基于机器视觉与YOLO算法的马铃薯表面缺陷检测*
2021-08-23傅云龙梁冬泰陈贤儿
□ 傅云龙 □ 梁 丹 □ 梁冬泰 □ 方 宁 □ 陈贤儿
宁波大学 机械工程与力学学院 浙江宁波 315211
1 研究背景
近年来,随着我国马铃薯主粮化战略的实施,马铃薯在我国的种植面积迅速增大,成为仅次于水稻、小麦、玉米的种植面积第四大粮食作物[1-2]。我国马铃薯种植面积为5.8×104km2左右,年总产量约9.9×108t,位居世界第一[3]。马铃薯不但有较高的食用价值和药用价值[4],而且因自身含有丰富的淀粉,成为塑料、造纸、化工等领域不可缺少的原材料。马铃薯在采摘、运输、储存过程中,不可避免会存在发芽、病斑、机械损伤、腐烂等表面缺陷,影响马铃薯的品质与食用安全性。
目前,在进行马铃薯表面缺陷检测时,主要由人工进行分拣,工作强度大,效率低,可靠性和一致性比较差[5],严重阻碍马铃薯加工自动化产业的发展。随着机器视觉技术的发展[6],国内外学者针对马铃薯缺陷机器视觉检测方法开展了相关研究。王溯源[7]将马铃薯表面缺陷统分为三类,分别基于六角锥体颜色空间、三基色颜色空间、单值段同化核算子实现三类表面缺陷的检测。赵明富等[8]应用高光谱成像技术和改进的贝叶斯分类器,实现对马铃薯外部缺陷的识别,平均识别精度达到95%以上。杨森等[9]基于轻量卷积网络实现马铃薯外部缺陷的无损检测,平均识别准确率能够达到96.04%。 Zhang等[10]采用单次激发法多光谱成像系统,建立一种基于全特征集的最小二乘支持向量机马铃薯缺陷分类模型,能够检测六类马铃薯表面缺陷。上述研究中,基于传统图像处理和高光谱成像技术的方法,虽然能够实现马铃薯表面缺陷的识别,但是识别缺陷种类和精度有限,系统的稳定性较差。基于轻量卷积网络的方法虽然提高了系统的稳定性,但是识别精度和识别速度仍有待提高。
针对马铃薯表面缺陷快速准确检测的需求,笔者提出一种基于机器视觉和YOLO算法的马铃薯表面缺陷检测方法。
这一方法采用图像增广对原始图像进行扩充,通过最大类间方差法将部分数据集的马铃薯图像从背景中分离出来,用于预训练。建立基于YOLO算法的马铃薯表面缺陷识别方法,对原YOLO算法中的聚类方法进行改进,基于二分K均值聚类算法进行目标框聚类分析。在训练过程中,采用分步训练方式优化学习权重,提高检测方法的稳定性和检测精度。
2 数据集构建
2.1 图像采集
马铃薯常见的表面缺陷主要有腐烂、发芽、机械损伤、虫眼、病斑五类,如图1所示。
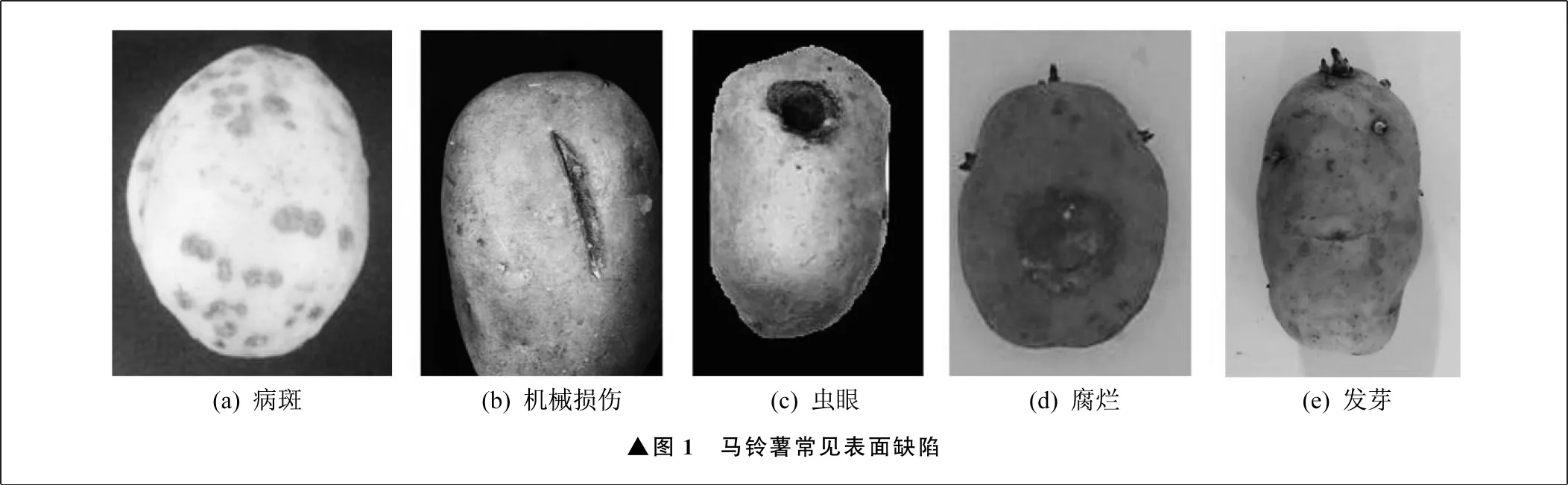
▲图1 马铃薯常见表面缺陷
从宁波市某批发市场筛选73个带有表面缺陷的马铃薯和28个完好的马铃薯,用工业相机在不同的光照强度和背景下采集363张马铃薯图像。市场采购的马铃薯,表面缺陷的多样性有限,不能满足工业数据集的要求,因此从网络上另外收集687张带有表面缺陷的马铃薯图像。
2.2 数据扩增
为避免数据集不足造成训练过程中产生过拟合问题,笔者通过调节亮度和对比度、旋转、翻转、缩放、高斯模糊、添加椒盐噪声等方法,进一步对原有的马铃薯数据集进行增广。采用最大类间方差法对原始数据集进行灰度阈值分割,去除背景,凸显马铃薯表面特征,使YOLO算法在预训练过程中能更快地学习马铃薯缺陷特征。
通过以上方式,将原有1 050张马铃薯图像数据集扩增至7 123张,数据集见表1。

表1 马铃薯数据集
最大类间方差法具有良好的自动阈值分割性能,基本思路是按照图像灰度特性将原始图像灰度值分为两部分,使两部分间的灰度值差异最大,同时每部分内部差异最小。假设原始图像大小为M×N,灰度值阈值为T,图像中像素属于目标部分的灰度值区间为(T,L],像素属于背景部分的灰度值区间为[0,T],灰度值k对应的像素数记为Nk,对应的概率记为Pk,Pk为:
Pk=Nk/(M×N)
(1)
则类间方差g(T)为:
g(T)=ω1(T)[μ(T)-μ1(T)]2
+ω2(T)[μ(T)-μ2(T)]2
(2)
式中:ω1(T)、ω2(T)分别为像素被分为背景部分和目标部分的概率;μ1(T)、μ2(T)为两类像素的均值;μ(T)为图像的整体均值。
(3)
(4)
(5)
(6)
μ(T)=μ1(T)ω1(T)+μ2(T)ω2(T)
(7)
将式(7)代入式(2),化简得:
g(T)=ω1(T)ω2(T)[μ1(T)-μ2(T)]2
(8)
令T遍历灰度值区间[0,L],寻找g(T)的最大值,此时所对应的T即为所求阈值。
2.3 数据标注
笔者通过labelImg图像标注软件对7 123张马铃薯图像进行在线标注,其中发芽、机械损伤、腐烂、虫眼、病斑的类别号依次为0~4。缺陷标签内容见表2。将原图像长、宽归一化至0~1,然后以(x,y)代表缺陷中心坐标,w、h分别代表缺陷目标框的长和宽。
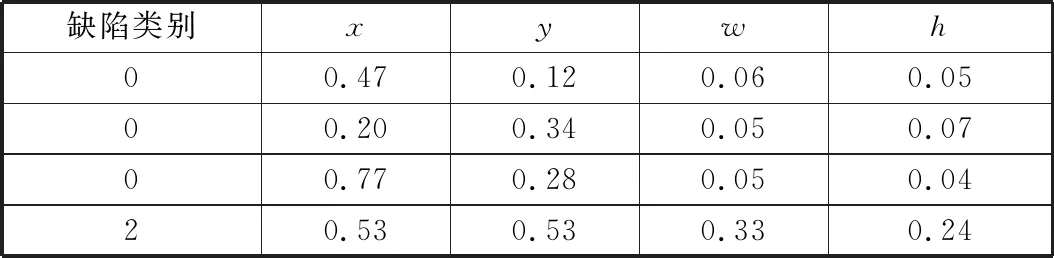
表2 缺陷标签内容
3 识别方法
3.1 YOLO算法
YOLO算法是一种端对端学习的深度学习模型算法[11-14],不同于基于候选区域的深度学习模型算法,不需要提取候选区域,可直接输入图像获得目标类别和目标边框,拥有较好的检测速度和精度。YOLO V4算法在YOLO V3算法目标检测架构的基础上,对数据处理、网络训练、激活函数、损失函数等进行优化。
笔者基于YOLO V4算法来实现马铃薯表面缺陷识别。马铃薯表面缺陷识别YOLO V4算法网络结构如图2所示,这一网络结构由输入端、主干网络、颈部、检测头四部分组成。输入端引入马赛克数据增强和自对抗训练两种新的数据增强方法,增强图像可变性,提高目标检测系统的稳定性。通过自对抗训练改变原始图像,使神经网络对自身进行对抗性训练。颈部采用路径聚合网络附加空间金字塔池化结构,空间金字塔池化结构采用内核为1×1、5×5、9×9、13×13的最大池化层串联结构。图2中,Mosaic为马赛克数据增强,SAT为自对抗训练,CBM为Mish卷积块,CSP1~CSP5为跨阶段局域网络,CBL为泄漏线性单元卷积块,SPP为空间金字塔池化结构,PAN为路径聚合网络。
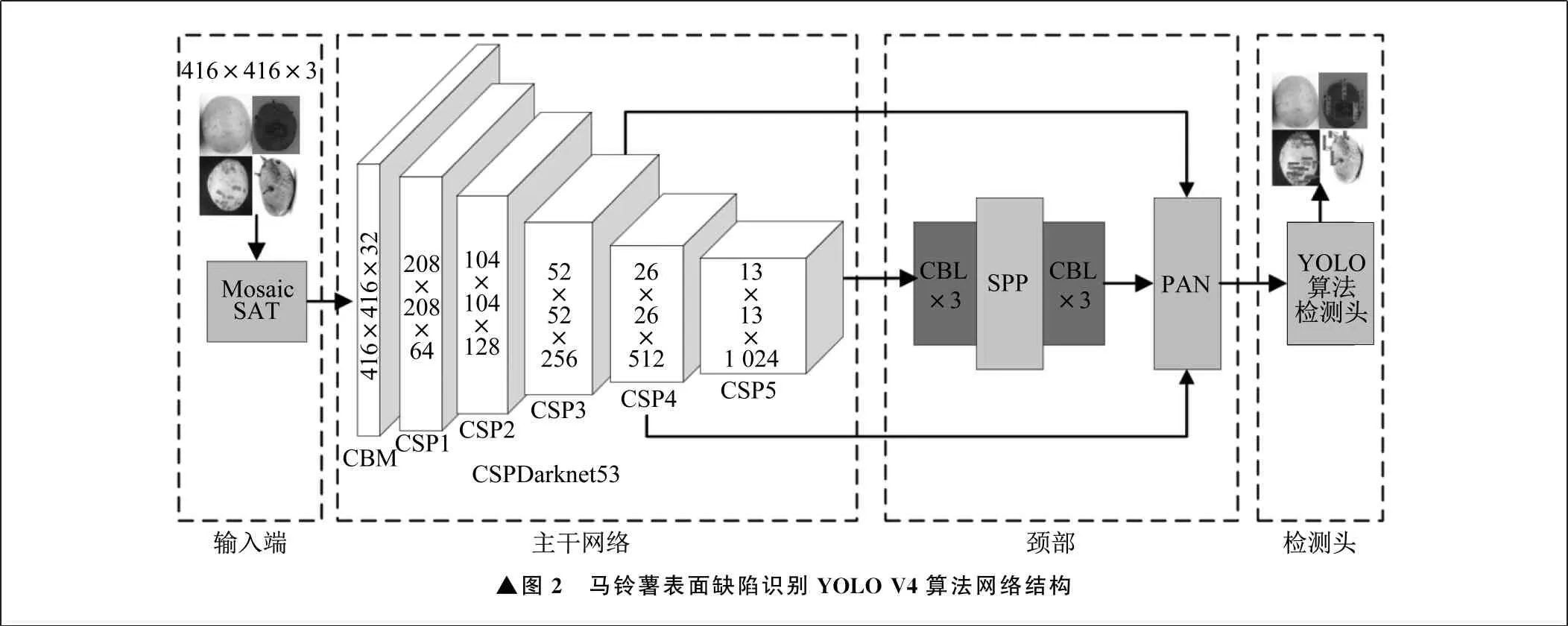
▲图2 马铃薯表面缺陷识别YOLO V4算法网络结构
马铃薯表面缺陷的识别流程如下:首先,构建马铃薯表面缺陷图像数据集,通过马赛克数据增强和自对抗训练,对原始数据集进行图像增强处理;然后,使用CSPDarknet53主干网络提取不同尺度的马铃薯表面缺陷特征,由颈部完成缺陷特征的路径聚合;最后,由YOLO算法检测头完成目标框和目标类别置信度的检测。置信度C为:
C=PrI
(9)
(10)
式中:Pr为用于判断是否有目标物落入候选网格的值,有为1,没有为0;bP为预测目标框面积;bT为真实目标框面积;I为交并比。
3.2 特征提取网络
马铃薯表面缺陷识别方法采用CSPDarknet53作为特征提取的主干网络,将Darknet53网络原有的残差块与跨阶段局域网络相结合,以减小整个网络的计算量,缩短计算所需要的时间,并且保证检测的准确率。CSPDarknet53主干网络结构由五个跨阶段局域网络构成,跨阶段局域网络3~5是三个有效输出层,分别输出52×52×256、26×26×512、13×13×1 024图像特征。跨阶段局域网络将浅层映射特征分为两部分,对两部分信息进行融合。跨阶段局域网络将梯度信息融合在特征图中,避免梯度信息重复,在缩短网络计算量的同时保证准确率。
残差单元由特征提取层与两个卷积块经过两层卷积构成。卷积块是CSPDarknet53主干网络中最基本的单元,由Mish函数、批归一化和卷积操作组成。
与传统带泄漏线性单元函数和线性单元函数相比,使用Mish函数作为主干网络激活函数,可以优化梯度流。Mish函数具有的平滑特性使图像信息能更深入地融合进神经网络,以获得更好的精度和泛化能力。主干网络Mish函数H(a)为:
H(a)=atanh[ln(1+ea)]
(11)
式中:a为图像像素经卷积操作后的像素值。
3.3 二分K均值聚类算法目标框分析
目标框指置信度最高的检测目标所在的矩形框,传统深度学习方法通过多尺度窗口滑动遍历来进行选取。YOLO算法在COCO数据集中进行K均值聚类分析,得到一组先验框,在训练过程中根据先验框匹配程度来调整目标框。 COCO 数据集所包含的检测对象多种多样,所聚类的先验框在自然场景中具有较好的检测效果。由于马铃薯表面缺陷识别的对象是五类典型缺陷,使用原有先验框检测难以满足实时快速检测要求,因此需重新进行先验框聚类分析。
K均值聚类算法是一种无监督的聚类分析算法,对于给定的样本集,按照样本的分布将样本划分为K个簇,并随机选取K个对象作为初始的聚类中心,计算每个对象与各子聚类中心的欧氏距离。欧氏距离D为:
D=1-I
(12)
采用误差二次方和准则函数作为聚类准则函数,误差二次方和J为:
(13)
式中:ni为第i个聚类样本点数量;mi为第i个聚类中心;xij为第i个聚类中的第j个样本点。
K均值聚类算法收敛速度相对较快,聚类效果较优,但最终结果和运行时间受初始聚类中心选取的影响较大,初始聚类中心选择不当,很可能会造成局部最优解。为解决随机初始聚类中心点问题,笔者采用二分K均值聚类算法来进行目标框分析。二分K均值聚类算法不需要选取初始聚类中心,由一个样本集分裂后得到两个簇,对于K个簇则进行K-1次分裂,具体流程如图3所示。经过多次试验,在K为9的情况下,二分K均值聚类算法得到的马铃薯表面缺陷检测先验框最优,分别为(18,18)、(22,37)、(40,25)、(39,62)、(75,43)、(71,81)、(165,80)、(82,165)、(210,211)。
4 试验分析
4.1 模型训练
在笔者试验平台中,中央处理器采用英特尔酷睿i3-9100,主频为3.6 GHz,图形处理器采用英伟达GTX 1080Ti,显存为11 GByte,内存为16 GByte。模型参数中,输入图像大小为418像素×418像素,类别数设置为5,每次训练输入的图片数量为 64。动量值设为 0.949,权重衰减因数设为 0.000 5,学习率设为 0.001,最大迭代次数设为30 000。
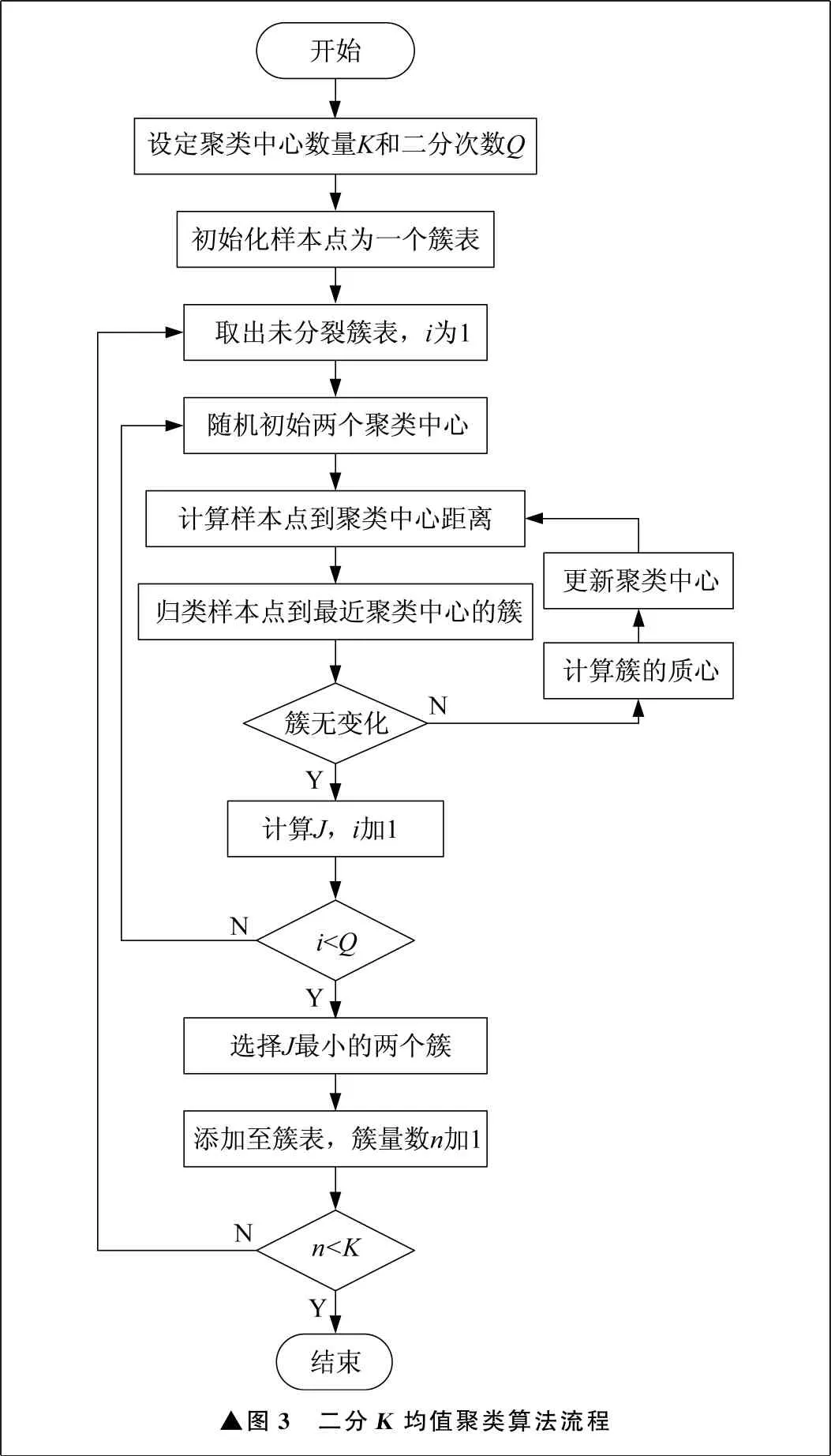
▲图3 二分K均值聚类算法流程
为提高马铃薯表面缺陷检测精度和模型训练速度,笔者用分步训练方式优化模型参数。
对最大类间方差法处理后的950张马铃薯图像进行预训练。经过最大类间方差法处理的图像没有背景因素干扰,模型可以更快、更准确地学习马铃薯表面缺陷特征,但此时模型稳定性较差。
为提高模型稳定性和检测精度,在预训练权重基础上,对数据集7 123张图像进行多次训练。
在基于YOLO算法的马铃薯表面缺陷识别训练过程中,每训练100次采集一次损失函数值,损失函数值变化曲线如图4所示。在训练过程中,迭代至24 000次和27 000次时,学习率开始衰减。由图4可知,随着迭代次数的增加,损失函数值不断减小,在训练到25 000次时,损失函数值已经趋于平稳。
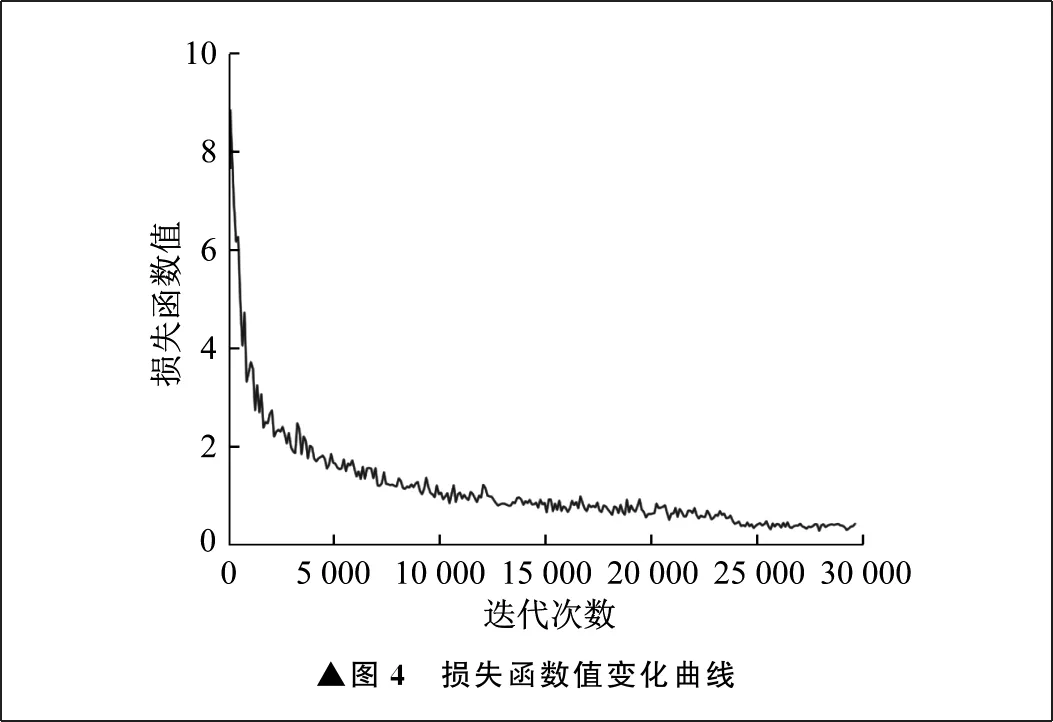
▲图4 损失函数值变化曲线
4.2 评价标准
通过精度AP、平均精度MP、识别时间t三个主要指标来评价马铃薯表面缺陷检测的效果。召回率R为:
(14)
精确率P为:
(15)
平均精度MP为:
MP=AP/E
(16)
式中:Tp为马铃薯表面有缺陷样本被检测为有缺陷的数量;Fp为马铃薯表面无缺陷样本被检测为有缺陷的数量;FN为马铃薯表面有缺陷样本被检测为无缺陷的数量;E为识别数量。
4.3 缺陷检测
选取360张马铃薯图像用于测试笔者提出的马铃薯表面缺陷检测方法的识别效果,每类缺陷图像均在60张以上,其中38张图像至少包含两种缺陷,另有无缺陷图像60张。识别结果如图5所示,在不同背景下,笔者提出的检测方法均能够准确识别缺陷位置和缺陷种类,对60张无缺陷的马铃薯图像,也均可以实现准确检测。
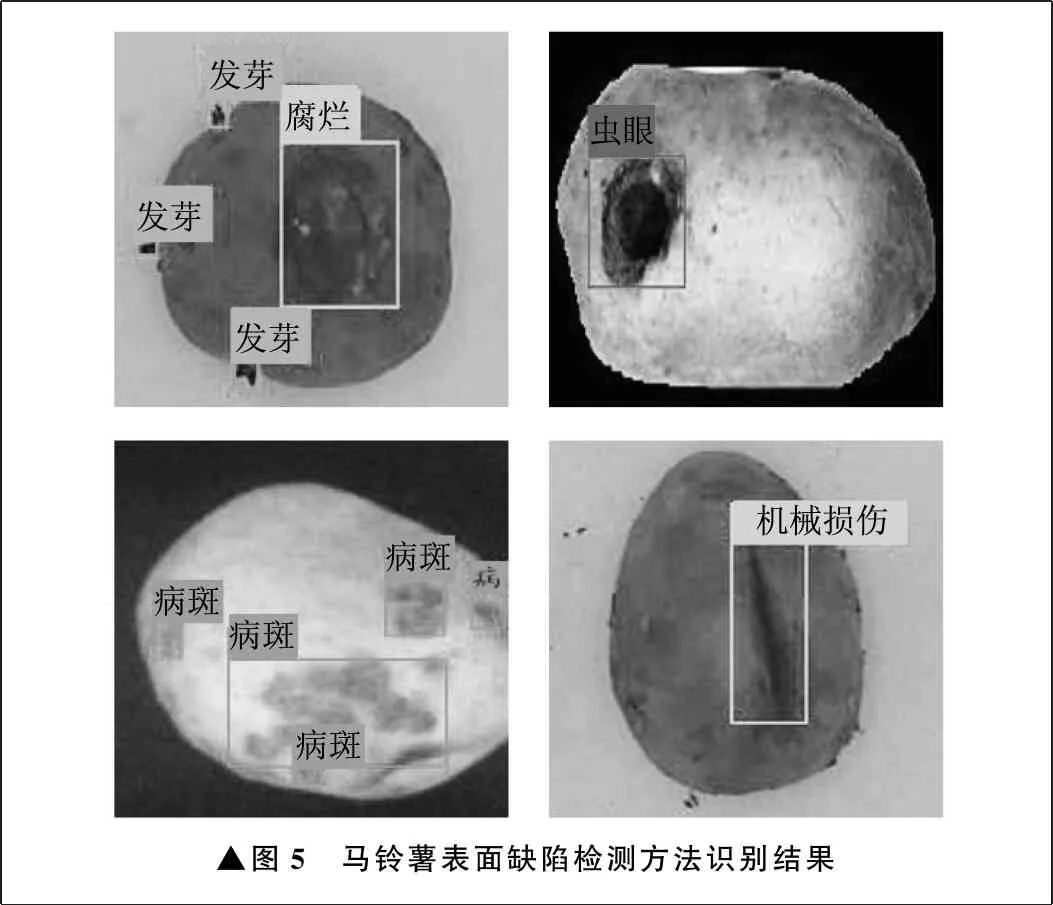
▲图5 马铃薯表面缺陷检测方法识别结果
为进一步分析马铃薯表面缺陷检测方法的识别效果,与高光谱成像法、基于轻量卷积网络的方法、多光谱成像法、原YOLO V4算法进行对比,对比结果见表3。表3中,×表示方法不能检测,Δ表示没有试验数据。对于发芽缺陷,高光谱成像法和笔者方法识别精度达到100%,原YOLO V4算法和多光谱成像法识别精度不足90%。对于机械损伤缺陷,笔者方法明显高于其它方法。对于病斑缺陷,笔者方法识别精度相比原YOLO V4算法提高了10个百分点以上。对于虫眼缺陷,笔者方法与原YOLO V4算法的识别精度均达到100%,多光谱成像法识别精度只有84.71%,高光谱成像法和基于轻量卷积网络的方法不能检测此类缺陷。对于腐烂缺陷,笔者方法识别精度达到98.86%,高于其它检测方法。

表3 马铃薯表面缺陷检测方法对比
在平均识别精度方面,笔者方法相比原YOLO V4算法提高了7.03个百分点,相比其它三种检测方法均提高了3个百分点以上,单幅图像的识别时间只需要29 ms。笔者方法的平均识别精度达到99.46%,其中,发芽、虫眼和合格品的检测精度达到100%。试验结果表明,基于机器视觉和YOLO算法的马铃薯表面缺陷检测方法可以满足马铃薯表面缺陷快速准确检测的需求。
5 结束语
针对马铃薯表面存在发芽、机械损伤、腐烂、虫眼、病斑五类缺陷的检测问题,笔者提出一种基于机器视觉和YOLO算法的马铃薯表面缺陷检测方法。构建马铃薯数据集,对马铃薯数据集进行图像增广,解决原始数据集中图像数量少且缺陷特征不均衡的问题。对原YOLO算法中的聚类方法进行改进,采用二分K均值聚类算法进行目标框分析。通过最大类间方差法将950张马铃薯图像从背景中分离出来,用于预训练,在预训练权重的基础上对整个数据集进行训练,得到最终权重。试验结果表明,笔者提出的检测方法明显优于其它四种检测方法,平均识别精度达到99.46%,对五类缺陷检测的精度均高于98%,单幅图像识别时间约29 ms,可以有效实现对马铃薯表面缺陷的快速准确检测。
