一种基于矩阵分解和随机森林算法的推荐模型
2021-08-12罗云芳
罗云芳 李 力
1(广西职业技术学院机电与信息工程学院 广西 南宁 530226)2(电子科技大学计算机科学与工程学院 四川 成都 610054)
0 引 言
近年来,大数据已发展成为许多工业和科学领域、电子商务和电子政务的数据分析和服务新技术。大数据这个术语通常指的是数据集,其容量超出了传统工具在可接受的计算时间内捕获、管理和处理数据的能力。由于网络上可用信息的爆炸性增长,用户面临着压倒性选择的关键挑战,出现信息过载现象。因此,大数据技术的挑战在于探索和分析海量数据,以提取特定目标所需的相关信息[1-2],为搜索服务和推荐系统提供更广泛、实时和精准的信息,尤其是面向用户和组织的个性化服务。
推荐系统已经成为解决上述问题的强大工具,该技术的目标是根据用户过去的喜好和兴趣为用户提供个性化建议[3-4]。目前,随着用户、项目和生成的其他信息数量的快速增长,海量的数据给推荐系统带来了诸多挑战[5]。这些挑战启发了许多研究者提出了几种方法来提高大数据背景下推荐系统的性能。Hsieh等[6]提出了一个基于关键词的推荐系统,利用从用户和项目文本数据中提取的关键词提高该系统使用Apache Hadoop处理大规模数据集的性能,缓解冷启动问题。Papadakis等[7]设计了一个基于综合坐标的推荐系统SCOR,通过使用vivaldi综合坐标算法将用户和项目放置在多维欧氏空间中,利用项目和用户之间的欧氏距离来预测未知偏好,从而提高预测精度。Hammou等[8]提出了一种大数据量的近似并行推荐算法,该算法是基于Apache Spark开发的,有效地提升处理大规模数据的效率。Tran等[9]提出了一种规则化的多嵌入推荐模型RME,该模型采用加权矩阵分解,结合用户嵌入、共同不喜好项嵌入和共同喜欢项嵌入,用以获得较高的预测精度。Costa等[10]提出了一种基于集成的协同训练方法ECoRec,它采用两种或两种以上的推荐方法来提高系统的性能,提高预测精度。
尽管当前一些推荐技术可以很好地应对大数据和推荐系统所面临的各种挑战,但是,执行训练任务的计算成本可能会对大规模数据造成计算上的限制,对于海量数据需要考虑计算效率。除此之外,数据稀疏性是面临的另一个关键问题,它对预测质量有负面影响。针对上述问题,本文提出一种基于数据分割策略和新的学习过程的分布式推荐模型,然后提出基于矩阵分解和随机森林的混合推荐算法,通过加速训练任务缩短计算时间,解决数据稀疏性问题,提高预测质量,有效地处理大规模数据。
1 相关知识
1.1 随机森林
随机森林算法是在2001年由Breiman提出的一种新的机器学习模型[11],该模型将随机子空间方法与引导聚集算法结合在一起,通过反复二分数据进行分类或回归,从而降低计算量。其原理是采用随机的方式建立一个森林,在森林里存在很多决策树,然后利用多棵决策树对样本数据进行训练、分类和预测。RF算法对大部分数据具有很好的分类效果,模型训练速度快,不易出现过拟合现象,具有一定抗噪声能力,同时预测准确率高。
随机森林的构建过程如下:
(1) 原始训练集有N个样本数,使用Bootstraping方法从中随机有放回地采样n(n≤N)个样本,共进行K次采样,生成K个训练集。
(2) 对K个训练集,分别训练K个决策树模型。
(3) 对于单个决策树模型,假设训练样本具有m个特征数,那么每次分裂时根据信息增益、信息增益比或者基尼指数,选择最好的特征进行分裂。
(4) 每棵树都采用这种形式分裂,直到该节点的所有训练样例都属于同一类。
(5) 每棵决策树的分裂过程中不需要剪枝,以最大限度生长。
(6) 将生成的多棵决策树组成随机森林,用随机森林分类器对新的数据进行分类与回归。对于分类问题,按照多棵树分类器投票决定最终分类结果;对于回归问题,由多棵树预测值的均值决定最终预测结果。
1.2 矩阵分解
矩阵分解[12]是一种将矩阵简化为其组成部分的方法,这种方法可以简化更复杂的矩阵运算。矩阵分解是降维技术,属于潜在因子模型。由于在可伸缩性和推荐系统方面的卓越性能,它受了极大的欢迎。
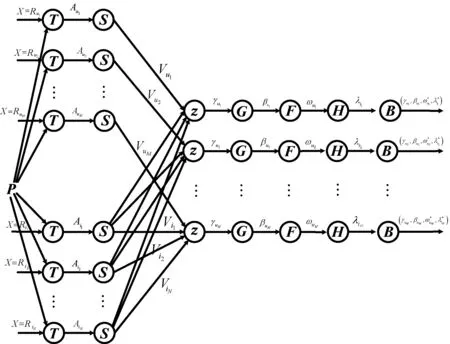
矩阵因式分解的主要思想是,项目和用户可以通过从评分矩阵中推断出的少量潜在因素来表示。具体来说,给定用户项评级矩阵R和潜在因子的数量C R≈EW (1) (2) 式中:Eu和Wi是用户u和项目i的潜在向量。 对于训练任务,常用方法是最小化目标函数: (3) 式中:ru,i是用户项目评分矩阵R中的已知偏好;λm是正则化参数。 大数据已经引起了学术界和行业的广泛关注,研究学者开发了一些分布式计算框架。由于MapReduce对于跨多个步骤共享数据的应用程序效率低下,最近出现了Apache Spark[13],克服了Hadoop的弱点。Spark中的关键部分被称为弹性分布式数据集(RDD),这是元素的不可变和分区集合,可以通过分布式方式进行处理。RDD设计为容错的,即在节点发生故障的情况下,Spark能够通过沿袭信息重建丢失的RDD分区。它运行速度比Hadoop MapReduce快100倍,而磁盘上的速度快10倍。 推荐系统是一种主动给用户推送信息的推荐技术,通过分析用户过往的行为信息与兴趣特点,向用户推荐其感兴趣的个性化决策支持和信息服务。大数据环境下的个性化推荐问题可以定义为:假定U={u1,u2,…,uM}和I={i1,i2,…,iN}是用户和项目的集合,其中M和N为系统中用户和项目的数量。每个用户u提供的偏好可以表示为评级向量Ru=(ru,i1,ru,i2,…,ru,iN),ru,i表示用户u对项目i的评级。使用用户项目评分矩阵R表示所有用户对项目的偏好。由于每个用户u∈U仅对非常少的项目进行评分,因此ru,i对评分矩阵R中的大多数对(u,i)是未知的,这是数据稀疏的主要原因。 针对大数据提出一种分布式推荐方法,由于稀疏性、预测质量和计算时间几个因素可能会影响推荐系统的性能,因此,本文解决方案的目标是解决数据稀疏性问题,提高预测质量,减少计算时间并有效处理大规模数据。提出的分布式推荐方法是基于Apache Spark设计的,它基于三个步骤:(1) 数据分区,目标是将数据划分为最佳数量的分区;(2) 通过使用一种新的学习过程来训练模型,以提高推荐质量,同时减少计算时间;(3) 预测偏好。图1给出分布式推荐方法的流程。 图1 分布式推荐方法的流程 数据在节点间的分布对于并行和分布式计算的效率至关重要。该步骤的主要目标是将训练数据RDDtrain划分为一个最优的分区数目,从而使所提出的模型能够加速并行和分布式训练任务的执行。 设Np为可能分区数的集合,Time(RDDtrain,np)为根据参数np执行训练任务所需的计算时间的函数。问题可以定义如下: (4) 该模型可以表示为有向无环图。每个节点代表一个接收输入数据并产生输出的函数。每个节点的输出用作下一个节点的输入,依此类推。为了说明步骤的顺序,图2给出了本文模型的总体结构。 图2 本文模型的总体结构 设pr为用户表示评分r∈[rmin,rmax]的概率,相关概率集的定义如下: P=(pr(1),pr(2),…,pr(k)) P∩(pr(k+1),pr(k),…,pr(0))=∅ (5) 式中:k表示用于反映用户意见的概率数;将等级r(1)表示为偏好的概率高于r(2)的概率,依此类推;符号O表示系统中可能的额定值数目。 如图2所示,该模型将每个输入实例X∈R|X|映射到相关表示A∈R|A|,表示为: Au=T(X=Ru)=(ru,i1,ru,i2,…,ru,i|l|) Ai=T(X=Ri)=(ru1,i,ru2,i,…,ru|U|,i) (6) 式中:X表示用户u的等级Ru的集合,或为项目i提供的等级Ri的集合。函数T(·)在pru,i∈P为真时,仅选择每个等级ru,i∈X。产生的Au和Ai根据每个用户u和项目i聚合如下: (7) 式中:Vu∈R概括了用户u的评级行为;Vi∈R近似于用户对一个项目i的偏好。式(7)的主要目标是反映用户对项目的乐观、中立或悲观偏好。 由于大数据的不同挑战以及评级矩阵的稀疏性,必须采用更复杂的机制来有效地处理大量数据,解决稀疏性问题。因此,对于每个Ru,模型仅启用来自用户u的单位Vu和由u评定的每个项目的单位Vi的连接,其中ru,i∈Ru且ru,i≠0。然后,将问题分解为一组子问题,每个子问题基于一组连续的目标函数进行优化。因为系统中的用户是独立的,该模型将问题分解为|U|优化子问题,表示为: (8) (9) 根据z的偏导数∂z/∂γu=0,每个用户u的启用单元之间的交互定义如下: (10) 式中:参数γu∈R表示最优值,它控制相对于用户u的单元之间的交互。 为了考虑每个用户u的个性化行为受到的影响。通过最小化损失函数直接估计参数βu: (11) 在函数g相对于参数βu的偏导数∂g/∂βu=0时,βu∈R最优值表示为: (12) 式中:参数βu的主要思想是根据用户的行为来调整预期的偏好。为了提供更适当的预测,必须根据最佳参数γu、βu和过去的偏好来更新每个用户u(Vu)的估计个性化行为。因此新目标函数可以表示为: (13) 同理,由∂f/∂ωu=0计算每个参数ωu: (14) (15) (16) 因此,通过考虑目标之间的权衡来执行估计过程。在数学上,此任务的公式如下: (17) 式中:O表示可能值的集合来估计B(x);min(Y(1))和max(Y(1))表示Y(1)的最小值和最大值。 (18) (19) (20) 用于改善用户意见的估计值D(x)可以表示为: (21) 式中:q(1)(x)、q(2)(x)是两个目标函数。q(1)(x)、q(2)(x)可以表示为: q(x)=[q(1)(x),q(2)(x)] (22) 基于式(4)-式(22),模型训练步骤如算法1所示。 算法1分布式推荐模型的训练步骤 输出:估计参数的RDD*。 2.利用式(5)确定相关概率集P={pr(1),pr(2),…,pr(k)}; 3.为每个用户u和项目i提供偏好设置Ru和用户意见Ri; 4.for ∀u和∀ido 利用式(6)将Ru、Ri表示为Au和Ai的形式; 利用式(7)近似用户u的评级行为Vu以及项目i的用户意见Vi; end for 5.for∀subproblemu和∀subproblemido end for 6.返回RDD*: 用户u对项目i的预测评分的计算方式如下: (23) 利用矩阵分解和随机森林模型来提高推荐质量,基本思想是将训练集中的每个已知评级ru,i表示为特征和标签。然后,将评级预测任务作为回归问题解决。 设C={(xj,yj),j=1,2,…,|C|}是训练数据集,|C|是非零等级的用户项目等级R的数量,xj∈Rβ+1和yj∈R分别表示实体j的特征和标签。 令β为矩阵分解模型的数量,主要目标是训练β矩阵分解模型,然后利用学习到的模型为训练集中的每个偏好ru,i生成一个表示: L(ru,i)=(xj,yj) (24) yj=ru,i 评级预测任务被视为回归问题,通过使用带有预定义标签的生成表示来训练机器学习模型来解决此问题。随机森林是一种有监督的学习方法,广泛用于回归和分类问题。因此采用随机森林来执行评级预测任务,在训练了随机森林之后,采用学习模型来预测未知的偏好。 所有的实验运行在16 Intel Xeon CPU和64 GB RAM平台。实验是在由两个节点组成的群集上进行的:一个主节点和一个从节点。每个节点都运行Ubuntu 16.04。同时,在相同条件下将本文方法与APRA[8]、FRAIPA[13]和CMII[14]几种推荐方法在Yelp、Movielens 10和Movielens 20M三个真实数据集[8]上的测试结果进行对比。这些方法是使用Apache Spark 2.1.0框架实现的。APRA是一种并行的近似推荐方法,采用随机抽样技术和特殊的学习过程来加速训练任务,用于处理大规模数据;FRAIPA将每个用户的评分行为和用户对每个项目的意见视为一组概率,然后利用估计的概率来预测偏好;CMII是一种基于混淆矩阵的推荐方法,将基于内容的聚类与协同过滤相结合,使用加权策略来预测偏好。 由于在实验环节中许多参数需要调整才能获得最佳的预测结果,对本文推荐算法做如下参数设置:分区数设置为Np=[8,16,24,32],相关概率的数量k=6,O=[-0.3,0.3],间隔为0.1。矩阵分解模型的数量参数β=3,每个分解模型的等级设置为10,学习率为0.05,执行训练任务的迭代次数为15。随机森林决策树数目设置为5。 MovieLens 10M和MovieLens 20M是一个真实世界的数据集,由明尼苏达大学的GroupLens研究小组收集,包含多个用户对多部电影的评级数据,及电影元数据信息和用户属性信息。MovieLens 10M由71 567个用户对10 000部电影,进行的1 000万个评级和100 000个电影标签。MovieLens 20M电影推荐数据集包含138 493位用户对27 278部电影的20 000 000项电影的评分和465 564个电影标签。Yelp数据集由6 685 900个交互组成,由1 637 138个用户表示,用于10个大都市地区的192 609个企业。由于原始数据是高度稀疏的,需要进一步处理数据集,保留至少30个偏好的项目和用户。最终数据集包含大约15 139个用户、27 307个项目和1 210 783个偏好。在测试过程中,根据现有研究工作中采用的方法对每个数据集进行拆分。将数据集随机分为两部分,其中80%的数据用作训练集,其余20%用作测试集。 为了评估推荐算法的性能,采用了均方根误差(RMSE)和均值绝对误差(MAE)两个指标用于测量预测精度: (25) (26) 对于本文方法,数据分区是一个重要步骤,通过确定分区数量来加速训练步骤。选择最佳的分区数量对于改善模型的性能至关重要。图3显示了MovieLens 10M和MovieLens 20M数据集上不同np值的计算时间变化。可以看出,计算时间对组数np的选择很敏感。对于MovieLens 10M,当np=16时,模型获得最佳性能;对于MovieLens 20M,当np=24时,模型可以大大减少计算时间。 图3 分区数量np对运行时间的影响 为了有效地评估本文模型的性能,将在三个数据集上的测试结果与其他方法进行对比。表1给出了在MovieLens 10M、MovieLens 20M和Yelp数据集上的实验结果,可以清楚地看到,本文模型在预测质量方面优于其他方法。 表1 不同推荐算法在三个数据集上的测试结果 本文针对大数据环境下的个性化推荐,提出一种分布式预测模型。它是基于Apache Spark设计的,可解决传统环境下的推荐算法效率低、计算成本高的问题。该模型采用数据分区策略用于加速大数据处理;基于较复杂的过程来表征用户的评分行为和项目的用户意见;将优化问题划分为一组独立子问题,每个子问题可以基于一系列连续的目标函数进行求解,并且对这些目标函数采用矩阵分解和随机森林技术,以并行和分布式的方式有效学习参数,克服了数据稀疏性问题。实验结果表明,本文算法在预测误差指标上明显优于其他推荐方法。
2 基于MF和RF的推荐方法

2.1 数据分区

2.2 模型训练

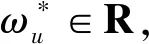




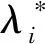
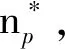


2.3 预测步骤
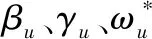
2.4 矩阵分解和随机森林

3 实 验
3.1 实验数据集和评价标准

3.2 结果分析


4 结 语
