表达和知识库中的知识表达之间存在语义鸿沟问题.怎么将两者进行映射是解决该问题的关键.组合范畴语法(CCG)[21]通过定义词典的方法使得该问题得到了一定程度的解决,但是其中又会涉及到词典的构建、数据的消歧等,特别是在知识库非常庞大的情况下,如Freebase(2)https://developers.google.com/freebase知识库包含19亿个事实.随着深度学习的发展,更多的开始使用深度学习的方法来解决该问题.通过将不同的符号表示都映射到一个低纬向量表示,进而通过计算向量之间的相似度来得到我们想要的答案.通过深度学习的方法在一定程度上解决了语义鸿沟的问题,但其在一些复杂逻辑推理问题上表现并不是很好.
2)复杂问题的推理.对于SimpleQuestions这种单关系问题(single-relation)的问答,只要找到问题在知识库中所对应的事实就可以对该问题进行回答,由此我们需要做实体识别、实体链接、关系预测、推理[76].对于逻辑比较复杂的问题,就可能无法仅仅通过一个事实来得到答案而需要一跳或多跳的查询才能找到问题的答案.因此在知识库问答过程中需要知识推理和预测才能对复杂问题进行回答.传统的方法一般使用更复杂的语义匹配技术来匹配具有高表达能力的查询,使其能够对数据进行最高级、聚合等操作,而用户无需了解其内部表示.但是传统的基于谓词逻辑的推理策略存在覆盖度低、推理速度慢的问题,如何利用表示学习自动学习推理规则是一个难点[77].也有学者对此做了系统的研究,如Yang et al.文献[78]提出了一种用于学习参数以及知识库推理逻辑规则结构的端到端的可微方法NeuralLP(Neural Logic Programming).目前的基于表示学习的KBQA方法大多针对简单问题和单边关系问题,对于复杂问题效果并不理想.例如带限制条件的问题(Who was vice president after kennedy died?),聚合问题(How many languages do they speak in spain?),最高级(Which of the following does Australia export the most?).
3)事实的选择.解决简单关系问答的核心是在知识库中找到能够与该问题相匹配的事实,该事实就包含了问题的答案.在知识库中能够唯一表示一个实体的并不是实体的名字而是实体ID,因此对于单关系问题我们只要确定了实体ID和关系对(entity-relation pairs),就相当于找到了问题的答案.但在对候选事实进行选择的时候可能会遇到如表3中的情况.经过实体链接后我们发现最高得分的候选答案不止一个,其中候选实体的名字相同,也都具有相同的关系.那么怎样将包含正确实体m.012_0k9的事实选择出来而不是包含实体m.019xs5r的事实,目前并没有很好的解决方法.Modammed et al.文献[39]指出可以使用实体节点在知识库中的度(in-degree)来代表该节点的流行度,认为度比较高的节点比较常见,更可能是问题中所提到的实体.进而通过度对候选答案进行排序,排名Top-1的即为正确的事实.事实证明该方法在一定程度上解决了该问题,但还有相当一部分情况无法通过该方法得到有效的解决.

表3 事实选择示例
4)深度学习技术的局限.知识库问答系统的基础是自然语言处理,而随着深度学习技术的不断发展,也使得知识库问答取得了长足进步.但由于自然语言本身的复杂性和算法的局限性,使得问答系统的准确度还远不能满足实际需求.例如利用深度学习技术在对问句“who is johnny cash′s first wife?”进行学习时,就很难学习到问句中first这种带有简单推理情况的含义而对最终的结果造成影响.又如目前深度学习应用于知识库问答系统主要是通过人工标注数据并有监督的学习,这就会面临问答系统对于新内容、新知识无法处理的情况.由此我们要不断的标注新数据来应对该情况的发生,但自然语言具有多样性和复杂性,通过人工标注的方法显然是不能满足实际需求的.因此,利用深度学习对新知识、新内容能够进行自主学习的无监督学习方法,才是实现知识库问答系统的关键技术难题.
4 总 结
本文首先对问答系统及其发展进行简单介绍,通过对知识图谱的介绍进而引出基于知识库的问答系统(KBQA).随后对知识库问答系统的研究方法包括基于模板的方法、基于语义解析的方法和基于深度学习的方法进行了较为全面的介绍,并对常用数据集和最新研究进展进行了总结.在最后部分我们对目前的知识库问答系统在实现过程中可能面临的问题与挑战进行了阐述.通过对KBQA各类方法较为全面的介绍和总结,为读者能够快速进入该领域展开研究提供帮助.
