融入改进的K-means聚类的协同过滤算法的研究与应用
2021-08-17刘鑫


摘 要:本文通过对K-means聚类算法和协同过滤推荐算法的学习研究。针对基于用户的协同过滤算法的不足,将改进的K-means聚类算法融入其中,设计了基于K-means聚类算法的个性化推荐算法,并将其应用于旅游景点及线路的个性化推荐中,以提高个性化推荐质量。实验结果表明,基于改进的K-means聚类的协同过滤算法缓解了初始数据的稀疏性问题,针对不同用户喜爱的旅游景点及线路推荐,在准确率和召回率两个方面证明可以提高个性化推荐的准确度。
关键词:K-means聚类;协同过滤算法;最小生成树
中图分类号:TP183 文献标识码:A DOI:10.3969/j.issn.1003-6970.2021.03.027
本文著录格式:刘鑫.融入改进的K-means聚类的协同过滤算法的研究与应用[J].软件,2021,42(03):097-099
Research and Application of Collaborative Filtering Algorithm Incorporating Improved K-means Clustering
LIU Xin
(Jilin Institute of Architecture and Technology, Changchun Jilin 130114)
【Abstract】:This article is based on the study of K-means clustering algorithm and collaborative filtering recommendation algorithm. Aiming at the deficiencies of the user-based collaborative filtering algorithm, the improved K-means clustering algorithm is incorporated into it, and a personalized recommendation algorithm based on the K-means clustering algorithm is designed and applied to the personalized recommendation of tourist attractions and routes In order to improve the quality of personalized recommendations. The experimental results show that the collaborative filtering algorithm based on improved K-means clustering alleviates the sparsity problem of the initial data. It is proved that it can improve the personalization in terms of accuracy and recall rate for different users' favorite tourist attractions and routes recommendation. Recommended accuracy.
【Key words】: K-means clustering;collaborative filtering algorithm;minimum spanning tree
0引言
随着互联网的飞速发展,信息资源呈现几何级数增长,用户在大量的信息中很难获取到真正需要的数据信息。传统的搜索引擎已无法满足用户的特殊需求,因此个性化推荐系统应运而生,并成为了解决信息过载问题的有效方法。一个完整的个性化推荐系统总体框架包含三个部分:数据特征提取模块、个性化推荐模块、推荐结果模块。个性化推荐系统能够根据用户个人喜好自動进行信息推荐,减少信息的冗余,简化用户的操作,因此个性化推荐算法也逐渐成为学术界的研究热点之一[1]。
1主要技术
1.1协同过滤算法及其存在的问题
推荐系统中协同过滤推荐算法是当前应用最为广泛,研究最多,影响最为深远的个性化推荐技术,协同过滤推荐算法的主要思想是:为了更好的服务目标用户,为用户推荐个性化的商品信息,需要获得用户的喜好,即在一个大的数据库中使用相似度计算公式计算搜索目标用户的N个最近邻居,根据N个用户对商品喜好的评分,建立评分矩阵,并预测目标用户所喜好的商品的评分,进行降序排序,将评分最高的前M个商品推荐给目标用户。协同过滤算法的原理图如图1所示。首先进行算法的输入,即数据信息的采集,包括用户的基本信息、商品的基本信息及用户与商品间的关系信息,然后进行协同过滤算法处理,即相似度计算,找到N个最近邻居,最后得到输出结果,即将前M个商品推荐给目标用户。协同过滤算法依据初始评分矩阵,因此存在着数据稀疏性问题,会导致推荐准确性不高[2]。
1.2 K-means 算法
K-means算法是James MacQueen在1967年提出的,K-means算法是一种基于最近距离划分进行聚类的算法,算法根据目标函数求得最近距离计算相似度,是数据挖掘研究领域中最常用的算法之一。K-means的基本思想是首先在预定的样本集中随机选取K个质心作为初始聚类中心,构成K个簇集,然后计算剩下样本和 K 个初始聚类中心的距离即相似度,将各个样本分别划分给离他最近也就是相似度的值最大的一个簇集中,每次划分后,再根据现有簇集重新计算获得新的聚类中心。不断循环这个过程,直到聚类中心不再变化或者函数满足了收敛条件[3]。
K-means算法进行聚类操作,算法原理简单,易于操作,基于大数据集合进行聚类的运算速度快、效率高。但由于K-means算法中初始的聚类中心是由随机选取方式选定,因此,在聚类过程中初始聚类中心的不确定性会影响推荐结果的准确性。本文提出改进的K-means聚类算法。
2 改进的K-means算法
针对K-means算法由于初始聚类中心不确定带来的影响,增加了用户的属性描述,并基于用户属性计算用户相异度的值,作为边的权值建立图结构,应用kruskal算法计算生成初始聚类中心,将其用于K-means算法中,该算法可以提高初始聚类中心的个数和位置的准确性,提高推荐系统的推荐效率[4]。改进的K-means算法的具体步骤如下:
(1)初始用户信息,对系统中用户基本信息进行预处理,增加用户属性描述(性别、年龄、学历、职业、兴趣爱好)使用公式1.1计算用户间的相异度值C(不同用户相同属性的相异值的个数P(ui≠uj)与用户属性总个数P(ui,uj)的比值),规定相异度值越小则用户间的相似度越大。
公式1.1
(2)根据公式1.1计算用户相异度值;
(3)将用户相异度值C作为边的权值,构造无向加权图G=({V},{E});
(4)应用Kruskal算法求出图G的最小生成树T= (U,TE),步骤如下:
1)初始化:U=V;TE={ };
2)将边集E按照从小到大进行排序,依次在E集合中寻找最短边(u,v)
3)如果顶点u,v位于T的两个不同的连通分量,则将边(u,v)加入到最小生成树的边集合TE中,顶点u,v 加入到顶点集合U中;
4)循环执行第③步,直到最小生成树T中的连通分量个数为1结束;
(5)在建立的最小生成树中选择权值最大的N个WeightMax和权值最小的N个WeightMin,求出它们的平均值,在最小生成树中删除大于平均值的边及孤立的顶点,将剩余顶点作为k个用户集合,然后计算得到k个分类的集合中心,即构成了初始的k个聚类中心。
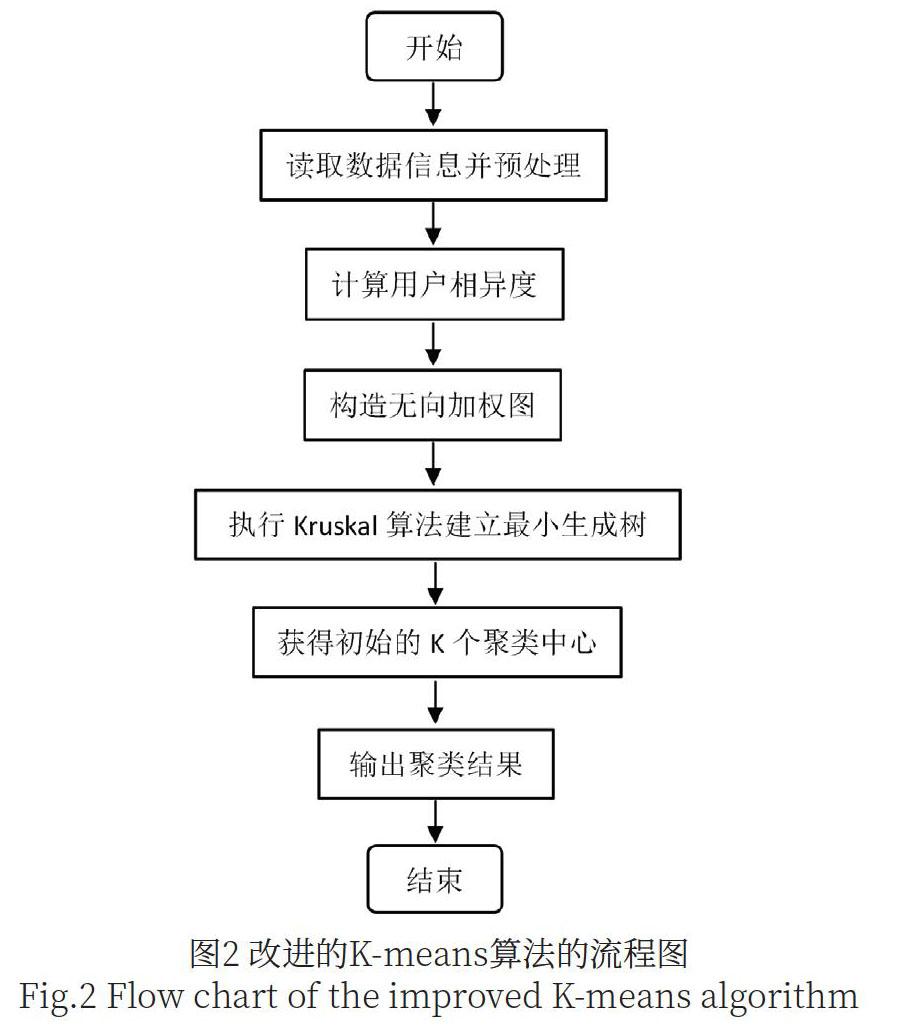
(6)执行K-means聚类算法,通过余弦相似度计算公式,完成聚类划分。改进的K-means算法的流程图如图2所示。
3融入改进的K-means聚类的协同过滤算法在旅游景点及线路个性化推荐系统中的应用
本文将融入改进的K-means聚类的协同过滤算法在旅游景点及线路个性化推荐系统中,通过用户数据及评分矩阵,建立相似用户集,完成旅游景点及线路的个性化推荐[5]。
第一步,数据预处理,初始化用户特征属性信息、各景点游览路线信息及用户对已游览过的景点评分信息,建立初始评分矩阵Aij;
第二步,根据初始评分矩阵Aij,运用kruskal算法获得个数及分布均匀的初始C个聚类中心;再执行改进的K-means 算法完成对用户的聚类划分,形成不同的相似用户簇集;
第三步,对于目标用户u,首先根据余弦相似度计算公式计算其与新生成的聚类中心的相似度,选择相似度最大的簇集Cu,将目标用户划分到此簇集中;在簇集内查找目标用户的K个最近邻居;
第四步,根据预测评分算法及目标用户的K个最近邻居,对目标用户中未评分的景点项目进行预测评分,将评分由高到低排序,并将前Top N个线路进行推薦。
系统测试产生的推荐结果表明:融入改进的K-means聚类的协同过滤算法提高了推荐质量,针对不同用户的喜好提高了个性化推荐的准确率。
4总结
本文首先针对K-means聚类算法随机选取初始聚类中心,导致聚类效果不佳的问题,将最小生成树Kruskal算法应用在K-means聚类算法中,设计了改进的K- means聚类算法,并将其融入到协同过滤算法中,应用于旅游景点及线路个性化推荐系统中,同时在建立系统的评分矩阵时,引入了旅游用户、景点信息及用户对线路的特征属性等信息,解决了协同过滤算法在初始数据上的稀疏性问题,提高推荐算法的准确率。
参考文献
[1] 刘荣权,袁仕芳.基于用户属性聚类与矩阵填充的景点推荐算法[J].计算机技术与发展,2020(11):206-210.
[2] 顾明星,黄伟建.结合用户聚类与改进用户相似性的协同过滤推荐[J].计算机工程与应用,2020(9):185-189.
[3] 常亮,曹玉婷.旅游推荐系统研究综述[J].计算机科学,2017 (10):1-6.
[4] 刘鑫.改进的协同过滤算法在商品推荐中的应用[J].电子技术与软件工程,2020(2):220-222.
[5] 李俊.基于聚类的推荐算法研究与应用[D].南京:南京邮电大学,2018.
