基于迁移学习的路面障碍物检测
2021-08-16赵永刚裴崇利
赵永刚,裴崇利
(中通客车股份有限公司,山东 聊城 252000)
近些年智能汽车技术迅速发展,对于缓解交通拥挤、减少交通事故有着深远的影响[1]。其智能系统可分为三个部分:环境感知、决策规划、运动控制。其中环境感知的质量是决策规划和运动控制的基础和前提[2],目前通过搭载高性能的传感器对交通环境中的行人和车辆能进行有效地识别和检测。但是道路环境复杂多样,除了行人和车辆外,还包括其他非规则的障碍物(凹坑、路障、石墩等)。这类非规则的障碍物同样极大地影响到智能车驾驶的安全性和舒适性。
目前,国内外研究人员大多专注于行人和车辆的识别与检测,而对于非规则交通参与物的研究较少,其中文献[3]以从双目视觉中获取道路信息,选择Canny模板作为边缘检测模板,准确定位到路面缺陷的边缘;这类方法一般适用于清晰的结构化路面,当路面纹理不清楚时,路面缺陷识别精度不高。文献[4]采用雷达传感器从探测信号识别路面结构的缺陷;雷达信号有时容易受到环境干扰,检测的鲁棒性会变差。文献[5]利用形态学的边界提取算法获得道路障碍物的轮廓,实现石块的检测;由于石块的大小和形状具有不确定性,所以依靠形态学的检测方法的泛化能力较差,无法精确地识别各种类型的石块。
1 解决方案
为了提高不规则障碍物检测的精度,同时又兼顾硬件成本,本文提出一种迁移学习与机器视觉相结合的解决方案,如图1所示。
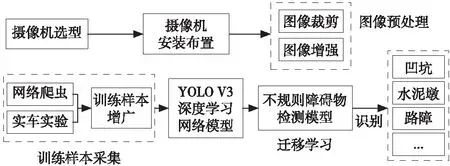
图1 迁移学习与机器视觉相结合的方案
1.1 相机选型与安装
智能汽车不同的应用场景决定了所选用相机的参数和规格。相机选型包括机身选型和镜头选型,相机选型主要考虑成像的分辨率、功耗、体积以及重量等因素。考虑到本文所选用的相机主要用于路面不规则障碍物的检测,对图像纹理和细节要求较高,但是实时性又不能太低,所以最终选用的相机为BASLER ACA1200-50gl,其分辨率为1 920×1 200 pixel,帧率为51 Fps,成像图片为彩色,额定功率3.8 W。
镜头的选型主要考虑工作距离和视角宽度两方面的因素。一般城市道路的平均车速为40 km/h,安全车距保持30 m以上,所用镜头的有效工作距离应大于安全车距。另外车辆在行驶过程中一般只关注本车道和相邻车道的道路状况。我国城市道路车道宽度一般为3.75 m,智能车辆一般需关注到本车道和左右相邻车道的障碍物信息,因此视角宽度应不低于11 m。根据相机的参数和镜头的工作距离及视角宽度,可计算出镜头的其他参数:镜头焦距为17.99 mm,垂直视角为13°,目标宽度为11 m,高度为6.8 m,如图2所示。根据图2的计算结果最终选定镜头的型号为BaslerC23-1618。
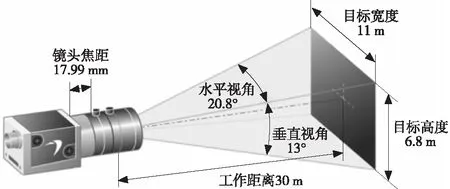
图2 镜头主要参数
相机捕获的图像除了道路信息,还包括其他交通环境信息,如建筑、树木、车辆等。为了确保感知信息中尽可能只包含道路不规则障碍物信息,相机在安装的时候要调整合适俯仰角α,如图3所示。

图3 相机安装布置示意图
相机的安装应以最大程度地感知到路面信息为原则,如图4所示,使其图像能够有效地避免其他环境信息的干扰,有利于提高障碍物的检测精度。

(a)不合适安装方位
1.2 不规则障碍物检测模型建模与训练
YOLO V3是YOLO[6-7]系列目标检测算法中的第三版[8]。相比之前版本,该版检测算法的实时性和准确性都得到了有效提高,尤其是针对小目标的精度有显著提升。YOLO V3已经成为最广泛应用的目标检测算法之一。
通常从零开始训练一个目标检测模型是一个繁琐而复杂的过程,这个过程需要大量的训练数据和丰富的调参经验。为了加速模型的开发和训练,本文基于迁移学习对YOLO V3模型进行再训练,获得不规则障碍物的检测模型,如图5所示。

图5 迁移学习建模流程
迁移学习是通过从已学习的相关任务中转移知识来改进学习的新任务[9],只需要利用相对较少的训练数据对预训的YOLO V3模型中的参数进行微调,便可以快速获得新的目标检测模型。迁移学习能提高模型训练的速度,降低对训练样本的依赖。
1.2.1 训练样本的采集与预处理
本文检测的不规则障碍物主要包括四类:凹坑、石块、石墩、路障。这四类不规则障碍物原始数据的采集来源于两部分:网络爬虫和实车采集。网络爬虫就是根据关键词使用网络爬虫技术从百度图库、搜狗图库、谷歌图库等收集符合要求的图片;实车实验则是通过车载摄像头在真实道路环境中采集这四类障碍物的图像信息。通过上述两种方法共采集原始训练数据图片3 600张,部分如图6所示。

图6 部分障碍物训练数据集
为了增广训练样本的数据,本文基于图像处理的方法分别采用镜像翻转、随机亮度调节和自适应图像增强算法将原始数据拓展到9 570张,其中凹坑图片2 587张,石块图片2 362张,石墩图片2 503张,路障图片2 118张,各类样本数据分布均衡,满足训练要求。最后采用LabelMe[10]数据标注工具对图像进行标注,生成VOC格式的训练数据。
1.2.2 YOLO V3深度学习网络模型迁移学习
迁移学习是在已有的YOLO V3模型的基础上对模型的参数进行重新训练。主要包括以下步骤:
1)首先从Github上下载YOLO V3预训练模型,然后配置cfg文件。设置训练数据和测数据的路径,将batch设置为32,subdivisions=2,代表每个批次参与训练的图像数量。
2)由于本文只检测上述四类障碍物,所以classess设置为4,filters设置filters=(classess+5)*3=27,5代表检测边框的位置信息和1个分类信息,3代表锚框的数量。
3)整个训练过程最大迭代周期设置45,默认优先使用GPU进行训练。参数设置好之后使用train.py文件对模型进行再训练,完成迁移学习。训练过程如图7所示。

图7 YOLO V3再训练过程
由图7可知,随着模型不断训练和迭代次数的增加,YOLO V3深度学习网络模型逐渐趋于收敛。图8中准确率曲线代表模型对各类障碍物识别的精度,随着迭代周期的增加准确率不断升高;损失值代表回归边框误差,为置信度误差与识别误差之和,随着模型不断训练,损失值不断下降,逐渐趋于收敛,最终满足模型检测需求。
1.3 模型效果与评估
为了验证模型的准确性和鲁棒性,选取了200幅未参与训练的图像进行测试验证,部分障碍物检测测试结果如图8所示,整个测试过程包含不规则障碍物412个,其中准确检出372个,检测准确率为90.3%,漏检率与误检率的和为9.7%,模型检测速度为31 FPS,基本满足智能车障碍物检测对于实时性和准确性的要求。

图8 部分障碍物检测测试结果
2 结束语
本文以YOLO V3模型为基础采用迁移学习的方法训练了一个用于智能车不规则障碍物检测的模型。实验表明该模型在光照较好的道路环境中基本满足智能车对于实时性和准确性的要求。但是相机的工作性能容易受到光线的干扰,在未来的研究中可通过融合多个传感器(如雷达)对模型进行改进,从而提高模型对环境的适应性和鲁棒性。
