用于金融文本挖掘的多任务学习预训练金融语言模型
2021-08-17WayneLin
刘 壮 刘 畅 Wayne Lin 赵 军
1(东北财经大学应用金融与行为科学学院 辽宁大连 116025) 2(中国石油物资采购中心 沈阳 110031) 3(南加州大学计算机学院 美国加利福尼亚州洛杉矶 90007) 4(IBM研究院 北京 100101)
海量的互联网金融信息在金融市场中有着举足轻重的地位,对网络金融文本信息的挖掘工作具有很大的实际价值.随着大数据时代的到来,金融大数据挖掘已成为行业热点趋势,面向金融的机器学习技术吸引了越来越多的关注.面对每日产生的数量惊人的金融文本数据,如何从中提取有价值的信息已经成为学术界和工业界一个非常有挑战的研究.如果我们采取人工的方式来分析这些文本信息并从中获得可行的见解几乎是一项极其艰巨的任务.机器学习技术的进步使金融科技中的金融文本挖掘模型成为可能.但是,在金融文本挖掘任务中,构建有监督训练数据代价非常高昂,因为这需要使用财务领域的专家知识.由于可用于金融文本挖掘任务的有标签训练数据量很少,因此大多数金融文本挖掘模型无法直接利用深度学习技术.
在本文中,我们创新地提出了F-BERT模型,通过利用自监督学习和多任务学习的深度神经网络方法来解决该问题.当前,金融科技中的金融文本挖掘模型主要是采取基于深度学习(deep learning)的自然语言处理(natural language processing)技术.
目前,自然语言处理主要使用基于深度神经网络的技术,其发展主要有两大里程碑工作.首先是2013年提出并不断发展的以Word2Vec[1]为代表的词向量技术,例如Word2Vec,GloVe[2]等;第2个里程碑是在2018年底由谷歌提出的以BERT(bidir-ectional encoder representations from transformers)[3]为典型代表的预训练语言模型(pre-training language models)技术,例如BERT,ELMO[4]等.其中,诸如Word2Vec,GloVe之类的词编码是从无监督语料库中提取知识的一种方式,已成为自然语言处理的主要进步之一.但是,由于在金融领域中包含了很多专业术语,因此这些简单的词向量方法不够有效.另一方面,预先训练的语言模型技术,例如BERT,ALBERT[5]等,采取在大规模无监督数据(例如维基百科数据等)上进行了预先训练,经过大规模语言模型预训练,BERT获得了有效的上下文表示.与Word2Vec词向量相比,BERT能够充分利用深度预训练模型的参数,可以更有效地学习上下文知识.但是,模型的预训练(例如BERT)主要使用基于简单的预训练任务来对语言模型进行训练,从而使得模型具备掌握单词或句子共现的能力.实际上,除了共现之外,还有其他词汇、句法和语义信息需要在训练语料库中进行检查.尤其是对于金融文本数据,例如,股票、债券类型和金融机构名称之类的命名实体包含唯一的词汇信息.此外,诸如句子顺序和句子之间的接近度之类的信息也使模型能够学习语义感知表示.并且,BERT的预训练数据来自Books Corpus和英文维基百科,这些语料不一定和目标任务的语言环境相近,如金融领域.因此,如果我们直接使用BERT进行金融文本挖掘,效果并不是很好.
为了在大型金融训练语料库中有效地捕获语言知识和语义信息,我们构建了涵盖更多知识的4个自监督学习的预训练任务,并通过对训练数据进行多任务学习来训练F-BERT.具体而言,我们创新地提出了F-BERT模型,在该模型架构中,我们构建了4个自监督学习预训练任务,并同时对普通文本语料和金融领域文本语料进行了学习,从而使得F-BERT可以更好地捕获金融文本数据的语言知识和语义等信息.总结来说,本文的主要贡献有5个方面:
1) 利用深度学习领域的自监督学习和多任务学习技术,提出了一种基于BERT模型架构的大规模语料上训练的开源金融预训练模型F-BERT.
2) 构建了4个自监督学习预训练任务,可以通过多任务自监督学习来进行同时预训练,通过该机制可以有效地捕获大规模预训练语料中的金融语言知识和语义等信息.
3) 分别在金融关系提取、金融情绪分类、金融智能问答任务上进行了金融任务实验,验证了F-BERT的有效性和鲁棒性.实验结果表明F-BERT模型在这3个有代表性的金融文本挖掘任务均取得了最佳准确性,优于所有当前其他模型性能;另外,针对金融命名实体识别、金融短文本分类这2个实际金融科技任务也进行了实验验证,所提出的F-BERT模型均取得了最佳准确性.
4) 采取了一种混合精度训练方法,并在Horovod框架上进行F-BERT的分布式训练,既使得整个训练过程具有稳定加速比,同时拥有较好的可扩展性.
5) 在Github上进行了F-BERT的开源,包括其模型架构、源代码、超参数、训练模型,以及用于微调的源代码.通过该开源代码,F-BERT可用于各种其他下游金融文本挖掘任务,对特定金融文本分析任务进行最少的修改即可帮助实现最新的性能.
1 相关工作
1.1 预训练模型
预训练模型最早应用于机器图像和计算机视频领域.在2012年的大规模图像识别竞赛ImageNet[6]中,当时取得第一名成绩的AlexNet[7]横空出世,它采取了基于CNN[8]的卷积神经网络模型架构.此后,AlexNet被广泛应用在众多的机器视觉任务中.虽然很多新模型并不是完全借鉴AlexNet模型架构从头开始训练,而是主要利用在ImageNet上训练得到的AlexNet模型的参数和神经网络架构,再进一步结合实际任务进行少量修改,然后在新的数据上训练和优化.实验结果表明,复用预训练模型可以显著增加目标任务的准确度,也大大缩短了新模型的训练时间.
预训练模型的一大优势是,可以利用在其他相似任务的大量数据上建立有效的模型再迁移到目标任务,从而解决了目标任务(例如股票涨跌预测)训练数据不足的问题.另外,从垂直领域文档(例如金融文本数据等)中提取有价值的信息正在变得越来越重要,深度学习促进了有效的垂直领域文本挖掘的研究发展.
1.2 预训练语言模型BERT
Google在2018年下半年发布了预训练语言模型BERT[3],在自然语言处理界具有开创时代的意义.接下来,BERT模型在十多个自然语言理解任务中全部取得了最佳模型准确率,在多个公开自然语言处理竞赛上取得大幅提升,甚至在常识推理、自动问答、情绪分析、关系抽取、命名实体识别等竞赛均取得了超过了人类准确率的成绩.同时,在BERT模型的源码发布之后,后续研究人员基于开源代码和预训练模型进行了各种自然语言处理任务,进一步大幅提升了各个NLP任务模型的成绩.例如,在SQuAD[9-12]竞赛排行榜上排名前20名的模型均选择使用BERT模型,且最好成绩超过人类水平;在CoQA[13-15]竞赛排行榜上,排名前12名的模型也全部基于BERT模型,排名第一的模型也同样取得了超过人类水平的成绩.
BERT本质上也是一种多层Transformer[16]结构.它的输入是一段文本中每个单词的词向量(分词由Word Piece生成),输出是每个单词的BERT编码.单词的BERT编码表示一般包含了该单词及其上下文的信息.BERT模型采用了2个预训练任务:双向语言模型和判断下一段文本.这2个任务均属于无监督学习,即只需要文本语料库,不需要任何人工标注数据.
1) 掩码机制
BERT提出了掩码机制.BERT在一段文本中随机挑选15%的单词,以掩码符号[MASK]代替.然后,利用多层Transformer机制预测这些位置的单词.由于输入中没有被掩去的单词的任何信息,这些位置上的Transformer输出可以用来预测对应的单词.因此BERT是一个双向语言模型.但是,由于原文本中并不包含掩码[MASK],从而使得预训练任务与真正目标任务会出现不一致的情况.为了更好地缓解这个问题,BERT采取了在选取被掩单词后以80%的概率替换成[MASK],同时以10%的概率替换成一个随机单词,以10%的概率保持原单词的方法.最终实验也证明该方法可以有效地提升目标任务的准确性.
2) 判断下一段文本机制
BERT的第2个预训练任务是二分类问题:给定2段文本A,B,判断B是否是原文中A的下一段文本.为了尽可能多地考虑上下文,文本A和B的长度总和最大为512个词.训练中,50%的正例来自原文中紧挨着的2段文本,50%的负例来自2段无关联的文本.由于Transformer结构只接收一段文本输入,BERT将A和B拼接起来,并加上起始符号[CLS]和分隔符[SEP].为了使模型区分文本A和B,还加入了段编码,即给文本A和文本B中的单词分配不同的编码.设起始符[CLS]位置的BERT编码为CLS,则模型预测文本B是文本A的下一段文本的概率.判断下一段文本的预训练任务属于分类问题,提高了预训练阶段与微调阶段任务的契合度.这也是BERT取得比其他预训练语言模型更优秀结果的原因之一.
3) BERT预训练
BERT的预训练数据来自公开语料库Books Corpus(共8亿个词)和英文维基百科(共25亿个词)[3].BERT公开的预训练模型有BASE与LARGE两种.
① BERTBASE:12层Transformer,输入和输出维度为768,注意力含12个Head,共1.1亿个参数.
② BERTLARGE:24层Transformer,输入和输出维度为1 024,注意力含24个Head,共3.4亿个参数.
其中,2个模型均训练了40轮.BERTBASE在4个Cloud TPU上训练,BERTLARGE在16个Cloud TPU上训练,均花费了4天左右的时间.特别地,相比于GPU来说,针对深度学习训练TPU能够进行更好的硬件和算法的优化.在4个GPU上训练BERTLARGE需要花费初略计算约100天时间.因此,BERT语言模型被提出时是当时耗费计算资源最多且模型规模最大的自然语言预训练模型.
2 F-BERT模型
如图1所示,我们利用深度学习领域的自监督学习和多任务学习技术,创新地提出了基于BERT模型架构的垂直领域预训练语言模型:金融预训练语言模型,我们将其命名为F-BERT模型.F-BERT是同样采取预训练(pre-training)加微调(fine-tuning)的两阶段架构.其中,在模型预训练阶段,F-BERT与传统的BERT预训练不同之处在于,与其使用少量的预训练目标进行训练,不如考虑同时引入多种预训练任务来尝试更好地帮助模型进行有效地学习训练.因为除了语言共现信息之外,在训练语料中实际上还涉及到多方面的语言知识,例如词法、句法以及更高层次的语义和语用等知识.同时,也还包括金融实体等词语概念的知识、文本语义相似度等语义知识.最重要的是,F-BERT会通过多任务学习来不断地更新预训练模型.并且,与现有的预训练模型相比,F-BERT同时在通用语料库和金融领域语料库上进行训练.在微调阶段,首先使用预训练的参数初始化F-BERT,然后使用特定于任务的监督数据进行微调训练.
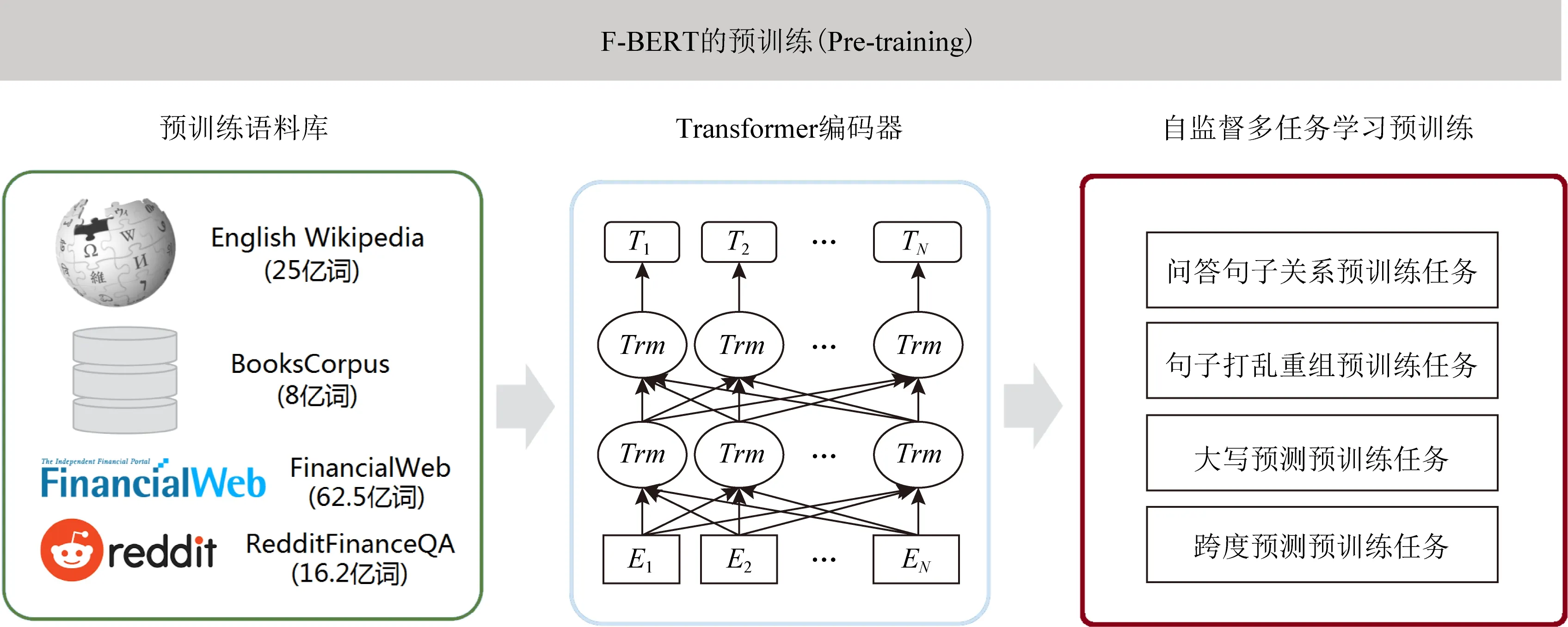
Fig. 1 An illustration of the architecture for F-BERT图1 F-BERT模型的预训练架构
本节将对F-BERT模型架构进行详细描述.
2.1 编码器
在预训练的阶段,我们使用Transformer编码器,采取和BERT类似的编码方法,即位置编码(position embedding)、段编码(segment embdding)和令牌编码(token embedding),但除此之外我们额外设计了一个任务编码(task embedding).针对不同的预训练任务,我们使用任务编码来精细化地建模不同类型的任务.对于N个任务,任务的ID范围就是1~N,每个任务ID都会被映射到不同的编码上,最终输入编码的输入为:输入编码=位置编码+段编码+令牌编码+任务编码.具体如图2所示.
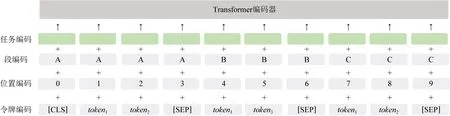
Fig. 2 Transformer encoder layer图2 Transformer编码层
接下来,针对输入编码计算注意力,我们使用Transformer的多头自注意力机制进行计算.它主要由查询Query(使用Q来代替),键Key(使用K来代替)和值Value(使用V来代替)作为输入,然后使用线性变换对Q,K,V进行投影,并且可以同步计算多次,即使用多头h来表示h个不同的线性变化.最后再将全部的注意力值结果进行拼接,从而完成一次多头注意力计算.对于单个Q,注意力功能的输出是V的加权组合.为了简化计算,在这里我们将自注意力取相同的Q,K,V值,并且注意力计算使用是缩放点积.具体注意力函数为
其中,d表示Q,K,V向量维度.
2.2 自监督多任务学习预训练任务
目前预训练阶段主要是利用句子或词的共现信号设计不同任务进行语言模型的预训练.例如,原始BERT模型构建了2个预训练(遮蔽语言模型任务和下一句预测任务);XLNet[9]模型利用全排列的语言模型进行自回归方式的预训练.相比较之下,我们在F-BERT模型中堆叠了大量的预训练目标.就好像人类进行外语考试,在卷子上面有多种不同的题型,如果可以进行综合训练,那么对整体学习提升一定有很大帮助.具体来说,在预训练阶段,F-BERT构造了4个自监督学习的预训练任务,并通过多任务学习方式从训练文本语料中学习不同层面的知识.如图1所示,这4个自监督的预训练任务分别为:跨度替换预测预训练任务、大写预测预训练任务、句子打乱重组预训练任务,以及问答句子关系预训练任务.
1) 跨度替换预测预训练
我们采取了一种分词级别的预训练任务,实现跨度替换预测预训练.BERT模型的输入主要是以字为单位进行切分,这样就不能够更好地考虑到共现单词和共现词组间的关系,进一步导致不能充分学习其所包括对隐含先验知识.针对金融领域文本语料该问题就会更进一步被放大,从而降低模型的学习效果.通过借鉴Mandar等人提出的SpanBERT[17]思想,我们对谷歌原生的BERT模型进行了2方面改进:①不再对单个随机词定义掩码,而是定义了一种更好的跨度掩码方案,即采取随机对一定窗口范围的邻接词来设计掩码;②不再对分词内单个词的表示过多依赖,而是定义一种分词边界表示来预测被添加掩码的分词内容,从而实现跨度替换预测的训练目标,最终我们可以更充分地学习到领域性更强的金融领域文本知识,提升F-BERT模型性能.
关于跨度替换预测预训练任务,具体来说,首先,我们迭代地采样文本序列,即针对每一个单词序列X=(x1,x2,…,xn),通过定义一个掩码比例阈值(例如整个序列的20%)来构造一个序列子集Y.在F-BERT训练任务中,我们采取基于几何分布来随机选择一定长度的文本.由于几何分布(geometric distribution)是一种离散型概率分布,在它的第m次伯努利试验中,试验k次才得到第1次成功的机率,因此我们能够均匀地(随机地)得到分词起点并可以得到一个较短的序列.为了获得更佳的采样长度分布,F-BERT模型中的几何概率分布超参数P=0.18,最大长度上限T=16(超出部分按照丢弃处理),通过实验我们得到的最佳平均序列长度是4.6.接下来,我们具体实现了该实现跨度替换预测预训练任务.在F-BERT训练过程中,我们将跨度定义为取跨度前后边界的4个词,如果这些词没有在跨度范围内,就使用这4个词的向量再加上跨度中被遮盖掉词的向量来预测原来的单词.具体实现就是使用一个2层的前馈神经网络,并使用层正则化,其中的激活函数我们使用ReLU,从而将编码向量和位置向量拼接起来:
h=LayerNorm(ReLU(W1X)),
f=LayerNorm(ReLU(W2h)).
我们同样使用交叉熵作为损失函数,就是跨度替换预测预训练目标的损失来用于模型训练.
为了更直观地理解跨度替换预测训练,图3中给出一个具体例子,其中使用了跨度替换预测预训练任务.假设输入序列为“股价预测很困难”,以“很”字为例,我们首先随机掩盖一个连续的跨度(图中的x4到x6),针对待预测字的位置信息和基于该跨度前后S个字的表示(这里S=2)来进行最终预测,这个过程就是跨度替换预测训练任务,同理,最终的“测”和“困”也使用同样的跨度替换方法来进行预测.在跨度替换预测过程中,对每个文本序列相当于进行多次验码,因此任意字都会成为跨度替换预测连续内容,这样就实现了各个字的表示均会包含周围跨度的信息,从而将跨度前后字的知识体现到跨度中的字的语义信息中.针对抽取类任务中(例如金融文本边界检测,跨度和起止位置的知识对模型而已非常重要),我们通过对预训练语料的不断训练,最终就可以使得F-BERT模型在这样的抽取类任务中取得很好的效果.

Fig.3 An example of span boundary prediction task图3 跨度替换预测预训练示例
2) 大写预测预训练任务
大写预测预训练任务主要是由F-BERT模型预测一个字母是不是大写.这个对特定的任务例如命名实体识别比较有用,与句子中的其他单词相比,大写单词通常具有某些特定的语义价值,尤其对于金融文本处理,其中包含很多专业命名实体,因此该任务可以发挥很大作用.同时,针对中文的训练语料,我们还额外定义了一个预测某个词组是不是专有短语的缩写训练任务,这个针对中文的金融文本处理作用较大.
3) 句子打乱重组预训练任务
句子打乱重组预训练任务主要是进行顺序还原,就是将输入文本序列随机打乱,然后通过该任务将其还原回来.受到ALBERT和T5[18]预训练任务的启发,我们提出一种更优的重组任务.具体来说,首先把一篇文章随机分为n=1到k份,对于每种分法都有n!种组合,然后我们再让模型去预测这篇文章是第几种,本质相当于构造了一个多分类的问题,通过该任务就能够让模型学到句子之间的顺序关系.
4) 问答句子关系预训练任务
问答句子关系预训练任务主要是判断2个句子是否属于问答对.问答或者对话的数据对语义表示很重要,因为对于相同回答的提问一般都是具有类似语义的,通过修改段嵌入,使之能够适用多轮问答或多轮对话的形式.具体:定义3个句子的组合[CLS]Sentence1[CLS]Sentence2[SEP]Sentence3[SEP]的格式,这种组合可以表示多轮问答和多轮对话,例如QRQ,QRR.在这里,Q表示“问题”文本,R表示“答案”文本.
3 实验分析
本节我们首先给出预训练数据集的构建;然后在多个金融任务上将F-BERT与最新的预训练模型进行了性能比较;最后进行了详细的模型分析,包括预训练对模型性能的影响、少量预训练数据进行预训练分析和预训练语料库的大小的讨论等.
3.1 预训练数据集
为了更好地训练F-BERT模型,我们主要构建了基于通用领域和金融领域2部分的训练语料.其中,通用领域训练数据集与BERT模型训练相似,使用来自Wikipedia和Book Corpus的英语语料库.为了将F-BERT模型更好地应用于金融文本,我们还构建了金融领域训练数据集,通过在金融网站上爬取各种金融文本数据,包括金融新闻和对话等.如表1所示,我们具体构建了4个大小不同、领域不同的英语语料库,总计超过40 GB大小的文本(约108.4亿个词):
1) 通用英语训练语料库Book Corpus和英语Wikipedia.即用于训练BERT的原始数据,共计13 GB(约33.1亿词)文本.
2) Financial Web金融文本数据集(共23 GB,约62.5亿词).主要是从Common Crawl News数据集中进行收集的,其中包含2012-01至2019-12期间的1 300万条财经新闻以及爬取自FINWEB网站的金融文章.
3) Reddit Finance QA金融问答文本数据集(共4 GB,约12.8亿词).主要从Reddit网站上收集有关金融问题然后构建一个问答训练语料.
表1中报告了F-BERT全部预训练数据的统计信息.我们已经建立并维护了一个开放的金融文本语料库并进行了开源处理,任何人都可以访问和利用该资料库资源.

Table 1 List of Pre-training Corpora Used for F-BERT
3.2 分布式预训练
F-BERT的预训练过程对整个计算力有着非常大的要求,我们主要采取基于AI Framework On YARN分布式框架来进行F-BERT预训练.该训练框架是使用Horovod[19]的分布式训练方案,整个架构基于YARN实现的16张NVidia Tesla v100 GPU卡进行训练,框架在调度上非常灵活,同时还具有调度作业高伸缩性和高容错力.Horovod是由Uber发布的开源深度学习工具,它是一个分布式深度学习框架.Horovod库为分布式训练提供了帮助,可以使分布式深度学习更易于使用且训练更高效,该库集成了百度Ring Allreduce和Facebook的一小时训练ImageNet论文的优点.Uber官方发布的Horovod包括TensorFlow和Horovod两种分布式方案,根据其架构特点,GPU的数量越多,Horovod性能损失越小,要优于分布式TensorFlow,甚至训练速度可以达到TensorFlow的2倍;同时,即使GPU卡数量达到几十张,仍可以保证稳定的加速比.我们使用混合精度的训练方式来训练F-BERT模型,以便可以更好地提高预训练效率.
目前的神经网络模型,它们的训练过程基本都使用双精度或单精度的数据类型.但由于显存大小的限制,如果神经网络模型很深且比较复杂时通常会使得处理的batch较小.如果调整batch的大小,会降低数据的处理效率,训练速度会受到影响,并且一旦batch很小的话,也会造成模型训练不稳定并影响模型整体性能.2018年,百度在ICLR提出了一种单精度和双精度的混合精度训练,该方法可以减少显存消耗并加速训练,通过在语言模型任务、语言识别任务和图像检测任务上进行了有效性验证,均表现非常高效.通常而言,Nvidia的Pascal系列显卡或新一代GPU架构Volta系列在单精度和底精度计算方面都有非常好的支持,例如,NVIDIA Tesla P40硬件支持INT8计算加速,NVIDIA Tesla V10支持FP16计算加速,同时,就计算峰值而言,相比单精度浮点,低精度浮点计算的峰值要高得多.因此,本节提出的F-BERT,在实验中采用了混合精度训练方式.具体而言,F-BERT采用的是FP16和FP32的混合精度训练.其中,模型的计算过程使用FP16精度进行加速,而权重参数会以FP32数据格式进行存储、FP32格式进行参数更新,从而使得模型兼具了FP16的速度和FP32的稳定性.因此,F-BERT的训练过程既减少了缓存的开销也加速了训练,同时因为FP16的速度优势,使得F-BERT的整体预训练和推理都有了一定提升.另外,由于神经网络的训练梯度一般会超过FP16的范围,为了控制梯度使其在反向传播过程中在其表示范围内,在训练过程中,我们针对F-BERT特别使用了Loss Scaling策略控制来对损失的控制,对其梯度进行了放大的处理.
3.3 微调任务
微调(fine-tuning)是机器学习和深度学习中常用的一种调参方法.在实际中,考虑到数据不足够大,通常很少且很难从头开始重新进行神经网络模型的训练.通常采取的办法是探索如何利用已有的神经网络,然后在其基础上结合具体任务特点进行进一步训练处理.通常,预训练语言模型BERT包括2个连续的步骤:一个是预训练阶段(pre-training),另外一个是微调阶段(fine-tuning).它首先在预训练阶段对大型语料库进行无监督预训练,接下来在微调阶段再对下游的自然语言处理任务进行有监督微调.与BERT相似,从头开始在这些大型无监督语料上训练F-BERT模型,并将其微调/应用于各种下游有监督的金融文本处理任务.在这里,我们分别在金融关系提取、金融情绪分类、金融智能问答任务这3个有代表性的金融文本挖掘任务上进行了微调处理.
1) 金融文本边界检测
金融文本关系抽取常被称作金融文本边界检测,它是金融文本挖掘的基本任务.由于句子是自然语言的基本单位,检测句子的开头和结尾,或者句子边界检测是许多自然语言处理任务(例如词性标记、信息提取等)非常基础的一步.在金融领域,招股说明书等文献中包含了投资方式等投资基金详细信息,金融句子边界检测任务,就是指如何将嘈杂的非结构化文本转换为半结构化文本,从而实现通过检测招股说明书的开始和结束边界来提取句子的细分.2019年,IJCAI19会议发布了FinNLP金融检测挑战赛数据集FinSBD Shared Task[20-22].本节使用FinSBD Shared Task数据集作为金融句子边界检测任务的有监督微调数据.FinSBD-2019数据集包含已自动分段的金融文本,它的训练集和开发集中有953个不同的开始标记和207个不同的结束标记.
2) 金融情绪分析
金融情绪分析是金融科技中一项基本任务,也是金融文本分析最基本的任务之一.金融情绪分析主要是指根据给定金融文本数据,检测文本的目标情绪得分.本节使用2个金融情绪分析数据,分别是Financial PhraseBank和金融情绪分析挑战数据集(FiQA Task1)[23].Financial PhraseBank数据集包含了4 845个英语单词,这些文本是从LexisNexis数据库中发现的财经新闻中随机挑选的,然后由具有金融和商业背景的16个专家进行了标注处理.金融情绪分析挑战数据集(FiQA Task1)包括2种类型:金融新闻标题和金融微博,分别带有人工标注的目标实体和情感得分.其中,金融新闻标题数据集总共包含529个带标注的标题样本(训练集为436个样本,测试集为93个样本),而金融微博包含总共774个带标注的帖子样本(训练集为675个样本,测试集为99个样本).
3) 金融智能问答
金融智能问答是金融科技的一项具有挑战的任务,其目的是自动提供与给定短文本或文章相关的问题的答案.2018年,WWW18会议发布了2个金融文本处理数据集[23-24],分别是金融情绪分析挑战数据集(FiQA Task1)、金融金融智能问答挑战数据集(FiQA Task2).这里使用FiQA Task2的数据集作为金融金融智能问答任务的有监督微调数据.FiQA Task2数据集是通过抓取Stack Exchange网站在2009—2017年间所有涉及“投资”主题的帖子内容人工构建而成的.例如,类似这样的问题“Why are big companies like Google or Apple not included in the Dow Jones Industrial Average (DJIA) index?”.最终FiQA Task2数据集包含了57 640个答案集,其中包含了17 110个“问题-答案”用于训练集和531个“问题-答案”用于测试集.
3.4 实验结果
1) 金融文本边界检测任务
在IJCAI19金融检测挑战赛数据集FinSBD Shared Task测试集上提交方法以进行评估,详细内容参见表2.在表2中我们可以看到,针对测试集上的准确率,所提出的F-BERTLARGE和F-BERTBASE优于模型发布时的其他方法,尤其取得最佳结果的F-BERTLARGE模型获得了0.93的ES(end of sentence)得分,0.95的BS(beginning of sentence)得分和0.938的MEAN(平均值)分数,均为评估指标的最佳成绩.正如实验结果所看到,对通用领域语料库和金融领域语料库进行预训练的F-BERT是非常有效的,在金融句子边界检测任务上获得了显著的模型性能提升.
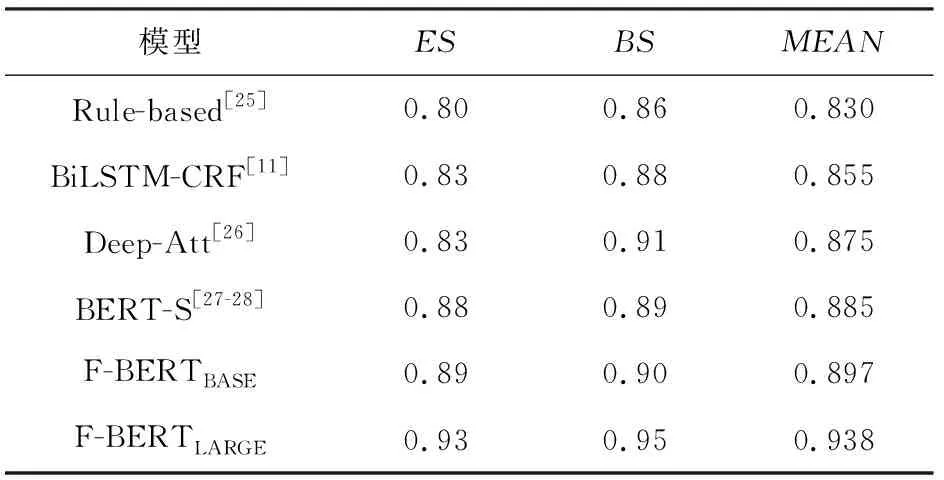
Table 2 Experimental Results on Test Set for the FinSBD Dataset
2) 金融情绪分析任务
从表3~4我们可以看到F-BERT模型和其他有竞争力的方法在Financial PhraseBank和金融情感分析数据集(FiQA Task1)上的性能.
如表3~4所示,F-BERT模型(包括F-BERTLARGE和F-BERTBASE)的模型准确率优于基线模型分别在PhraseBank情感分析数据集和FiQA Task1情感分析数据集上取得的成果.其中,在Financial PhraseBank[29]上,最优模型F-BERTLARGE获得了0.90的准确率和0.89的F1值.
情感分析数据集FiQA Task1主要包括2种类型的数据:金融新闻头条和金融微博.FiQA Task1具体有2个评估指标[27]:均方误差(MSE)和R方(R2).在表4中,MSE(H)和MSE(P)分别表示金融微博的均方误差和金融新闻头条的均方误差,同样R2(H)和R2(P)分别表示为金融微博和金融新闻头条的R方值.通过表4可以清晰看到,在FiQA Task1上,最优模型F-BERTLARGE获得了MSE(H)=0.30和R2(H)=064的值,以及MSE(P)=0.34和R2(P)=0.27的值.
表3~4的实验结果表明在Financial PhraseBank和FiQA Task1上,F-BERT的表现均明显优于提交时的所有其他方法,这证明了方法的有效性.考虑到使用众多语言功能的最新模型的复杂性,目前的实验结果令人鼓舞,这些结果突出了特定于金融领域的语料库预训练设计的重要性.

Table 3 Experimental Results on Test Set for the PhraseBank Financial Sentiment Analysis Dataset
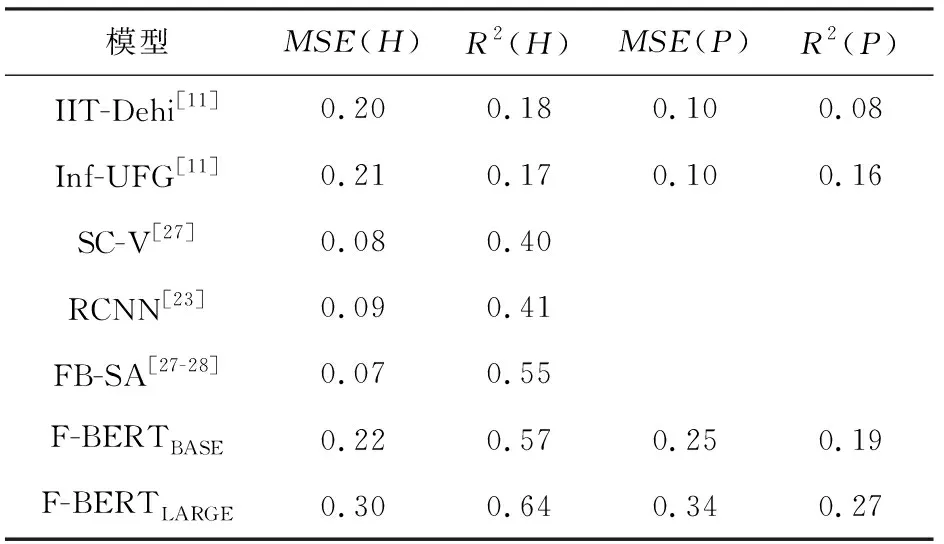
Table 4 Experimental Results on Test Set for the FiQA Task1 Financial Sentiment Analysis Dataset
3) 金融智能问答任务
表5展示了金融文本智能问答挑战数据赛(FiQA Task2)上方法和其他基准模型的性能对比.为了更好地进行金融智能问答模型的性能比较,FiQA Task2数据集主要定义了2个评估指标[27]:归一化贴现累积收益(nDCG)和平均倒数排名(MRR).从表5可以看到,我们的最佳模型F-BERTLARGE在测试集上可达到nDCG=0.60和MRR=0.52,同时F-BERTBASE达到了nDCG=0.51和MRR=0.41,其准确率也高于其他的基准模型.由于金融智能问答的数据一般都很小(只有几十或者上百个训练样本),由此可见,模型预训练模型在金融智能问答任务中可以起到非常重要的作用.

Table 5 Experimental Results on Test Set for the FiQA Task2 Question Answering Dataset
3.5 实验分析与讨论
为了详细分析架构内各组件对最终性能的影响,在本节中对架构进行了详细的模型分析,包括预训练对模型性能的影响、少量预训练数据进行预训练分析和预训练语料库大小的讨论.
1) 预训练对模型性能的影响
如表6所示,进一步测量了预训练对模型性能的影响.详细比较了4个模型:没有进一步的预训练,由Vanilla BERT和Vanilla F-BERT表示;对训练集进行进一步的预训练,使用BERT-task和F-BERT-task表示.在测试数据集上使用准确率、精确率和召回率的得分对相应模型进行评估.从表6可以明显看出,F-BERT模型能带来可观的性能提升.尽管BERT任务在金融领域训练集上进行了进一步的预训练,但Vanilla F-BERT的性能优于2个基于Vanilla BERT的模型Vanilla BERT和BERT-task,在准确率上,比它们分别提高0.06和0.03.这表明F-BERT在预训练期间有效地利用了来自大量未标记金融文本的领域特定知识.

Table 6 Experimental Results on Test Set for the Financial Classification Dataset
2) 少量预训练数据预训练分析
预训练模型通常需要庞大的训练语料库来进行训练,但是,在金融领域的许多应用程序中,很难拥有大型的有标注训练语料库.因此,为进一步验证F-BERT的优势,本文进行了一个模型实验.实验使用小型语料库来分别对BERT和F-BERT进行预训练.具体地说,通过在整个金融训练数据集中随机选择1/8大小的文本数据作为训练语料库.然后,基于自己模拟构造的这个小语料库,对所有模型进行预训练,并和1)中实验的相同任务上进行测试,实验结果详见表7.

Table 7 The Performance of BERT and F-BERT on Three Financial Tasks When They Are Trained on a Small Corpus
从表7中的实验数据我们可以看到,与之前的实验相比,该实验呈现了相同的趋势,F-BERT模型在所有任务中始终胜过BERT.该实验结果进一步证实,当模型在不同大小的语料库上训练时,F-BERT可提供稳定的增强.如表7所示,这些实验数据也表明,F-BERT模型可以在具体金融文本处理任务上提供更多帮助,例如金融机器阅读理解任务、金融情感分析任务和金融句子边界检测任务.总体而言,该实验模拟了在数据有限的情况下对金融文本进行预训练的情况,这是特定领域经常遇到的问题,因此证明了F-BERT有潜力处理特定领域的小训练数据集问题.
3) 预训练语料库的大小及训练时长变化分析
为了进一步评估针对不同大小的数据集F-BERT模型的表现,我们针对预训练语料库的规模大小进行了消融实验.通过在3个具体下游金融任务上的性能改进变化,进一步验证了在预训练阶段数据大小和多样性的重要性.表8详细地展示了不同大小的数据集上F-BERT模型的性能变化.通过该实验我们还观察到,随着训练时间的提升F-BERT并没有过分拟合数据,模型同样会从进一步训练中获益.
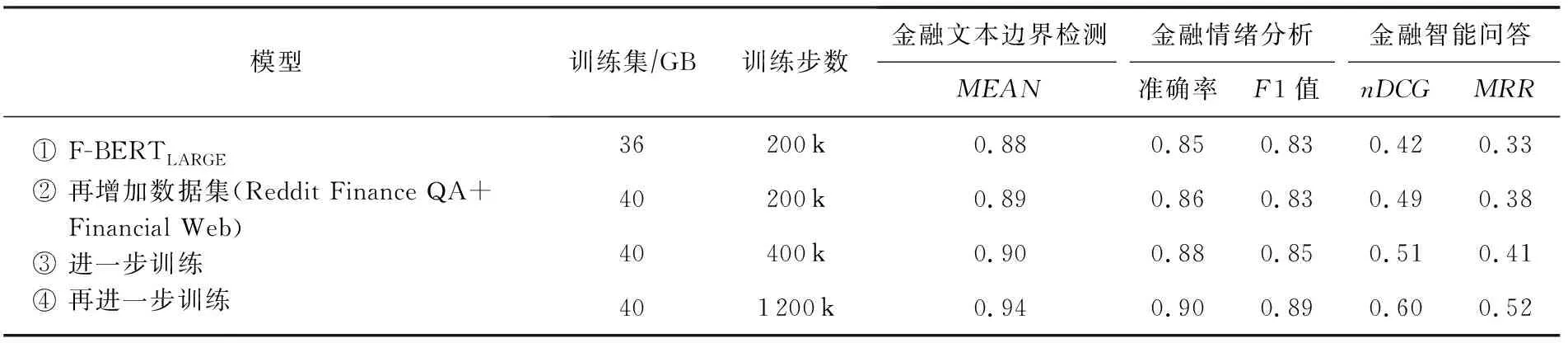
Table 8 The Performance of F-BERT on Different Traing Size and Steps of the Corpus
3.6 真实业务数据的实验
我们利用真实线上业务数据对所提出的F-BERT模型有效性进行了进一步验证.具体来说,我们从金融科技实际业务中抽象并人工构建了2个典型的金融领域数据集:包括金融命名实体识别任务数据集和金融短文本分类任务数据集,然后分别针对金融命名实体识别和金融短文本分类这2个实际金融任务进行了实验.
1) 金融命名实体识别
金融命名实体识别,是一种非常常见的金融业务,此任务主要是对给定的金融文本,利用训练模型可以自动完成有特定意义的金融实体的识别,包括识别出金融机构名、人名(例如高管、人名),以及其他专有实体名词等.该任务也是关系抽取和实体提取的基础任务,也多用于金融大数据和金融知识图谱相关任务中,是金融数据分析的一项非常基础的任务.在这里,我们对实际业务数据进行了简化和脱敏处理,从真实数据中人工整理出一个金融命名实体识别数据集.该数据集共包含53 000条训练样本,测试数据集45 000条,训练数据样本8 000条.
2) 金融短文本分类
金融短文本分类是一种非常常见的金融业务,此任务主要是帮助判断该金融短文本属于哪一类别,从而完成金融文本内容对自动类别分类,最终对于不同的金融业务场景可以有不同的业务处理方案.在这里,我们对针对实际金融短文本分类进行了精简处理,基于真实的业务数据,我们构造了一个包含6 600条样本、6个类别的金融短文本分类数据集.该数据集的训练集和测试集分别有2 000条和2 850条.
3) 实验结果
基于构建的金融命名实体识别数据集、金融短文本分类数据集,我们将提出的F-BERT模型分别与BERT模型和RoBERTa-wwm-ext[6]模型、BERT-wwm[26]模型进行金融文本挖掘任务的实验比较.表9和表10给出了最终的实验对比结果.实验过程中,我们针对这3个基准模型(BERT,RoBERTa-wwm-ext,BERT-wwm)和F-BERT均设置成相同的学习率等超参数,最终在F1值上平均可以提升3~4个百分点的准确率.通过对真实业务数据的对比实验,包括金融命名实体识别任务、金融类短文本类型分类任务的基线测试,我们可以清楚看到,F-BERT模型在相比于BERT等其他基线模型在金融文本发掘任务上有比较明显的提升.

Table 9 Experimental Results on Named Entity Recognition Task

Table 10 Experimental Results on SMS Text Classification Task
4 总 结
在本文中,我们利用深度学习领域的自监督学习和多任务学习技术,创新地提出了一种基于BERT模型架构的大规模语料上训练的开源金融预训练模型F-BERT.虽然BERT是为理解通用语言而构建的,但F-BERT通过多任务自监督学习进行同时预训练,有效地捕获了大规模预训练语料中的金融领域知识和语义信息.我们通过最小限度地修改特定于具体金融任务的模型结构,F-BERT在多个金融文本数据挖掘任务(包括金融关系提取任务、金融情绪分类任务、金融智能问答任务)上的性能均优于当前的最新模型.同时,我们还从金融科技线上业务中构建了2类有代表性的金融大数据挖掘任务,即:金融命名实体识别、金融短文本分类,在这2个实际金融科技任务进行了实验,F-BERT模型同样取得了最佳准确性.
将来的工作中,我们将进一步扩展F-BERT模型以进行消费者情绪分析和个性化理财智能投顾问题的研究.
