基于孪生BERT网络的科技文献类目映射
2021-08-17何贤敏李茂西何彦青
何贤敏 李茂西 何彦青
1(江西师范大学计算机信息工程学院 南昌 330022) 2(中国科学技术信息研究所 北京 100038)
分类法是一种具有层级结构的分类体系,根据内容和属性不同进行组织.虽然不同分类法的层级结构和编制原则差异很大,但其编制的基本原理和目的是相同的,都是为了提高检索效率而编制的一系列表达概念及概念关系的标识.因此,不同分类法在概念表达上存在一定的相似性,所以可以建立它们之间的映射关系[1].
专利信息作为一种特殊的科技文献,通常使用国际专利分类法(international patent classification, IPC)来对其进行组织和管理,为了标识专利所属的领域和范畴,每份专利文件会标明适当的IPC分类号.如表1第1行给出了IPC中“输入机构”有关的专利信息分类号及其类目文字描述,其中,符号“|”的个数表示分类法的类目层级数.而在中文学术期刊中,普遍使用中国图书馆分类法(Chinese library classification, CLC)来标识文献,如表1第2行给出了CLC中“输入设备”有关的期刊分类号及其类目文字描述.

Table 1 Examples of Identification of Patent and Journal Related to “Input Mechanisms (Devices)”
建立IPC与CLC之间的类目映射对实现专利信息与期刊文献相互关联以及它们组织体系间交叉浏览和检索有着重要的意义,因此,许多学者对此展开了研究.基于规则的方法[2-6]大都是对IPC和CLC类目描述文本分别提取关键词集或特征词集,用于替代原始类目的含义,通过计算词集之间的相似性间接得出类目之间的相似度,从而建立映射关系.基于传统机器学习的方法[7]将类目映射转化为分类问题,利用分类算法建立2部分类法之间的映射关系.但是它们都忽略了IPC和CLC类目描述文本的语义信息,导致映射的准确率不高.
针对这个问题,本文提出基于BERT预训练上下文语言模型的孪生网络将IPC类目描述文本和CLC类目描述文本完整地输入到映射模型中,获取IPC和CLC类目描述文本的句子向量,通过计算句子向量的余弦相似度,建立起2部分类法之间的类目映射关系.为了定量地验证所提模型的映射性能,人工标注了1 000条IPC类目和CLC类目之间的映射语料库,在该语料库上使用5折交叉验证,实验结果表明本文提出的基于BERT模型的孪生网络平均准确率可达94%,显著优于其他对比模型.概括来说,本文的贡献主要有3个方面:
1) 提出基于BERT预训练上下文语言模型的孪生网络对IPC和CLC进行类目映射,提高了IPC与CLC自动映射的准确率;
2) 构建了1000条高质量的IPC类目与CLC类目之间的映射语料库,该语料库覆盖了IPC的8大类别,能更准确地训练和测试模型的泛化能力;
3) 公开发布了相关代码、模型和人工标注的语料库(1)GitHub开源地址:https://github.com/i-wanna-to/IPC2CLC/,供其他研究人员免费使用.
1 相关工作
分类法之间的类目映射方法包括人工标注和自动映射,人工标注尽管准确率得到一定的保障,但人力成本高,主观性强,不利于构建2部分类法中大规模类目之间的映射关系.随着计算机技术的发展,自动映射方法取得了很大的进步,它们大致可以分为4种:基于同现的方法[3]、基于类目相似度的方法[4-5]、基于交叉检索的方法[6]和基于传统机器学习的方法[7].
当一批文献或图书可以同时利用2部分类法的分类号来进行标识,说明标识同一文献或图书的2个分类号之间具有一定的联系.基于同现的方法利用这种联系建立2部分类法之间的映射[3].基于类目相似度的方法将分类法的每条类目描述文本分解成一组具有代表性的词汇集,如类名词、注释词和上下位类名词等,通过计算词汇集间的相似度,间接得到类目的相似度[4-5].基于交叉检索的方法利用一种分类法在一个已被另一种分类法标识的文档集中进行检索,通过对检索结果进行分析,进而构建2个分类法之间的映射[6].基于传统机器学习的方法从2种分类法的类目描述文本中挑选出特征关键词集,将一个分类法的特征关键词集作为模型的训练集,训练得到一个分类器,用该分类器对另一个分类法的特征关键词集进行分类,将预测为同一类的类目作为映射目标,从而实现分类法的映射[7].
有学者将人工标注和自动映射相结合进行类目映射.陈瑞等人[8]提出将众包的思想应用在分类法类目映射上,众包用户把自动映射结果作为类目之间的初步映射,在其基础上进行人工重新标注.该方法的映射效率和准确率随众包用户标注差异而不同,映射可控性较差.
近年来,随着深度学习的发展,许多神经网络模型,如TextCNN[9],LSTM[10]和Transformer[11]等被成功地应用于文本序列建模任务中.同时,蕴含丰富句法、语义信息的预训练上下文语言模型,如ELMo[12],BERT[13],GPT[14]等在自然语言处理领域引起了越来越多的关注,刷新了多个语言理解任务的最优性能.它们在海量单语文本上预训练,获得通用的语言模识(modeledge)[15],然后被应用到下游任务中并根据任务的特点进行微调.这种预训练加微调的方式不仅极大地提升了下游任务的性能,而且大幅度降低了下游任务所需标注语料的规模.因此本文提出基于BERT预训练上下文语言模型的孪生网络以构建IPC和CLC的类目映射模型,结合BERT模型和孪生网络两者的优势,提升映射的准确率.
2 背景知识
2.1 BERT预训练上下文语言模型
BERT[13]是一种深度双向编码表征的预训练上下文语言模型.它的网络架构基于Transformer编码器结构,将原始Transformer编码器层数加深,并在“遮挡语言模型”和“下一句预测”2个训练任务上同时训练网络的参数,得到一个表达能力很强的预训练上下文语言模型.
BERT预训练上下文语言模型的网络架构如图1所示,其结构主要分为3层,分别为词向量编码层、多头自注意力机制(multi-head self-attention)和位置全连接前馈网络(position-wise feed-forward networks),图1中简化了位于多头自注意力机制和位置全连接前馈网络之后的归一化层,左侧的符号N表示Transformer编码器层堆叠的个数.
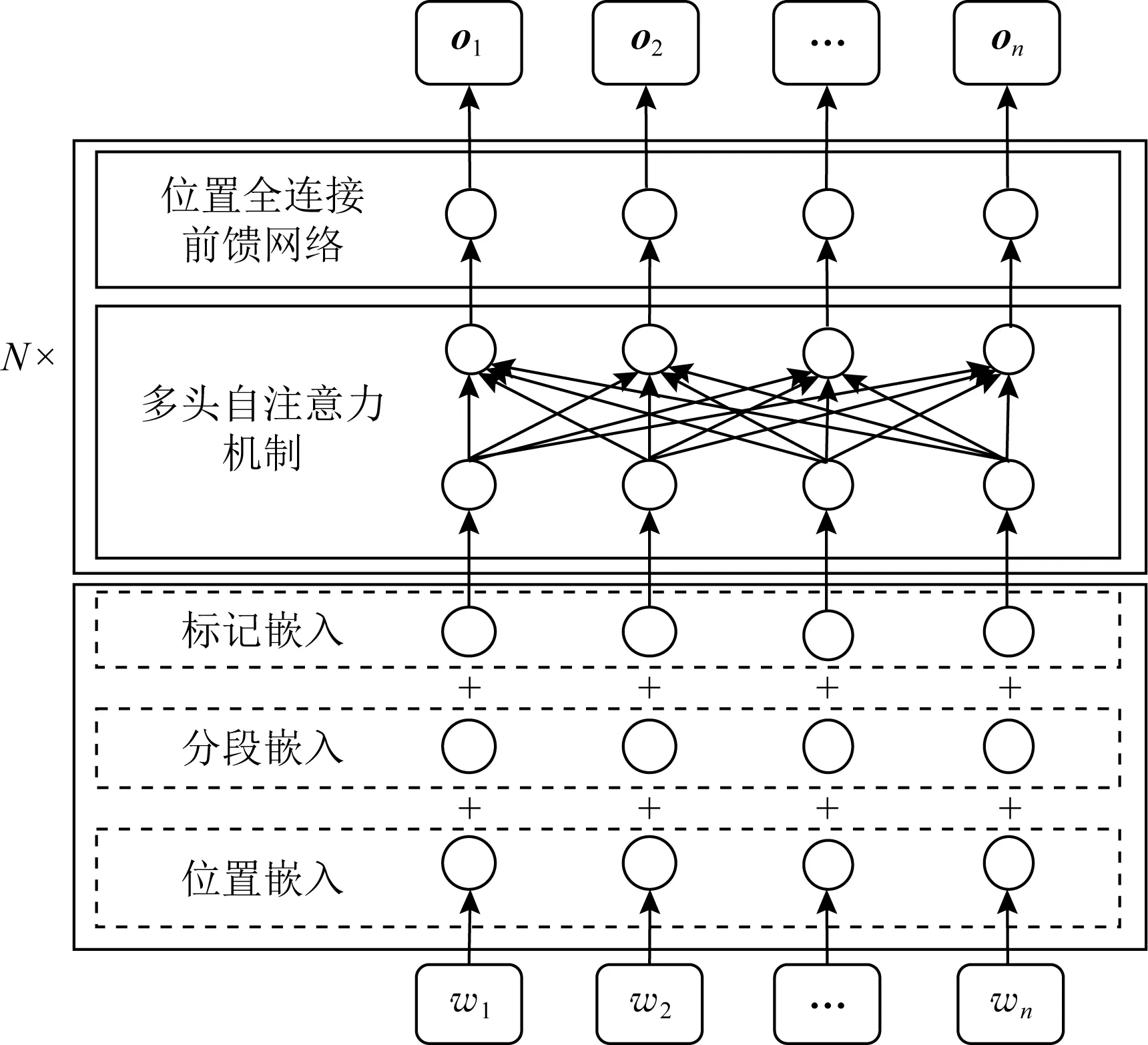
Fig. 1 The BERT model architecture图1 BERT模型架构
与Transformer编码器不同,BERT的词向量编码层由3个子层组成.其中位置嵌入(position embeddings)的参数由模型在训练过程中自动学习得到,而不同于Transformer编码器中通过规则进行设置;分段嵌入(segment embeddings)是为了区分输入序列中的不同句子而设置,如果将2条句子拼接输入BERT中,那么第1条句子的分段嵌入为0,第2条为1;标记嵌入(token embeddings)是将句子中的各个词(token)转化为特定维度的向量,这与Transformer编码器相同;最终这3层嵌入会逐元素相加,得到词向量编码层的输出.句子S={w1,w2,…,wn}的词向量编码层输出经过N个多头自注意力机制和位置全连接前馈网络的组合层,得到句子中每个词语的深层抽象表示O=(o1,o2,…,on).
2.2 孪生网络
孪生网络(siamese network)最早应用于数字图像的手写体识别,用于验证支票上的签名是否与银行预留的签名一致[16],由于其性能优异,随后在计算机视觉领域得到广泛应用,包括人脸识别[17]和目标跟踪[18].近年来,许多学者将孪生网络应用于自然语言处理任务中,Neculoiu等人[19]和Mueller等人[20]提出基于LSTM结构的孪生网络模型用于文本语义相似度计算;叶文豪等人[21]提出基于双向门控循环单元(gate recurrent unit, GRU)以及Transformer编码器的孪生网络模型,用于检测基金与受资助论文的相关性.
孪生网络的基本模型架构如图2所示,从图2可以看出,模型中左右相同的子网络共享参数权重,也由此得名“孪生网络”.输入的2个样本(X1,X2)通过这个相同的子网络分别得到其针对特定任务的深层抽象表示(R(X1),R(X2)),通过在抽象表示空间中计算2个样本的距离Dw〈R(X1),R(X2)〉 即可获取样本的相似度Sw.

Fig. 2 The siamese network model architecture图2 孪生网络模型架构
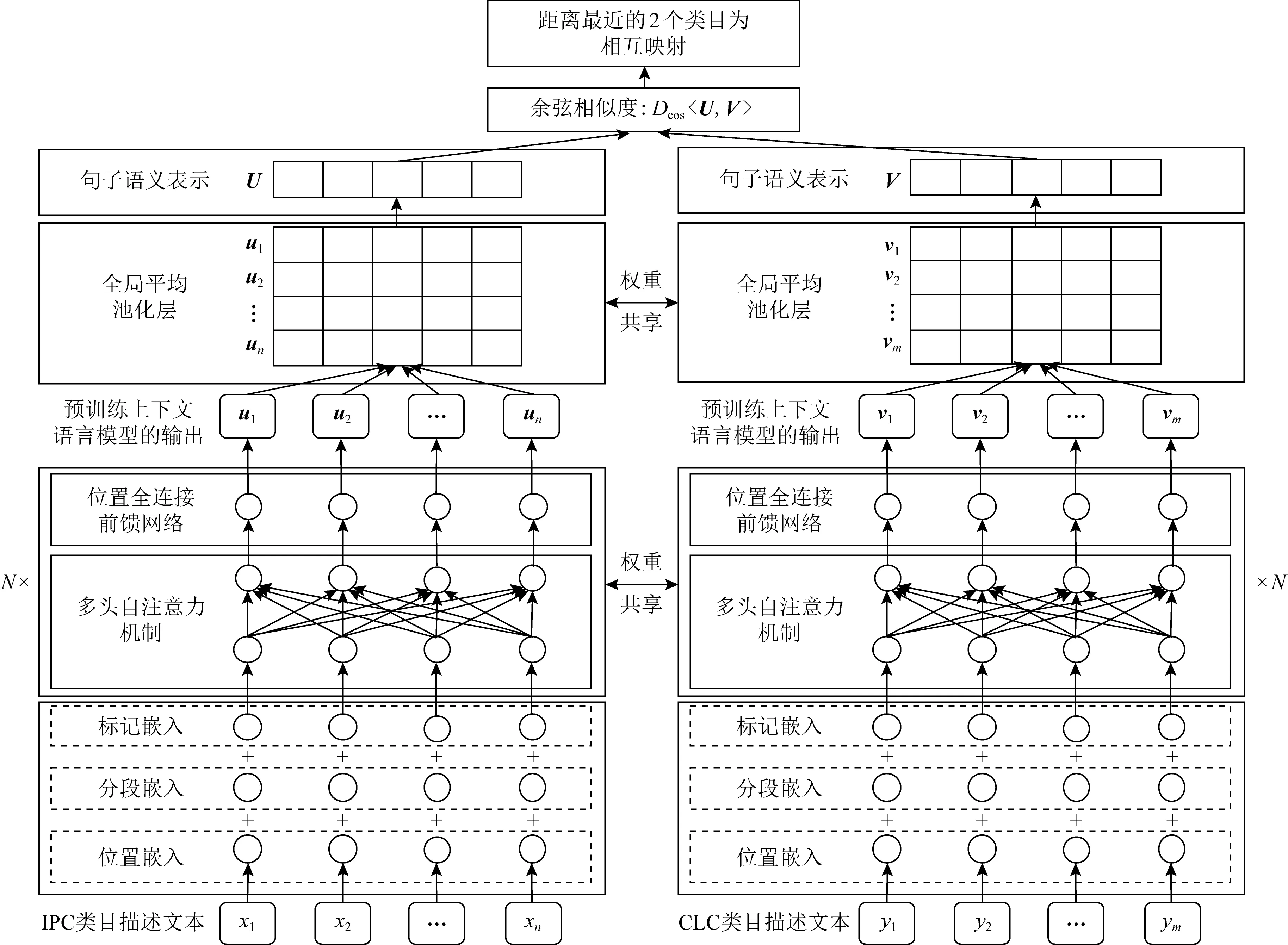
Fig. 3 Siamese network architecture based on BERT pre-training contextual language model图3 基于BERT预训练上下文语言模型的孪生网络架构
3 模 型
为了建立IPC类目和CLC类目之间的映射,我们提出利用基于BERT模型的孪生网络计算IPC类目描述文本和CLC类目描述文本之间的相似度,实现IPC分类号和CLC分类号的匹配.该方法的出发点是通过相同的BERT网络模型对IPC类目描述文本和CLC类目描述文本进行深层抽象,获取它们的通用语义表示,在语义表示空间中对IPC类目和CLC类目进行映射.这不仅可以利用BERT预训练模型实现语义映射,减少模型参数在训练中对有标签数据的需求;而且可以利用孪生网络有效刻画2个待匹配类目之间的差异,实现精准匹配.
3.1 基于BERT预训练上下文语言模型的孪生网络
基于BERT模型的孪生网络总体架构如图3所示,给定IPC类目描述文本X={x1,x2,…,xn}和CLC类目描述文本Y={y1,y2,…,ym},通过BERT预训练模型可得IPC类目描述文本的抽象表示Ou和CLC类目描述文本的抽象表示Ov:
Ou=(u1,u2,…,un)=
BERT({x1,x2,…,xn}),
(1)
Ov=(v1,v2,…,vm)=
BERT({y1,y2,…,ym}),
(2)
其中,Ou∈n×d,Ov∈m×d,符号n,m分别表示IPC和CLC类目描述文本的长度,ui和vj分别表示IPC类目描述文本中第i个词xi的抽象表示和CLC类目描述文本中第j个词yj的抽象表示,d代表句子语义表示向量的维度,设置d=768.
为了直观地说明IPC类目描述文本X和CLC类目描述文本Y的具体组成.例如当前IPC和CLC都为与“输入机构(设备)”有关的专利信息和期刊文献,那么X和Y分别为表1中IPC类目描述文本和CLC类目描述文本(不包含符号“|”,类目层级之间用单个分号连接形成一条句子),之后将X和Y分别利用开源工具包Transformers[22]的分词器Bert-Tokenizer进行分词,分词后输入到基于BERT模型的孪生网络中.
由于IPC类目描述文本和CLC类目描述文本经BERT模型后语义表示Ou,Ov均为词语级别,其长度不一定相同(m≠n),很难直接计算这2个不同维度张量的距离.为了进一步对类目描述文本的词语级别语义表示进行抽象,我们初步对2种池化策略进行实验:CLS池化和全局平均池化,最终选择了全局平均池化提取句子级别的语义表示U和V:
U=GlobalAveragePooling((u1,u2,…,un)),
(3)
V=GlobalAveragePooling((v1,v2,…,vm)),
(4)
其中,U∈1×d为IPC类目描述文本句子语义表示,V∈1×d为CLC类目描述文本句子语义表示,GlobalAveragePooling表示在序列长度维度上对输入向量进行全局平均池化.
利用余弦相似度计算U和V的距离:
(5)
其中,余弦相似度Dcos∈[-1,1].
在IPC和CLC映射阶段将U和V的余弦相似度作为IPC类目描述文本和CLC类目描述文本的相似度得分Sw,之后将距离最近的2个类目设为相互映射.需要说明的是由于欧氏距离的取值范围为[0,+∞),数值分散,不易规范化,因此类目映射时选择余弦相似度来衡量U和V之间的距离.
3.2 对比损失函数
在模型训练时,对比损失函数(contrastive loss function)[23]被用来计算2个类目描述文本之间的匹配损失,设计目的在于使匹配的IPC类目描述文本和CLC类目描述文本在它们语义空间中距离最小,而不匹配的类目描述文本之间距离最大.计算公式为
(1-T)max(m-DEuc,0)2,
(6)
其中,θ为模型参数,N为样本个数,T为样本的标签,m为阈值,初步实验经验设置为0.5,DEuc为U和V这2个句子向量之间的欧氏距离,其计算公式为
(7)
当样本标签T=1时,表示IPC类目描述文本和CLC类目描述文本为相互映射(正例),对比损失函数使模型调整参数以最小化U和V之间的距离;当样本标签T=0时,表示IPC类目描述文本和CLC类目描述文本不相互映射(负例),此时分2种情况:当U和V之间的距离大于阈值m,损失为零则不做优化;当U和V之间的距离小于阈值m,则对比损失函数使模型调整参数以增大U和V之间的距离到阈值m.
4 实 验
4.1 人工标注语料
由于前人工作均只在2部分类法的部分类目上进行实验测试,语料类目较为单一,很难充分验证模型的泛化性能.而IPC分类法共有8个类别(部),CLC分类法共有22个类别,每个类别分属不同的领域,为了构建覆盖面全的映射语料库,本文以IPC类目为基准,聘请8位专家对IPC和CLC类目映射进行人工标注,再由一位专家统一对标注后的语料进行校正和核验.总共构建了包含1 000条完全映射的类目对用于模型测试.
图4统计了IPC的8个类别包含的类目数量情况.可以看出,IPC不同类别的类目数量有较大差异,如果在IPC的8个类别中使用简单分层采样抽取类目进行人工映射,容易导致各个类别的采样类目数量不平衡.为了保留各个类别之间的类目数量差异,提高使用其作为训练集训练后模型的泛化能力,借鉴跨语种预训练模型XLM[24]中对不同语言进行随机多项式采样的方法计算IPC的8个类别的类目采样数量,多项式采样公式为
(8)
其中,参数α用来控制采样比例,参考XLM取α=0.5,M为IPC类别的个数,ni,pi为第i个IPC类别包含的类目数量和比例,qi即为第i个IPC类别的采样比例.
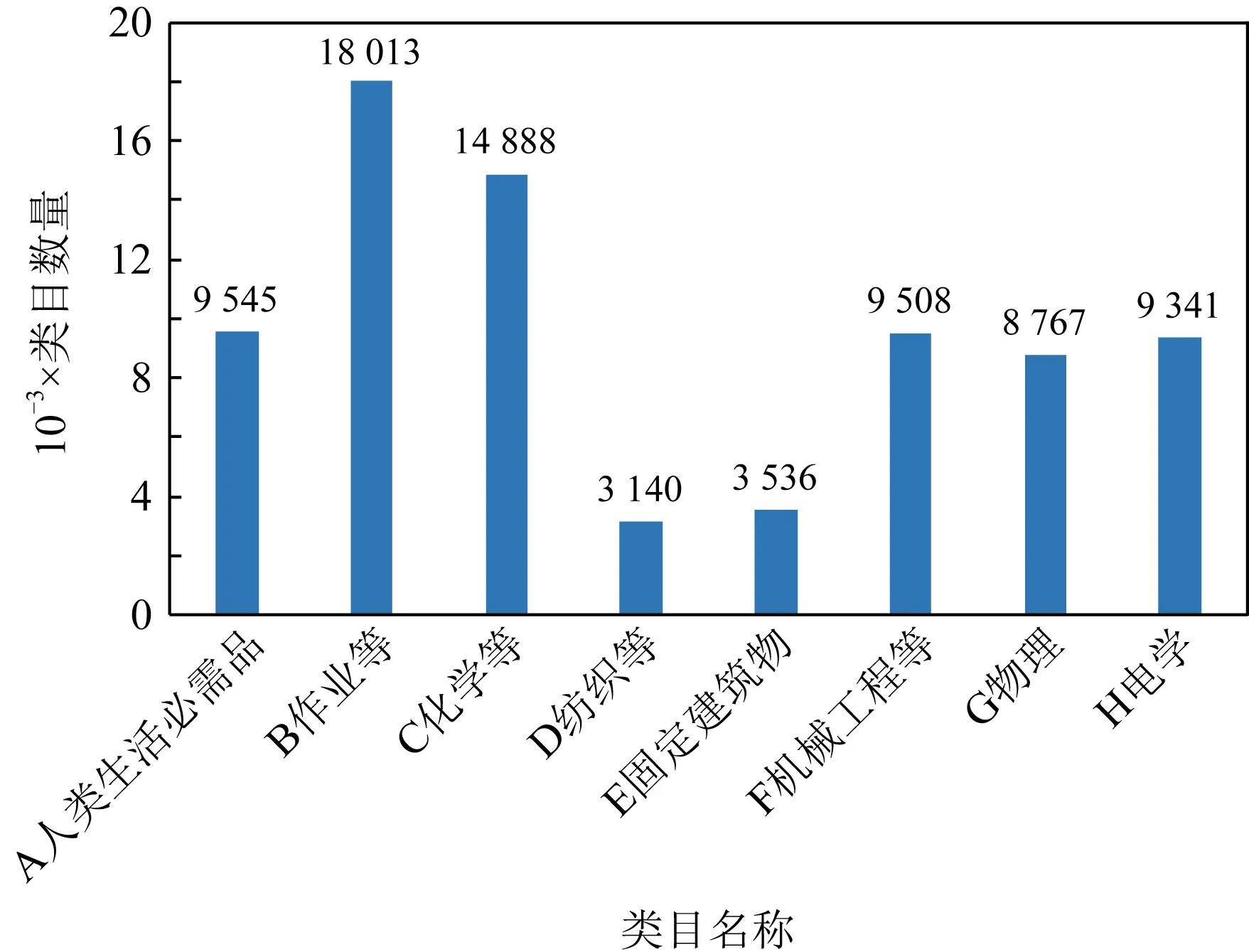
Fig. 4 Category quantity statistics of IPC图4 IPC的类目数量统计
经过多项式采样IPC各个类别后最终得到的类目数量如表2所示.从表2可以看出,如果使用简单的分层采样,IPC各个类别的采样数量极不平衡,这不利于后续模型的充分训练.而使用多项式采样后,可以缓解这种不平衡的情况.
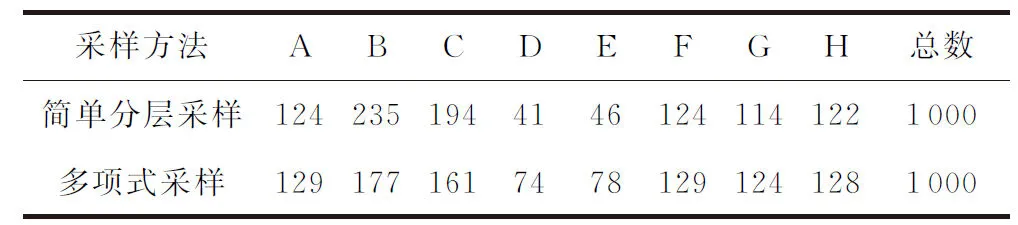
Table 2 Number of Samples in Each Category of IPC
表3展示了一对IPC和CLC数据样例.其中,IPC和CLC都具有严格的层级结构,IPC层级结构分别为部、大类、小类,大组和小组,并且各小组的等级由小组类目名称前的圆点数决定,r个·表示r点小组,最多有六点小组.本文映射语料库建立在IPC的大组到六点小组之间,由多项式采样方法从IPC的大组到六点小组中随机采样进行人工标注,CLC的类目级别由IPC人工标注时决定.此外,在表3中IPC“大组”和“二点小组”行中括号内加粗的句子在整个IPC分类法中重复出现.因此,人工标注时会进行数据清洗,剔除类似这类重复出现的句子,避免实验数据中包含过多的噪音.为详细说明人工标注语料库的数据组成,例如,当人工标注表3中与IPC分类号“G06C7/02”相互映射的CLC分类号,专家根据IPC和CLC类目名称定位到映射目标CLC分类号“TP334.2”,之后专家将IPC分类号“G06C7/02”和CLC分类号“TP334.2”所在类目层级及所有上一级类目层级的类目名称经过数据清洗后利用分号连接成一条句子,最终得到IPC类目描述文本“物理;计算;推算;计数;数字计算机;输入机构;键盘;”和CLC类目描述文本“工业技术;自动化技术、计算机技术;计算技术、计算机技术;电子数字计算机;外部设备;输入设备;”,即构造得到一条相互映射的语料.需要说明的是,人工标注的语料库中包含一对一和一对多的映射关系.
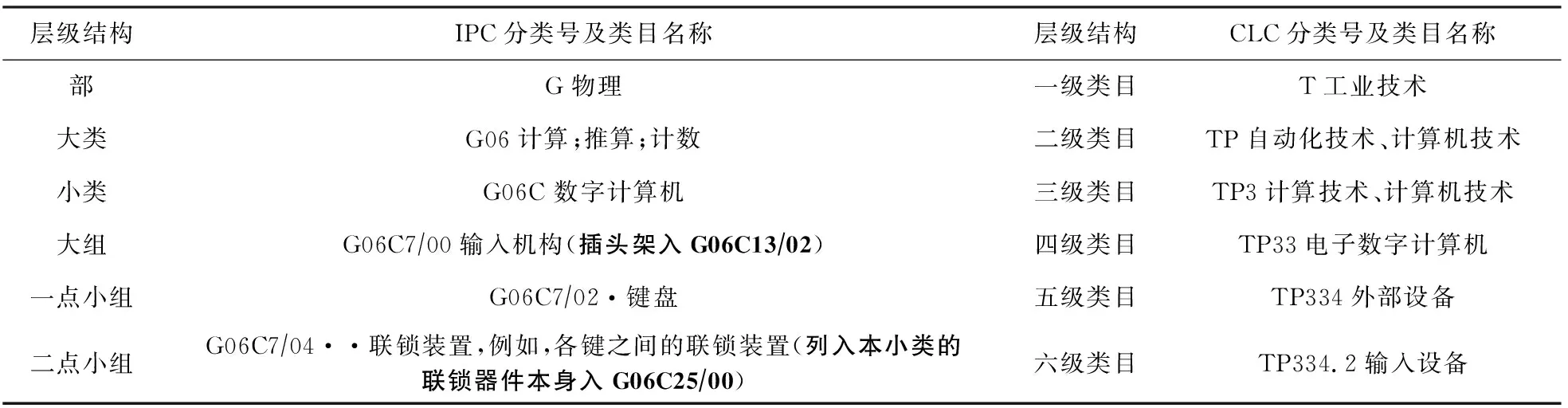
Table 3 Examples of IPC and CLC Hierarchy Structure
4.2 实验设置
为了测试基于BERT模型的孪生网络在IPC和CLC类目映射中的性能,本文采用5折交叉验证,将1 000条人工标注的语料按照4∶1划分成训练集和测试集,然后将5次结果取平均作为最终的模型性能.此外,训练集中的负例由排除正例后随机产生,正负例的比例为1∶1.
实验使用预训练好的BERT上下文语言模型“bert-base-chinese”[22],它由12层Transformer编码器堆叠而成,多头自注意力个数为12,参数数量为1.03亿,在中文维基百科语料上训练获得.在基于BERT模型的孪生网络训练时超参数设置为:批处理大小(batch size)设为64,学习率(learning rate)设为2E-5,优化器使用AdamW,优化器参数设为默认参数,为了减缓模型过拟合,dropout设为0.1,权重衰减(weight decay)设为0.01,使用15%的训练数据作为预热(warm up),训练至模型收敛为止.
准确率(accuracy, AVE)、方差(variance, VAR)和Top-k准确率(Top-kaccuracy)被用作为模型的评价指标.将基于BERT模型的孪生网络方法(Sia-BERT)与其他8个相关模型进行实验对比:
1) Category-Sim.本文复现的基于匹配计数的类目相似度映射模型.
2) Sia-Multi.Reimers等人[25]开源的最佳多语言孪生网络模型,该模型命名为“distiluse-base-multilingual-cased-v2”,支持中文处理.
3) TextCNN.基于Kim提出的TextCNN模型[9],将其实现为TextCNN孪生网络,其中,卷积核大小为(1,3,5),每个尺寸的卷积核个数为256.
4) Bi-TextCNN.基于双线性池化(bilinear pooling)[26]的TextCNN孪生网络模型,卷积核大小为(3,4,5),每个尺寸的卷积核个数为128.
5) Bi-LSTM.基于双向LSTM[27]实现的孪生网络模型,Bi-LSTM的层数为1,隐藏层神经元个数为768.
6) T-Encoder.基于Transformer[11]编码器实现的孪生网络模型,层数为2,多头自注意力个数为8.
7) Sia-Multi-Zero.为了验证孪生网络模型在零样本迁移学习方面的映射性能,在Sia-Multi的基础上不对模型参数进行微调训练,直接利用模型对1 000条实验数据进行映射.
8) Sia-BERT-Zero.与Sia-Multi-Zero设置和目的相同,在Sia-BERT的基础上不对模型进行训练,直接进行映射.
4.3 实验结果
不同模型的IPC和CLC类目映射准确率和5折交叉验证准确率的方差如表4所示,由于Category-Sim,Sia-Multi-Zero和Sia-BERT-Zero没有进行训练,因此表中没有汇报这三者的方差.首先,本文提出的Sia-BERT方法取得了最高平均准确率94.0%,显著优于其他在训练集上优化的深度学习模型Bi-TextCNN,Sia-Multi,TextCNN,Bi-LSTM和T-Encoder.这说明本文提出的方法能极大地提高IPC和CLC类目映射的准确率.其次,Sia-BERT方法的方差值也较小,说明Sia-BERT模型性能十分稳定.再之,在训练集上进行优化的深度学习模型其平均准确率超过80.0%,大幅度优于不使用训练数据的深度学习方法Sia-Multi-Zero和Sia-BERT- Zero,它们平均准确率仅为55.0%左右,这间接说明我们人工标注的语料质量较高,在其上训练的相关模型性能得到极大的提高.

Table 4 Accuracy and Variance of Classification Mapping of Different Models
同为基于预训练的语言模型,Sia-BERT比Sia-Multi性能高出5.2个百分点,这可能是因为多语言模型在训练时需要输入多种语言,各种语言之间的差异导致训练时无法在每种语言上都达到最佳表现.对比Bi-TextCNN模型和TextCNN模型,Text-CNN的平均准确率比Bi-TextCNN高出11.2个百分点,这可能是因为TextCNN编码的句子向量质量已经足够好,如果再进行双线性池化操作导致学习到的句子语义被打乱,致使性能下降.而对比TextCNN,Bi-LSTM和T-Encoder三个模型,发现三者的性能比较接近,但是由于Transformer网络本身的优势,其更适合捕捉句子的深层语义信息,因此T-Encoder在这三者中性能表现最好,其在类别C,E和G上都取得了最高的准确率,分别为94.41%,98.72%和95.97%.
4.4 实验分析
为了进一步展示模型的性能,图5统计了匹配得分前3的类目映射准确率.Sia-BERT模型的Top-3准确率达到99.2%,显著高于其他相关模型的Top-3准确率,且显著优于其本身的Top-1准确率,这说明Sia-BERT模型性能还有很大的提升空间.
表5给出了Sia-BERT模型一个IPC类目“A01C 21/00”的CLC映射Top-3实例.从实例可以看出,Sia-BERT模型可以很好地区分出与IPC类目的描述文本含义比较接近的3个CLC类目“S147.35”“S776.24+1”和“TQ440.2+2”,虽然这3个CLC类目描述文本都与肥料相关,但是与IPC类目正确匹配的CLC类目“S147.35”相似度为0.92(最高为1),且3个CLC类目根据与IPC类目的相似度不同展现出明显的数值差异.

Fig. 5 Mapping accuracy of Top-3 of each model图5 各模型Top-3的映射准确率

Table 5 Mapping Example of Sia-BERT Model
4.5 孪生网络中损失函数的消融实验
损失函数引导网络参数优化的方向,是孪生网络训练中最重要的一环.为了选择最合适的损失函数,实验对比了孪生网络中3个常用的损失函数,分别为三元组损失(triplet loss)、多重否定排序损失(multiple negatives ranking loss)和对比损失(contrastive loss).表6给出了使用不同损失函数时模型的性能,其中对比损失函数的平均准确率最高,达到94.0%,多重否定排序损失函数的性能与对比损失函数相当,三元组损失函数的性能最差,仅为90.7%.虽然多重否定排序损失函数的性能也较好,但是该损失函数要求任务中数据为一对一映射关系,而对比损失函数没有强制的映射关系要求,为减少模型对训练数据的限制,本文选取对比损失函数作为模型优化的目标.

Table 6 Performance of Siamese Network Based on BERT Model Using Different Loss Functions
5 结论与展望
结合BERT模型在语义抽象和孪生网络在差异表现上的优势,本文提出将基于BERT模型的孪生网络应用到IPC分类法和CLC分类法的类目映射任务上,实现2种类目的自动匹配.在高质量的人工标注语料上进行5折交叉验证实验,结果表明所提方法显著优于对比的其他深度学习方法.实验分析揭示基于BERT模型的孪生网络能较好地刻画类目文本的相似度,并在相似文本之间体现出适当的差异性.未来的工作包括借助现有的文本相似度语料训练模型,利用迁移学习将模型应用到科技文献类目匹配任务中,以克服人工标注类目匹配语料耗时耗力的不足.
