网络Meta分析研究进展系列(十五):证据网络断续的网络Meta分析
2021-08-19张天嵩董圣杰杨智荣武珊珊田金徽孙凤
张天嵩,董圣杰,杨智荣,武珊珊,田金徽,孙凤
1 证据网络断续示例
Goring等[5]列举了证据网络断续的情况(如图1所示),A:少数试验进行比较;B:许多试验进行比较;C:模式转移;D:因研究问题导致的网络断续,虚线和白色结点表示可通过附加药物来形成连接。

图1 证据网络断续结构示意图
2 层次模型
2.1 基本模型Goring等[5]根据效应量为干预反应和干预效应(如干预措施Avs. B的相对效应)的不同,在Dias等[9,10]提出的层次模型(实质上为广义线性模型)基础上,拓展提出了干预效应尺度网络Meta分析模型、干预反应和干预效应联合网络Meta分析模型、干预反应网络Meta分析模型等三种证据网络断续的NMA建模策略,分别讨论了每个模型的优缺点,并通过模拟数据对三种模型进行验证和比较[5]。
假设某NMA共有M个研究、含K个干预措施,测量结局为二分类数据,假定第1个干预措施为参照干预,第i(i=1,2,...,M)个研究中第k(k=1,2,...,K)个干预措施相对于参照干预的研究特定效应为δi,1k(如二分类数据为比值比的对数尺度),是来自于均数为d1k、方差为σ2正态分布刻画的随机效应,根据一致性原理则有δi,jk=δi,1kδi,1j(j,k>1);假定第i个研究中参照干预措施臂的事件(如治疗成功)比值的对数为αi,则第i个研究中第j个干预措施(非参照)臂事件(如治疗成功)比值的对数为αi+δi,jk,基于干预效应尺度的NMA(network meta-analysis of treatment effect,NMA-TE)模型为:
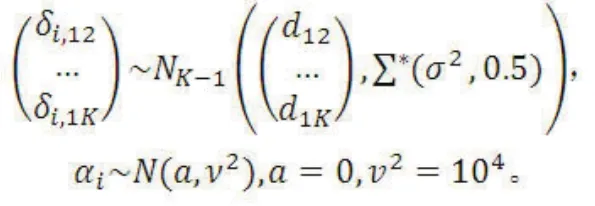
基于干预基线反应和干预效应联合建立的NMA(network meta-analysis of baseline response and treatment effect,NMA-BRTE)模型为:

NMA-TE模型和NMA-BRTE模型比较:NMA-TE模型虽然将干预反应参数纳入但只将其作为讨厌参数,而NMA-BRTE模型将其作为基本参数;NMA-BRTE模型允许数据对v2值产生影响,意味着单臂研究可以提供信息,可以用于对断续证据进行推断;两种模型虽然基于跨研究间相对干预效应服从正态分布的假设,但NMABRTE模型也要求基线风险(logit尺度)服从正态分布,因此在利用数据方面更能获益。
在NMA-BRTE模型的基础上,可以再发展为基于干预反应的NMA(network meta-analysis of treatment response,NMA-TR)模型,假定NMA中共含有K+1个干预措施,分别为对照(将其作为第0个干预)和除对照外其他K个干预措施,则有:
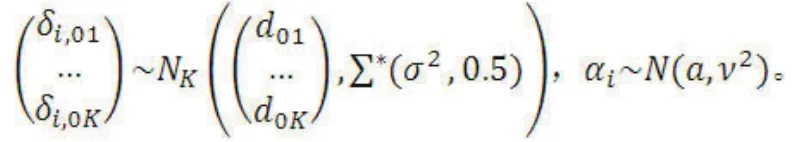
假定第i(i=1,2,...,M)个研究中第k(k=1,2,...,K)个干预措施的事件发生概率为ρi,k,令γi,k=logit(ρi,k),则NMA-TR模型为:
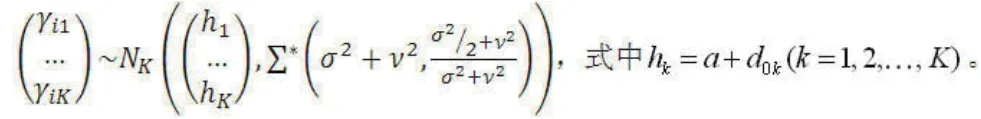
2.2 模型拟合上述模型在贝叶斯分析框架下可由WinBUGS/OpenBUGS、JAGS、R等软件来拟合。Goring等[5]在文献附加材料中给出了模型的WinBUGS程序代码及相应数据输入格式,可供参考。
人在都市,却不属于都市,这是造成农民工身份认同危机的根源。中国当代都市电影通过形象化的叙事,揭示了农民工“人在都市,却又不属于都市”的尴尬处境,以及他们在都市景观与乡土情结之间的两难选择,而这种“两难”,正是农民工身份认同危机的外在体现。
3 组分网络Meta分析模型
3.1 基本模型Rücker[4,11]等提出了组分网络Meta分析(component network meta-analysis,CNMA)模型,可以作为断续网络的一般模型,适用于由一个或多个组分构成的复合干预措施,或者在分离的网络中存在至少一个共同组分的干预措施间的分析比较,可分为CNMA加性模型(Additive CNMA model)和CNMA交互模型(interaction CNMA models)两种:
假定NMA数据中有n个干预措施,m个干预措施配对比较,干预措施中含有多组分者为c,则有c≤n。每个配对j=1,2,...,m比较可以通过观察到的(相对)干预效应dj及其标准误SE(dj)来表达,如为多臂研究,可按文献方法[12]对标准误进行校正。加性模型的设计矩阵为m×n矩阵X=BC;矩阵X将网络结构信息(有m行,表示干预措施配对比较;有n列,表示干预措施)和组分信息(n×c矩阵C)联合起来,其元素为0、1、-1表示每行中配对比较中的组分(列),则共同效应加性模型为d=Xβ+ε。式中向量d∈im,为研究中观察到的相对效应(差);为X设计矩阵;参数向量β∈ic,长度为c,可由加权最小二乘回归方法估计;多元正态分布误差ε∈im。加性模型可以扩展为交互模型[13],如双因素交互模型,可以通过针对每一感兴趣的交互因素在矩阵C中增加一列来实现。模型选择可以采用前进法或后退法。
3.2 应用实例Rücker等[4]采用CNMA模型重新分析了Schmitz等[8]分析过的多发性骨髓瘤数据,以前进法或后退法来选择合适的模型,比较了加性模型、交互模型以及Schmitz匹配法等不同模型的计算结果。研究认为,虽然CNMA模型基于随机对照试验,但在实践中,如果要引入观察性研究的证据,则CNMA模型也可作为匹配法的替代分析策略。
3.3 模型拟合该模型可以由基于频率学分析框架下R语言netmeta(当前最新版本为1.4-0版)扩展包的discomb( )函数轻松实现[14]。
4 基于模型的剂量-效应网络Meta分析模型
4.1 基本模型Pedder等认为,基于模型的网络Meta分析(model-based network meta-analysis,MBNMA)可以扩展经典的NMA模型来处理剂量-反应关系,是一种有潜力的连接证据网络的新方法[6]。
假定第i个研究中第k个臂某药物αik的剂量为xik,则剂量-反应MBNMA模型为:
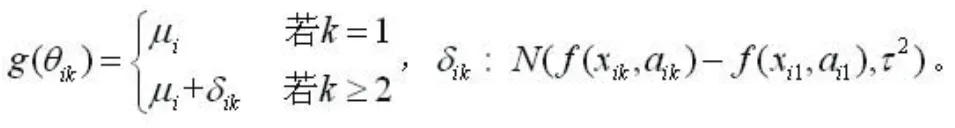
式中,g( )表示链接函数,可根据不同的数据类型来选择;θik表示效应量参数(如概率、均数等);μ i表示第i个研究中对照臂的效应,为讨厌参数;δik为研究中特定相对干预效应;f(xik, αik)表示药物αik剂量xik的剂量-反应函数;τ2表示研究间异质性。该模型有指数模型和Emax模型两个常用模型:
指数模型为:f(xik, αik)=E0i+βaik(1-e-xik)。式中E0i表示第i个研究中剂量xik=0时对照的治疗反应;βaik表示第个研究中臂k的率参数(rate parameter)。
4.2 应用实例Pedder等[6]以MBNMA策略重新分析了曲坦类药物缓解偏头痛有效性的研究数据[15],从中不但可得到连续网络中不同干预措施之间的相对干预效应,也能从断续网络中获得连续网络中不能得到的不同干预措施之间相对干预效应。认为,如在NMA时,存在不同剂量数据,采用MBNMA策略可连接证据断续网络,能提高研究精度;与其他模型相比也不需要更多的强假设。4.3 模型拟合该模型可由基于贝叶斯分析框架下R语言MBNMAdose扩展包(当前最新版本为0.3.0版)来拟合[16,17]。
5 其它分析策略
5.1 分析策略此外,还有不少研究者针对证据网络断续的NMA方法进行了探索,如使用外对照(external controls)[7,18,19]、干预效应参数(treatment effect parameter)[5,7]、随机基线模型(random baseline models)[20,21]、校正干预反应(adjusted treatment response)[22-24]、多元Meta分析(multivariate meta-analysis)[7,25]、类效应模型(class effect models)[7,26]等。其中,倾向评分匹配(propensity score matching,PSM)法和匹配校正间接比较(matching-adjusted indirect comparisons,MAIC)等匹配法(matching method)是利用个体参数者数据(individual participant data,IPD)建模对观察到的协变量进行校正来获得不同干预措施间的比较结果[7,8,22,23]。
5.2 应用实例Thom等[21]基于随机基线效应模型,采用贝叶斯分析框架,将单臂研究、自身前后对照、观察性研究等不同设计类型的IPD或聚合数据纳入NMA,比较分析探讨不同干预措施对肺动脉高压的治疗作用,认为其提出的模型虽然有缺陷,但仍建议可作为证据网络断续的分析策略。
Signorovitch等[24]采用MAIC分析策略在没有头对头研究数据情况下,通过对IPD研究中的个体参者与基线进行校正后与聚合数据进行匹配,比较了阿达木单抗和依那西普治疗银屑病的疗效,发现对于中、重度银屑病阿达木单抗与依那西普相比,可明显减轻症状。
Schmitz等[8]针对多种干预措施治疗多发性骨髓瘤的数据(两个分离的NMA数据),采用匹配的方法试图将观察性研究连接到断续的证据网络中,基于协变量信息计算研究间距离大小来评价研究间相似性对研究进行匹配,若是无需比较的观察研究则可采用单臂研究,可找到5个对子可以将分离的NMA结构连接起来,并发现达雷木单抗+地塞米松+来那度胺或硼替佐米对无进展生存率(progression free survival,DFS)的提高具有较大优势。
6 结语
针对证据网络断续的NMA,目前已有不少建模方法,虽模型创建者也声称对模型进行验证[8],但在实际应用时还应谨慎:一要注意假设问题,所有模型应遵循NMA经典的假设如同质性、一致性和相似性,特别是跨研究间干预效应调节因素的可传递性等;同时,不同模型还应基于自身模型的独有假设,如CNMA加性模型假定多组分干预措施中组分效应是可加的。二是待分析的数据要适用于待拟合的模型。IPD数据允许对干预效应调节因子和预后因子不平衡进行校正分析,但实际情况下常缺乏IPD;基于聚合数据的分析易导致聚合偏倚(即生态学谬误),在解释结果要高度小心。三是对证据网络断续的干预措施间相对效应进行估计,多数研究会将观察性研究数据纳入分析,则更需考虑处理和校正研究间干预效应调节因子和预后因子不平衡的统计策略和模型假设等。我们期待,针对不同决策需求,研究者推出更多更为适用的模型和方法,提高该类证据制定的科学性和规范性。
