基于特征双重蒸馏网络的方面级情感分析
2021-08-13宋威温子健
宋威,温子健
(1.江南大学人工智能与计算机学院,江苏无锡214122;2.江南大学江苏省模式识别与计算智能工程实验室,江苏无锡214122)
0 引言
方面级情感分析(aspect-based sentiment analysis,ABSA)作为情感分析领域中的细粒度分析任务,其目的是识别句子中给定方面词的情感极性,即积极、消极和中性。例如,“Great food but the service was dreadful”,当给定的方面词为“food”时,其情感极性为积极。而当给定的方面词为“service”时,其情感极性则为消极。由于ABSA 能够预测不同方面词的情感[1],具有较高的灵活性,目前已被广泛应用于金融[2]和政治[3]预测、电子健康[4],以及用户画像[5]等领域。
ABSA 是自然语言处理(natural language processing,NLP)领域中的一项基本任务[6-8],近十来年得到众多研究人员的广泛关注。早期ABSA 方法利用情感词典、文本语义等人工特征,并结合传统的机器学习来实现方面词级别的情感分类[9-10]。由于获取这些人工特征需要耗费大量的人力和时间,且人工特征的主观性会影响特征的质量,限制了ABSA 的应用[11]。近年来,随着神经网络的快速发展,双向长短时记忆网络(bidirectional long shortterm memory,BiLSTM)被广泛应用于NLP 中的特征提取[12-13]。Chen等人[14]利用正反两个方向的LSTM 分别对句子进行编码,并对编码进行拼接,从而获得句子中每个词的上下文语义特征。此外,由于方面词的实际含义往往会随其上下文的不同而各异,基于上下文的方面词嵌入(context-based aspect embedding,CAE)方法被广泛用于方面词的特征提取。Song等人[15]基于上下文,利用输入的方面词向量,生成基于上下文的方面词语义特征。然而,单独利用各词的上下文或方面词语义特征,缺乏句子中各词与方面词的交互,无法获取句子中给定方面词的情感特征[16]。为此,Wang等人[17]引入注意力机制来计算句子中每个词对方面词的重要性,进而获取给定方面词的上下文特征,以实现情感分析。然而,注意力机制在进行句子与方面词的交互时,容易导致方面词与句子中各词的错误搭配,引入与给定方面词情感无关的噪声,影响方面级情感分类的精度。针对此问题,本文提出一种基于特征双重蒸馏网络(feature dual distillation network,FDDN)的方面级情感分析方法,首先利用Bi LSTM提取句子中每个词的上下文语义特征,并结合CAE获取给定方面词的语义特征,进而通过提出的双重蒸馏门(dual distillation gate,DDG)实现句子中每个词与方面词的语义特征交互,并控制信息流,去除与给定方面词不相关的冗余特征,以获取与给定方面词对应的情感特征。最后利用最大值池化(max pooling)与Softmax对获取的情感特征进行分类。所提的基于FDDN 的方面级情感分析方法主要包含语义特征提取层(semantics feature extract layer,SFEL)、特征蒸馏层(feature distillation layer,FDL)和情感输出层(sentiment output layer,SOL)三个部分。
(1)语义特征提取层:利用BiLSTM 提取句子中每个词的上下文语义特征。同时,结合CAE 获取方面词的语义特征。
(2)特征蒸馏层:利用门控机制设计DDG,其情感特征提取包括初步蒸馏和精细蒸馏两个过程。前者计算句子中每个词与方面词的语义特征相关性,提取方面词在句子中的情感特征,并控制信息流,实现句子与方面词的初步交互与冗余过滤。后者对方面词语义特征进行自适应微调,获取精炼的方面词语义特征,进而用于增强情感特征对方面词的关注度,并增强控制信息流,实现句子与方面词的精细交互与冗余去除。
(3)情感输出层:对情感特征进行最大值池化,并利用多层感知机(multi-layer perceptron,MLP)将池化后的特征映射到分类空间,最终结合Softmax对情感进行极性分类。
本文的主要贡献如下:
(1)情感特征初步蒸馏:本文将情感特征提取细化为初步蒸馏和精细蒸馏两个过程。其中初步蒸馏直接利用方面词语义特征实现句子与方面词的初步交互,并控制信息流,初步过滤冗余特征。
(2)情感特征精细蒸馏:利用精炼的方面词语义特征增强情感特征对方面词的关注度,并增强控制信息流,实现句子与方面词的精细交互与冗余去除。
(3)在通用的Laptop①http://alt.qcri.org/semeval2014/task4/index.php?id=data-and-tools、Restaurant①http://alt.qcri.org/semeval2014/task4/index.php?id=data-and-tools和Twitter②https://githubc.om/songyouwei/ABSA-Py Torch/tree/master/datasets/acl-14-short-data数据集上,所提方法的准确率分别达到79.26%、84.53%和75.30%,宏平均F1值(Macro-F1)分别达到75.77%、75.63%和73.21%,优于目前主流的方面级情感分析方法。
1 相关工作
方面级情感分析旨在识别句子中所给方面词的情感极性,其早期方法主要结合人工特征与传统机器学习来进行情感分类。Vo等人[18]利用情感词嵌入和情感词典来获取丰富的人工特征,在特定的数据集上取得了较好的情感分类效果,但该方法过于依赖人工特征,当迁移到其他数据集时,受其影响较大,且人工特征的获取耗费了较高的时间和人力成本。近年来,方面级情感分析方法主要集中于利用神经网络对句子中的每个词进行编码,以获取其抽象的语义特征。Dong等人[19]提出了一种自适应循环神经网络,通过句法分析来获取句子与方面词的特征。但是句法分析需要依存树、句法关系等外部知识,网络的结构过于复杂,Tang 等人[20]利用LSTM 分别对方面词左侧和右侧的句子进行编码,并将两部分编码进行叠加,以获取整个句子的语义特征。为了获取更全面的句子语义特征,Liu 等人[21]利用BiLSTM 分别从正反两个方向对句子进行编码,以反映双向语义,并拼接编码,提升了语义特征的表达能力。为了获取句子中每个词与方面词相关的情感特征,Ma等人[22]引入了注意力机制,滤除句子中与给定方面词不相关的信息。然而,注意力机制难免会将更大注意力权重分配给句子中不相关的单词,导致方面词的情感特征包含噪声,即典型的注意力机制噪声问题。针对此问题,Liu等人[23]利用门控机制,分别将方面词左侧、右侧及整个句子与方面词进行交互,从而获取与给定方面词相关的句子语义特征。Xue等人[24]首先利用卷积神经网络分别提取句子与方面词的语义特征,并设计门控机制对其进行交互,从而生成句子中与给定方面词相关的情感特征。总而言之,以上方法的门控机制结构相对简单,难以从句子中准确提取与方面词相关的情感特征。为此,本文提出一种基于FDDN 的方面级情感分析方法,在提取各词的上下文及方面词的语义特征基础上,进一步利用门控机制构建DDG,实现句子中每个词与方面词的语义特征交互,并控制信息流,去除与给定方面词不相关的冗余特征,获取与给定方面词相关的情感特征,以实现情感分析。
2 基于特征双重蒸馏网络的方面级情感分析方法
本节具体介绍基于FDDN 的方面级情感分析方法。如图1所示,FDDN 框架包含SFEL、FDL和SOL 三个部分。在SFEL 中,FDDN 首先利用BiLSTM 提取句子中各词的上下文语义特征,并结合CAE 获取方面词语义特征;在FDL 中,构建DDG,实现句子中各词的上下文与方面词语义特征的交互,去除与给定方面词不相关的冗余特征,以获取与给定方面词相关的情感特征;在SOL 中,对情感特征进行最大值池化,并利用MLP 将池化后的特征映射到分类空间,最终利用Softmax对情感进行极性预测。

图1 FDDN 框架
2.1 语义特征提取层(SFEL)
假设输入的句子有n个单词,由词嵌入方法表示句子s的词嵌入向量以及方面词a的词嵌入向量ea,其中,ej表示句子中第j个词的词嵌入向量。在SFEL 中,Bi LSTM使用正反两个方向的LSTM 将ej转换为对应各词的上下文语义特征hj。正向LSTM 从句首开始编码,获取ej的正向语义特征,其计算如式(1)所示。

反向LSTM 从句尾开始编码,获取ej的反向语义特征,接着将与进行拼接,进而获取ej的上下文语义特征,因此,句子词嵌入向量Es的上下文语义特征表示为。
另外,由于给定方面词的实际含义往往会随其上下文的变化而各异,需结合句子的上下文语义来表示方面词。本文利用CAE 方法,首先计算hj与ea的相关性,其计算如式(2)所示。

其中,Wc表示权重,σ表示sigmoid函数,“;”代表拼接操作。基于sim(ea,hj),进而获取ea基于hj的语义特征,其计算如式(3)所示。

因此,ea基于整个句子词嵌入向量Es的语义特征表示为。
2.2 特征蒸馏层(FDL)
在FDL中,利用门控机制设计DDG,实现句子中各词上下文与方面词语义特征的交互,去除与给定方面词不相关的冗余特征,进而获取句子中与给定方面词相关的情感特征。如图2所示,DDG 的结构包含初步蒸馏与精细蒸馏两个部分。

图2 DDG 结构
DDG 首先利用初步蒸馏计算句子与方面词的语义相关性,提取句子中该方面词的情感特征hp∈Rd,实现句子与方面词的初步交互,其算法如式(4)所示。
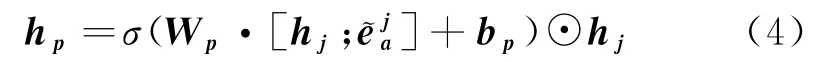
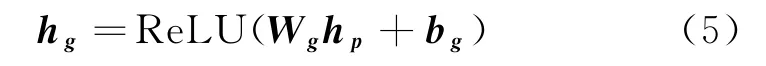
进一步地,DDG 利用精细蒸馏对方面词语义特征进行自适应微调,获取精炼的方面词语义特征,其算法如式(6)所示。
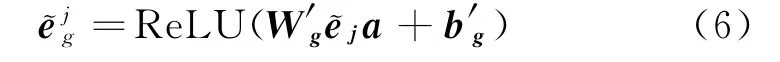

同时,利用精炼的方面词语义特征增强控制信息流,去除句子中与方面词无关的情感特征,最终获取句子中与方面词相关的精细情感特征其算法如式(8)所示。
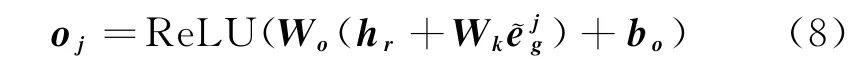
2.3 情感输出层(SOL)
针对单个词的上下文语义特征hj,FDL利用初步蒸馏和精细蒸馏获取其与方面词相关的精细情感特征oj。因此,句子中所有单词上下文语义特征与方面词相关的精细情感特征表示为O=(o1;o2;…;oj;…;on),其中,n代表句子中单词的个数。接着,SOL利用最大值池化,获取O中最具鉴别性的情感特征,易于实现情感预测。最大值池化计算方法如式(9)所示。

接着,利用MLP 将情感特征Z映射到C个分类标签空间,再通过Softmax来预测给定方面词的情感极性,计算方法如式(10)所示。

其中,Wz与bz分别代表权重与偏置。FDDN的训练过程采用交叉熵作为损失函数,并利用L2正则化减少网络对训练样本的过拟合,提高其泛化性。FDDN 的损失函数计算方法如式(11)所示。
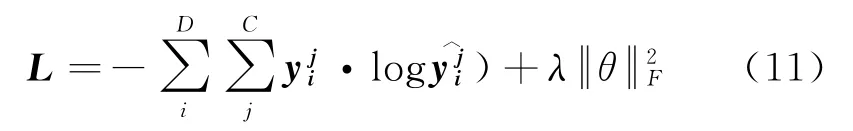
其中,D表示训练集中样本的个数,C表示情感极性的种类,在本文中为3,即积极、消极和中性。代表样本的真实标签,代表正则项。
3 实验
3.1 数据集介绍及评价指标
本文实验分别利用300维的Glo Ve词向量[25]与768维的BERT 词向量[26]来表示输入的句子与方面词,并采用通用的Laptop、Restaurant 和Twitter数据集来验证所提方法的有效性。其中,Laptop和Restaurant 数据集来自SemEval 2014 Task4[27],包含对Laptop和Restaurant两个领域的用户评论。Twitter 来自于ACL14[19],收集了Twitter网站上的推文。每个样本都由句子、方面词及其对应的情感极性构成,三个数据集的统计信息如表1所示。同时,本文采用准确率(accracy)和宏平均F1值(macro-F1)作为情感极性预测的评价指标。

表1 三个数据集的统计信息
3.2 对比方法
本文采用以下方法和所提的FDDN 进行比较。
Feature-based SVM[28]:基于人工特征的支持向量机方法。
LSTM[20]:利用LSTM 直接对句子进行编码,从而获取句子特征。
ATAE-LSTM[17]:利用LSTM 获取句子中每个词的上下文特征,并与方面词向量拼接,获取更关注方面词的句子特征。
IAN[22]:以句子与方面词交互的方式,分别生成含有相互关系的句子与方面词特征。
MemNet[29]:多次采用注意力机制获取句子中每个词针对方面词的重要性,进而获取句子中与方面词相关的特征。
RAM[14]:利用多个注意力机制将Bi LSTM 的输出结合,形成句子的特征。
CNN[30]:利用卷积神经网络来编码句子和方面词的拼接向量,获取情感特征。
GCAE[24]:利用卷积神经网络分别对句子和方面词进行编码,再采用门控机制获取句子中与方面词情感相关的特征。
SK-GCN[31]:利用句法依赖树及常识信息,通过图卷积网络进行情感分析。
BERT-SPC[26]:将句子与方面词分别输入到BERT 分类网络中,对情感进行预测。
ReMemNN[32]:利用多元素注意力机制对句子与方面词特征进行交互,并通过Mem Net[29]进行情感分析。
3.3 实验结果与分析
在实验部分,本文首先对FDDN 进行消融实验。其中,FDDN-DDG 表示在FDDN 中缺省整个DDG,直接对句子和方面词特征进行加和来实现情感分类。FDDN-RD 表示在FDDN 中缺省了DDG的精细蒸馏(refined distillation,RD)过程,直接利用初步蒸馏提取的特征进行情感分类。实验采用Glo Ve与BERT 词向量分别测试以上方法的准确率。在三个数据集上的对比实验结果如图3~图5所示。
从图3~图5 可以看出,从整体趋势上看,在Laptop、Restaurant和Twitter数据集上,FDDN、FDDN-DDG 和FDDN-RD 的准确率在训练开始阶段随着迭代次数的增加而快速上升,然后逐渐趋于稳定。不论是利用Glo Ve词向量,还是利用BERT词向量,在同一词向量的前提下,FDDN 的准确率比FDDN-DDG 和FDDN-RD 要高得多。这是由于相对于FDDN-DDG,FDDN 包含了FDL;而相对于FDDN-RD,FDDN包含了FDL中的RD。具体而言,FDL利用DDG 对情感特征进行了初步蒸馏和精细蒸馏,前者首先对句子与方面词进行初步交互与冗余过滤,后者则实现了句子与方面词的精细交互与冗余去除。

图3 Laptop数据集上FDDN、FDDN-DDG 和FDDN-RD 的训练过程
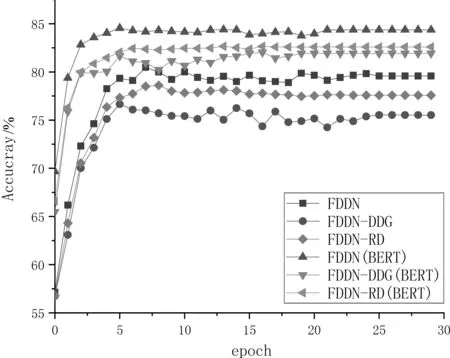
图4 Restaurant数据集上FDDN、FDDN-DDG 和FDDN-RD 的训练过程
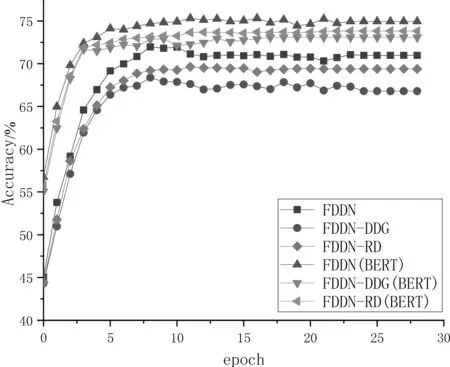
图5 Twitter数据集上FDDN、FDDN-DDG 和FDDN-RD 的训练过程
另外,由图中还可以看出,相对基于Glo Ve词向量的方法,基于BERT 词向量的方法表现较好,这是由于BERT 的词向量维度为768维,而Glo Ve词向量的维度仅为300维,BERT 词向量提供了更丰富的语义与语法信息。同时,与Glo Ve采用静态词向量来表示单词不同,BERT 是一种动态的词向量表示方法。因而,对于同一单词,Glo Ve会生成固定的词向量,但没有考虑单词上下文的变化。而BERT 会根据单词的上下文动态地生成更为准确的词向量来表示目标单词。
为了进一步验证FDDN 的有效性,本文将其与10种基于Glo Ve词向量的主流方法及两种基于BERT 词向量的主流方法进行比较。各方法的准确率及Macro-F1如表2所示。其中,下划线和加粗字体分别代表基于Glo Ve和BERT 词向量方法在三个数据集上的最高准确率和宏平均F1值。“—”代表原始论文没有提供该方法在对应数据集上的实验结果。

表2 FDDN 及主流方面级情感分析方法在三个数据集上的比较

续表
由表2所示,在三个数据集上,FDDN 和FDDN(BERT)的准确率及Macro-F1都高于基于相同词向量的其他方法。具体地,在Laptop、Restaurant和Twitter 数据集上,在利用Glo Ve 词向量时,FDDN的准确率相较于总体表现次好的ReMem NN提高了0.05%、0.09%和0.13%,Macro-F1提高了0.07%、0.22%和0.47%;在利用BERT 词向量时,FDDN(BERT)的准确率相较于总体表现次好的SK-GCN(BERT)提高了0.26%、1.05%和0.3%,Macro-F1提高了0.2%、0.44%和0.2%。
4 总结与展望
本文提出一种基于FDDN 的方面级情感分析方法。该方法首先利用BiLSTM 提取上下文语义特征,并结合CAE,获取方面词语义特征。进一步地,利用门控机制构建DDG,通过初步蒸馏与精细蒸馏两个过程实现上下文与方面词两种语义特征的交互,去除与给定方面词不相关的冗余特征,获取句子中与方面词相关的情感语义特征,最终利用Softmax实现方面级情感分类。为了验证所提方法的有效性,本文采用Laptop、Restaurant和Twitter数据集进行了广泛实验。基于BERT 词向量的FDDN(BERT)在这三个数据集上的准确率分别达到79.26%、84.53%及75.30%,Macro-F1分别达到75.77%、75.63%及73.21%,优于目前主流的方面级情感分析方法。
未来工作中,我们将研究如何把本文所提方法应用于舆情分析、弹幕情感分析等实际问题。同时,为了更好地将所提方法进行实际应用,我们将开发便捷的用户界面,提供更好的用户体验。
