基于深度学习的图像语义分割方法研究综述
2021-08-19曾文献马月丁宇张淑青李伟光
曾文献,马月,丁宇,张淑青,李伟光
(1.河北经贸大学信息技术学院,石家庄050061;2.中国电子科技集团第五十四研究所,石家庄050081)
0 引言
语义分割如今成为计算机视觉研究的关键技术之一,通过对图像中的像素点进行分类,然后得到目标像素点的标签和位置信息,并将不同目标分割出来。早期的图像语义分割方法主要是利用人工提取一些浅层的特征,如基于边缘[1]、基于阈值[2]等。但是对于复杂的场景图片,无法达到分割的预期效果。随着深度学习的发展,基于深度学习的语义分割方法取得了突出表现,常用的深度学习语义分割网络有:卷积神经网络CNN(Convolutional Neural Network)、全卷积网络FCN(Fully Convolutional Network)[3]、循环神经网络RNN(Recurrent Neural Network)和对抗神经网络GAN(Gen⁃erative Adversarial Network)[4]等。后来出现的基于FCN、RNN和GAN等改进的方法,与早期方法相比不管是准确率还是速度上都有了很大的提高。本文针对基于深度学习的图像语义分割方法进行了归纳总结,对图像语义分割方法进行了分类讨论和性能对比,并对今后的发展趋势进行了总结。
1 基于全监督学习的语义分割方法
图像语义分割方法主要是基于全监督学习方法,全监督语义分割方法使用像素级标签数据进行网络训练,训练样本提供了大量的细节信息和局部特征,有助于提高网络的分割效果。
1.1 基于改进的FCN的方法
基于候选区域的方法在语义分割方面虽然取得了一定的成果,但是容易丢失图像中小目标信息,直接影响图像语义分割效果。2014年,文献[3]提出的FCN,可以输入任意尺寸的图像。FCN是将卷积神经网络最后一层的全连接层替换成1×1的卷积层,然后通过反卷积层对最后一个卷积层进行上采样,使输出恢复到输入图像相同的尺寸,最后每个像素进行预测。FCN在图像语义分割方面取得了不错的成果,但该方法存在一定的局限性,一是虽然上采样恢复了图像的尺寸但丢失部分像素的位置信息。二是FCN没有考虑全局上下文的信息,缺乏空间一致性。针对FCN的不足,研究者提出一系列基于FCN改进的方法。
1.1.1 基于空洞卷积的方法
FCN上采样虽然恢复到原来图像的大小,使得很多细节信息被丢失。空洞卷积(Atrous Convolution)则可在不减小图像大小的情况下还可以增大感受野提高图像特征图的分辨率。感受野计算如公式(1),其中rn表示第n层layer的输入的某个区域,sn表示第n层layer的步长,kn表示filter的尺寸。

DeepLab[5]深度卷积网络模型,通过利用空洞卷积代替反卷积操作来增加感受野,获得更多上下文信息。该方法还增加了条件随机场CRF(Conditional Random Field),用来提高网络语义分割的准确性。CRF模型的能量函数E(x)如公式(2),其中x是像素的标签,θi(xi)是一元势能函数,用来描述观测序列对标记变量的影响。θij(xi,yi)是二元势能函数,描述变量之间的相关性和观测序列的影响。

在DeepLab的基础上提出了DeepLab-v2[6],解决了图像中存在的多尺度问题。该方法提出了空洞空间金字塔池化ASPP(Atrous Spatial Pyramid Pooling)模块,利用4种采样率的扩张卷积核提取多尺度特征,然后利用全连接随机场优化分割效果。加入空洞卷积后,处理速度达到8FPS,CRF达到0.5s。随后,在DeepLab-v2的基础上提出了DeepLab-v3[7]网络。该网络改进了ASPP,在空洞卷积之后添加了批量归一化层,将结果经过1×1卷积,然后利用双线性插值上采样得到所需的空间维度。该网络在数据集PASCAL VOC 2012上的性能比DeepLab、DeepLab-v2有了明显的提升。
基于空洞卷积的方法总结如表1所示,通过引入空洞卷积和CRF不仅有效解决了因为连续池化和降采样而导致的分辨率降低、细节信息丢失的问题,而且可以获取不同尺度的图像信息。

表1 全监督语义分割方法
1.1.2 基于编解码的方法
编码器-解码器(Encoder-Decoder)结构可以解决FCN因上采样操作而导致的像素位置信息丢失的问题。编码器由多个卷积层组成,用来获取图像的总体特征和局部特征。解码器则是由多个反卷积或上池化组成,用来恢复特征图的空间分辨率,并进行像素分类。
2015年,Noh等人[8]提出了一个基于反卷积的De⁃convNet网络。它是基于编码器-解码器体系结构,将上池化操作与反卷积操作结合起来,可以适应多尺度的目标。Badrinarayanan等人[9]将DeconvNet网络进一步扩展成SegNet网络。SegNet网络去掉了DeconvNet的FC层,减少了参数量和存储空间,而且在下采样时不仅输出pooling结果还输出pooling过程中的索引。随后,Fourure等人[10]将SegNet扩展为基于贝叶斯的模型(Bayesian SegNet),在编码器和解码器之间添加了ratio=0.5的dropout层。进一步提升了网络学习能力。2018年,Chen等人[11]提出DeepLab-v3+模型,该模型设计了一个Encoder-Decoder结构,用于恢复目标的边缘信息,获得更丰富的上下文信息,还增加了Xcep⁃tion模块,提高了网络的运行速度和语义分割精度。
卷积神经网络通过牺牲空间信息和像素位置信息来获取高层次的图像特征,丢失的细节信息往往对后面的操作有着很大的影响。由上池化或者反卷积组成的解码器通过对卷积层输出的特征图进行上采样,就可以避免因为特征图分辨率降低带来的问题。
1.1.3 基于特征融合的方法
FCN学习到的是局部特征,感受野不够、缺乏对图像全局特征和上下文的信息的利用。该技术包括合并全局特征(从网络中的上一层提取)与从下一层提取的更局部的特征图。研究发现,因为FCN的实际感受野比理论要小的多,提取到的特征图就会缺乏全局特征信息,为了解决这个问题,ParseNet[12]模型引入全局池化层来弥补感受野不足的问题。先通过一个全局池化提取全局特征就,然后再采用早融合的方式将全局特征与局部特征进融合,因为特征图尺度不一样,融合时准确率会下降,所以特征融合之前需要进行L2正则化处理如公式(3)所示,其中输入x=(x1…xd),‖x‖2是定义的x的L2范数。

SharpMask[13]网络中引入了一种渐进式优化模块,以自顶向下的体系结构将低维特征与高维语义信息相结合,即先由卷积神经网络生成一个粗略的mask,然后逐层与低维特征融合进行一系列的Refine,来优化物体的边缘信息。Refine的过程中,Refine模块Ri合并粗略的mask(Mi)和对应层的特征Fi得到新的mask(Mi+1)如公式(4)所示。

针对下采样过程导致的信息丢失问题,研究者们提出了反卷积操作和空洞卷积来解决这一问题。除此之外,RefineNet[14]提出了一种多路径神经网络,通过递归方式获取低层特征来优化高层特征,有效地利用多级特征来生成高分辨率特征图。MSPP[15]模型提出了Global-Attention Fusion(GAF)模块,包含两个分支,一个用来将高层特征图进行全局平均池化作为注意力机制图,另一个将低层特征图通过瓶颈架构初步学习获得浅层特征,然后利用生成的注意力机制图与浅层特征图相融合得到加权特征图。最后将高层特征图与加权特征图连接起来进行上采样得到最终预测。
1.2 基于RNN的方法
根据RNN处理处理序列数据的特点,RNN可以用来解决无法充分利用上下文信息的问题。2D LSTM模块[16]是一种二维长短记忆递归神经网络模块,由四个LSTM块组成,将四个方向的上下文信息存储在序列数据中,并对图像中的长期依赖记性建模。每个LSTM包含三个门,输入门i、忘记门f和输出门o。在x和y的方向上计算输入门如公式(5),其中,W、H和C是权值矩阵,是x和y方向的输出激活,f1(·)和f2(·)是sigmoid和tanh函数。

输出门的输出ot如公式(6)。

ReSeg网络[17]在ResNet基础上进行的改进,该方法由局部特征提取层、ResNet层和反卷积层三个部分组成。图像先经过VGG16进行预训练得到局部特征,然后送入ResNet网络获得全局特征和上下文信息,这个过程减小了空间分辨率,最后再通过反卷积组成的上采样层,恢复空间分辨率,获取分割结果。
使用RNN处理图像语义分割,解决了长期依赖关关系进行建模的局限性,通过将图像像素进行连接按顺序处理,建立像素与像素之间的时间依赖模型,充分利用上下文的关系。
2 基于弱监督学习的语义分割方法
图像语义分割算法大都采用有监督学习,但是训练模型需要大量像素级标记数据,不仅成本高,还费时费力。近几年,弱监督学习的方法广泛应用到语义分割中,主要方法是基于以下两种经典网络:基于CNN的方法和基于GAN的方法。
2.1 基于CNN的方法
基于CNN的方法如今仍然占大多数。CCNN(Constrained Convolutional Neural Network)[18]是基于弱监督的约束卷积神经网络,该方法使用图像级标注作为CNN分类器输出的标签分布的约束条件,并提出损失函数MULTI-CLASS MIL LOSS来对具有任意线性约束的卷积网络进行优化。训练过程可以看作是求线性约束条件最优问题如公式(7),其中P(x)是一个隐含的类别分布,Q(x)是CNN预测类别分布。

陈辰等人[19]提出基于动态掩膜生成的弱监督语义分割方法。该方法首先利用CNN提取图像特征,然后通过迭代的方式整合多层特征,每次迭代的输入采用一层特征图,得到图像前景目标边缘,再根据目标边缘信息生成掩膜,最后通过CNN特征对掩膜进行修正。训练损失函数L如公式(9),其中l(hij,yij)表示Softmax损失函数,hij和yij分别表示预测结果h伪标签y在(x,y)处的数据。

由于弱监督语义分割减弱了对密集注释的依赖,其性能远不如全监督语义分割方法,受多尺度特征在图像处理应用中的启发,SAFN[20]是通过注意力机制为不同尺度和不同位置的特征分配权重,然后将所有尺度的特征图加权求和得到目标定位。因为注意力机制损失函数可以进行反向传播,所以可将注意力机制与分类进行联合训练。
2.2 基于GAN的方法
生成对抗网络(GAN)通过巧妙地利用博弈的思想来学习生成式模型,由两个网络组成,一个是生成器网络,用于生成样本;另一个是判别器网络,区分从训练数据抽取的样本和从生成器抽取的样本。如今,GAN在弱监督学习领域有广泛的应用。Souly等人[21]对GAN网络进行了改进,将GAN网络应用于弱监督学习的图像语义分割。该方法通过生成对抗网络创建大量非真实图像,使判别器学习到更准确的特征。还通过添加噪声和使用图像级标签作为附加信息的样本用于生成图像,为确保GAN生成更高质量的图像。通过向网络中添加图像级类别标签,损失函数如公式(10)所示,其中Pl(l)类标签的先验分布,D(x,l)是数据x和标签l的联合分布,G(z,l)是噪声z和标签l的联合分布,Pz(z|l)是z和l的条件分布。
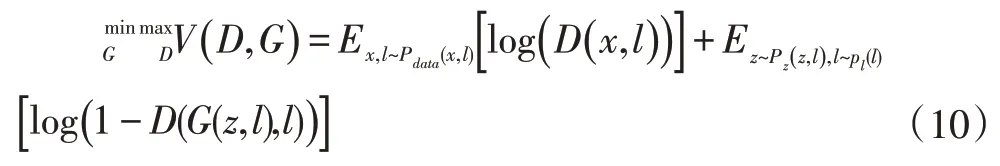
为了解决分类网络仅对小而稀疏的区域做出响应的问题,对抗性擦除方法(Adversarial Erasing,AE)[22]被提出来解决这一问题。该方法首先使用图像级标注的样本训练网络,利用分类网络定位图像中最具判别力的区域,然后从原始图像中擦除该区域,并将擦除后的图像用于训练定位其他区域的网络。重复进行对抗擦除操作,直到网络在被擦除的训练图像上不能很好地收敛。最后将被擦除的区域合并起来作为挖掘出的物体区域。
对抗擦除方法虽然取得了一定的成果,但是网络过于复杂,参数多、计算量大,对抗互补学习(ACoL)方法[23]虽然借鉴了对抗擦除方法的思想,但是计算复杂度大大减小。该方法可以在弱监督下自动定位语义感兴趣的区域,并采用两个平行的两分类器,其中一个分类器A用来定位具有判别性区域,而另一个分类器B用来定义A没有定位出来的感兴趣区域,从而形成一种互补。最后,将两个分类器的结果融合为输出。训练图集表示如公式(11),其中yi是图像的标签,N是图像的数量。

现有的许多语义分割算法只能在特定的场景下使用,泛化能力比较差,无法在相似数据集上取得不错的性能。为了解决这一问题,迁移学习逐渐被应用到语义分割,如基于深度迁移学习的生成对抗网络[24],该网络在浅层和最终输出层中添加对抗学习,使输出目标预测个更加接近源预测,然后反向传递弱监督语义分割算法,将不同空间的数据映射到某个特征空间。最后利用源域训练出的分割模型,通过迁移学习在目标域上获得良好的分割效果。损失函数由三部分组成,分别是Lseg分割损失函数、Ladv对抗损失函数和Lsemi弱监督损失函数,λ1、λ2是最小化多任务损失函数的两个权重。
3 基于自监督学习的语义分割方法
深度学习被广泛研究的状态下,监督学习需要利用大量的标注数据进行训练,但是标注成本很高而且很难获得。所以,我们希望用更容易获得的无标注数据训练出具有更好泛化能力的模型。为了解决这个问题,自监督学习因为它在表示学习方面的飞速发展,受到很多研究者的关注。深度学习中较早使用自监督学习的是2015年Doersch等人[25]提出的一种基于上下文的自监督学习方法。之后很多研究者都是借鉴这篇文章的思路进行研究的。
为了解决大部分自监督学习算法只针对输入空间已经部分定义的目标才有比较好的特征表达能力的问题,Deep InfoMax(DIM)模型[26]通过类似对抗自动编码器的方式,最大化输入和输出之间互信息。随后,在DIM的基础上提出AMDIM[27]模型了引入multiple views,实现最大化特征之间互信息的自监督学习方法,可以最大化从共享上下文的多个视图中提取特征质安监的相互信息,从而获得更好层次的特征信息。其中对DIM的一个改进是利用数据增强的图片进行特征提取,数据增强预测如公式(12),f1表示最终输出的一维向量,f7表示输出的是7×7的特征图,下标i、j表示在local feature map中某一图像块的索引。

最大化任意两个层的输出的feature map中,任意两个位置块之间的互信息,任意层任意两块之间的联合分布如,等,则数据增强图像的预测损失函数如公式(13),其中Nm表示m×m层的边缘分布pA(fm(x2)ij)中一组独立分负样本集合。

弱监督语义分割方法很多是基于CAM,但是它存在一定的局限性,语义覆盖不完整、语义不准确的问题。针对CAM的问题,进行了一系列的改进。为了提高网络的一致性预测能力,自监督的等变注意机制(SEMA)[28]将自注意机制与等变正则化相结合,并且对CAM进行了改进,引入了像素相关模块(Pixel Correla⁃tion Module,PCM),可以为每个像素捕获上下文外观信息,利用相似像素的特征来修正像素的预测结果。基于分段的网络模型和自监督的方法[29]对CAM进行了全面的改进,且以单阶段的方式来训练图像级标注的语义掩码。该方法基于CAM和PAC(Pixel-Adaptive Convolutional),包含三个模块:nGWP(normalized Global Weighted Pooling)、PAMR(Pixel-Adaptive Mask Refine⁃ment)和Stochastic Gate。其中nGWP是在CAM的基础上增加了focal mask penalty到class score;PAMR是基于PAC改进的,用于修正网络预测得到的粗糙mask;Stochastic Gate的作用是将深度特征与浅度特征随机结合,缓解自监督学习由于过拟合导致更多的错误。基于自监督的学习方法,如表3所示。

表3 自监督学习的方法
4 语义分割模型性能对比
图像语义分割常用的性能评价指标有:像素准确率PA(Pixel Accuracy)、像素准确率平均值MeanPA(Mean Pixel Accuracy)和平均交并比MeanIOU(Mean Intersection Over Union)。其中使用最广泛的是MeanI⁃OU如公式(14),因为它简单而且具有较好的代表性。平均交并比作为图像语义分割上的常用评价标准如公式,它是预测值和真实值的交集和并集的比,然后取平均值。MeanIOU的值越大,说明分割效果越好。

模型的性能评估要在标准数据集上进行,但是许多方法没有在标准数据集上进行实验,而且评价指标也不同,所以为了对提到的语义分割方法进行评估,选择以数据集PASCAL VOC 2012为标准数据集,MIOU为评价指标进行对比实验。实验结果如图1、图2所示。

图1 基于全监督学习的语义分割方法性能对比

图2 基于弱监督学习和自监督学习的语义分割方法性能对比(%)
从表1中可以看出来,基于数据集PASCAL VOC 2012、DeepLab-v3、DeepLab-v3+、RefineNet和MSPP算法得MIOU均超过了80%,这些方法将多尺度特征进行融合,并且整合上下文信息,对图像像素进行准确分类,实现图像语义分割。其中,DeepLab-v3+效果最好,它不仅继承了DeepLab系列的优点,还引入Encoder-Decoder模型和Xception模块,获取更丰富的语义信息的同时还提高了网络运行速度。
表2 是基于弱监督学习语义分割和自监督学习语义分割方法的性能对比实验结果。由于全监督学习的语义分割方法需要大量的像素级标注,浪费大量的人力物力,然而弱监督学习和自监督学习很好地解决了标注困难的问题。其中,基于GAN网络的语义分割方法的MIOU超过70%,语义分割准确率较高,GAN网络基于博弈思想进行对抗训练,使网络的鉴别能力不断提高。基于自监督的语义分割方法的MIOU超过60%,性能相对较低,虽然表现结果不如有监督学习,但是解决了像素级标注的高成本问题。

表2 弱监督语义分割方法
5 结语
基于深度学习的方法在图像语义分割应用中取得了不错的效果,但是仍有很多问题亟待解决。深度学习方法训练耗时很长,降低了语义分割的实时性;弱监督学习及自监督学习在一定程度上解决了训练样本难以获得的问题,但与监督学习方法相比效果并不理想。基于以上分析,图像语义分割的今后研究方向:①实时图像语义分割技术;②弱监督学习或自监督学习语义分割技术。
