面向专业领域的多头注意力中文分词模型
——以西藏畜牧业为例
2021-08-13崔志远赵尔平雒伟群王伟孙浩
崔志远,赵尔平,雒伟群,王伟,孙浩
(西藏民族大学信息工程学院,陕西咸阳712082)
0 引言
英文的书写要求每个单词之间带有空格,分词只需注意缩写、专有名词和标点符号即可,利用正则表达式便可以很好的完成。但是中文的两个词之间并没有空格等天然的分隔符,这就是中文分词的难点所在。中文分词是命名实体识别、关系抽取的前提和基础,随着算法和模型的不断研究和创新,中文分词技术现在已发展为基于词典规则、基于机器学习和基于深度学习这三类方法。
基于词典规则的分词方法又叫机械分词,对需要分词的文本通过正向最长匹配、逆向最长匹配、双向最长匹配等匹配算法查找词典进行分词。目前词典分词一般作为一种分词后的辅助工具,与一些正确率较高的分词模型相结合,弥补模型的不足。曹勇刚等[1]在统计中文分词模型中融入了词典,提高了中文分词新词识别的准确率和歧义消解能力。成于思等[2]针对中文领域分词的特殊性,改进了构建领域词典的流程,提出了一种可以通过规则和字表消解歧义的二次分词方法,精确率、召回率和F1值分别达到了92.08%、94.26%和93.16%。在深度学习没有发展起来之前,基于机器学习的分词方法一直都是主流,隐马尔可夫模型(Hidden Markov Model,HMM)[3]、感知机(Perception)[4]、条件随机场(Conditional Random Field,CRF)[5]等机器学习模型将中文文本转化成序列标注问题,取得了更高的分词准确率。但是基于机器学习的方法需要制定严格的特征模板,两个常见的单词组合后得到的词语可能会很少出现,在训练集中这类词语的权重微乎其微,带来数据稀疏的麻烦。尤其在领域特征模板的制定上,标注人员需要较强的领域知识,加大了资源的消耗。在自然语言处理领域,Collobert等[6]首次使用了深度学习的方法,解决了人工特征模板存在的问题,将基于特征的处理方式转变为基于结构的工程,根据不同语言和文本来设计不同的网络结构。近几年ELMo(Externally Loaded Media Object)[7]、BERT(Bidirectional Encoder Representation from Transformers)[8]、XLNet[9]等预训练模型更是取得了非常高的准确率,但是在一些特定领域,基于通用语料库的分词器无法解决领域需求。西藏畜牧业领域文本拥有大量的直接音译或者合成的人名、地点、牲畜名、牧草名等富有西藏特点的名词,如人名“次仁明久”,地名“嘎如冲”,牧草名“窄裂委陵菜”和“紫花针茅”等未登录词,所以现有分词技术不适合拥有大量未登录词的西藏畜牧业语料进行分词,为此本文提出了一种深层的包含多头自注意力机制的BiGRU+Multi-Head Attention+CRF分词模型。本文贡献主要体现在以下几点:(1)建立1.5万句西藏畜牧业领域语料库,填补领域语料空白;(2)模型使用双向门控循环神经网络(Bidirectional Gated Recurrent Unit,BIGRU)代替多头注意力机制(Multi-Head Attention)中的位置编码,更好地学习文本上下文关系;(3)与传统注意力机制不同,模型所有的向量都要与句中每个向量计算权重,这样可以无视每个字之间的距离长短,捕获长距离依赖,并行计算向量的关系权重大小;(4)对自建西藏畜牧业语料库使用合成少数类过采样技术(Synthetic Minority Oversampling Technique,SMOTE)进行过采样操作,增强小样本语料对模型的影响程度,一定程度上缓解领域训练数据不足的问题。最后,设计对比实验,验证了本文所提出的分词模型在性能上的优势。这对提高西藏畜牧业等专业领域的智能信息服务水平和信息处理方法具有重要意义。
1 相关工作
随着自然语言处理技术的不断进步,面向专业领域的分词也逐渐成熟,如张婧等[10]从微博未标注语料库中挑选优质语料进行标注,并严格控制重复样例的个数,提出了一种主动学习的方法,F值有较大的提高。姚茂建等[11]将双向长短时神经网络作为分词模型,并使用条件随机场模型对句子进行顺序注释,有效解决了文本语义的长距离依赖性,缩短了网络训练时间并缩短了预测时间。这些基于深度学习的分词技术大大提高了语言模型的准确性,使存在的问题得到了很好的改善。近年来深度学习模型也越来越多的用于中文分词领域,如门控递归神经网络(Gated Recursive Neural Network,GRN)[12],长短期记忆网络(Long Short-Term Memory,LSTM)[13],门控循环单元(Gated Recurrent Unit,GRU)[14]等优秀模型都应用于中文分词中。针对一般文本的汉语分词技术得到了逐步的改进,基于领域的汉语分词研究也不断增加。邓丽萍等[15]使用通用领域的标注文本与无标注的领域文本训练了一种半监督的条件随机场模型,并结合领域词典提高了领域分词的自适应性。倪维健等[16]在面向领域文献的分词中设计了一个独特的分词指标:词频偏差,这个指标能够反映领域文献的构词特点,并基于这个指标提出一种分词结果优化算法,领域适应性较强。
2 多头注意力中文分词模型
本文使用的是一种基于多头注意机制的中文分词模型(BiGRU+Multi-Head Attention+CRF),模型的双向门控循环神经网络(BiGRU)层由正向门控循环单元和反向门控循环单元组成,并在其与条件随机场(CRF)层之间加入了多头注意力层。训练集由公开语料库和自建语料库融合而成。图1为融合了多头注意力机制(Multi-Head Attention)的BiGRU-CRF模型示意图,即BiGRU+Multi-Head Attention+CRF网络模型。模型将文本映射为字向量后传入网络,然后分别利用双向门控循环神经网络与多头注意力机制获取上下文特征和文本相互之间的特征关系,最后由条件随机场输出最优分词标注序列。
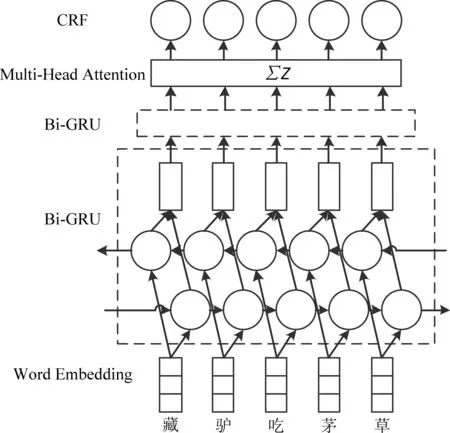
图1 Bi-GRU-CRF模型
2.1 Bi-GRU 层
在n元语法模型中,利用上下文相邻词间信息,对于出现最大概率的词语组合进行自动分词。理论上n值越大越好,但随着n值增加,模型的参数会呈指数级增长,极大地消耗了资源。循环神经网络(Recurrent Neural Network,RNN)通过增加一个隐藏状态来存储前一时间步保存的信息,可以对序列元素之间的依赖性进行建模。有效避免了未登录词(Out-of-Vocabulary,OOV)问题,减少了参数数量,大大加快了训练速度,提高了训练效率。长短期记忆网络和门控循环单元是循环神经网络主要的两个变体,它们修改了循环神经网络中隐藏状态的计算方法,能够记忆一定时间内的长距离依赖关系,解决了一般的循环神经网络遇到较长时间步时存在的特征丢失问题,使循环神经网络能够在更长的序列中有更好的表现。如图2所示,门控循环单元相对于长短期记忆网络来说,其将遗忘门和输入门融合为一个更新门,只通过重置门和更新门就可以完成长短期记忆网络的任务。实验证明,门控循环单元完全能够代替长短期记忆网络,而且更加的简洁,速度也更快。所以本次实验采用了模型结构更加优秀的门控循环单元模型。

图2 GRU 结构示意图
如图2所示,在门控循环单元中,存储器ht-1包括长期记忆和短期记忆模块。过去的记忆和现在的信息都包含在ht内,然后根据zt更新门来决定其重要性的大小。如果使用门控循环单元来对一个句子进行建模,还存在一个不可忽视的问题。单个门控循环单元无法编码一个句子从前到后的所有信息,尤其是在非常细粒度的分词时。本文建立了一个深层的门控循环单元神经网络,以字符嵌入作为输入来学习给定句子的结构信息。在相同输入序列上沿不同的方向训练了两个门控循环单元,构成了双向门控循环神经网络层。双向门控循环神经网络模型具有记忆功能,能够结合上下文的信息。多个双向门控循环神经网络层相互堆栈,并以较低层的输出为输入。双向门控循环神经网络是单个门控循环单元的扩展,并被证明适用于词法分析任务,其中输入是一个完整的句子。如图3所示,将反向门控循环单元与正向门控循环单元组合以形成双向门控循环神经网络层。这两个门控循环单元接受相同的输入,但沿不同的方向训练,并将其结果连接为输出。深层次的神经网络可以有效地表示某些功能并对不同长度的依赖性进行建模。本文使用的增量训练网络由两个双向门控循环神经网络层(两个正向门控循环单元层和两个反向门控循环单元层)组成,具有256维的隐单元。
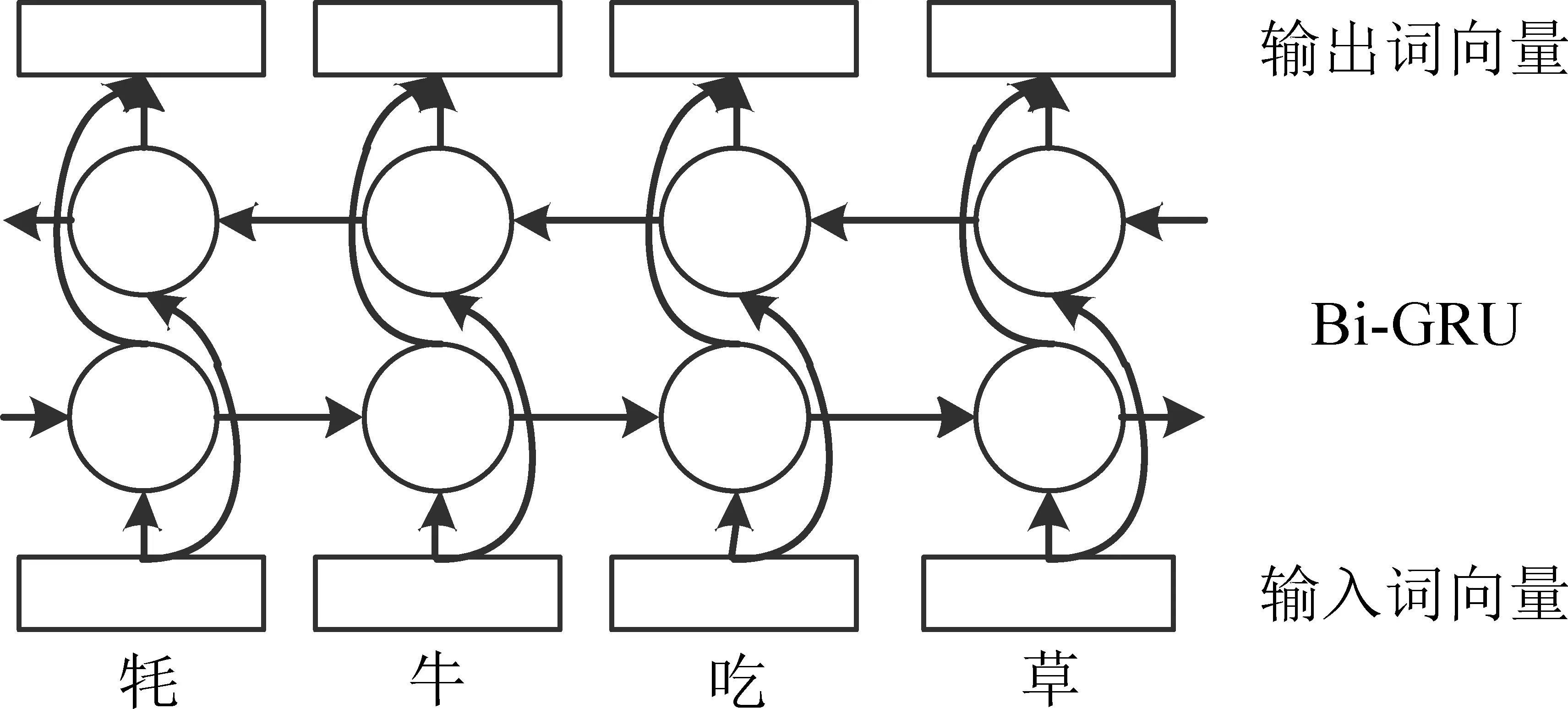
图3 BIGRU 结构图
双向门控循环神经网络可以解决更细粒度的中文分词,例如,前向门控循环单元输入“羊”,“吃”,“草”,使用向量形式标记后为{h L0,h L1,h L2},然后向门控循环单元输入“草”,“吃”,“羊”,使用向量形式标记后为{hR0,hR1,hR2}。然后将前向门控循环单元与反向门控循环单元的隐含向量进行拼接,最后可以得到{[h L0,hR2],[h L1,hR1],[h L2,h R0]},即{h0,h1,h2},这样就可以包含前向和后向的所有信息,捕捉双向的语义依赖。利用双向门控循环神经网络的正反两种状态,就能够在特定的时间范围内充分地利用过去的特征信息和未来的特征信息。其中,门控循环单元层定义如式(1)~式(4)所示。

其中,⊗是向量的元素乘积。σg是更新门ut和重置门σc的启动功能。σ是候选的隐态启动函数。其中,双向门控循环神经网络就是把一个句子所有的字向量分别传入相反方向的门控循环单元网络,将正向学习与反向学习得到的向量连接,使双向门控循环神经网络能够充分学习过去和未来的信息。输出结果如式(5)所示。

其中,⊕表示将两个向量进行拼接。
2.2 多头注意力机制
多头注意力机制(Multi-Head Attention)最先是作为Transformer的一部分提出来的,是Transformer编码器和解码器的核心部分。多头注意力机制由多个自注意力机制组成,其与传统的循环神经网络不同,循环神经网络基于时间步来向网络传输,是迭代进行的,前一个时间步的词处理完成再进行下一个词的处理。而自注意力可以将一个句子中的所有词传入网络,并行处理所有的词。在字向量经过自注意力层(Self-Attention)后,字向量之间有了彼此之间的信息,这种自注意力机制可以让每个字理解互相之间的影响力有多大。本文使用双向门控循环神经网络结构代替多头注意力机制中的位置编码,更好的学习上下文位置关系。
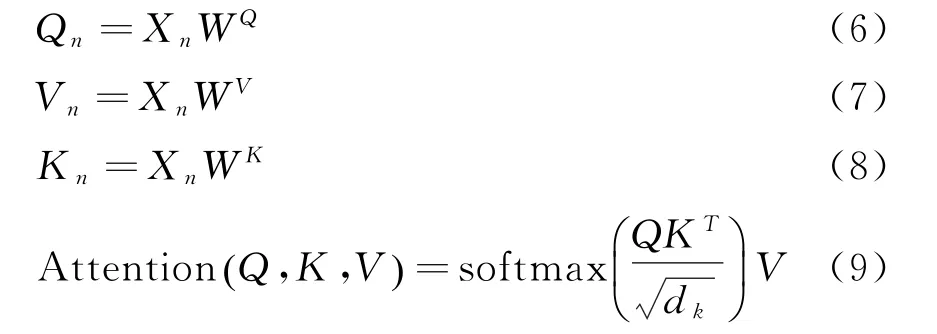
本文多头注意力层包含了六个自注意力头。即:

其中wn为权重参数,Zm代表每一个自注意力头,m为多头注意力的头数,也就是自注意力的个数,在本次实验中设置为6,⊕表示将两个向量进行拼接。
图4显示了上文所述多头注意力机制的计算流程。由字向量转化而来的Q、V、K向量经过矩阵相乘(Mat Mul)得到向量相关度(Score),相关度经过尺度标度和Softmax激活函数的处理后与V向量相乘就得到了一个自注意力,最终由多个自注意力组成多头注意力的层次结构。多头注意力机制可以更有效地捕获文本字符间的权重的大小,而且与双向门控循环神经网络结合后,可以获得多层次的语义特征信息,从而提高中文领域分词能力。

图4 Multi-Head Attention计算流程图
在基于多头注意力机制的BiGRU+Multi-Head Attention+CRF 模型中,我们将多头注意力层插入条件随机场之前,将训练好的字向量传入双向门控循环神经网络之后,每一个字向量都结合了上下文的有关信息。进入多头注意力层后,因为每个字都是独立传入自注意力的,所以其本质是首先计算多个独立的注意力,然后对其所有的注意力做一个集成操作,防止模型过拟合。所以多头注意力模型可以无视每个字向量之间的距离关系直接得出向量之间相互依赖的程度,这样并行计算的方式可以更好、更快地学习句子的内部结构。
2.3 带约束的线性链条件随机场
在经过双向门控循环神经网络层和多头注意力层后,特征向量通过一层全连接层进入条件随机场层。条件随机场是在自然语言处理中常用的序列标注模型,其与感知机有类似的功能,感知机是给已知的序列打一个分数,而条件随机场是计算哪个序列的概率最大。在应用于中文分词时,条件随机场的输入输出都为两个等长的序列,也称为线性链条件随机场,其定义如式(11)所示。

其中,xt有n个特征数,f(yt-1,yt,xt)是一个特征函数,这里称作因子节点。只有包含xt和yt的特征才称为状态特征,包含yt-1的称为转移特征。Z(x)为归一化函数。这里的y是从所有的标注序列Y中取得的,需要遍历所有的y求和,然后进行归一化函数计算。最后类似于感知机的打分函数,在条件随机场中概率最大的序列就是我们所需要的正确序列。在模型中,条件随机场层可以通过门控循环单元层的特征向量提取句子前后的标签信息,然后结合多头注意力机制使每一个字向量包含的信息更有效。条件随机场正好弥补了门控循环单元和多头注意力机制对输出预测标签信息利用不充分的缺陷,使用条件随机场来学习相邻分词标签,得到最终分词预测结果。全连接层将最顶层门控循环单元层的输出转换为L维向量,L是所有可能标签的数量。设矩阵P为双向门控循环神经网络的输出,Ai,j是第i个时间点转移到第j个时间点的概率,Pi,j表示输入序列中第i个词为第j个标签的概率,观察序列X对应的标注序列y=(y1,y2,...,yn)的预测输出如式(12)所示。

训练采用了CRF++工具包,最后,译码后使用IOB2格式的顺序注释方法。例如,向网络中传入一句话“我爱西藏”,经过BiGRU+Multi-Head Attention+CRF 网络后输出“r-B”,“v-B”,“LOCB”,“LOC-I”。其中B 为一个词的开始,I为中间,词以I结束,对于一个字就是一个词的情况用S来表示。最后我们根据分词的输出词性做了约束输出,约束规则如下:
(1)当两个及以上“LOC”(地名)出现,合并为一个“LOC”。
(2)句子的第一个字符不能为“I”标签。
(3)“I”标签前只能为“B”或“I”。
基于以上规则使输出符合IOB2格式的输出,且在长地名方面识别效果更佳,在后续命名实体识别任务中节省相当大的资源消耗。
2.4 领域词典辅助分词
一个优秀的中文分词器必然有一个全面广泛的分词词典,目前有很多开源的分词词典,例如,搜狗的Sogou W[17]、清华大学的THUOCL[18]开放中文词库等千万级开放词库。但是由于西藏信息化发展滞后,网络公开资源严重不足,加之西藏畜牧业领域大量词语是音译的词、专有词等未登录词。即使使用上述千万级词库也不能很好地识别一些带有西藏特色的词汇。例如,“垫状驼绒藜”,这是一种生长于高山山地的低矮植物,使用带有六千万词条的Hanlp[19]分词工具分词后的结果为:“垫状/驼绒/藜”。还有一些藏族的地名和人名,具有浓厚的藏族特色,比如“甲措雄乡充堆八村”、“扎西曲扎”、“嘎玛次成”,都分别被错分成了“甲措/雄乡/充堆/八村”、“扎西/曲扎”、“嘎玛/次/成”。所以为了解决这些未登录词(OOV),提高OOV 的召回率,本文建立了一个西藏畜牧业领域的分词词典。我们爬取了中国科学院西北高原生物研究所关于青藏高原动植物的数据库[20],其中包括动物名355 个,植物名2 150个;我们还从其他相关站点爬取了地名300个,藏族常见姓名500 个。将爬取的数据进行逆向最大匹配,从句子的末尾处开始从词典中匹配,当遇到句子里的一个词语包含词典中的几个词语时,按照从左到右词语长度最大的为准。加入了领域词典后解决了一些未登录词被误分的错误。
3 实验及结果分析
3.1 训练数据与方法
为了获得足够的数据量以使分词模型的效果达到最佳,训练集的训练语料主要来自MSR 语料库和PKU 语料库,MSR 为微软亚洲研究院标注,PKU 为北京大学联合富士通根据人民日报标注。MSR 与PKU 都是语料标注员手工进行标注的。为了使模型更好地学习西藏畜牧业领域分词的特点,我们自己建立西藏畜牧业领域语料库(Xizang Minzu University,XMU)来规范化训练。表1总结了训练集中每个语料库的详细信息。

表1 训练语料库
本文使用相同的训练语料库进行了两轮共八次分词实验,语料库如表1所示。对于我们自建的西藏畜牧业领域语料库,使用合成少数类过采样技术(Synthetic Minority Oversampling Technique,SMOTE)对语料库进行过采样,SMOTE 算法就是从已有的少数样本中提取特征和规则,然后根据这些特征和规则进行人工合成新样本,最后加入到训练集中。如图5所示,设三角形代表我们的领域语料库的向量表示,圆形代表公开语料库的向量表示,SMOTE就是随机选定少数样本中的一个样本,再使用k近邻算法得到最靠近它的几个少数样本,这样两个少数样本之间的任意一点就可以作为新增样本加入训练。

图5 SMOTE算法示意图
式(13)为上述SMOTE 算法生成新训练样本xnew的计算公式。

其中,xi为领域语料库中随机样本,xi(nn)为k个近邻中的随机样本,S为0 至1 之间的随机数。对所有少数样本进行上式操作便可以生成新的训练样本数据。过采样的方式确保了每种语料库都能在一定程度上影响模型的参数,充分发挥了自建小领域语料库对模型的影响程度。本文实验设置如下:实验一使用jieba分词工具的隐马尔可夫分词模型,并加入了西藏畜牧业领域词典;实验二采用了文献[21]中的条件随机场模型,实验三采用了文献[11]的BiLSTM-CRF模型,两次实验的训练集与本文模型一致;实验四是采用的本文BiGRU+Multi-Head Attention+CRF模型。第二轮实验时,我们添加了领域词典,又分别做了以上四个实验。
3.2 实验环境与评价指标
本文实验采用Tensorflow2.1.0深度学习框架,编程环境为Python3.7.7;实验运行环境为Windows10 系统,CPU 为Xeon e5-2678 v3,内存为32GB,GPU 为NVIDIA GeForce RTX 2070,显存为8GB,CUDA 版本为10.2。本文利用LAC 词法分析工具进行分词,构建了一个注释训练集。选择LAC是因为LAC 的训练集包含来自:网页标题,Web搜索查询,来自大量站点的网页新闻和文章等四个方面的文本。比如对于西藏的一些公司和企业名字来说,LAC和其他常见的分词工具相比具有最高的准确率,原因是依托的百度公司信息库非常庞大。为了验证本文模型的有效性,实验选用的训练集是MSR、PKU 和XMU 数据集,因为目前国内在西藏畜牧业领域尚无规范的语料库作为参考,所以我们从XMU 数据集中拿出10%作为测试集。语料的分词标准参考《北京大学现代汉语语料库基本加工规范》[22]。实验结果使用常用的P、R、F值来判定,如式(14)~式(16)所示。

3.3 最佳训练参数
如表2所示,在本文模型中,第一层门控循环单元传入的字符嵌入的维数设置为128;全连接层使用随机矩阵初始化。初始化矩阵时所有元素均从-0.1 到0.1的均匀分布中采样。在双向门控循环神经网络层中,本次实验使用Sigmoid函数作为激活函数,将tanh 函数用于候选隐藏状态的激活函数。神经网络模型使用随机梯度下降来进行参数优化。基本学习率设置为1e-4。嵌入层的学习率设置为4e-2。一次训练所选取的样本数(Batch Size)设置为256,使训练能够最好地利用GPU。在设置好网络的参数后,从每种语料库中选择40个样本分批传入神经网络。选择样本都是以随机的,非替换的方式进行,直至语料耗尽,然后从头开始重新选择,不断循环。

表2 西藏畜牧业领域分词模型超参数
带词典的BiGRU+Multi-Head Attention+CRF模型F1值随训练轮数的变化如图6所示,其中模型在所有训练样本训练20次时(epoch=20)达到最大F1值95.27%;不带词典的BiGRU+Multi-Head Attention+CRF 模型也是在训练20次时达到最大F1值91.39%;BiLSTM-CRF 模型在训练19次时(epoch=19)达到最大F1值90.23%。隐马尔可夫模型(HMM)与条件随机场(CRF)模型都是在训练18次后(epoch=18)达到最大F1值。因为在这里领域词典是在训练结束后加入的,所以从理论上讲,对于相同模型是否加入领域词典对结果的影响是一致的,即F1与epoch 数值关系应该是成比例增加的,但是由于在测试集上每一个epoch并不完全相同,所以相应的F1值受到词典的影响程度具有一定的弹性,故呈现出图6所示的变化曲线。

图6 Epoch与F1关系图
3.4 分词效果分析
表3 列出了本文模型(BiGRU+Multi-Head Attention+CRF)与隐马尔可夫模型、条件随机场、BiLSTM-CRF模型在测试集上的P(准确率)、R(召回率)和F1值(综合指标)。根据实验结果可知,BiGRU+Multi-Head Attention+CRF 模型在西藏畜牧业领域已经达到了较高的准确率,比一般的BiLSTM-CRF模型P、R、F1分别高出了3.93%、5.3%、3.63%。实验证明,本文模型中双向门控循环神经网络很好地完成了结合上下文信息的任务,而且比双向长短期记忆网络模型拥有更少的模型参数,更快的收敛速度,尤其是在加入多头注意力层后,模型能够抓住文本的重点特征时,并行计算文本句子的内部结构,提高分词准确率。

表3 分词实验结果(不带词典)
通过表3 与表4 的对比可知,本次实验的BiGRU+Multi-Head Attention+CRF模型加入领域词典与不加领域词典F1值相差了3.88%,这主要是因为西藏畜牧业领域的专有名词较多,许多植物名称和地点名称是由藏语直接音译而来,与大众语料库的语法规则相差较大。因为领域词典能够很大程度上解决未登录词和专业词语,所以造成了评测指标的巨大差异。

表4 分词实验结果(带词典)
表5列举了测试语料中3个例句在实验1~实验4中的对比结果。从分词结果来看,隐马尔可夫模型、条件随机场与BiLSTM-CRF模型在遇到未登录词时,偏向于将未登录词切分为单字,例如,“紫花针茅”分别被切分为“紫/花针茅”与“紫/花针/茅”。本文提出的模型趋向于将词结合,可以在领域词典未收录的情况下,正确切分出某些词。例如,表5中的例3“喜马拉雅米口袋”,其中“喜马拉雅米口袋”是一种中药名称,不应被分开。这一点在进行地名分词和公司机构名分词中尤为明显,例如,表5例2中,“桑珠孜区甲措雄乡卡堆罗吉专业合作社”是一种典型的包含地点名词的机构名称,隐马尔可夫模型、条件随机场和BiLSTM-CRF模型都将其错误地切分开。而在例2和例3中,因为“江孜藏毯”、“痈肿疔毒”不在领域词典中,所以,实验1~实验3相应的分词结果不正确。这种领域术语中包含常用的非专业领域词,直接加载领域词典往往不能正确处理,但是采用本文提出的模型(带词典)可以切分为“江孜藏毯”、“痈肿/疔毒”,虽然第二个被分开,但是不影响语义完整性与可读性。

表5 实验结果举例

续表
综上所述,在处理西藏地区特有的畜牧业语料时,利用本文提出的分词模型能够极大提高分词的正确率、召回率和F1值。在西藏畜牧业领域也具有很大的实用性,可将一些不常见的动植物名称、人名与地点名很好地分开,在做下游的命名实体识别任务时减少一些不必要的工作量,准确率也会相应地提高。
4 结论
为了解决中文分词在专业领域分词正确率低的问题,本文以西藏畜牧业领域为例,使用了带有多头注意力机制的BiGRU+Multi-Head Attention+CRF网络结构,构建了一个面向西藏畜牧业领域的中文分词模型,使用1.5万条西藏畜牧业领域分词语料库与MSR 和PKU 等公开语料库进行训练,最后通过构建领域词典来进一步提高OOV 召回率和歧义消解能力。通过与现有流行的几个主流分词模型比较,本文提出的模型能更好地识别西藏专有的动植物名称、地点名称和人名,能有效改善西藏畜牧业领域分词模型性能,对专业领域分词系统的构建提供了参照。
由于西藏畜牧业的公开网络文本资源较少且不集中,领域语料库为纯手工从网络中摘取,单一句式较多,在一些短文本分词中会出现切分不完全等错误,而且也导致没有更多的语料进行测试。本文提出的模型结构和参数在针对小型语料库训练还有进步提升空间,是我们未来的研究方向。
