基于信息距离的文献个性化知识发现系统的设计与实现
2021-08-23刘爱琴刘扬
刘爱琴 刘扬

摘 要 本文基于信息距离的文献个性化知识发现系统,首先基于文献领域本体对用户输入得到的概念扩展集进行修正处理,形成更符合用户兴趣的概念集合;其次,借助兴趣概念集合,将主题词和与其互相关联的知识匹配,实现用户层级的知识发现;最后,融入基于信息距离和信息层次的个性化推荐算法,对锚定的未评分文献集合进行打分排序,采用Top-N算法,从中挖掘出更深度的知识关联,形成推荐列表,实现个性化的文献知识发现。该系统一方面改善了基于内容的知识发现系统中结果过于专一化和延展性差等问题,扩展了查询粒度;另一方面通过信息量权重的引入,在提高知识检索效率和知识推荐准确度的同时,实现了更为精准的个性化知识发现。
关键词 信息距离 兴趣概念集合 文献个性化 知识发现系统
分类号 G251.6
DOI 10.16810/j.cnki.1672-514X.2021.07.010
Design and Implementation of Personalized Knowledge Discovery System Based on Information Distance
Liu Aiqin, Liu Yang
Abstract Based on the literature personalized knowledge discovery system of information distance, this paper corrects the concept extension set obtained by the user based on the literature domain ontology, and forms a collection of concepts that more in line with the users interest. Secondly, with a collection of interest concepts, matching subject words and interrelated knowledge to achieve knowledge discovery at the user level. Finally, the personalized recommendation algorithm based on information distance and information level is integrated to rank the collection of unscored literature, and the Top-N algorithm is used to excavate the deeper knowledge correlation, form the recommendation list and realize the personalized literature knowledge discovery. On the one hand, the system improves the problems of excessive specialization and poor elongation of the results in the content-based knowledge discovery system, expands the granularity of query. On the other hand, with the help of information content, it can realize more accurate personalized knowledge discovery while improving the efficiency of knowledge retrieval and the accuracy of knowledge recommendation.
KeywordsInformation distance. Collection of interest concepts. Literature personalization. The knowledge discovery system.
1 研究背景
由于用户信息服务的重点和难点正从文献获取转变为知识发现[1],因此打破以往的书刊目录、文献索引和部分文献全文利用的局限,引入知识挖掘、索引规则构建信息资源的立体知识网络[2],为用户提供具有完善、高效的知识挖掘与数据分析功能的知识发现系统[3]迫在眉睫。
发现系统经历了传统资源发现、学术资源发现和知识发现三个阶段。第一阶段,全球第一个资源发现系统Summon,其重点放在资源发现功能上,信息服务体系未能形成。第二阶段,发现系统从出版商、内容商、大学、公开网站等提取各类有价值的数据信息资源[4],实现了资源获取。目前,知识发现系统的发展正处于第三阶段,一方面致力于解决复杂异构数据库群的集成整合,完成高效、精准、统一的学术资源搜索;另一方面通过聚类、分析、抽取等算法研究实现高价值学术文献发现、纵横结合的深度知识挖掘和可视化的全方位知识关联,并将潜在有用的知识直接传递给用户, 为用户提供个性化的知识服务[5]。
针对不同个性化知识发现系统的算法,国内外学者都在积极展开着相关研究。P. Ganesan[6]提出的基于边权重和有向节点的信息距离相似度计算方法帮助实现项目推荐;Wu and Palmer[7]方法则认为语义相关度是通过衡量两个概念的公共父节点与这两个概念的路径距离而得出;Degemmis[8]用WordNet代替基于关键词的传统方法,结合语义网与基于内容的推荐算法,计算项目之间相似度距离进行推荐;Y.Zhang[9]通过自适应过滤技术对用户的配置文件进行更新,将有关用户喜好的信息进行整理总结,与Web文件流中的相关内容进行距离对比,将相关性最高的文件推荐给用户;Debnath[10]研究了不同特征信息权重的提取方法,并对其推荐效果进行综合评估。国内学者黎雪微[11]提出了一种基于语义关联和信息距离的个性化推荐方法,在传统语义相似度上融入信息量理论,实现了用户兴趣偏好的有效迁移;林鑫[12]针对基于内容的个性化推荐策略,提出资源信息特征选择与权值计算优化策略,从而改善个性化推薦的效果。严凡[13]等利用卷积神经网络的特征提取功能,对图书主题信息进行挖掘,通过信息权重计算向量相似度将得分靠前的图书推荐给读者。
综上可见,当前的研究集中于关键字与本体概念的距离算法研究和推荐,而基于文献知识发现系统的研究刚刚起步。基于信息距离研究用户兴趣的个性化需求能够扩散用户偏好,改善推荐系统中过于专门化的问题,有效提高个性化知识发现的推荐效果,因此本文基于文献領域本体和用户兴趣模型,首先对用户输入得到的概念扩展集进行修正处理,形成更符合用户兴趣的概念集合;其次,借助用户兴趣概念集合在标准化数字资源库中进行文献查询,实现用户层级的知识发现,并且对与该主题词互相关联的主题词进行检索并匹配相关的知识,共同展示给用户;第三,在用户已评分文献的基础之上,融入基于信息距离和信息层次的个性化推荐算法,对锚定的未评分文献集合进行打分排序,采用Top-N算法,从中挖掘出更深度的知识关联,形成推荐列表,实现个性化的文献知识发现。
2 信息距离算法理论基础
在信息科学中,对于任意两个带有信息的实体的信息距离,Bennett等人在1998年给出了定义。由于信息距离不可计算,在实际应用中,我们需要用不同方法对信息距离进行测度。
2.1 信息层次测度
以语义树为架构,采用基于边权重和有向节点的信息层次相似度的计算方法,假设用户感兴趣的文献实例m与目标文献实例n都属于同一个类,且m、n之间存在层次相关性,两实例的层次距离相似度表示为公式(1)。
(1)
其中,LCP(Lowest Common Parents)指最低层级的公共双亲,LCP(m,n)表示m、n最近的公共双亲,即到m、n的具有最短路径的公共双亲,任意两个结点都有至少一个根结点作为其公共双亲;depth(m)表示根结点到结点m的上一层级的双亲结点的路径长度。如果两个实例为一个类的子类,则depth(LCP(m,n))=depth(m)=depth(n),即它们的层次距离相似度为1;如果两实例的最近公共双亲(LCP)为根结点,则其层次距离相似度为0。
2.2 信息量距离测度
基于信息层次的相似度计算存在默认本体中所有路径所处权重相同的问题,但是每个结点因其所包含的子结点数量的不同,包含的信息量也不同,因此在知识发现中目标文献存在偏差。为此,本文引入基于王浣尘提出的信息距离测度计算模型来解决此类问题,并将结点所包含的信息量表示为结点所包含的子结点在所有结点的权重,结点a可表示为公式(2)。
(2)
其中,a表示本体中的某个结点,k是a的子结点,weig(a)表示a所包含的子结点总数。同时,为了表示a的子结点数在本体所有结点中所占的权重p(a),可表示为公式(3),由此计算得出的信息量IC(a)根据结点a所在本体层次的高低而变化,可表示为公式(4)。
(3)
(4)
结点位置越高,p(a)的值越大,但IC(a)越小,即结点信息量随结点层次位置的上升而递减,反之递增。反映了处于高层次的结点所包含的信息量少,含义抽象;处于低层次的结点包含的信息量多,含义更加具体。
假设一对父子结点a、b,两者之间由于信息层次不同而信息量存在差异,则将两者之间的信息量差表示为公式(5)。
(5)
假设两个具有共同上层结点的实例m、n,通过属性结点联通,两者之间的信息距离可以表示为联通路径上每个结点之间的信息量差之和,假设有n段结点路径,则m、n的信息距离可表示为公式(6)。
(6)
两结点之间可能存在不只一条的联通路径,假设m、n之间有s条路径,第i条路径的信息距离可表示为ICdistancei(m,n),则m、n之间的信息距离相似度表示为公式(7)。
(7)
2.3 基于信息层次和信息距离的综合相似度
通过信息量差得出的信息距离相似度修正信息层次距离相似度,解决了原先的层次距离相似度中路径权重相等问题,使结果得到一定的扩散。为两者之间设定权重 (0≦≦1),修正后的综合相似度(Comprehensive Similarity)表示为公式(8)。
(8)
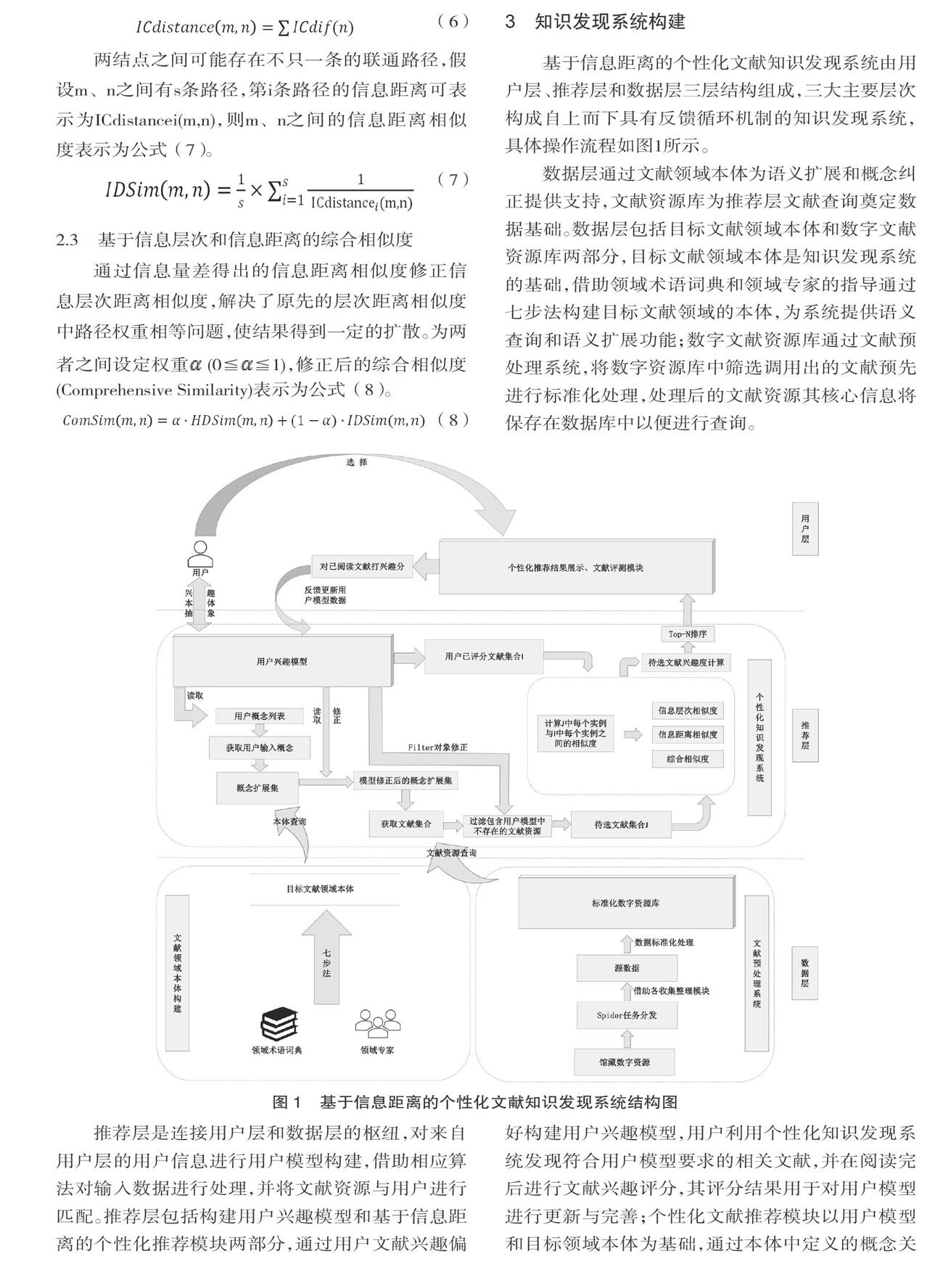
3 知识发现系统构建
基于信息距离的个性化文献知识发现系统由用户层、推荐层和数据层三层结构组成,三大主要层次构成自上而下具有反馈循环机制的知识发现系统,具体操作流程如图1所示。
数据层通过文献领域本体为语义扩展和概念纠正提供支持,文献资源库为推荐层文献查询奠定数据基础。数据层包括目标文献领域本体和数字文献资源库两部分,目标文献领域本体是知识发现系统的基础,借助领域术语词典和领域专家的指导通过七步法构建目标文献领域的本体,为系统提供语义查询和语义扩展功能;数字文献资源库通过文献预处理系统,将数字资源库中筛选调用出的文献预先进行标准化处理,处理后的文献资源其核心信息将保存在数据库中以便进行查询。
推荐层是连接用户层和数据层的枢纽,对来自用户层的用户信息进行用户模型构建,借助相应算法对输入数据进行处理,并将文献资源与用户进行匹配。推荐层包括构建用户兴趣模型和基于信息距离的个性化推荐模块两部分,通过用户文献兴趣偏好构建用户兴趣模型,用户利用个性化知识发现系统发现符合用户模型要求的相关文献,并在阅读完后进行文献兴趣评分,其评分结果用于对用户模型进行更新与完善;个性化文献推荐模块以用户模型和目标领域本体为基础,通过本体中定义的概念关系帮助用户在文献资源库中匹配相关文献,并根据用户已评分文献集和待选文献集之间的信息层次与信息距离相似度计算待选文献兴趣度并进行排序,生成个性化推荐结果。
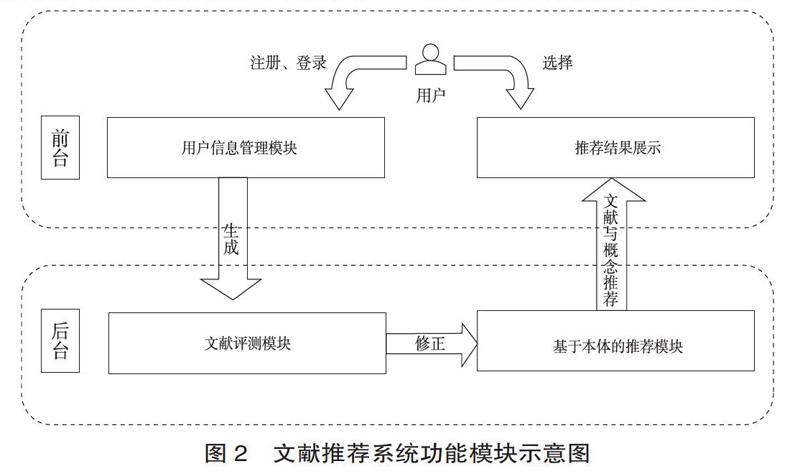
用户层是知识发现系统的可视化交互平台,将用户相关信息和输入内容传递到推荐层,并将推荐结果以可视化形式展示,同时会搜集用户信息和评测分数反馈给下层,便于推荐层进行数据完善。用户层包括用户信息管理模块、基于本体的文献推荐模块和文献评测模块(如图2)。
用户信息管理模块为用户提供注册、登陆、个人信息、历史记录等功能。用户登陆后,系统读取用户信息并抽象为用户模型,在用户输入搜索信息后,系统通过用户模型和本体知识库为用户推荐其可能感兴趣的文献集,按照Top-N算法的排序顺序以列表形式展示给用户,在用户阅读完文献后将对其进行评测打分,根据用户兴趣分对用户模型进行更新,完善升级系统推荐功能。
4 知识发现系统实现测试结果
利用中国知网CNKI数据库对上述基于信息距离的个性化文献知识发现系统进行仿真验证。首先,借助于Python爬虫技术,检索关键字“知识发现”,并选取前300篇文献形成实验的数字文献资源库,同时对文献摘要进行领域本体概念的修正与扩展,形成目标文献领域本体。部分爬虫代码和获得的由文献与领域主题词构成的仿真实验数据库如图3和图4所示。
其次,分析用户的访问历史数据,形成用户兴趣本体UserModel,并在领域文献本体LiteratureModel定位已评分文献。假设用户通过知识发现系统中的文献评测模块对文献集合I={I1,I2}进行自主评分,其中,l1表示文献集合元素基于知识发现的图书馆个性化知识服务研究,兴趣度0.8;l2表示文献集合元素共词分析法用于文献隐性关联知识发现研究,兴趣度0.2,系统根据兴趣分数更新用户模型,形成用户已评分文献集合I。随后,用户本体对文献资源库进行修正过滤,形成锚定待选文献集合J。然后,基于信息层次与信息距离的相似性测度计算I与J之间的综合相似度。最后,利用已评分文献I的兴趣度来推测未评分文献J的兴趣度,并对兴趣度从高到低排序,生成Top-N个性化推荐列表。结果如表1所示。
最后,采用LDA主题分析,通过相关算法、数据挖掘、优化等对Top-N个性化推荐列表进行解释,解释结果详见图5和图6。
在图5中,圆表示不同主题,圆的大小表示主题的重要程度,以深色突出显示重要程度最大的主题圆。通过以上分析,可见在LDA分析的十个主题中,主题1的重要优先级高于其他主题,其他主题由于出现的词频为前30的关键字数量较少且频率较低。
图6通过数据统计,以条形图方式列出了与主题最有关的前30个词语以及相应的词频。主题1作为最重要的主题,条形图展示了对应主题中出现的词语以及词频,每个词语的频率代表了其相应的比重。利用该结果,可以将同一主题的相关知识进行整合,并通过主题词共现方式提取知识关联。
5 结语
基于信息距离的文献个性化知识发现系统将信息层次相似度和信息量距离相似度综合起来对用户兴趣进行扩散,一方面改善了基于内容的知识发现系统中结果过于专一化和延展性差等问题,扩展了查询粒度;另一方面通过对信息量权重的引入,在提高知识检索效率和知识推荐准确度的同时,实现了更为精准的个性化知识发现。
参考文献:
廖凤,周静怡.国内外文献数据库个性化服务研究[J].图书情报工作,2010,54(13):67-70,146.
赵功群,王恒.国内三大中文发现系统比较分析及评价[J].图书馆研究,2016,46(6):72-77.
廖志江.知识发现及数字图书馆知识服务平台建设研究[J].情报科学,2012,30(12):1849-1853.
曾建勋.资源发现系统的颠覆性[J].数字图书馆论坛,2016,(2):1.
陆韡.面向OA资源的图书馆知识发现系统应用研究[J].图书馆工作与研究,2019(10):83-88.
PRASANNA G, HECTOR G M, JENNIFER W.Exploiting hierarchical domain structure to compute similarity[J].ACM Trans.Inf. Syst.2003,21 (1):64-93.
RADA R, MILI H, BICKNELL E, et al. Development and application of a metric on semantic nets[J]. IEEE Transactions on Systems, Man and Cybemnetics, 1989, 5(s): 17-30.
DEGEMMIS M, LOPS P, SEMERARO G. A content-collaborative recommender that exploits WordNet-based user profiles for neighborhood formation[J].User Modeling and User-Adapted Interaction,2007,17 (3):217-255.
ZHANG Y, CALLAN J. Maximum likelihood estimation for filtering thresholds[C].Proceedings of the 24th annual interational ACM SIGIR conference on Research and development in information retrieval.New York.2001.294-302.
DEBNATH S, GANGULY N, MITRA P. Feature weighting in content based recommendation system using social network analysis[C].Proceedings of the 17th international conference on World Wide Web. ACM,2008:1041-1042.
黎雪微,應时,洪伟.基于语义关联和信息距离的个性化推荐方法研究[J].情报理论与实践,2019,42(11):142-149.
林鑫,桑运鑫,龙存钰.基于用户决策机理的个性化推荐[J].图书情报工作,2019,63(2):99-106.
严凡,张霁月.基于图书语义信息的推荐方法研究[J].图书馆学研究,2018,(21):40-45.
刘爱琴 山西大学经济与管理学院副教授。 山西太原,030006。
刘 扬 山西大学经济与管理学院本科生。 山西太原,030006。
(收稿日期:2020-07-18 编校:左静远,刘 明)
