基于改进RetinaNet的自然环境中蝴蝶种类识别
2021-08-17谢娟英鲁银圆孔维轩许升全
谢娟英 鲁银圆 孔维轩 许升全
1(陕西师范大学计算机科学学院 西安 710119) 2(陕西师范大学生命科学学院 西安 710119)
蝴蝶是节肢动物门、昆虫纲、鳞翅目、锤角亚目动物的统称[1],在全世界有广泛分布,约有18 000种[2].蝴蝶对环境敏感,有些蝴蝶幼虫以植物为食,危害经济作物,借助蝴蝶分布可研究区域生态环境保护和生物多样性[3].本文借助2018年第3届中国数据挖掘竞赛——国际首次蝴蝶识别大赛[4]公开的蝴蝶图像数据集[5],通过改进经典RetinaNet[6],实现自然环境中蝴蝶种类识别.
快速发现野外环境中蝴蝶位置,实现蝴蝶分类,已经引起计算机视觉领域研究者的关注.然而,现有蝴蝶分类研究主要基于蝴蝶标本照片.2011年,Wang等人[7]借助1 333张蝴蝶标本照,采用基于内容的图像检索技术,通过不同特征提取方法和特征权重设置,使用不同的相似性匹配算法进行消融实验,验证了蝴蝶形状特征对分类更重要.2012年,Kang等人[8]使用包含7个种类的268张蝴蝶标本照,设计特征提取器,提取图像中的分支长度相似性特征,设计3层神经网络进行蝴蝶分类,得到85.6%的准确率.2014年,Kaya等人[9]基于包含14种蝴蝶的140张蝴蝶标本照数据,通过设计特征提取器,将颜色和纹理特征融合,使用3层神经网络分类,得到92.85%的准确率.Kaya等人[10]还分别使用灰度共生矩阵和局部二值模式,采用极限学习机对包含19种蝴蝶的190张标本照进行分类,分别得到98.25%和96.45%的准确率.2014年,Kang等人[11]通过提取不同视角下的图像分支长度相似性特征,利用3层神经网络对含有15种蝴蝶的150张标本照进行分类,得到97.85%的准确率.2015年,Kaya等人[12]提出2种新的描述子提取局部二值模式,处理图像中的纹理特征,对包含14种蝴蝶的140张蝴蝶标本照,利用3层神经网络进行分类,得到95.71%的准确率.2017年,Zhou等人[13]对包含1 117种蝴蝶的4 464张标本照进行数据增强,借助CaffeNet网络模型进行分类,得到95.8%的准确率.2019年,Lin等人[14]提出新的感知网络ISP-CNN,用116 208张增强的蝴蝶标本图像来训练网络,实现蝴蝶分类,验证集准确率达到93.67%,测试集准确率达到92.13%.2020年,Lin等人[15]使用包含56种蝴蝶的24 836张标本照,提出一种带跳层连接的卷积神经网络进行蝴蝶种类识别,得到93.36%的准确率.
截止目前,基于自然环境中蝴蝶图像的蝴蝶种类识别研究相对较少.原因是该类研究非常具有挑战性.蝴蝶分类的依据是其翅膀的花纹、颜色和图案,而野外自然环境中的蝴蝶照片,其翅膀往往被遮挡,使得分类依据的翅膀特征不完全可见.另外,该类数据的获取也非常困难,不仅需要到蝴蝶的栖息地拍摄自然环境下的蝴蝶照片,而且照片中的蝴蝶类标需要非常专业的昆虫学家才能给出.2018年的第3届中国数据挖掘竞赛——国际首次蝴蝶识别大赛[4]公布了一个自然环境下的蝴蝶标注数据集[5].Xie等人[16]使用深度学习目标检测框架Faster R-CNN[17]和YOLO系列[18-19],为竞赛实现了baseline,最佳mAP=76.1%.2018年,Kartika等人[20]使用包含10种蝴蝶的890张自然环境中蝴蝶图像,通过掩膜技术过滤自然背景,保留图像中自然状态下的蝴蝶,构成实验数据,通过提取局部二值模式的纹理特征和形状特征,使用SVM分类,得到66.0%的准确率.2020年,Liang等人[21]通过网络爬虫技术采集网络上的蝴蝶图像,扩充竞赛数据集[4-5],使用集成的YOLOv3[19]对蝴蝶进行自动识别,最佳mAP=79.8%. 2020年,Almryad等人[22]建立一个生态蝴蝶图像数据集,剔除一些同时包含多个蝴蝶实例的图像,并只保留样本数目较多的10类蝴蝶,使用卷积神经网络(VGG16[23],VGG19[23],ResNet50[24])进行分类,最高mAP=79.5%.2021年,Xie等人[25]为解决蝴蝶识别竞赛数据集[4-5]中的蝴蝶类别间不平衡问题,提出一种新的划分策略和数据平衡扩增策略,得到最佳mAP=79.71%.
自然环境下的蝴蝶识别本质上是一个目标检测任务,需要首先检测蝴蝶在图像中的位置,然后进行分类.目前同时涉及蝴蝶位置检测与分类的研究只有Xie和Liang的工作[16,21,25],3篇文献均未达到较高精度.为此,本文将探索和提出更适合自然环境下蝴蝶识别任务的算法模型.RetinaNet模型的Focal Loss[6]有效解决了目标检测中正负样本不平衡问题,本文使用的自然环境中蝴蝶数据前景、背景类别极不平衡,且各类别的蝴蝶数量分布呈现极不平衡的长尾分布,因此,选择RetinaNet为基础模型.注意力机制[26-29]在计算机视觉领域能显著提升检测精度,本文根据蝴蝶数据特点,提出改进的注意力机制来改进RetinaNet模型,增加模型的蝴蝶检测精度.自然环境中蝴蝶形态多变,本文将在注意力机制基础上,引入可变形卷积[30-31]提升模型对形变的建模能力,使有效感受野能更好覆盖前景,囊括更多语义信息辅助检测,得到性能更优的蝴蝶自动检测模型.同时,使用类激活图[32-33]可视化实验结果,分析提出模型的有效性,并采用相似性可视化探索影响模型性能的关键因素.
本文主要贡献包括:1)对数据集进行了详细分析,采用K-means确定合适的实验参数;2)提出新的注意力机制,改进RetinaNet模型;3)引入可变形卷积,增加RetinaNet模型对蝴蝶形变的建模能力;4)将可变形卷积和注意力机制组合,探索自然环境中蝴蝶位置检测和分类方案;5)可视化实验结果,分析模型性能提升的原因和影响模型性能的关键因素.
1 实验数据和参数
1.1 数据数量特征
Xie等人[16]得出训练集中包含测试集类别之外的模式照对最终模型的性能无益,因此本文训练集只含有测试集对应的94种类别的生态照和模式照.对训练集采用与文献[16]相同的扩增方式进行扩增,扩增后的训练集含12 070张图像,命名为Butterfly_Data,按照4∶1划分为训练子集和验证子集.测试集命名为Test_Butterfly_Data,含有94类687张蝴蝶自然生态环境下照片.Butterfly_Data实例分布如图1所示:
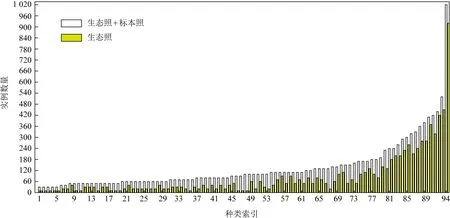
Fig.1 The instance quantity distribution of Butterfly_Data图1 Butterfly_Data数据集蝴蝶实例数分布
从图1可以看出,本文实验数据呈现典型的长尾状分布,不同类别间分布不平衡,一些实例数量比较多的类中,生态照实例超过50%;大部分实例数目较少的类中,标本照的实例数多于生态照的实例数.每张标本照中只含一个实例,每张生态照中可能有多个实例.
整个数据集中实例数量特征如表1所示.表1的最小值列和最大值列数据显示:在生态照、标本照及整个训练集,均存在较大的类别不平衡.
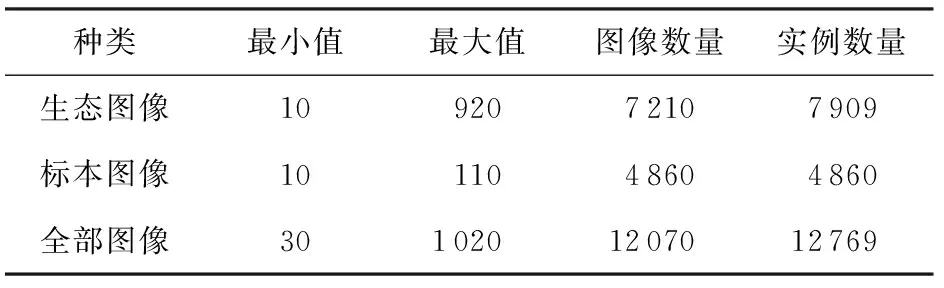
Table 1 Image Quantity Distribution in Butterfly_Data
1.2 数据几何特征
借鉴Kozlov[34]的做法,对Butterfly_Data的几何特征进行统计,结果如图2所示.
图2(a)显示Butterfly_Data数据集图像宽大于高.图2(b)显示数据集图像高宽比和宽高比以1.0近似对称.图2(c)显示数据集实例宽、高分布类似,但宽大于高.图2(d)显示实例宽高比与高宽比关于1近似对称.图2(e)显示,数据集中自然环境下的生态照实例与其所在图像的面积比和标本照实例与其所在图像的面积比有显著差异,生态照实例明显占比小,说明生态照图像中有较多背景信息,标本照实例的面积占比几乎覆盖整张图像.另外,图2(e)还显示,测试集实例面积占比与训练集生态照的实例面积占比类似.
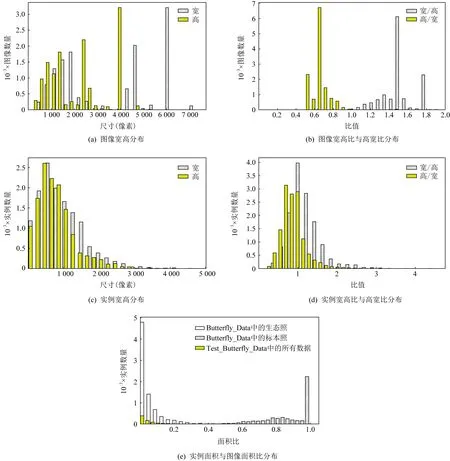
Fig. 2 The geometric distribution of Butterfly_Data图2 Butterfly_Data数据几何分布
1.3 实验参数
为了保障检测精度,RetinaNet[6]根据骨干网络(Backbone)不同阶段的特征图下采样比例,设置不同检测尺寸,每个尺寸通过3种尺度(scale)和3种纵横比(aspect ratio)组合,以特征图中每个像素为中心,形成9个不同尺寸的Anchor boxes.然后计算密集Anchor boxes与Ground-truth boxes的交并比(intersection over union,IoU)值,通过设置阈值对Anchor boxes进行正负样本划分,作为先验知识指导网络训练.然而,RetinaNet使用的COCO数据集[35]和本文的Butterfly_Data不同,因此,需要对Anchor boxes参数进行调整.
RetinaNet以输入数据最短边进行适配缩放.为缓解Butterfly_Data图像缩放形变,同时避免输入过大导致显存溢出,根据图2(b)显示的Butterfly_Data图像的宽高比均值(约为1.5),设定图像最短边不低于512像素,最长边不超过768像素.在此基础上,根据COCO数据集[35]的实例尺寸划分方式分析Butterfly_Data的实例尺寸分布,结果如表2所示:

Table 2 The Instance Size Distribution of Butterfly_Data
表2显示,Butterfly_Data的大实例和中等实例占比之和超过95%,小实例占比为3.89%.Butterfly_Data的大实例样本超过一半((9078-4218)/9078=53.54%)源于标本照,中等实例和小实例均来自于生态照;Test_Butterfly_Data和Butterfly_Data的生态照实例分布类似.
对Butterfly_Data实例的高宽比进行K-means聚类,类簇数K与原始RetinaNet的纵横比参数量保持一致,设置为3,聚类结果的簇中心设为Butterfly_Data的最佳纵横比.根据Butterfly_Data的实例大小情况,将Anchor boxes中的scale范围偏向小物体.Anchor boxes每个阶段的尺寸设置和IoU阈值保留原始RetinNet设置.从而得到本文实验参数,如表3所示:

Table 3 The Parameter Setting of Anchor Boxes
2 方 法
2.1 Backbone网络
卷积神经网络是目前计算机视觉领域的一种主要特征提取技术[23-24,36-45].ResNet[24]的残差模块,一定程度上解决了网络退化问题,使网络能够有更深层次,从而提取到更抽象的特征.另外,还有不少ResNet的改进研究[40,46-48].RetinaNet[6]将ResNet作为Backbone.由于Butterfly_Data的生态图像有较复杂的自然背景,因此,本文选用较深的ResNet[24]以及最新的ResNeSt[48]作为候选Backbone,通过消融实验,选择最佳Backbone.
2.2 注意力机制
注意力机制是一种资源分配机制,可以发掘原有数据的关联性,突出重要特征,被计算机视觉领域关注[26-29].SENet[26]是由Hu等人提出的一个网络架构,是由多个Squeeze-and-Excitation块堆叠而成(见图3(a)),本文记为SEA(squeeze-and-excitation with global average pooling),是一种基于特征图通道的注意力机制,通过Squeeze操作整合特征图不同通道的全局信息,然后利用Excitation模块为相应通道的特征加权,强化对任务有效的特征,弱化无效特征.本文Butterfly_Data生态图像中,图像大部分内容是自然背景,蝴蝶只占了小部分区域,若在Squeeze操作时,直接考虑特征图全局信息,背景特征会对蝴蝶有效特征造成干扰,为此,引入最大池化替换Squeeze操作中的全局平均池化,缓解背景干扰问题(见图3(b)),记为SEM(squeeze-and-excitation with global max pooling).此外,Squeeze-and-Excitation模块类似编码-解码过程,经过Squeeze操作后的通道向量需要经过Reduction Ratio为16的2层全连接整合全局信息,全连接参数质量影响Squeeze-and-Excitation模块的性能,但SENet并没有对全连接参数质量进行有效约束,直接通过全局损失函数来进行梯度更新.针对此问题,本文提出2种硬注意力机制,分别命名为DSEA(direct squeeze-and-excitation with global average pooling)和DSEM(direct squeeze-and-excitation with global max pooling),将Squeeze操作后的通道向量直接经过ReLu整合,使用Sigmoid输出对应通道的注意力向量(见图3(c)~(d)).在RetinaNet的Backbone中分别引入提出的硬注意力机制DSEA和DSEM,提升RetinaNet在自然环境中蝴蝶种类识别的性能.实验部分将通过消融实验验证提出的硬注意力机制DSEA和DSEM的性能.

Fig. 3 The modules of attention mechanism图3 注意力机制模块
2.3 可变形卷积神经网络
在Butterfly_Data中,不同类蝴蝶甚至同一类蝴蝶可能分布在不同自然场景中,在自然环境下呈现多种不同形态,加上照片拍摄条件差异,以及蝴蝶对其生存环境的拟态性,使得蝴蝶位置检测与分类非常困难.卷积神经网络具有平移不变性,能够对简单规则形态的物体进行有效的特征提取,但对物体一些角度未知的几何变换,特征提取性能会大打折扣[49].解决该问题的主要方案有2种:1)通过充足的数据增强提升模型泛化性,然而蝴蝶样本的局限性,无法使模型泛化到一般场景中;2)借助具有几何不变性的特征提取算法来提取特征,如SIFT(scale-invariant feature transform)[50],DPM(deformable part-based models)[51],STN(spatial transformer networks)[29].然而,方案2中前2种算法为手工设计特征,有局限性,不能满足对复杂几何变换的建模,STN体现了空间注意力机制思想,通过学习图像全局仿射,扭曲特征图实现图像特征提取,但无法有效关注局部几何变换.可变形卷积网络(deformable convolutional networks, DCN)[30-31]在每个普通卷积采样点引入偏移量,让采样点可以提取不规则的特征,关注物体局部形态变换.因此,将DCN思想引入RetinaNet的Backbone,增强模型提取特征的能力,达到具有竞争力的蝴蝶位置检测与分类性能.
2.4 类激活映射
模型可视化[32-33,52-55]能直观反映模型关注的区域,一方面可以验证模型泛化性能,另一方面可以指导后续研究.类激活映射(class activation mapping, CAM)[55]相比其他可视化研究,能精确突出图像哪些区域对模型推断是重要的.但CAM在最后一层卷积特征输出后,需要添加全局平均池化[56],再训练微调一个全连接层,经过softmax求得每个类别得分,然后将全连接权重作为类别特征映射权重,在输入图像上得到对应类别的激活视图.Selvaraju等人[32]提出的Grad-CAM不用修改网络结构,直接通过反传梯度获得类别的特征映射权重.Chattopadhyay等人[33]进一步对Grad-CAM进行扩展,提出Grad-CAM++,适配图像中有同类多目标的情况.本文将Test_Butterfly_Data的部分预测结果使用Grad-CAM++可视化.
2.5 方法框架
本文方法的整体框架如图4所示,其中si(i∈{3,4,5,6,7})表示RetinaNet中第i阶段的特征图,K代表类别数(本文K=94),A代表特征图中每个像素对应的Anchor boxes数量(本文A=9).从图4可见,本文在RetinaNet模型框架的基础上,分别采用4种不同的Backbone网络结构进行实验,并将网络输出结果进行类激活可视化.

Fig. 4 The framework of the methods in this paper图4 本文方法整体框架图
3 实验结果与分析

通过3.1节实验比较,选择以ImageNet[57]预训练的RetinaNet的ResNet50为Backbone,实验代码基于Detectron2[58].在训练和测试阶段,设置最短边为512像素,Anchor机制中包含3个scales和3个aspect ratio.使用随机梯度下降算法更新参数,初始学习率为0.001,每5轮学习率减半,动量项权重为0.9,权重衰减系数为0.000 2,训练初期,热身训练迭代1 000次,学习率线性增大.实验操作系统为Centos 7.8,使用单个GPU Nvidia GeForce RTX 2070 SUPER训练模型,在损失函数和验证子集性能变化不显著时,停止模型训练.
3.1 Backbone选择实验
分别将ResNet34,ResNet50,ResNet101,ResNeSt50和ResNeSt101作为RetinaNet的Backbone,Anchor boxes参数设置为表3的RetinaNet配置,Test_Butterfly_Data在各模型的测试结果如表4所示.
表4实验结果显示,对野外环境下的蝴蝶识别任务,ResNet50作为Backbone时,RetinaNet取得了综合最优的性能,除了mAP@0.75指标不是最优外,在其余各指标均取得最优值.因此,本文实验选用ResNet50作为Backbone.
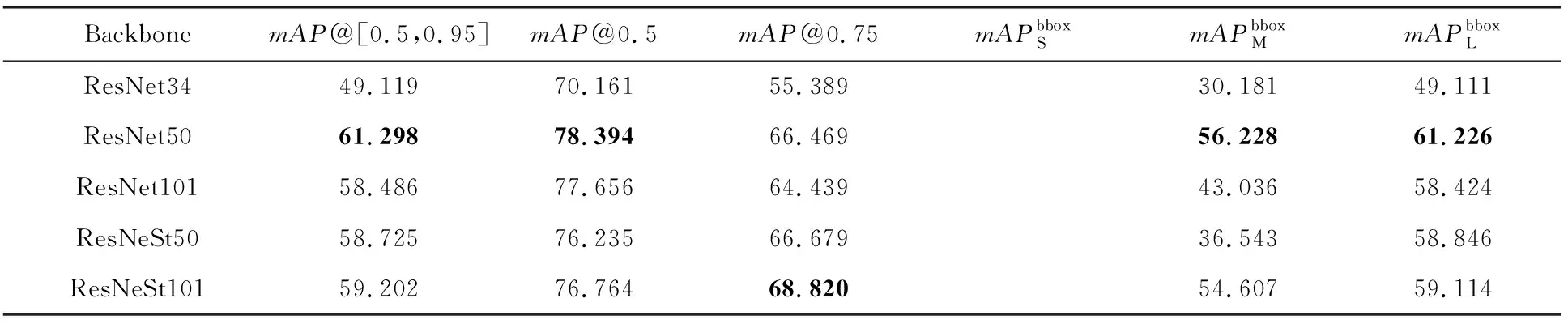
Table 4 The Results of Test_ Butterfly _Data with Different Backbone in RetinaNet
3.2 实验参数配置验证
本节将测试表3根据Butterfly_Data中蝴蝶标本照和生态照的几何特征差异,并鉴于生态照实例的几何特征,调整原始RetinaNet的Anchor boxes参数,提高ground-truth boxes与anchors的匹配度,提升模型性能的实验参数设置的合理性.具体策略是:1)将表3原始RetinaNet的Anchor boxes size减半,scale和aspect ratio保持表3的RetinaNet配置不变;2)将表3原始RetinaNet的Anchor boxes size减半,scale和aspect ratio保持表3中我们的配置;3)采用表3中我们的配置参数.表5为上述3种参数设置的消融实验结果.
表5消融实验结果显示,策略1使RetinaNet模型性能仅在mAP@0.5指标有略微的提升,使用更严格的mAP@[0.5,0.95]和mAP@0.75评价指标时,原始RetinaNet的默认配置更有优势,说明Anchor boxes size减半影响模型对Butterfly_Data中大实例的学习.策略2使模型的mAP@[0.5,0.95],mAP@0.5和mAP@0.75指标相比策略1均有提升,特别是在更严格的mAP@[0.5,0.95]和mAP@0.75评价指标上比策略1有大的提升,说明本文的scale和aspect ratio参数配置合理且弥补了Anchor boxes size减半带来的性能退化.另外,策略2相比于原始RetinaNet模型,在mAP@[0.5,0.95]指标性能相当,但在mAP@0.5和mAP@0.75指标优于RetinaNet模型,特别是在mAP@0.75指标比原始RetinaNet有超过2%的提升.表5结果还显示,策略3采用表3中我们的配置是最优的,模型在mAP@[0.5,0.95],mAP@0.5和mAP@0.75指标均比原始RetinaNet有较大提升.策略3的Anchor boxes size和原始RetinaNet相同,不同的是scale和aspect ratio参数配置,进一步说明本文设置的scale和aspect ratio参数非常合理.综上关于表5的实验结果分析可见,本文RetinaNet模型的参数设置(见表3)非常合理.
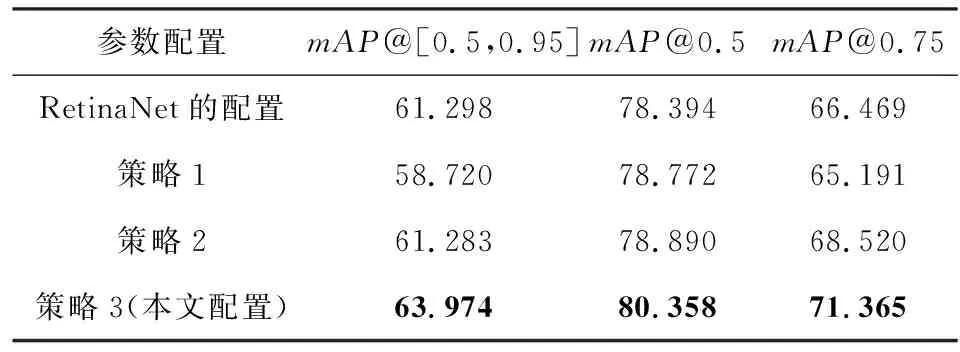
Table 5 Test Results of Test_ Butterfly _Data for Different RetinaNet
3.3 注意力机制测试
图2(e)关于实验数据Butterfly_Data的几何分布显示,自然环境中的蝴蝶图像,蝴蝶实例占整张图像面积的比例很小,注意力机制可以让模型更关注实例区域,减小背景信息对目标检测性能的影响.因此,2.2节在SENet[26]的SEA和SEM注意力机制模块基础上,提出2种更符合Butterfly_Data识别的注意力机制模块DSEA(图3(c))和DSEM(图3(d)).本节以图3的SEA,SEM,DSEA和DSEM注意力机制残差块代替ResNet50中的标准残差块,使用表3我们的参数配置进行消融实验,实验结果如表6所示:

Table 6 The Ablation Experimental Results by Introducing Different Attention Mechanisms in Different Stages of Our RetinaNet Backbone
表6的实验结果显示:在我们RetinaNet的Backbone的全阶段s2~s5引入SEA或DSEA模块比引入SEM和DSEM模块能获得更鲁棒的性能,模型的整体评价指标mAP@[0.5,0.95]得到提升.DSEA模块在没有增加参数的情况下,使模型整体性能比引入SEA模块高出0.528%,说明提出的硬注意力机制对Butterfly_Data的优越性,能非常有效地识别野外环境中的蝴蝶.
此外,浅层特征图中,模型可能提取不到目标的高级特征,背景特征会有较大特征值,因此,将注意力机制模块放在模型的后两阶段高层特征层s4~s5,以避免背景特征的干扰.表6后4行的实验结果表明,在高层特征层,引入SEM和DSEM模块的模型比引入SEA和DSEA模块的模型性能更好,说明提出的SEM和DSEM模块放在高层能学习到目标更高级的特征,且硬注意力机制DSEM比SEM学习的特征更好,在无参数增加的情况下,使模型的性能达到了最大的提升.
表6实验结果分析可见,硬注意力机制DSEA和DSEM对不同层的特征抽象程度敏感,DSEA适用于包含浅层特征的情况,DSEM更适用于抽象高层特征.我们的RetinaNet在深层引入DESM能获得非常好的性能,且需要的参数最少.
3.4 可变形卷积性能测试
3.3节实验测试表明在我们的RetinaNet中引入注意力机制,特别是引入提出的硬注意力机制DSEM使得模型的性能大幅提升,但注意力向量考虑了特征图每个通道的全局特征,没有考虑特征图的局部空间信息,因此,本节使用可变形3×3卷积替换普通3×3卷积,以使模型能够学习到蝴蝶复杂的形态特征.实验使用我们的RetinaNet作为baseline,将可变形卷积残差块替换Backbone不同阶段的普通卷积残差块,测试可变形卷积对模型性能的影响;并测试将连续两阶段普通卷积用可变形卷积替换对模型性能的影响;以及将不连续两阶段的普通卷积替换为可变性卷积的模型性能,甚至将Backbone第2~5阶段的普通卷积全部替换为可变形卷积时的模型性能.消融实验结果见表7.
表7实验结果显示:引入可变形卷积后,模型的性能得到提升,这是因为可变形卷积在特征提取时考虑了特征图的局部空间特征.然而,在不同层引入可变形卷积的效果不同.在深层s5引入可变形卷积的综合效果最佳;在连续2层引入可变形卷积,模型所获得的性能提升介于分别在2个单层引入可变形卷积获得的性能提升之间;在连续多层引入可变形卷积并没有带来模型性能的提升,特别是当s2~s5层全部引入可变形卷积,模型性能与使用普通卷积获得的性能类似.由此可见,可变形卷积对自然环境中的蝴蝶识别不像对COCO数据集那么有效.分析原因可能是:1)自然环境中的蝴蝶识别是细粒度分类,不同类别蝴蝶形态差异小且类间样本分布极不平衡,不足以训练多阶段的可变形卷积残差模块;2)自然环境中的蝴蝶图像包含丰富的背景,可变形卷积在浅层特征中容易关注过多背景特征.

Table 7 The Ablation Experimental Results of Introducing DCN Module in Our RetinaNet
由此可见,可变形卷积不需要太多引入,只需要在高层引入可变性卷积即可较大幅度提升模型性能.
3.5 可变形卷积结合DSEM的实验测试
3.3节验证了提出的DSEM模块的优越性能,本节将DSEM添加到包含可变形卷积的我们的RetinaNet的Backbone,对可变形卷积残差块输出的不同通道特征进行进一步筛选.用dconv_DSEM@si表示在Backbone第i阶段引入带有DSEM的可变形卷积残差模块,dconv_DSEM@si~sj代表在Backbone第i~j阶段引入带有DSEM的可变形卷积残差模块,其他阶段均为普通卷积残差模块.消融实验结果如表8所示:

Table 8 The Ablation Experimental Results by Introducing DCN with DSEM Module in Our RetinaNet
表8消融实验结果显示,在mAP@0.75这种更严格的评价指标下,将DSEM添加到s2~s5阶段的可变形卷积,对可变形卷积残差块输出的不同通道特征进行筛选,可使模型的性能大幅提升,优于没有可变形卷积的RetinaNet模型,也优于在对应阶段仅加入可变形卷积(表7实验结果:69.283%)或者DSEM模块(表6实验结果:68.986%)的模型性能.根据表8的模型整体评价指标mAP@[0.5,0.95]可见,加入带有DSEM的可变形卷积残差模块,不仅弥补了DSEM对特征层级敏感的不足,也增强了可变形卷积的鲁棒性.对比表7的实验结果可见,DSEM结合可变形卷积残差模块应用在Backbone的第5阶段,模型的整体性能mAP@[0.5,0.95]=64.291%低于该阶段仅用可变形卷积的效果(表7实验结果:65.290%),说明在较高抽象特征层,使用可变形卷积能提取更有效的特征,若再经过通道特征筛选,可能造成有效特征丢失,但从较严格的评价指标mAP@0.75可以看出,加入带有DSEM的可变形卷积残差模块,可以让模型对预测框的回归更好.
在此基础上,组合DSEA和DSEM两个硬注意力模块,在Backbone网络浅层(2~3阶段)引入带有DSEA的可变形卷积残差模块,深层(4~5阶段)引入带有DSEM的可变形卷积残差模块,该模型记为dconv_MIX_1@s2~s5;并与浅层(2~3层)只引入可变形卷积残差模块,深层(4~5层)引入带有DSEM的可变形卷积残差模块的网络模型进行对照,该模型记为dconv_MIX_2@s2~s5.消融实验结果如表9所示.
表9实验结果显示,模型第2~3阶段仅使用可变形卷积残差模块,4~5阶段使用带有DESM的可变形卷积的效果优于第2~3阶段使用带有DSEA的可变形卷积残差模块,4~5阶段使用带有DESM的可变形卷积模块.

Table 9 The Ablation Experimental Results by Introducing DSEA+DSEM Module in Our RetinaNet
综合3.2~3.5节的实验结果可见,为实现自然环境中的蝴蝶识别,ResNet50是合适的网络结构,根据Butterfly_Data的几何特征,调整RetinNet的Anchor boxes参数可得到很好的蝴蝶识别模型,在此基础上,引入注意力机制、可变形卷积及两者的组合,可得到更优的预测模型.mAP@[0.5,0.95]整体评价指标最优为65.290%(表7),mAP@0.5指标最优为81.208%(表8),mAP@0.75指标最优为73.276%(表8).对比仅使用单一mAP@0.5作为评价指标的Xie等人[16]的最优结果76.1%、Liang等人[21]的最优结果79.8%和Xie等人[25]的最优结果79.71%,本文取得了该领域最好的实验结果81.208%(表8),且采用了更全面的评价指标.
需要说明的是,由于不同评价指标设置的IoU阈值不同,使得各项指标未必在同一网络结构同时取得最优值,IoU阈值设置越高,对应的mAP值则越低;不同指标还存在一定局限性;另外,不同网络结构对同一数据集提取的特征会存在差异,直接或间接影响模型的各评价指标值.各项指标对比发现,模型dconv_DSEM@s4~s5(表8)是本文最佳的网络结构,在野外环境的蝴蝶识别任务中取得了最好的性能.
3.6 实验结果可视化分析
评价指标mAP只能反映模型的检测与分类性能,不能解释模型具体“看”到了什么.本节采用类激活图方法,解释模型“看”到的具体内容.图5中②~⑩列分别展示了不同模型的预测结果和对应的类激活图,1~4行4幅图像均为测试集数据,其中1,2,3号图像分别包含单个大、中、小蝴蝶实例,4号图像包含多个小实例,可视化中取分类得分最高的预测结果.9种不同模型均检测到了图像中的实例.
图5的实验结果显示,本文各模型,特别是模型⑧~⑩提取的特征更关注的是蝴蝶翅膀的特征,因此其性能更好.这与昆虫学家进行蝴蝶分类的依据一致.
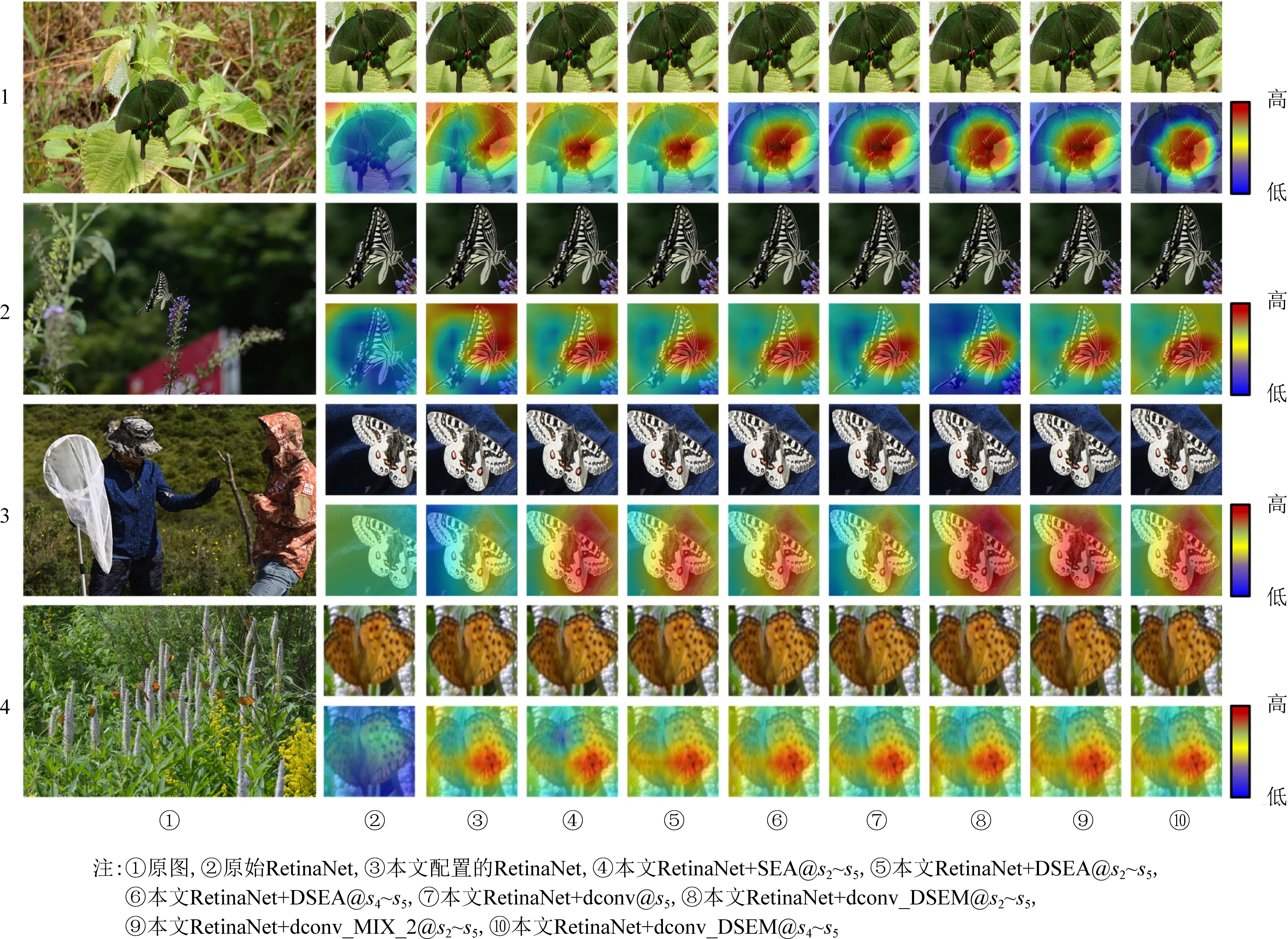
Fig. 5 CAM visualization of several predictive results of different models图5 不同模型部分预测结果的类激活图可视化
为进一步探究本文提出模型的性能提升原因,对图5模型②的预测结果和图5模型⑩的预测结果进行统计分析,统计结果如图6所示.图6中每幅图上半部分为散点图,下半部分为频率直方图和核密度估计曲线.图6(a)~(b)展示了图5模型②预测结果与测试集所有实例的交并比(IoU)和分类得分(Score)分布,图6(c)~(d)对应图5模型⑩.

图6关于原始RetinaNet模型和本文提出的RetinaNet+dconv_DSEM@s4~s5模型预测结果的统计分析结果显示:图5模型⑩的IoU和分类得分均比原始RetinaNet好,尤其在分类得分方面,提出的图5模型⑩有更突出的表现,这有利于模型后处理阶段选择与Ground-truth boxesIoU更高的预测框.
图6统计结果中IoU和分类得分均为0的漏检实例严重影响模型性能.使用图5模型⑩的结果,分别统计漏检实例在测试集对应类别的占比情况,结果如图7所示,横坐标是测试集各类别对应实例数量由小到大排序生成的类别索引,纵坐标为比例值,NoI代表实例数量(number of instance),定义不超过10个实例的类为少样本类别,反之为多样本类别,图像的整体漏检率表示所有漏检实例数目占测试集所有实例数目的比例.
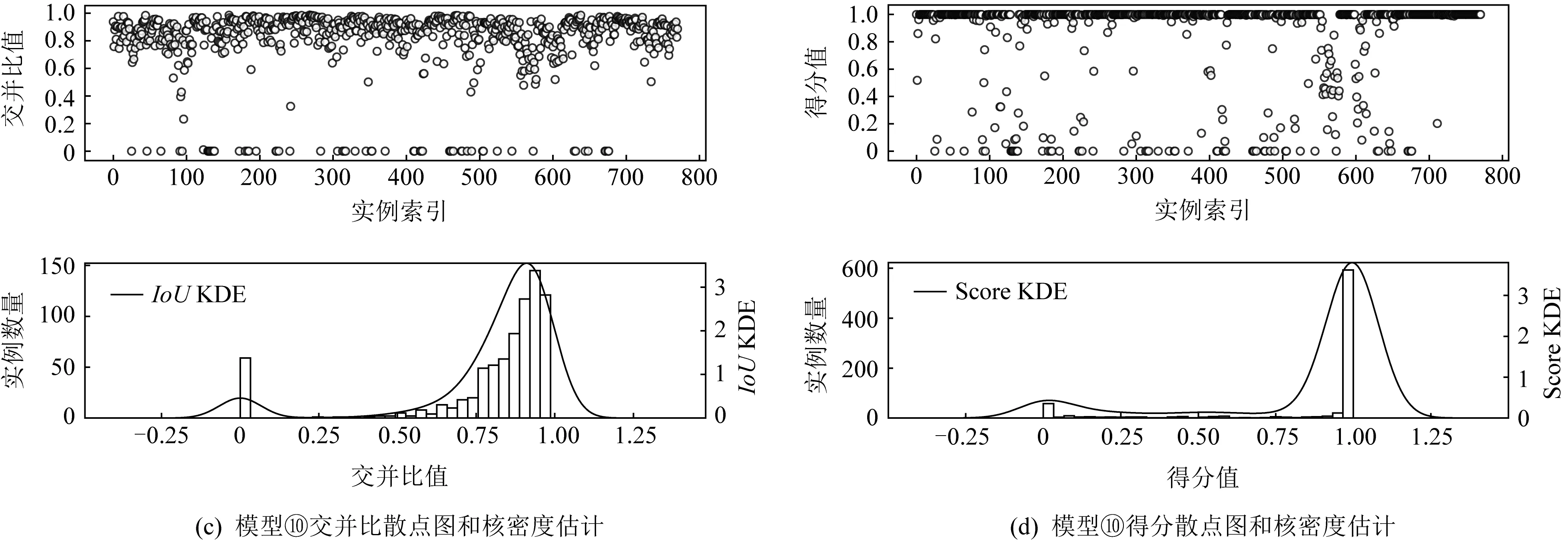
Fig. 6 Distributions of IoU and classification Score of Fig. 5’s models ② and ⑩图6 图5模型②、模型⑩的IoU和分类Score分布
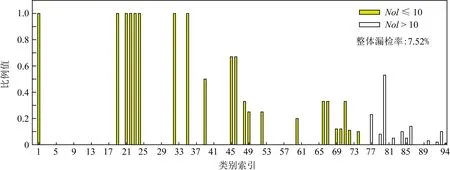
Fig. 7 Ratio of each category missed detection instances in Test_Butterfly_Data of Fig. 5’s model ⑩图7 图5模型⑩对测试集的漏检实例在测试集对应类别实例的占比
图7结果显示:在模型推断过程中,测试集中少样本类别的漏检比例较大,这应该与数据集类别分布不平衡有关,模型对少样本类别的特征学习不足,以至于分类错误,整体漏检率为7.52%.下面通过实验测试,验证平衡数据集可提升本文提出模型的性能,降低漏检率.
文献[25]对竞赛中的蝴蝶图像重新划分训练集和测试集,对训练集应用平衡扩增策略,得到类别分布平衡且标注良好的蝴蝶训练数据集aug-eco-1,对应测试集见文献[25]描述,实验结果如表10所示.其中模型1和模型2均为RetinaNet网络,不同之处在于模型1为表3的原始RetinaNet配置.模型2借助K-means确定针对训练数据集aug-eco-1的RetinaNet模型的Anchor boxes aspect ratio和scale.模型3为本文提出的RetinaNet模型dconv_DSEM@s4~s5,Anchor boxes参数设置与模型2一致.

Table 10 Corresponding Test Results of Different RetinaNet Trained by aug-eco-1 from Ref [25]
表10结果显示,采用类别分布平衡的自然环境中蝴蝶数据集aug-eco-1训练提出模型,所得模型具有更强大的泛化性能,说明本文提出的模型加上分布均衡的训练数据集,可以得到更强的自然环境下蝴蝶种类识别系统.
根据表10中模型3的结果,分别统计漏检实例在测试集对应类别的占比情况,结果如图8所示,图中横纵坐标及图例信息与图7一致.
图8结果显示:使用类别分布平衡的训练集,训练所得模型的少样本类别漏检率可以得到一定程度的缓解,整体漏检率降至4.37%,但漏检实例仍然集中在少样本类别.

Fig. 8 Ratio of each class missed detection instances in corresponding test subset of model 3 in Table 10图8 表10中模型3对应测试集的漏检实例在测试集对应类别的实例占比
表10和图8结果表明,使用类别分布平衡的训练数据集训练模型,所得模型的性能提升有限,说明数据集类别分布平衡与否会影响模型性能,但还不是影响模型性能的关键因素.
为进一步探索影响模型预测性能的关键因素,使用本文的Test_Butterfly_Data对训练好的模型3进行测试,实验结果如表11所示.
表11结果显示,用Test_Butterfly_Data测试训练好的模型3时,各项指标明显增强,主要原因是Test_Butterfly_Data和训练模型3的aug-eco-1数据集有部分数据重合,即训练集中包含了部分测试集数据,因此模型3在Test_Butterfly_Data的表现远超过表8结构完全一样的dconv_DSEM@s4~s5模型.根据以上分析,可以猜想训练集和测试集数据差异是影响模型性能的关键因素.下面通过模型预测结果可视化,验证这一猜想.

Table 11 Test Results of Different Test Subsets Against Well-trained Model 3 in Table 10
3.2~3.5节的消融实验显示本文提出的RetinaNet模型dconv@s5的综合评价指标mAP@[0.5,0.95]表现最佳(65.290%).下面统计该模型预测结果中的正确检测实例和漏检实例及所在图像,然后与训练集中对应类别的实例及图像分别计算结构相似性指数SSIM Index(structural similarity index)[59]和图像均值感知Hash相似性MPHash(mean perceptual hashing)[60],将每个实例和图像的最高相似性得分可视化,如图9所示.其中,图9(a)为测试集所有图像的SSIM Index散点图,横坐标为图像索引,纵坐标为相似度得分;图9(b)为测试集所有实例的SSIM Index散点图,横坐标为实例索引,纵坐标为相似度得分;图9(c)为测试集所有图像的MPHash相似性散点图,横坐标为图像索引,纵坐标为相似度得分;图9(d)为测试集所有实例的MPHash相似性散点图,横坐标为实例索引,纵坐标为相似度得分.

Fig. 9 Plots of SSIM Index and MPHash图9 结构相似性指数和均值感知Hash相似性散点图
图9(a)~(d)结果显示,测试集中正确检测样本与训练集样本最大相似度均值普遍高于漏检样本与训练集样本的最大相似度均值,说明模型对与训练集样本相似性更高的数据推断更准确.其中,图9(a)~(b)均使用SSIM Index相似性,从亮度、对比度和结构3方面衡量2个对象的相似性,不同在于,图9(a)是测试集图像与训练集图像的相似性,考虑图像的前景和背景,图9(b)是测试集实例与训练集实例的相似性,只考虑前景.图9(a)相似性得分明显高于图9(b),说明图像背景可以辅助检测.
图9(c)~(d)使用MPHash算法,从结构单方面度量相似度,图9(c)是测试集图像与训练集图像的结构相似性,考虑图像的前景和背景,图9(d)是测试集实例与训练集实例的结构相似性,只考虑前景.图9(c)和(d)的最大相似度均值显示,正确检测的样本与训练集样本的结构相似性更近,说明正确检测的样本背景和前景均有较高的结构相似性;而图9(c)的漏检样本与训练集样本的图像相似性低于图9(d)的漏检样本与训练集样本的实例相似性,说明漏检样本背景差异较大.
比较图9(a)和图9(c)中正确检测样本和漏检样本的最大相似度均值之差发现,图9(c)使用MPHash算法的差异更明显.这一现象在图9(b)和(d)也存在.由此可见,图像结构差异是导致漏检的关键,同时,也验证了上文猜想的正确性.

Fig. 10 MPHash visualization of instances图10 实例样本均值Hash可视化
图10显示了部分漏检实例和正确检测实例的MPHash变换图像的可视化结果,为凸显图像结构细节,将原图缩放至128×128像素得到对应的MPHash图.图10(a)为漏检实例,图10(b)为正确检测实例,每幅图中前2列为测试集实例和对应的MPHash变换图像,后2列是与对应测试集实例类别相同且MPHash相似性最大的训练集实例及其对应的MPHash变换图像.图10可视化结果显示,测试集漏检样本与其在训练集最大相似样本的结构差异非常大,测试集中被正确检测样本与其在训练集的相似性最大样本的结构差异较小.这与图9的可视化分析所得结论一致,再次说明了野外环境下的蝴蝶种类识别,样本的结构相似性更重要.
4 总结和讨论
本文提出了依据数据几何结构特征配置Retina-Net网络的Anchor boxes参数,实现自然环境下蝴蝶种类识别的有效参数配置策略.本文提出了2种硬注意力机制模块DSEA和DSEM,并引入可变形卷积替代普通卷积的残差块,构建可变形卷积与DSEA,DSEM组合的改进RetinaNet模型,实现自然环境下的蝴蝶检测与分类.大量消融实验验证了提出的模型对自然环境下蝴蝶识别任务的有效性.模型预测结果可视化显示,模型在蝴蝶分类过程中更关注蝴蝶的翅膀特征,与专家辨识蝴蝶的方法相同;模型结果的可视化还发现,野外环境下的蝴蝶分类,样本的结构相似性对模型性能影响更大.
然而,如何使模型自适应地依赖数据几何特征设置Anchor boxes参数有待进一步研究;如何克服由于拍摄角度等不同带来的同类样本的巨大结构差异,从而导致的模型漏检问题,是需要进一步探索和解决的挑战性问题.
