基于多模态信息联合判断的驾驶员危险行为监测系统
2021-08-20李春贺
李春贺,陶 帅
(中国矿业大学(北京)管理学院,北京 100083)
随着中国经济的飞速发展,机动车保有量呈现出爆发式增长的态势[1]。目前机动车已经成为交通出行中一项必不可少的工具,机动车的广泛使用,极大地提升了公众出行的效率,但是随之而来交通安全问题也日益增多。报告显示[2],自从2015年初至2019年底,中国共出现超过600万起各类交通事故,导致直接经济损失高达259亿元人民币;据统计,约有80%的交通事故与驾驶员危险驾驶行为直接相关[3]。例如驾驶员在驾驶过程中出现接打手机等行为,会严重地干扰驾驶员的注意力,从而无法专注地观察前方和周围的路面状况,一旦出现突发情况,驾驶员往往无法及时做出正确的反应,从而导致交通事故的产生,引起生命财产损失。因此,对驾驶员的驾驶行为进行实时监测,及时发现可能出现的危险行为并做出相应的预警和提示,可以避免部分事故的产生[4]。所以,对驾驶员危险行为监测系统的研究具有重要的价值和意义。
目前已有部分工作分别从生理信号、视觉等不同角度来解决这一问题;如文献[4]提出了一种基于双目视觉的方法来检测驾驶员是否出现分神等危险状态,这种方法虽然检测速度较快,但是准确率较低,并且容易受到光照变化的影响;文献[5]提出基于面部和手部特征联合分析的驾驶员疲劳状态检测算法,该算法通过支持向量机(support vector machine,SVM)构建分类模型,具有较高的识别精度,但是模型的泛化性较差,无法大规模使用;文献[6]借助深度神经网络强大的特征提取能力,设计了一个基于人脸特征的驾驶员疲劳检测模型,测试结果显示该方法精度高、泛化性强,但是计算量较大,对运行设备的算力有较高的要求。文献[7]设计了一种级联型深度神经网络模型,采用超分辨率测试序列(visual geometry group,VGG)模型来对驾驶员常见的9种分神动作进行检测,但是该方法忽略了驾驶员在驾驶过程中的情绪、视线、危险动作等信息,因此无法覆盖所有可能出现的情况。文献[8]借助现有的Dlib和OpenCV模型设计了一种驾驶员危险行为检测算法,这种算法设计简单,但是鲁棒性较差,并且Dlib中的模型无法训练,因此难以在实际中使用。针对现有工作所存在的问题,现从危险动作检测、情绪识别、视线估计等多个方面进行深入的研究和分析,设计一套可以联合使用多模态信息的驾驶员危险行为监测系统。
1 监测系统
1.1 问题探究
从原理上进行分析,现有的驾驶员危险行为监测系统主要可以分为3种[4]:基于驾驶员生理参数的监控方法、基于驾驶员驾驶状态的监控方法和基于计算机视觉的监控方法。其中基于驾驶员生理参数的监控方法的判断精度较高,但是该方法需要驾驶员佩戴多种传感器,并且会对驾驶员的操作产生一定的阻碍,因此该方法大多应用于学术研究方面,在实际的使用场景中很难大规模推广使用;基于驾驶行为的监控方法通过使用多种传感器收集驾驶员的行为方法,并通过算法进行分析,目前这种方法应用较多,但是这种方法灵敏度和精度较差,只有驾驶员出现明显危险驾驶行为时才进行预警[9];基于计算机视觉的监控方法通过摄像头采集驾驶员的驾驶状态,使用相应的算法直接从视觉的角度对驾驶状态进行评估和判断,该方法具有硬件设备简单、处理速度快、识别精度高、易于升级等优点,正在被广泛地关注和研究,但仍然存在多项急需解决的问题。
(1)训练数据缺失。基于计算机视觉的驾驶员危险驾驶监控系统的核心是其中的识别模型,该模型需要具有较强的泛化性和稳定性。但是在驾驶员监控任务中,所需要处理的场景多种多样,训练数据无法完全覆盖到所有的情况,导致模型在某些极端的情况下出现较多的漏检和误检。
(2)传感器模式单一。现有的方法大多采用可见光摄像头作为图像采集传感器,但是可见光传感器非常容易受到环境光照强度的影响,在光照较差的情况下,有可能导致监控系统无法正常工作,造成一定的安全隐患。
(3)判别依据较少。现有的监控系统大多是通过分析驾驶员眨眼频率来判断是否出现疲劳驾驶行为;在实际场景中,危险驾驶行为不仅仅只有疲劳驾驶一种,还包括使用手机、分神、极端情绪等多种。
(4)模型的运行效率。基于视觉特征的方法需要对图像数据进行处理,因此算法的时间复杂度和空间复杂度较高,对部署设备的硬件要求较高,导致实际使用成本增多。
为了解决上述的问题,提出了一种基于多模态信息联合判断的驾驶员危险驾驶行为监测系统。在系统中,设计了一种轻量化的深度学习模型,该模型使用多任务输出的方式进行构建,使用一个模型同时完成“疲劳检测”“视线估计”“情绪识别”等多个任务,不但压缩了模型的体积,并且提高了运行速度。此外,为了解决目前公开数据集训练样本场景单一和分布不均衡等问题,在项目中采集和标注了大量的数据,用于模型的训练。
1.2 危险驾驶行为分类
为了能够更加精确地对驾驶员的驾驶行为进行监控,对危险驾驶行为从“人脸属性”和“动作属性”两个方面进行了更加细致的分类。其中人脸属性主要包括分神、疲劳和极端情绪;动作属性主要包括未系安全带、使用手机、喝水和吸烟;具体如表1所示。
从表1中可以看出,人脸属性中的3种具体行为无法直接进行判断,因此需要使用间接的方式来进行处理;如对于分神这个危险行为,算法可以通过视线估计的方法来判断驾驶员是否正处于分神的状态。与人脸属性中的危险行为不同,动作属性中的4种危险行为可以使用目标检测算法来直接进行检测和判断。
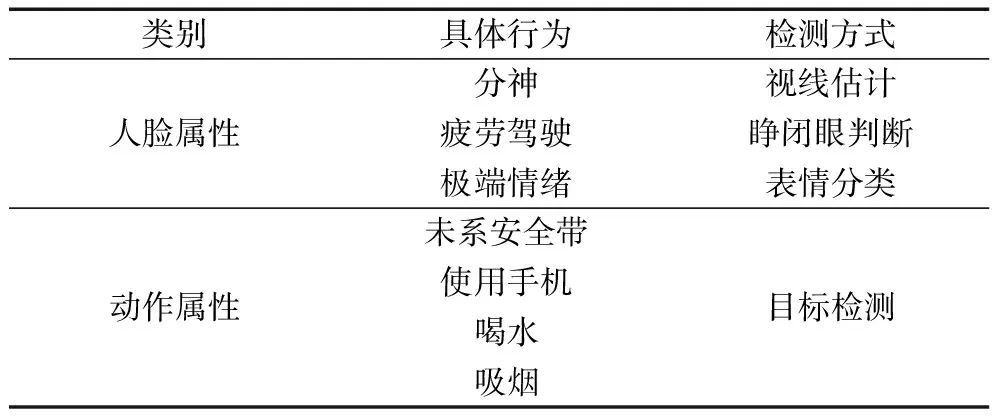
表1 驾驶员危险动作定义
2 研究方法
为了解决现有的驾驶员危险行为监控系统中所存在的传感器模式单一、判别依据较少以及模型实时性较差等问题,设计了一种基于多模态信息联合判断的驾驶员危险行为监测系统,该系统中的核心识别算法完全基于深度神经网络技术实现,具有较好的泛化性和较高的识别精度[10]。
2.1 基于人脸属性的危险动作识别
基于人脸属性的驾驶员危险动作识别算法相对复杂,因为其中的分神、疲劳驾驶以及极端情绪都无法通过人脸图片直接获取,需要任务的特点来间接判断。
2.1.1 人脸关键点定位算法
人脸关键点定位算法是基于人脸属性危险动作检测的核心,其中分神和疲劳驾驶两个任务都需要在人脸关键点定位的结果之上进行分析和处理。人脸关键点定位是指从一张人脸图片中定位出一系列具有特殊语意信息的点,如鼻尖、嘴角、眉梢等[11]。常用的人脸关键点定位技术主要分为两类,一种是基于坐标回归的方法,另外一种是基于热图回归的方法。基于坐标回归的人脸关键点定位方法速度快但精度略差;基于热图回归的方法精度高但是速度慢,并且模型的参数量和计算量远大于基于坐标回归的方法,不适合应用于实际的产品中。因此,在所提出的系统中,选择基于坐标回归的人脸关键点定位方法。
为了提升基于坐标回归方法的精度,提出了一种全新的损失函数(loss function),这种损失函数与常用的l1loss、l2loss不同,该损失函数在模型训练的过程中,使深度神经网络增加对误差较小点的关注,减少对误差较大点的关注,使模型可以更加快速地收敛,具体公式为
(1)
式(1)中:x为输入数据;ω为损失函数中的非线性区域部分;为非线性区域的曲率半径;C为一个常数项,计算公式为
(2)
为了寻找最优的参数组合,进行了大量的对比分析实验,发现当ω=10,=2时,可以获得最优的实验结果,因此在实际训练中选择上述的参数组合。
人脸关键点定位的结果如图1所示。从图1可以看出,本系统所使用的人脸关键点定位算法可以精确地从人脸图片中检测出68个关键点的位置坐标。
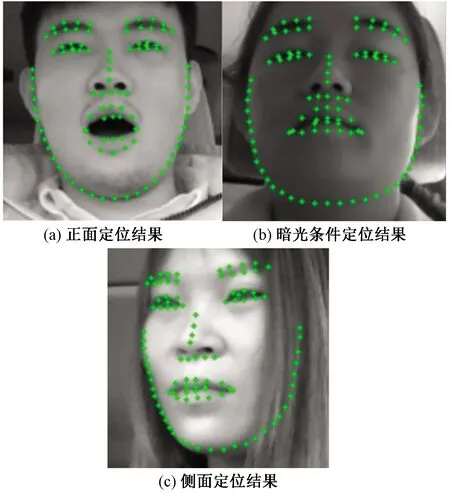
图1 人脸关键点模型定位结果
2.1.2 驾驶员分神检测
驾驶员在驾驶过程中出现分神行为具有频发性和短暂性,非常容易引起严重的交通事故。目前尚无法直接从单张图中来直接判断驾驶员是否处于分神状态的技术,因此为了完成这一任务,需要从其他角度进行间接的处理。常用的处理方式为基于头部姿态估计的方法和基于视线估计的方法。
基于头部姿态估计的方法是指通过判定头部朝向的欧拉角(pitch、yaw、roll)来间接地估计驾驶员时候处于分神状态;这种方法通过特定的人脸关键点之间的几何分布求解出姿态参数,因此算法的精度严重依赖于人脸关键点的定位结果,一旦人脸关键点定位出现偏差,将会对头部姿态估计的结果产生严重的干扰,从而影响驾驶员分神检测的准确性。
基于视线估计的方法可以有效地解决上述的问题,该方法直接使用眼部区域的图片作为输入,拟合出视线的欧拉角。眼部区域只需要使用人脸关键点的定位结果进行粗略的裁剪,从而极大地降低了驾驶员分神检测对人脸关键点结果的依赖程度,提升了算法的稳定性和泛化性。眼部区域如图2所示。

图2 裁剪后眼部区域图片
将经过裁剪和对齐的眼部区域图片送入卷积神经网络模型中,使用深度学习的方法可以通过回归的方法直接计算出视线的朝向,从而判断出驾驶员是否处于分神状态。
2.1.3 驾驶员疲劳状态识别
驾驶员疲劳驾驶是引发各类交通事故的主要原因,因此对驾驶员的驾驶状态进行实时监控,并在出现疲劳驾驶的时候及时给出报告和预警,对减少交通事故具有重要的意义。
疲劳驾驶行为无法直接进行度量,通常情况下采用眨眼频率和Perclose算法来进行间接判断。因此,该模块的核心问题转变成了如何精确地判断驾驶员睁闭眼的状态;传统的方法大多采用眼部关键点之间的相对距离来判断睁闭眼的状态,但是这种方法的精度会严重的依赖于关键点的定位精度,因此准确性较差。为了解决这一问题,设计了一种基于卷积神经网络的睁闭眼判断模型,为了提高算法的运行效率,模型中使用深度可分离卷积代替原有的标准2D卷积操作。通过模块输出驾驶员在单位中闭眼的次数,然后计算Perclose[4],即
(3)
式(3)中:n为单位时间内检测到闭眼的总次数;N为总共检测的帧数。
2.1.4 驾驶员情绪识别
驾驶机动车时需要驾驶员以平和的心态来应对各种可能出现的突发事件。当驾驶员处于焦虑、烦躁、沮丧等极端负面情绪的时候,容易产生冲动的行为,因此这种情况并不适宜驾驶机动车。
现有的驾驶员监控系统并没有考虑驾驶员在驾驶过程中的情绪变化,因此存在一定的安全隐患。为了解决这一问题,使用深度学习的方法设计了一种情绪识别算法,该算法使用人脸图像作为输入,借助神经网络模型对人脸中的表情特征进行建模,从而精确地识别出驾驶员的情绪[12]。
2.1.5 人脸属性整体解决方案
基于人脸属性的危险动作检测方案中,需要完成关键点定位、视线追踪、疲劳驾驶判断以及情绪识别等多个任务。如果为每一种任务单独设计一个模型,将会极大地增加系统的运算量,导致处理速度下降。因此,借鉴深度学习中多任务学习模式,设计了一种轻量化的深度学习模型,该模型可以使用一个特征提取网络完成多个任务。根据人脸属性中的4个不同的任务,将人脸关键点定位任务和情绪识别两个任务相结合使用一个深度学习网络直接输出识别结果。视线追踪与疲劳驾驶判断需要根据眼部区域的图片进行判断,因此这两个任务需要在人脸关键点的结果的基础之上进一步的进行处理。基于人脸属性的危险动作检测方案的总体流程如图3所示。
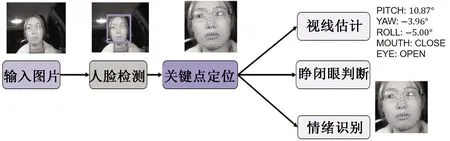
图3 基于人脸属性的系统框架
驾驶员危险行为监测系统需要在嵌入式硬件设备上运行,并对驾驶员的驾驶过程进行不间断的监控。大部分嵌入式设备的由于CPU架构等原因,算力和存储空间相对较小,因此在系统中使用深度可分离卷积来代替标准的2D卷积,并对模型的Block结构进行重新设计,将原本用于降采样操作的Max Pooling结构使Stride=2的3×3的卷积层代替,加速模型前向传播速度。为了解决ReLU在模型训练时导致的神经元退化现象,使用Leaky ReLU作为轻量化模型的激活函数。网络的具体结构如表2所示。
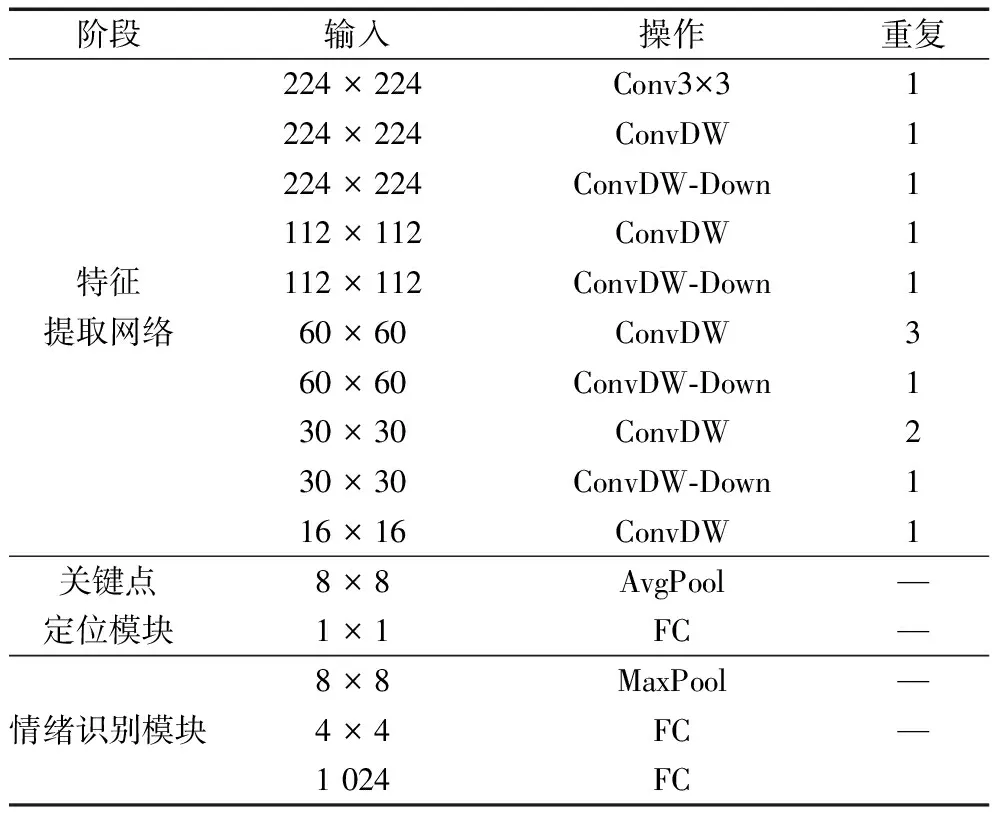
表2 轻量化模型具体结构
关键点定位模块和情绪识别模块是两个平行的结构,特征提取网络直接相连。
2.2 基于动作属性的危险动作识别
与基于人脸属性的危险动作识别不同,基于动作属性的危险动作检测可以使用一种统一目标检测框架来处理。常用的目标检测算法主要分为单阶段目标检测算法和双阶段目标检测算法,双阶段目标检测算法如Faster-RCNN、RetinaDet等,这种方法检测精度高,但是实时性较差、体积相对较大,很难直接在实际项目中使用。单阶段目标检测算法直接使用模型输出检测框的相对位置和分类信息,在保证检测精度相对较好的情况下,极大地提升了处理速度。根据项目的实际需求,在本系统中选择单阶段目标检测算法YOLOv3作为基础框架进行改进和优化[13]。
YOLOv3[14]是一种常用的端到端的单阶段目标检测模型,算法使用DarkNet-19作为特征提取网络,借助特征金字塔来融合高层的语意信息和低层的细节信息,实现快速目标检测。但是原始的YOLOv3仍然存在一些缺点,如:对小目标的检测精度较差,DarkNet-19特征提取网络的体积较大,不适于在移动端进行部署[15]。
为了解决上述问题,将Non-Local注意力机制引入到目标检测框架中,该模块可以对全局信息和局部信息进行差异化信息融合,提高了模型的特征提取能力,优化了模型对小目标的检测精度。此外,将原有的DarkNet-19换成ShuffleNetV2,既降低了模型的参数量和计算量,同时维持了模型的特征提取能力。
2.3 系统总体框架
所提出的基于多模态信息联合判断的驾驶员危险行为监测系统包括基于人脸属相的驾驶员危险动作识别算法和基于动作属性的驾驶员危险动作识别算法。系统的总体框架图如图4所示。
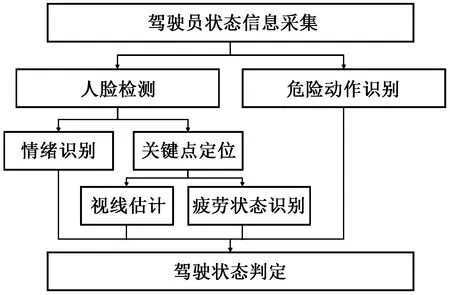
图4 系统总体架构
3 实验分析
在本系统中需要设计和训练多个深度学习模型,故对训练过程和对比实验进行具体的分析。
3.1 数据库构建
为了解决适用于驾驶员危险行为检测的数据量小、场景覆盖不足等多种问题,在本项目中,构建了一个包含10万张图片的驾驶员危险行为数据集。数据集采集环境为真是车内环境,包含多种车型如轿车、卡车、商务车以及运动型多用途汽车(sport utility vehicle,SUV)等。采集人群包含多个年龄段,覆盖多个时间以及多种行为。采集设备为可见光和双目红外摄像头,分辨率为640×480。为了解决单一摄像头在拍摄过程中存在视觉盲区这一问题,数据会同时从左侧A柱上方、中控台上方以及后视镜3个位置同时进行采集。数据标志内容包括68个人脸关键定位置坐标、情绪、视线朝向、安全带位置、以及多种不安全行为类别。
3.2 实现细节
模型的训练时使用Adam进行优化,初始学习率为0.001,批次处理(batch size)是256,一共训练100个epoch,每隔30个epoch学习率减小为原来的1/10。模型使用4张Nvidia GTX 1080Ti显卡进行训练,BatchNorm层使用Syncchronized BN技术进行优化。算法使用平均精度均值(mean average precision,mAP)、精确率、召回率以及错误率作为评价指标。
3.3 实验结果分析
由于目前没有任何一种驾驶员危险动作监控系统可以对所提出的各项指标同时进行检测;因此,将分别设计对比实验与现有的方法进行对比。
3.3.1 人脸关键点定位实验对比
人脸关键点定位是系统的核心,该部分的定位结果的精度将会对后续的分神检测、疲劳状态判断产生较大的影响。将所提出的关键点定位算法与常用的MTCNN[16]、RAR[17]和TCDNN[18]3种方法进行比较,使用归一化均方误差(normalized mean square error,NMSE)作为评价指标,具体结果如表3所示。
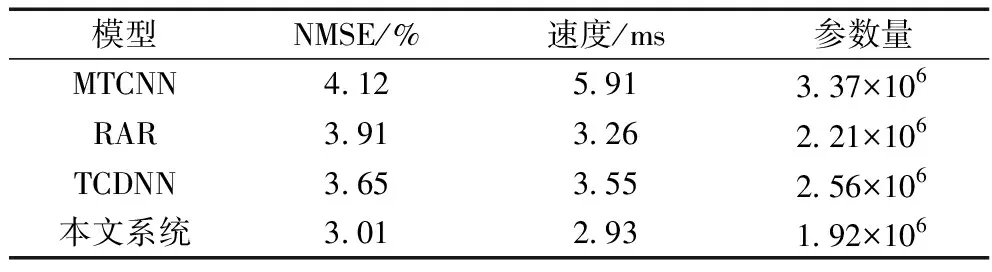
表3 人脸关键点检测精度结果对比
从表3可以看出,所提出的关键点定位算法精度最高,并且运行速度快,模型体积小,适用于实际项目中。
3.3.2 情绪识别实验对比
表4是情绪识别模型与常用的情绪识别算法性能的对比结果,其中使用准确率进行评价,所对比的方法有VGG-Face和AlexNet。所需识别的表情包括平和、高兴、悲伤、愤怒和焦虑。
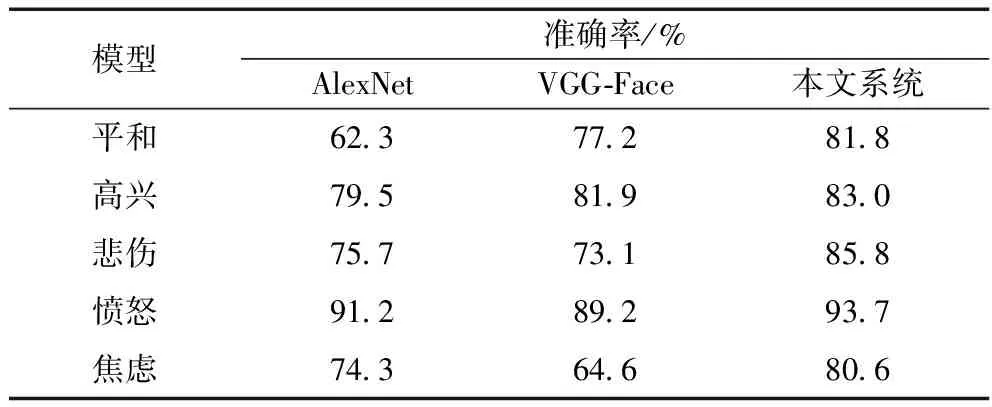
表4 情绪识别实验对比结果
从实验结果可以看出,所设计的情绪识别算法在5种情绪识别准确率上都要优于现有的算法,并且情绪识别模型与人脸关键点定位模型公用一个特征提取网络,有助于降低系统的整体运算量,提升运行效率。
3.3.3 睁闭眼状态判断与视线估计实验
驾驶员在行驶过程中是否出现疲劳和分神两种危险驾驶行为,很难直接使用算法进行识别,因此需要使用其他的指标辅助判断。在本文系统中使用睁闭眼的频率来表征驾驶员是否出现疲劳驾驶;使用视线朝向来判断是否出现分神行为。睁闭眼判断和视线估计使用一个多任务模型同时进行输出。表5是睁闭眼实验对比结果,其中使用精确率和召回率作为判断指标。表6是视线估计算法的实验对比结果,使用相对误差作为度量指标。
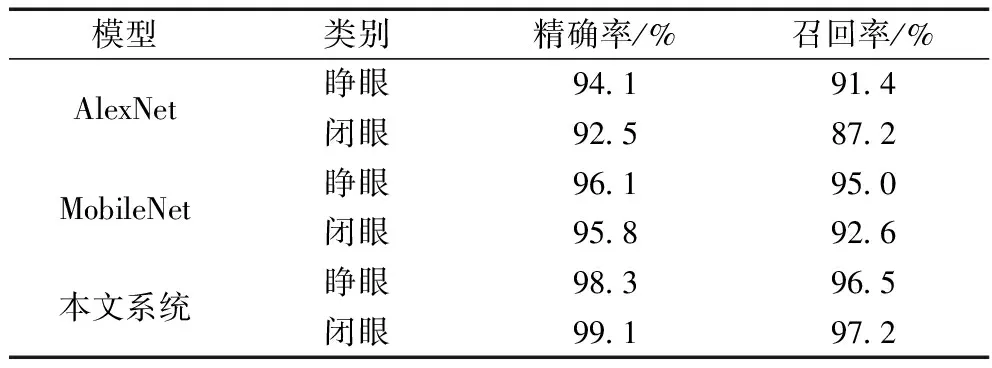
表5 睁闭眼判断实验对比结果
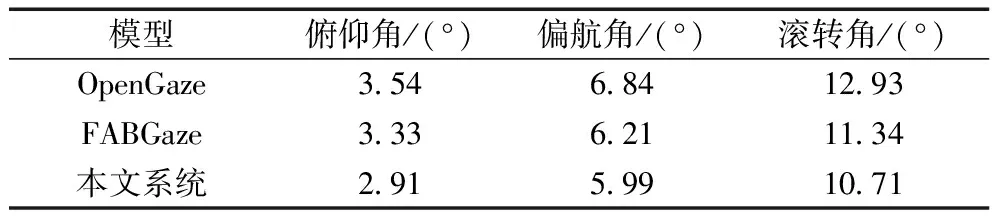
表6 视线估计实验对比结果
从对比结果中可以看出,所使用的睁闭眼识别算法和视线估计算法的精度明显优于现有的常用的方法。
3.3.4 动作检测实验对比
为了证明系统中所使用所提出的目标动作检测算法的可靠性和稳定性,与常用的目标检测算法(SSD、YOLOv3等)进行了对比。因为实验中所需监测的类别较多,所以选择平均精度均值mAP作为评价指标。具体实验结果如表7所示。
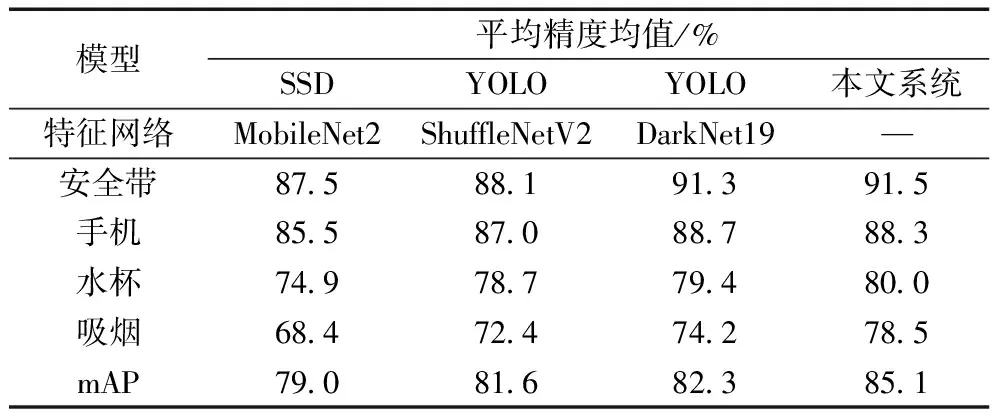
表7 动作检测结果
从实验结果中可以看出,所提出的基于Attention的目标检测算法在性能上明显优于常用的目标检测模型的结果,并且在小目标的检测精度上更好。
3.4 实验结果可视化
为了更加直观地分析系统的性能,图5展示了部分测试结果。
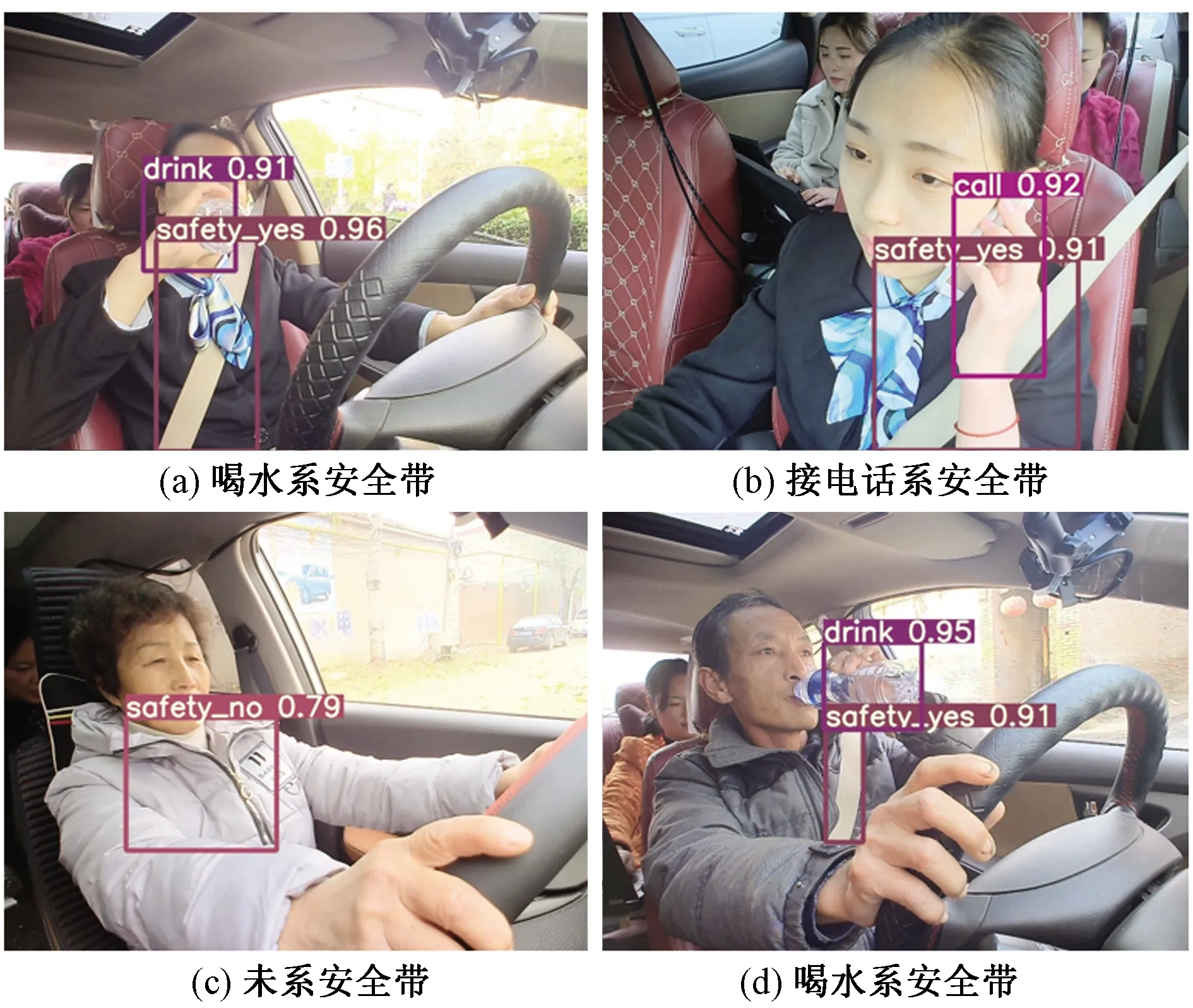
图5 可视化结果
从可视化结果中可以看出,系统能够准确地识别出监控画面中是否出现了危险驾驶行为。
4 系统集成
为了将所提出的驾驶员危险行为监测系统应用到实际中,将上述的多个模块进行集成,开发了一套可以用于实际情况的系统,系统界面如图6所示。
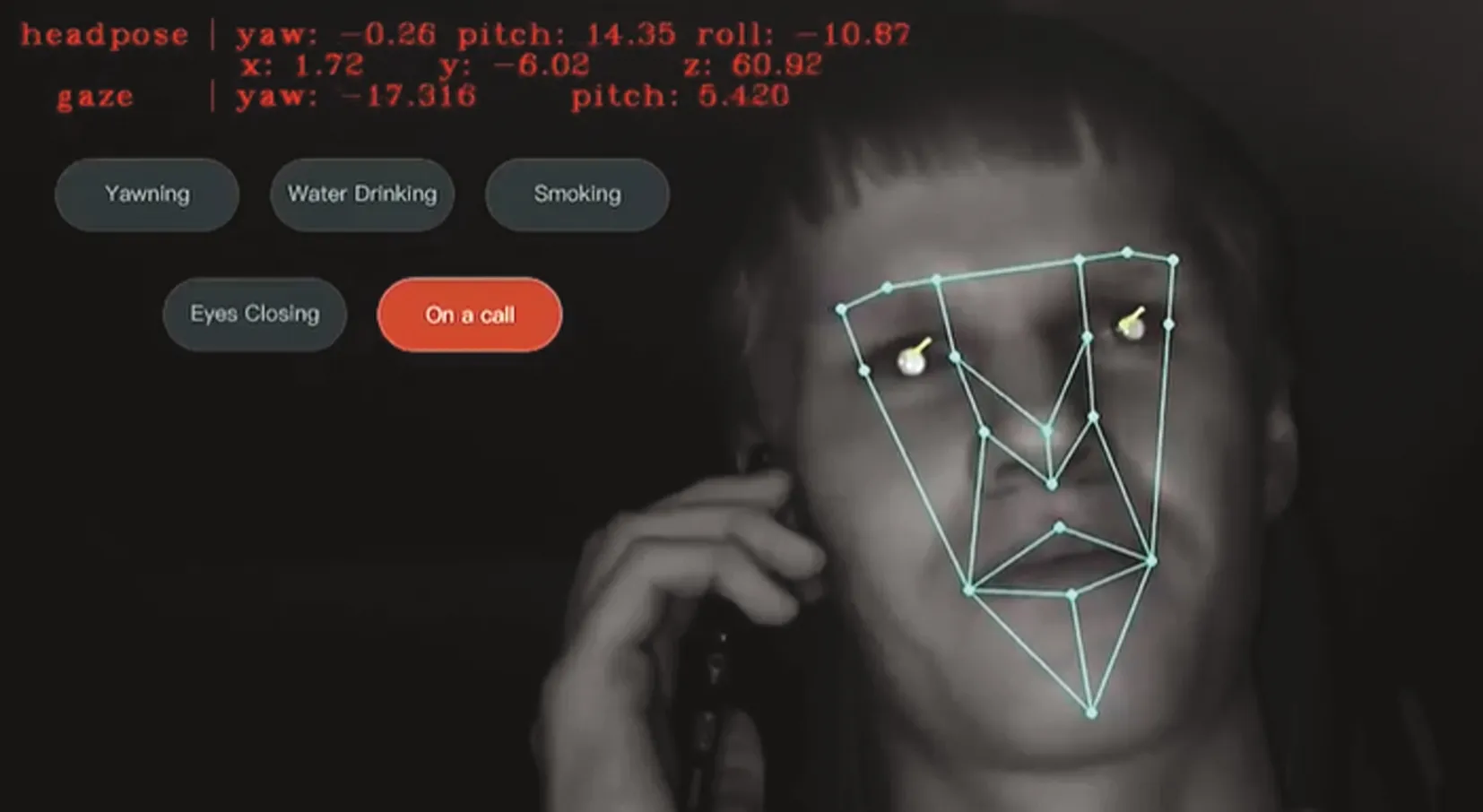
图6 产品运行画面
所提设计的系统目前已经在国内某大型汽车制造商的多款产品中进行实验性调试,在嵌入式设备中的实际测试速度为81 fps,可以满足对驾驶员的实时这一需求。在实际行驶场景下,经过多次测试和分析,所设计的系统对驾驶员危险动作检测准确率为96.2%,误检率为1.6%,漏检率为2.2%,符合实际项目需求。
5 结论
提出了一种基于多模态信息融合的驾驶员危险行为监测系统,该系统使用了深度学习、人工智能等先进技术,对驾驶员的驾驶行为进行实时监测。所提出的系统通过头部姿态、视线估计、情绪识别以及动作检测等从多个角度全面分析,弥补了现有驾驶员监测系统存在的缺陷。此外,将所提出的系统进行了产品化,目前已经完成了实际测试,系统的识别精度、运行效率均已达到要求,即将商业化量产。
