牛乳体细胞分类器的研究与实现*
2021-08-19杨伟杰薛河儒白洁
杨伟杰 薛河儒 白洁
(内蒙古农业大学信息与工程学院,内蒙古呼和浩特 010018)
0 引言
奶牛养殖的源头环节就是要保障乳品的质量安全,奶质受损主要的原因就是奶牛患乳腺炎引起的,奶牛乳腺炎的诊断与治疗主要是依据牛奶中所含体细胞的类别与数量。体细胞由巨噬细胞、中性粒细胞、淋巴细胞和上皮细胞组成[1],要想对奶牛患乳房炎进行防治,就需要进一步的研究体细胞种类的分类情况。目前国内外对细胞检测有直接和间接两种计数方法,直接计数法中显微镜计数法是国际标准方法,但是该方法费时费力不适宜对大样本量的数据检测[2];间接计数法中加利福尼亚细胞数测定法是最常用的,但是该方法得到的细胞数测定值是估算值,准确率偏低[3]。牛乳体细胞与人体血液细胞存在很大的区别,目前国内外对于细胞的研究中大部分是面向人体器官的细胞图像,在研究牛乳体细胞分类识别方法占比较小。牛乳体细胞与血液细胞相比干扰信息更多,因此在分类上又增加了一定的难度[4]。本文针对牛乳体细胞构造分类器进行识别,对每一类分类器分类结果进行对比分析,分类结果显示本文构建的四类分类器分类结果精度较高并且可行。
1 单一分类器简介
1.1 KNN分类器
KNN(K-Nearest Neighbors,KNN)是一种较为简单的分类算法的一种。在距离的计算上,一般采用欧几里得距离或者马氏距离。K的取值很重要,假设一个M值,要判断它归属于哪一种类别,就要在样本特征空间中找到距离最邻近K距离的值,将样本中的多数情况作为依据,看属于哪一类别,则M就属于这一类别。K值选取太大会导致分类模糊,K值选取太小会导致受个例影响,波动较大[5]。使用交叉验证的方法来确定K的取值。本文是对四类细胞进行分类,所以使用的方法是ML-KNN多标签K近邻算法。它是在单标签KNN的基础上延伸的,主要的思想是在每一类样本中都包括了多个标签,然后对样本进行测试,在训练集中找到它的K近邻值,结合最近样本的综合信息,看和最近样本的信息是否一致,如果一致则归属同一类样本的数量。最终对样本标签集合进行测试采用的方法是最大后验概率原则[6]。
1.2 支持向量机分类器
支持向量机(Support Vector Machine,SVM)在图像分类、人脸识别中应用广泛,并且还扩展出一系列的算法改进和融合[7]。传统的SVM是一种二类分类方法,对数据只有两类的情况较为适用。本文有四类细胞,用到的是SVM的多类分类。成对分类方法是在每两个类之间都构造一个二类分类SVM。对于第i类和第j类数据,训练一个二类分类 SVM即求解二次规划问题如公式(1-3)所示:
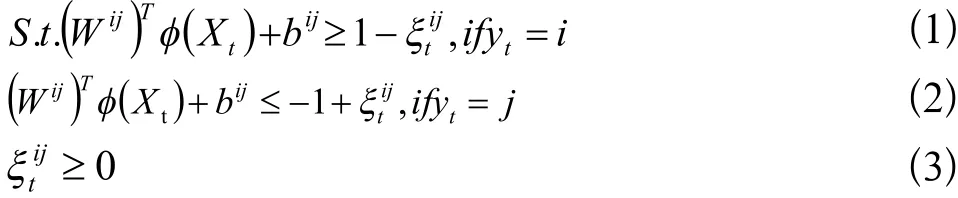
式中,i和j代表SVM的二分类参数,t代表i和j的样本索引,Φ代表非线性映射在输入空间到特征空间。
1.3 随机森林分类器
随机森林的主要思想是学习的集成,也就是说集成多棵树进而实现最终目的一种算法[8]。一组相同的数据,使用同样的算法仅会产生一棵树,在这种情况下Bagging策略则应运而生,它能够生成存在差异的数据集[9]。Bootstrap aggregation是Bagging策略来源,基本原理是如果一份样本集中包括了P个数据点,要在这份样本集中进行重采样,在重采样的过程中选择PB个样本[10]。在样本集中,基于PB个样本创建分类器,在这个基础上一直重复重采样和创建分类器,直到最终创建了F个分类器,判断数据属于哪一类,依据是看F个分类器给出的投票结果[11]。
1.4 BP神经网络分类器
BP神经网络(Back Propagation Neural Network,BPNN)在1986年提出,属于有监督的学习算法。对权值和阈值的调整训练通过反向传播算法来完成,尽量将误差平方降低到小于指定的误差值,则训练完成。对取得最小误差的权值和阈值进行保存。BPNN模型有输入层、输出层和隐含层三层。
BP神经网络具体运行过程描述如:(1)进行初始化对网络,明确各层的节点数量,对各层之间权值初始化。(2)计算隐含层的输出。公式(4)所示:wij表示输入层与隐含层之间连接的权值,a表示隐含层的阈值。(3)计算输出值。根据Q,对权重和阈值进行连接,预测输出进行计算。公式(5)所示。(4)计算误差。用预测输出值减去期望输出值。(5)对权值和阈值进行更新。根据误差对权值和阈值进行更新。(6)判断误差是否达到标准,即小于指定的误差值。若小于则结束,若没达到则继续进行迭代。
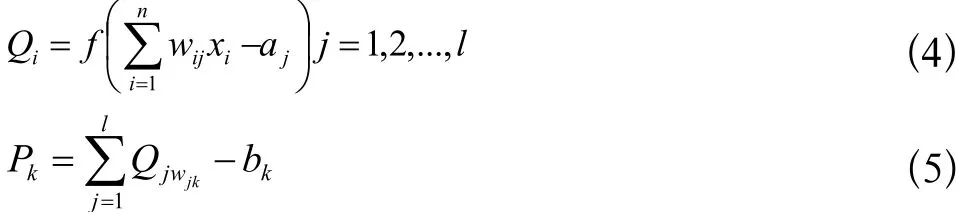
2 实验结果分析
本文用于实验的图像来自对牛乳体细胞中采集的120张细胞图像。包括四类体细胞,分别是巨噬细胞(30张)、淋巴细胞(30张)、中性粒细胞(30张)和上皮细胞(30张)。在四类细胞中共提供形态和纹理两种特征。本文利用灰度共生矩阵(GLCM,Gray-Level Co-Occurrence Matrix)对牛乳体细胞图像进行纹理特征的提取。本文共提取了六种纹理特征分别是对比度、差异性、逆方差、熵、相关性以及二阶矩,因为纹理特征之间差距小,所以又在这六种纹理特征的基础上分别提取了四个方向的值,共计24个纹理特征。提取了六种形态特征分别是面积、最小外接圆面积、周长、质面积、圆形度以及细胞核质比。一共提取的特征总计30种。
30类特征中纹理特征有24类,避免影响分类结果,利用随机森林对纹理特征进行优选,我们将优选出的贡献率排在前十的纹理特征和形态特征再次进行分类识别。纹理特征贡献率最后选取的是:0°、45°和90°的逆方差、0°的熵、45°和90°的对比度、0°和45°的差异性、0°和90°的二阶矩。优选特征之后的分类结果以及各分类器分类结果的标准差如表1所示:

表1 基于优选特征识别的准确率(%)Tab.1 Accuracy rate based on preferred feature recognition(%)
分析表1得到经过优选之后的形态和纹理特征以及总特征准确率较高。其中随机森林分类器准确率达到96.84%,准确率最低的是K近邻分类器,准确率仅有90.98%。随机森林分类器的准确率明显高于其他的分类器,标准差最低,准确率最高且结果最稳定。SVM分类器相较于神经网络分类器分类的准确率最为接近。所有的分类器中,标准差最大是SVM分类器,其测试准确率结果的不稳定性最高。
3 总结
本文针对牛乳体细胞构建单一分类器进行分类识别,发现不同分类器对于不同的牛乳体细胞分类效果不同,且每一个分类器均具有各自的特点。四类分类器中最好的单一分类器是随机森林分类器。实验结果证明本文构建的四类单一分类器针对牛乳体细胞进行分类识别精度较高且可行。
