舆情场景下基于层次知识的话题推荐方法
2021-08-17史存会胡耀康俞晓明程学旗
史存会 胡耀康 冯 彬 张 瑾 俞晓明 刘 悦 程学旗
1(中国科学院计算技术研究所数据智能系统研究中心 北京 100190) 2(中国科学院网络数据科学与技术重点实验室(中国科学院计算技术研究所) 北京 100190) 3(中国科学院大学 北京 100049) 4(烟台中科网络技术研究所 山东烟台 264005)
随着信息技术的发展,互联网正深刻地改变着大众的方方面面,逐渐成为生活不可或缺的组成部分.
人民网发布的2017网络舆情报告(1)http://yuqing.people.com.cn/GB/n1/2018/0103/c209043-29743172.html指出,依托于移动互联的信息分享和意见交流的工具,如“两微一端”(微博、微信、新闻客户端),已经越来越多地成为社会舆论发源地和发酵平台.庞大的网民基数带来的巨大影响力已使得传统媒体对舆论场的影响力减弱,网络用户发表的各种言论与意见已经可以形成强大的舆论压力,网络舆情正在成为社会舆情的主要部分.
互联网中时刻都在产生新的信息,舆情也随之发展演变,但是网络中的信息本身完整性无法得到保证,信息碎片化会影响用户的判断.舆情用户想要抓住其脉络需要重新组织信息方法,话题即为其中一种可行的方式,将信息以话题的粒度进行聚合,能充分提高用户获取信息的效率.
另外,由于各种舆情事件层出不穷,很短时间就能在不同媒介得到迅速传播,被大规模网民广泛关注与参与,并有可能引发互联网空间或现实社会的强烈反响,乃至诱发大规模群体性事件.于是,以话题推荐为代表的网络舆情精准化信息推送手段在舆情场景应用中得到广泛的关注.
1 相关工作
话题推荐同时涉及话题和推荐方法相关工作与研究,2个领域经过多年的发展都形成了相对成熟技术方案体系.近年来,深度学习相关技术的蓬勃发展,也带动了两者相关的研究,出现了很多探索、尝试以及新的解决思路.
1.1 话题相关工作
话题检测任务(topic detection task, TDT)[1-2]是在缺乏话题先验知识的情况下进行检测,将同一个话题的对象归为一类,形式上与聚类目标相近,故而目前大部分相关研究集中在使用聚类方法来进行话题检测.主要有基于划分的聚类、基于模型的聚类、基于密度的聚类等,较为常见的有K-Means,BIRCH(balanced iterative reducing and clustering using hierarchies),SinglePass等聚类算法.除此之外还有一类基于概率生成模型的话题检测方法,包括pLSA(probabilistic latent semantic analysis)[3]和LDA(latent Dirichlet allocation)[4],及其改进算法等.
1.2 推荐相关工作
推荐主要是用来给特定用户提供其最可能感兴趣的选项的技术,其可以增加用户满意度和忠诚度及更好地理解用户需求,有效解决信息过载的问题,让用户及时、有效地发现其感兴趣的内容,使用户更高效地获取信息.推荐系统粗略来看可以简单分为早期的传统推荐模型与近些年研究较多的基于深度学习的推荐模型.传统推荐模型主要为较早期出现的推荐模型,典型的有协同过滤推荐[5-6]、基于内容的推荐以及混合推荐模型[7]等.
协同过滤主要是使用用户评分或用户行为(如购买、浏览、点击等)来给用户进行推荐,无需与用户或物品相关的信息.主要特点是利用用户行为计算相似度,然后利用相似的近邻预测得分来推荐.与之相对的还有一种基于矩阵分解的协同过滤模型,这类模型重点在于挖掘用户对物品评分矩阵中的潜在特征.包括pLSA[3],LDA[4]以及基于用户-物品评分矩阵分解的如SVD(singular value decomposition),SVD++[8]等方法.
另外,借鉴深度内容分析技术的基于内容语义的推荐方法成为了近年来最具创新性的研究之一[9].总体上,我们可以将语义相关的内容推荐方法分为自顶向下与自底向上的2类.前者主要在于集成外部知识到推荐系统中,知识可以是词典、知识图谱等信息[10-12].而自底向上的方法在于通过大量语料中词项的上下文来学习其分布式表达[13-14].随着知识图谱等技术的发展,引入先验知识能有效提升模型效果,基于内容的推荐模型被重视起来.
近年来,深度学习在语音识别、图像处理和自然语言处理等领域的革命性进步受到了极大的关注.深度模型也通过各种方式被引入到推荐领域,Betru等人[15]对此进行了分类,主要有基于多层感知机的推荐模型[16-20]、基于卷积神经网络的推荐模型[21-24]、基于循环神经网络的推荐模型[22-23,25]等.
2 基于层次知识的话题推荐方法
舆情场景下,系统会在全网采集信息,信息源主要包括门户网、社交网、新闻媒体,如腾讯、网易、新浪、搜狐、凤凰网、微博、贴吧以及各种论坛等.然后将这些信息进行清理过滤,按照一定的聚类或者分类算法对信息进行聚合,在此基础上舆情系统会选择如舆情指标体系等方法对信息进行多维度的计算排序,然后展示给舆情用户.总的来说这些方法较多依赖于统计特征来选择信息,无法挖掘信息之间语义上的关联,很难用来刻画用户兴趣,亦不能针对用户进行有效地个性化推荐.本文提出基于层次知识嵌入的话题推荐方法,利用层次知识深入挖掘话题信息中的语义的关联,为用户进行个性化话题推荐.本节的推荐模型中充分利用语义信息来选择舆情用户最可能关注的话题来进行推荐展示,提升了舆情选题的效果.
随着深度神经网络相关技术在计算机视觉、语音识别、自然语言处理等领域遍地开花,尤其是自然语言处理领域在相关技术的加持下发展更是突飞猛进.这使得基于内容的推荐方法也重新得到了学术界和工业界越来越多的关注,取得了不少进展.目前不少工作集中在如何将知识图谱等外部先验知识引入推荐模型中,但是知识图谱的构建本身极为复杂与严格,需耗费大量的成本,在舆情场景中亦不太适用.舆情场景中信息繁杂且更新频繁,另外知识图谱主要基于实体与关系,能利用的文本信息有限,本文利用较为容易获取的层次知识挖掘潜在的语义信息,提高话题推荐的效果.
2.1 模型介绍
对本文提出的基于层次知识网络(hierarchical knowledge network, HKN)的话题推荐模型,整个模型主要分为3层,最底层为层次知识表示网络(hierarchical knowledge representation network, KRN),用于学习知识的嵌入表示,在此基础上使用话题表示网络(topic representation network, TRN)学习话题的嵌入表示,然后利用注意力模型学习用户表达,最后将学习到的用户表示与候选话题表示进行相似计算,计算用户对候选话题的点击概率,如此即为整个基于层次知识的话题推荐模型.
2.2 问题定义
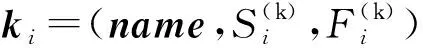
2.3 层次知识表示
如图1所示,层次知识主要包含:知识节点、知识描述以及知识间的层次关系,即每个知识节点包含其对应的知识描述及其父节点.层次知识相对知识图谱更易获取,约束也相对较少,没有知识图谱中复杂的关系和实体信息,这使得层次知识构建相对容易.层次结构是逐层细化的关系,所以结合推荐技术可以使用层次信息来扩展用户兴趣语义,深入挖掘用户兴趣.
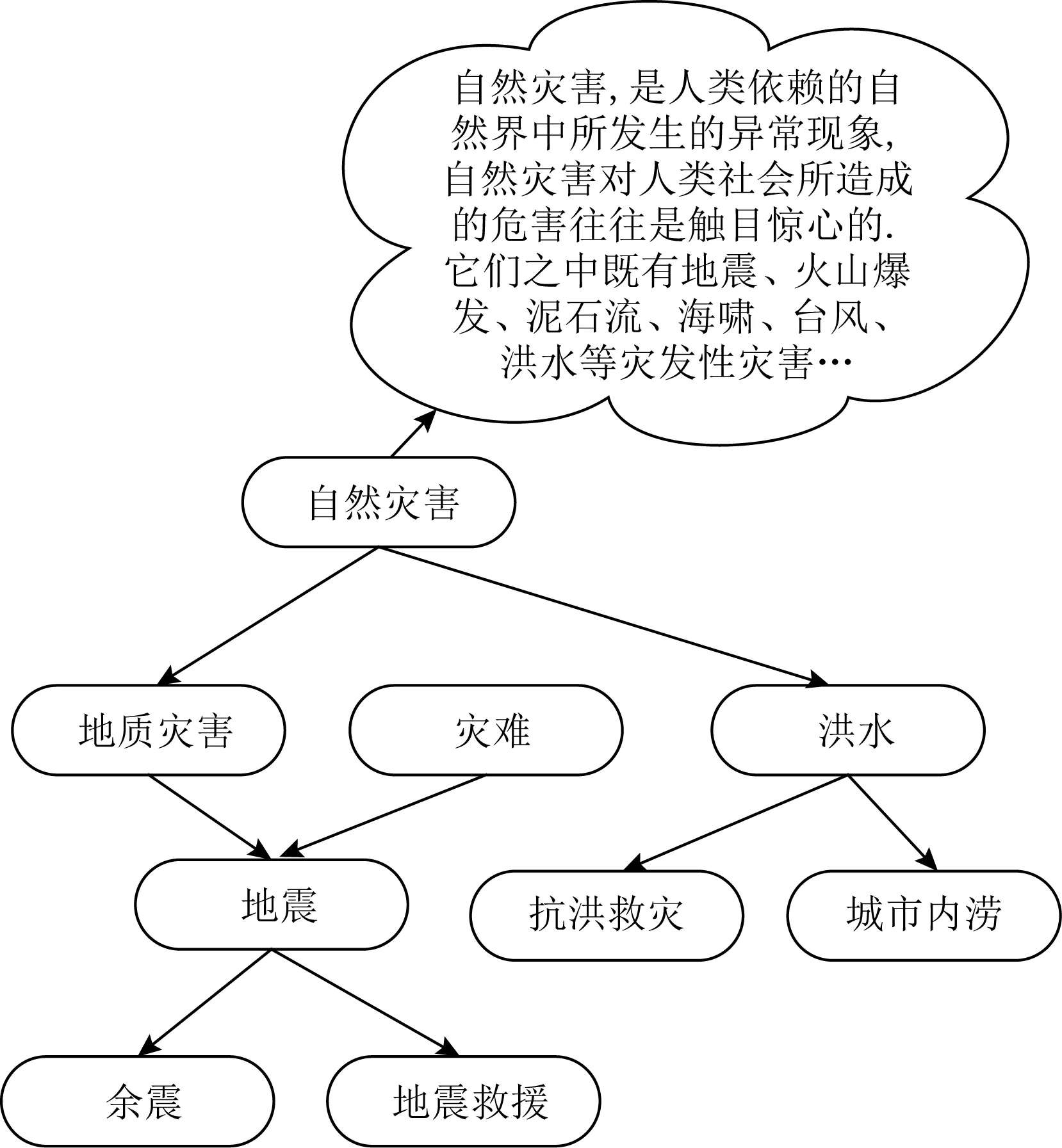
Fig. 1 Hierarchical knowledge图1 层次知识
知识由其名称以及与其关联的节点组成,本模型利用层次注意力模型学习层次知识的表达,充分挖掘其中的语义信息;然后在层次知识路径序列上使用循环门控网络对层次序列进行编码,最后再利用注意力模型整合得到知识表示.
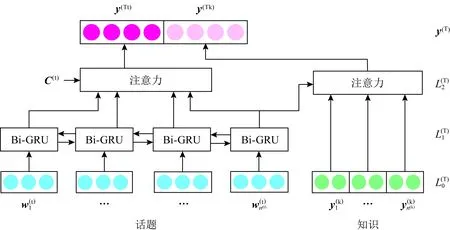
Fig. 3 Network of topic representation图3 话题表示网络
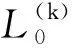
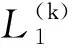
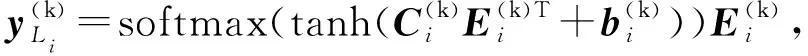
(1)


(2)

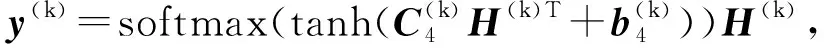
(3)
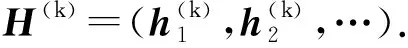
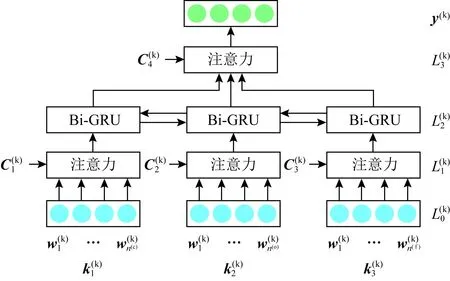
Fig. 2 Network of knowledge representation图2 知识表示网络
2.4 话题表示

为了评估水分胁迫对各处理番茄的影响,每隔25 d左右用土钻沿着番茄的主茎取土,用烘干法测定各处理番茄根区0~40 cm深度的土壤含水量,每个处理3个重复。

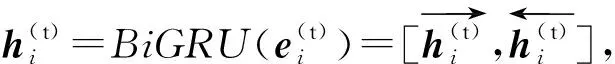
(4)

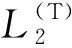
y(Tt)=softmax(tanh(C(t)H(t)T+b(t)))H(t).
(5)
话题的知识表达部分y(Tk)计算为

(6)
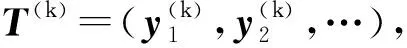
最后输出层的结果y(T)即为话题的向量嵌入表示,如式(7)所示,由话题的词嵌入表示和知识嵌入表示拼接得到.
y(T)=concat(y(Tt),y(Tk)).
(7)
以上即为话题表示网络,模型主要通过话题标题和话题包含的知识信息来学习话题的嵌入表达,模型也使用了KRN模型来学习知识的表示.
2.5 基于层次知识的话题推荐模型
基于层次知识的话题推荐模型基本结构借鉴于语义匹配模型,即分别学习候选话题和用户的嵌入表示,然后根据两者的相关性来预测用户点击.模型结构如图4所示,模型可以分为6层.
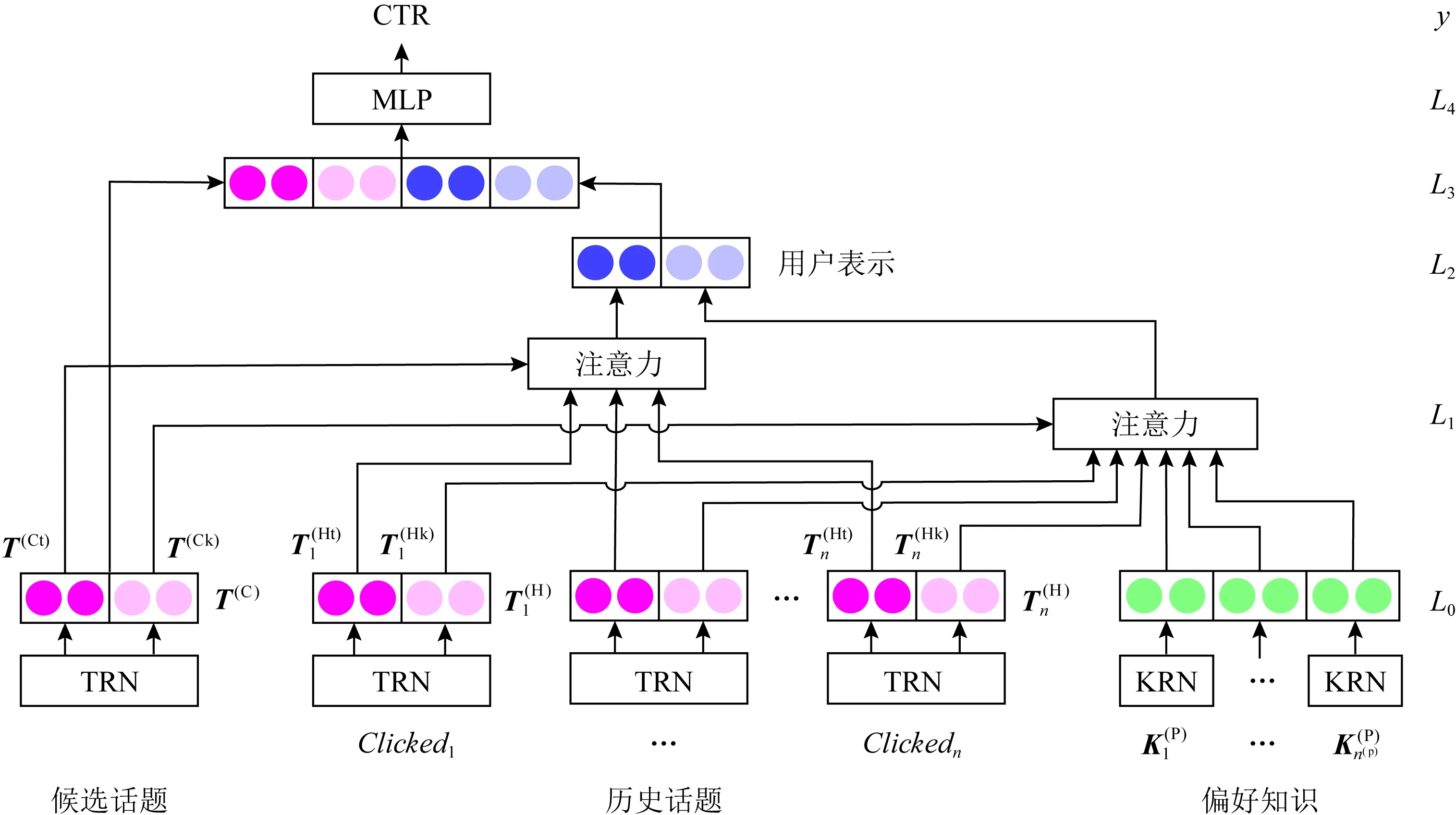
Fig. 4 Hierarchical knowledge based topic recommendation model图4 基于层次知识的话题推荐模型

L1层由话题注意力层和知识注意力层2部分组成,前者为话题标题注意力,计算为
u(Tt)=softmax(tanh(W(Tt)T(Ct)T(Ht)T+b(Tt)))T(Ht).
(8)
后者为知识注意力,使用候选话题的知识嵌入部分作为注意力信号,另外此处加入了用户知识偏好K(P),用户知识部分表达可计算为
u(P)=softmax(tanh(W(P)T(Ck)K(HP)T+
b(P)))K(HP),
(9)
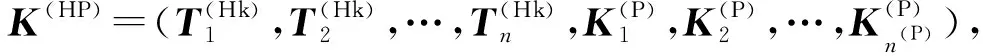
L2层将2个注意力网络的输出拼接从而得到用户的嵌入表示u:
u=concat(u(Tt),u(P)).
(10)
L3层为拼接层,将候选话题的表示与用户表示进行拼接,作为L4层匹配层的输入,最终根据式(11)计算两者的相似度来预测用户点击率.
y=MLP(concat(T(C),u)).
(11)
3 实 验
本节将详细介绍考虑层次知识的话题推荐方法的实验细节,包括实验数据集、作为对照的基线算法、评价指标以及实验的参数设置等.
3.1 数据集
实验所用数据是从CCIR2018知乎个性化推荐评测数据集(2)https://biendata.com/competition/CCIR2018/data/中构建,并从知乎网站抓取了层次知识结构的数据,该数据集主要分为3部分,即用户数据、内容数据与交互数据.
如表1所示为话题数据实例,可以看到该话题名称为“如何看待美国正式公布涉及500亿美元出口的301征税清单?”;话题包含“中美关系”“外交”“中美贸易”“经济”这4个知识信息;每个知识可以找到其相关联的层次知识,如“中美关系”的父节点有“国际关系”与“地缘政治”,其子节点有“中美冲突”“中美贸易战”“中美建交”和“中美博弈”.
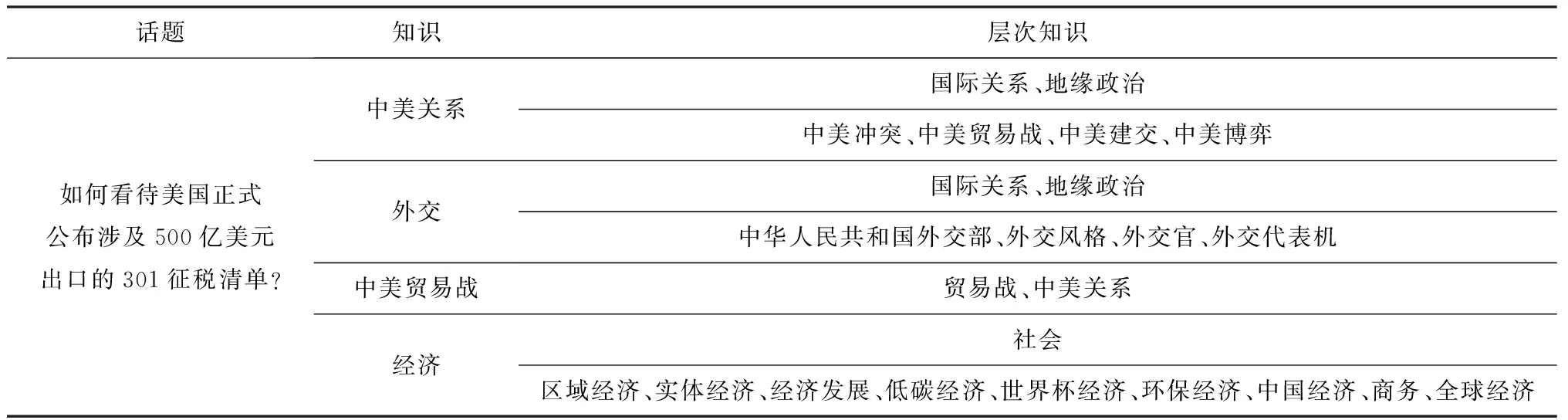
Table 1 An Example of a Topic
3.2 数据处理
为了让数据便于处理,本文对数据集进行了必要的处理.主要包含以下规则:1)按知识标签筛选舆情相关的数据,筛选的主要数据范围为政治、军事、民生、经济、事故以及灾害等.2)对具体数据也有筛选如知识标签数据,即1个话题至少需含有以上类别的知识信息,用户知识偏好必须含有5个以上的舆情类别的知识;另外,标题长度必须大于等于6个词语,最多16个词语,超出的截断,不足的删除;对历史信息条数不足10条的记录也删除.最后共选择了100 000条记录作为实验数据.
处理后的一条数据主要包括4部分,分别是用户偏好、用户历史、候选话题、点击标记.用户偏好集用户关注的知识信息,用户历史为用户最近对话题的点击记录,候选话题即要进行预测点击率的话题,点击标记为用户对候选话题是否进行了点击.
3.3 评价指标
在推荐场景中,存在各式的评价指标,并有不同的适用条件.由于本文预测的是话题的点击率,所以采用F1(the balancedFscore)值与AUC(the area under curve)值来进行评价.
F1值常被用于二分类模型中评价模型的指标,它被定义为准确率与召回率的调和平均数,可以兼顾两者;另外点击率预估可以建模为二分类问题,因此F1值比较适合.
AUC与F1值需要确定正负样本具体的分割值,而AUC计算可以等价于随机抽样时正样本排在负样本前的概率,在推荐场景中AUC有重要的意义.
3.4 基线算法
本文选择的基线算法主要有以下4种:
1) LibFM(factorization machine library)[26]是因子分解机FM(factorization machines)模型的一个开源实现,作为经典的基于特征的机器学习算法,因子分解机FM模型具有很好的适应性,在很多领域都有很好的效果.LibFM作为FM模型的软件实现是一个不错的基线算法.
2) Wide&Deep(jointly trained wide linear models and deep neural networks)[16]模型主要是结合了线性模型的记忆能力与深度模型的泛化能力,从而整体提升模型性能,谷歌已将该模型应用到线上.
3) DeepFM(factorization-machine based neural network)[20]模型在Wide&Deep的架构上,使用FM模型代替了Wide部分的LR模型,从而告别了繁琐的人工特征工程,该模型在实际业务中也取得了不错的效果.
4) DKN(deep knowledge-aware network)[24]模型是通过结合实体嵌入、单词嵌入以及实体上下文来学习新闻表达,然后利用注意力机制结合用户浏览记录来学习用户表达.最后根据学到的用户表达和候选新闻表达联合计算,用户点击该条新闻的概率的推荐模型.
3.5 参数设置
实验中使用的词嵌入为腾讯人工智能实验室开源的中文词嵌入(3)https://ai.tencent.com/ailab/nlp/embedding.html. 本文使用训练集进行初步实验获取超参数,对于缺失的词向量进行随机初始化,模型训练终止条件是在损失值趋于稳定时. 最终相关超参设置如下:词向量维度为200,学习率为0.001,BiGRU隐层数均为100,多层感知机隐层为50,优化器为SGD,模型训练的批大小为32,模型迭代轮数为500,在多层感知机中dropout值为0.3.
3.6 实验结果分析
为了对比本文提出的基于层次知识嵌入的话题推荐模型与现有的同类型模型之间的效果差异,并验证层次知识的有效性,本文按照基线模型的特点在处理过的数据集上做了对比实验.其中参与对比的基线模型主要有LibFM,Wide&Deep,DeepFM,DKN等模型.
如表2所示为模型间的对比实验结果,表3所示为本模型对比基线模型的提升效果,即用本模型的效果减去基线模型效果.

Table 2 Comparison of Models
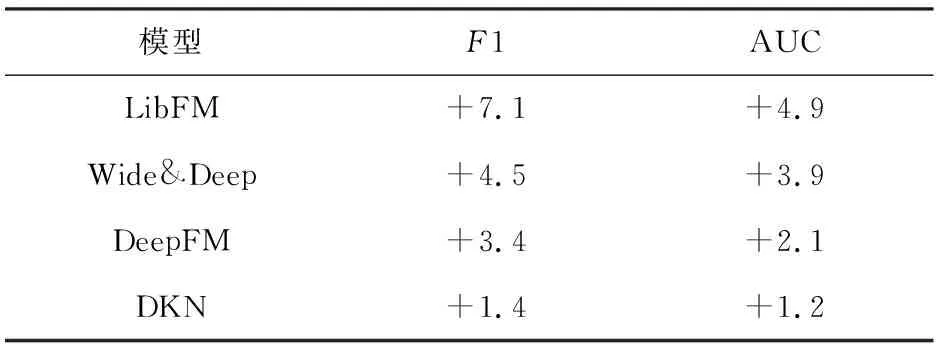
Table 3 Comparison of HKN Improvements
本文提出的基于层次知识嵌入的话题推荐模型HKN在F1与AUC这2个评价指标上效果都超出了基线算法中效果最好的DKN模型,对比之下本文的模型在F1和AUC指标上分别提升了1.4和1.2个百分点.另外除了DKN模型之外,对比最好的基线算法,分别提升为3.4和2.1个百分点,由此可以看出使用语义信息的模型HKN和DKN相比没有利用语义信息的模型如DeepFM,Wide&Deep模型而言具有显著的优势.另外DKN模型原本使用的是知识图谱中关系的嵌入以及上下文结构信息和更有实体信息,其在原始数据集上就有不错的表现,所以在层次知识嵌入后亦能取得不错的效果,但是对比HKN没能利用到层次知识的信息,而两者均没有使用语义信息,因此最终模型的效果还是被HKN模型超越.对比Wide&Deep与DeepFM,两者具有不少共通之处,后者是前者的改进,因此能取得更好的效果.由于LibFM使用的仅是TF-IDF特征,不能充分挖掘更多语义信息,故而效果提升不明显,又由于LibFM是所有模型中唯一一个非深度模型,模型使用的信息相对较少,故而最后效果相对较差.经过分析不难得出由于HKN模型充分利用了层次知识信息,所以与基线模型对比取得了良好的效果,HKN模型在基线算法的F1和AUC指标上均有提升.
4 总结与展望
随着互联网技术的飞速发展,互联网逐渐成为人们获取信息的主要渠道.针对个性化监测的精准推送需求,舆情话题的时效性高以及用户数较少,导致了用户的交互信息十分稀疏,难以刻画用户兴趣,本文考虑使用基于内容的推荐方法,引入层次知识信息,提出了一种基于层次知识的话题推荐方法,对用户兴趣使用层次知识和用户历史记录信息学习用户嵌入表示,然后和话题嵌入表示一起来预测用户点击,生成推荐列表,并取得了良好的效果.
本文研究了基于层次知识的话题推荐方法,主要是基于深度学习的内容推荐模型.下一步工作可以在本文已有的研究基础上做进一步改进优化.本文通过引入层次知识,来增加话题信息之间的潜在语义关联,解决在舆情场景下因用户交互稀疏导致的用户画像难以刻画的问题,后续研究可以继续探索引入诸如知识图谱等不同的外部信息,对比效果的差异.在推荐领域,可解释性一直是研究热点,一般来说基于内容的推荐方法具有较好的可解释性,本文中基于层次知识的话题推荐方法也具有一定的可解释性,后续的研究可以以此为基础继续探索如何提高推荐结果的可解释性等.
作者贡献声明:史存会负责设计研究思路、方法、完成实验及论文;胡耀康负责提出方法,完成实验及论文;冯彬负责完成实验和论文;张瑾负责设计研究思路、方法;俞晓明、刘悦、程学旗负责提出研究思路和方法.
