结合多类特征融合与ICM目标函数优化的图像语义分割方法
2021-08-12杨秋菊
王 彤 杨秋菊
1(苏州高博软件技术职业学院信息与软件学院 江苏 苏州 215163)2(西南石油大学应用技术学院 四川 南充 637001)
0 引 言
场景解析也称为语义图像分割,它将图像划分为语义区域或对象,如山、天空、建筑等,近年来受到了广泛关注[1]。场景解析结合了检测、分割和多标签识别这三个传统问题[2],将预定义标签集中的对象类标签分配给输入图像中的每个像素(或超像素)是一个热门的研究领域。
目前,各种场景解析方法被相继提出,大致可分为三类。第一类是参数化方法,其使用自动上下文技术以学习图像中感兴趣类别的紧凑参数模型[3]。此方法可以学习参数分类器以识别物体(如建筑物或天空)。该类方法中,已有几种深度学习技术应用于语义分割,如文献[4]提出了基于卷积神经网络(CNN)的参数化场景解析算法,其中CNN旨在学习强大的特征和分类器以区分局部视觉细微差别。
第二类是非参数化方法,其目标是通过将图像的部分与标记图像的大数据集中的相似部分进行匹配来标记输入图像[5],其中类别分类器学习通常由马尔可夫随机场代替,一元势能通过最近邻检索来计算。
在非参数场景解析方法中,基于在图像中的不同像素之间编码的关系(依赖性),可分为三种类型。第一种类型包含对每个像素独立地进行分类来解决像素标记问题的方法。文献[6]提出的场景解析方法使用包含完全注释图像的大数据集为输入图像选择最近邻居的子集,使用SIFT流算法在查询图像和每个最近邻居之间建立密集的对应关系[7],然后使用在像素上定义的马尔可夫随机场(Markov Random Field,MRF)将注释从检索的子集传送到输入图像。但此类方法的计算成本高且效率低,导致其无法在应用程序中运用。第二种类型基于成对MRF或条件随机场(Conditional Random Field,CRF)模型[8],其图中的节点表示与像素相关联的语义标签,并创建电势以定义系统的能量,促使外观相似的相邻像素采用相同的语义标签。但此类方法对复杂成对术语的学习和推理成本较高,且具有局部性。第三种类型是像素被分组为片段(或超像素),并且为每个组分配单个标签[9]。文献[10]提出了一种称为Superparsing的高效非参数图像解析方法,将MRF应用于超像素而不是像素,然后基于超像素相似性将标签从一组相邻图像转移到输入图像。文献[11]提出了一种使用混合模型和多个CRF的基于本体的语义图像分割,将图像分割问题简化为分类任务问题,其中具有CRF模型的基于片段的分类器生成大规模区域,然后利用区域的特征来训练基于区域的分类器,为每个视觉特征分别将图像区域分类为合适的标签。
第三类是非参数模型与参数模型集成方法,如文献[12]提出了一种准参数(混合)方法,其集成了基于KNN的非参数方法和基于CNN的参数方法;文献[13]开发了一种新的自动非参数图像解析框架,以利用参数和非参数方法的优势。
虽然参数化方法在场景解析方面取得了巨大成功,但其在训练时间方面存在一定的局限性,且在添加新的训练数据集时需要重新训练模型。相比之下,对于非参数方法,当扩展语义类别标签的词汇时,不需要做特殊的调整。
为此,遵循非参数方法,本文提出了一种结合多类特征融合(Multi Feature Fusion,MFF)与ICM目标函数优化的图像语义分割方法,主要创新如下:
(1) 现有大多数方法从训练数据集中为查询测试图像检索一些类似图像的成本较高且效率低。故提出一种新的基于全局一致性误差的几何检索策略,用于从包含完全分割和注释图像的数据库中选择最近邻居,快速将区域图或输入图像的分割与数据集中每个图像的区域图匹配。
(2) 现有方法中对复杂成对术语的学习和推理成本较高,而本文方法采用一种新的基于能量最小化(Energy minimization,EM)的方法,即多特征融合语义分割模型(EM-MFF),将多类型特征融合到能量或目标函数,并根据全局适应度函数为每个区域分配类别标签,同时限制参数数量,可集成场景中的对象的更多信息,降低推理成本。
(3) 现有的语义分割模型一般需要大型数据集来训练高精度分类器,工作量大,而本文模型专用于以有限数量可用图像为特征的小数据集,采用微软研究剑桥数据集(MSRC-21)和斯坦福背景数据集(SBD)进行实验论证,结果表明了该方法的可行性和准确性。
1 方法设计
本文方法主要将图像I分解为一个未知的几何区域数K,然后通过迭代优化一个多特征的能量函数以识别图像类别(即树、建筑物、山峰等),进而评估所提方案的质量。该系统框架如图1所示,包括四个步骤:区域生成创建一组区域,用于给定的输入图像;几何检索集通过基于全局一致性误差(Global Consistency Error,GCE)测量的新匹配方案从整个数据集中选择图像的子集;区域特征为每个区域提取不同类型的特征,包括颜色、纹理和图像位置;图像标记通过使用能量最小化方案为每个区域分配对象类标签。

图1 系统框架
可见,给定输入图像(a),通过使用GCEBFM算法生成其区域集(b),然后利用GCE标准从完整数据集中检索相似图像(c),为输入图像提取不同的特征(f)和检索到的图像(d),结合基于标记的分割语料库(e),使用基于ICM的能量最小化将单个类别标签分配给每个区域(g)。
1.1 区域生成
区域生成即由基于GCE的新预分割算法生成一组段(区域),该算法通过组合由标准K均值算法生成的多个和最终弱分割图来获得最终精细分割。将GCE算法应用于12个不同的颜色空间,以确保分割集合的可变性。
由于使用由过度分割产生的预定义超像素,提供的边界与真实区域边界不一致,且在大多数情况下,对象被分割成许多区域,以致无法进行精确分解图像。为此,使用GCE算法生成大区域,允许每个区域导出全局属性,降低整个模型的复杂性和内存需求。
1.2 几何检索集
本文方法使用与查询图像类似的图像子集而不是使用整个数据集,更适用于标签任务。为了找到相对较小且有趣的图像集,使用GCE查找区域图与输入图像的分割之间的匹配,以及数据集中每个图像的区域图。

(1)
式中:|r|表示像素集合r的基数;表示差异的代数运算符。结合LRE能够使所有局部细化都处于同一方向,而每个像素pi需要计算两次,则可得到全局一致性误差为:
(2)
式中:GCE*∈[0,1],GCE*=0表示分段RI和RM之间的最大相似度,GCE*=1表示两个分段之间不匹配。
根据GCE值将查询图像按升序排列,并对整个数据集T的所有图像进行排名。以此消除具有较高GCE值的无用图像,并且可以从整个数据集T中选择图像子集M作为检索集。
1.3 区域特征
为了执行标记过程,需要提取每个区域不同的特征来定义该区域,所提方法提取颜色、纹理、位置这三类特征。
1) 颜色。颜色特征是用于描述图像整体或其部分表面属性的特征,通常来说,颜色特征的提取是基于像素点的,而统计是基于全局或者部分,因此具有旋转和平移不变性,这导致颜色特征无法完全展现关键点的颜色分布。
本文方法采用对立颜色空间SIFT描述子[15](Opponent Color SIFT,OCSIFT),以保证获得特征的稠密性和局部性,以及具备几何与色彩不变的双重性能。OCSIFT由原始RGB的三个通道组成,其通道O3为亮度,通道O1和O2为颜色。
(3)
由于O1和O2中存在减法,当三个通道的值相同时其值为0。OCSIFT使用SIFT算子描述对立颜色空间的全部通道,且对立颜色空间SIFT的性能优于其他颜色空间的SIFT。
2) 纹理。为了量化图像中不同区域的感知纹理,文献[16]提出原始LBP算法,通过编码中心点的像素值与其相邻的像素值之间的差异以表示图像中包含的微观模式的统计量。由于LBP算法获取存有光照变化和随机噪声的图像特征效果不太理想,为此LDP算法被提出并予以应用[17]。
LDP算法通过将中心像素点与8个Kirsch掩模作卷积运算,获得相应的边缘响应值,再将绝对值稍大的前k个边缘响应值的二进制位设为1,剩下8-k个值设为0。该算法具体计算方法为:
(4)
式中:mk为第k个最大的边缘响应值,计算中一般令k=3。
3) 位置。位置特征用来描述像素点在图像中所处于的坐标信息,由于其坐标形式庞大的特点,一般的K-means聚类算法无法适用。
本文方法采用基于格论的CBL(C1usterbase on lattice)聚类方法[18],可在不增加空间复杂度的条件下有效提高聚类精度。将图像的宽和高进行m和n等分,把图像分割成m+n个格子,处于同个格子的像素点就是同一聚类。令Iw和Ih分别表示图像的长与宽,(i,j)表示图像中任意像素点,该点在x和y方向上的聚类(i,f)cluster_x和(i,f)cluster_y分别为:
(5)
(6)
如此,可以得到一个二维的聚类中心。实验取m=n=12,并使用一维值(i,f)cluster表示二维的聚类中心:
(i,f)cluster=(i,f)cluster_x×m+(i,f)cluster_y
(7)
1.4 图像分类
1) 结合多特征的语义分割模型。在提取用于描述区域的特征描述符并给出可用的标记分割语料库之后,通过优化全局适应度函数,测量所生成的解的质量,将单个类标签分配给每个区域。
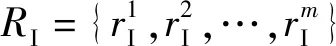
(8)

2) 能量函数的优化。将提出的多特征语义分割模型表述为包含非线性多目标函数的全局优化问题。为了达到该能量函数的最小值,可以利用基于不同优化算法的近似方法找到最佳解决方案,如遗传算法、模拟退火算法等,但计算时间长。
为了避免上述问题,采用了迭代条件模式(Iterative Conditional Mode,ICM)方法,即高斯-塞德尔松弛,其中像素一次更新一个,能够快速收敛[19]。ICM算法的核心是设定一个观测图像y,及像素点s邻域∂s中全部点的当前预测x∂s,之后统计像素点s处的标记概率:
P(Xs=xs|y,XS/s=xS/s)=P(ys|xs)P(Xs=xs|X∂s=x∂s)
(9)
式中:xS/s为图像中除了像素s外其余像素点的标记。
基于ICM的EM-MFF伪代码如算法1所示。
算法1基于ICM的EM语义分割模型算法
输入:待标记图像I、k图像集{Γk}(k≤K)、k个语义分段集{Sk}(k≤K)。
1.将图像I分割为不同的相干区域RI
2.使用类标签集合ε({Sk}k≤K)中的随机元素为每个区域ri∈RI分配类别标签
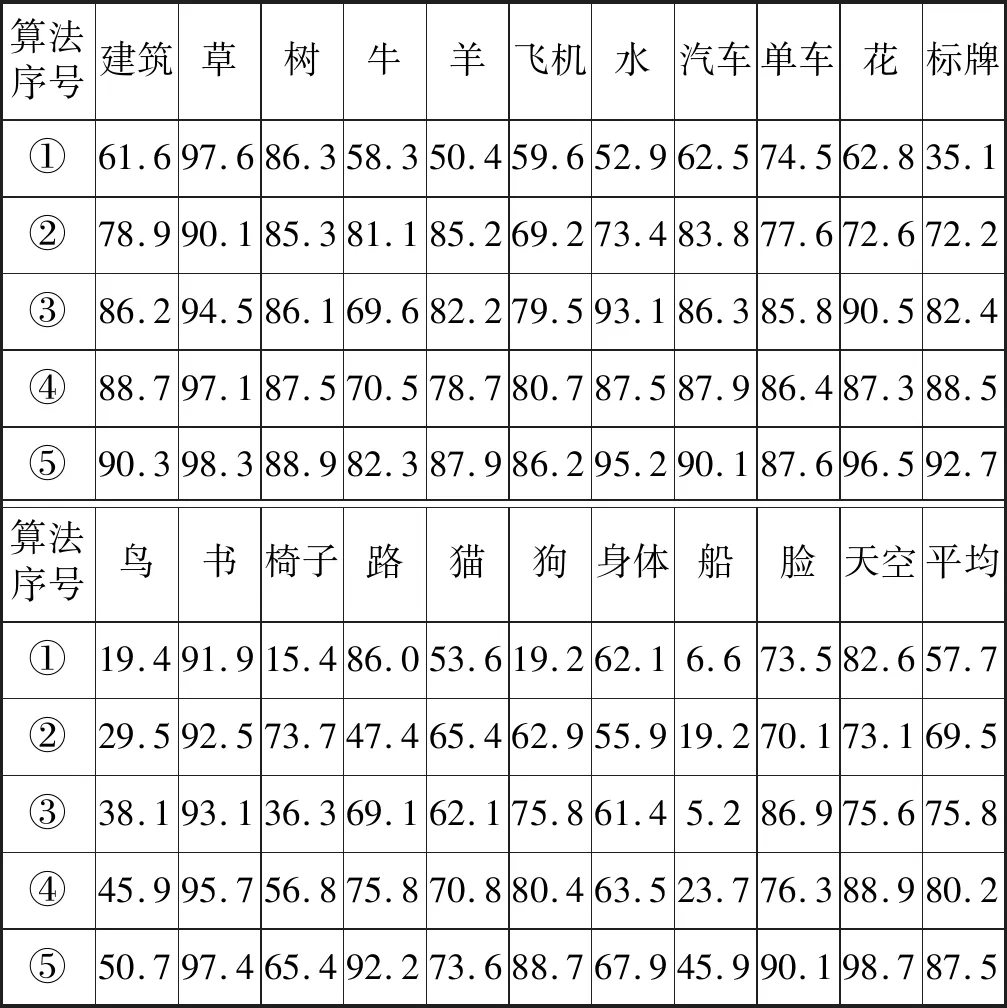
3.whilep 4.for每个区域ri∈RI执行 5.根据类标签集合ε中的均匀分布,绘制新的标签y 6.对每一个像素点s,通过最大化P(ys|xs)来初始化x 7.s≤S,通过最大化式(9)更新xs 12.end if 13.end for 14.s←s+1,p←p+1 15.end while 为了评估模型的性能,本文将其与不同的非参数方法进行了比较,并在两个具有挑战性的语义分割数据集(微软剑桥研究院数据集和斯坦福背景数据集)上进行了测试。 1) 微软剑桥研究院数据集(MSRC-21)是目前种类最多且标注最完善的图像语义分割数据库之一。它包含了591幅彩色图像,并对23个对象类(建筑、草、树、牛等)进行了相应的地面真值标记。在23个对象类中,只有21个类是常用的。未使用的标签是(void=0,horse=5,mountain=8),因为其背景或训练样本太少。 MSRC-21数据集如图2所示,其第一行为原始图像,第二行为原始图像对应的手工标注图像,使用不同的颜色代表不同的目标,第三行显示了颜色标签的类别含义,其中黑色代表空类。 图2 MSRC-21语义分割数据集 2) 斯坦福背景数据集(SBD)包含一组从现有公共数据集导入的室外场景图像,如图3所示。该数据集中的每个图像都至少包含一个前景对象。数据集按像素进行注释(水平位置、像素语义类、像素几何类和图像区域),以评估语义场景理解的方法。 图3 场景标注 从两个层次对EM-MFF模型进行性能对比分析,即全局每像素精度(Global Pixel Accuracy,GPA)和每类平均准确度(Average Class Accuracy,ACA)。其中全局每像素精度表示正确标记的像素的总比例,其算式为: (10) 式中:v(·)为指标函数;n为输入图像中的像素数;yi为算法预测的像素i的标签;li为像素i的地面真实标签。 每类平均准确度表示每个类别中正确标记的像素的平均比例,其算式为: (11) 式中:|C|为输入图像中的类数;nb为数据集中的图像数;∧为逻辑运算符号。 1) 本文模型在MSRC-21数据集中的实验结果分析。为了在MSRC-21数据集上验证所提模型,采用留一法的评估策略。即对于每幅图像,将其用作查询图像,并根据数据集中的其余图像对区域进行分类。 为了保证基准测试结果的完整性,本文算法的权值参数(α1、α2和α3)通过使用局部线性搜索过程的可行范围参数值([1,2])与固定步长为10来进行整体优化。经过反复验证发现,α1=1.83、α2=1.53和α3=1.44是模型中产生最佳性能的可靠超参数。 本文模型属于非参数方法,将其与文献[10]提出的超解析模型与文献[11]提出的CRFTree模型,以及与参数方法中周期性CNN[4]与自动上下文[3]模型进行相应的性能对比分析。 如表1所示,EM-MFF的性能优于非参数超解析方法,其GPA和ACA得分分别为0.73和0.62。此外,与目前最新的参数化方法相比,本文方法可提供良好的结果,且模型训练简单、成本低。与非参数方法相比,参数场景解析方法在准确性方面优势不明显,且需要大量的模型训练,对于开放数据集不太实用。 表1 本文模型在MSRC-21数据集上的GPA和ACA得分 表2显示了从MSRC-21数据集得到的实验结果。可以看出,对于草地、飞机、羊和书等类别的准确性得到了更好的结果,其精度高于80%。但是,对于17.4%的椅子类别,其准确性较低,该类别经常与鸟类混淆,因为这两个类别在颜色和纹理上具有相似性。 表2 对MSRC-21类数据集的分割精度(%) 此外,将本文模型与超解析、周期性CNN、自动上下文和CRFTree(FL)做对比,在MSRC-21数据集上的分类准确度如表3所示,各模型定性比较如图4所示。 表3 五种方法在MSRC-21数据集上的分类准确度(%) 图4 在MSRC-21上EM-MFF和其他算法的图像分割结果示例 图5显示了本文方法生成的MSRC-21示例结果。 图5 EM-MFF模型在MSRC-21数据集上获得的示例结果 检索集的大小也会影响模型准确度,因此通过改变K值以验证模型效果,如图6所示。测试结果表明当K=197(数据集的1/3)时,本文模型的准确度最佳。 图6 MSRC-21数据集的检索集大小K值变化的影响 2) 本文模型在SBD数据集中的实验结果分析。在SBD数据集上验证了本文模型,并采用了相同的评估策略,即留一法,但对于整个数据集,使用了与MSRC-21数据集的训练集上固定的参数相同的值。本文模型的GPA和ACA得分如表4所示。本文模型的GPA值为0.61,ACA值为0.57,不同方法下仍然具有竞争力。但与在MSRC-21数据集中的值相比,效果不是很好,这是因为SBD数据集包含一个前景类,其引用了不同类型的对象,大大增加了类内的可变性。 表4 本文模型在SBD数据集上的GPA和ACA得分 表5显示了本文模型在SBD数据集中的精度值。可以看出对于天空和草地类,在类别准确性方面会产生更好的结果,其值高于80%。相反,对于山地级别,其精度较低。 表5 SBD数据集分割的分割精度(%) 此外,将本文模型与超解析、自动上下文、周期性CNN和CRFTree(FL)的对比,在SBD数据集上的分类准确度如表6所示。 表6 五种方法在SBD数据集上的分类准确度(%) 为了测试迭代优化过程的收敛性,通过用不同的迭代次数的优化算法评估了所提出的模型,MSRC-21数据集上的GPA和ACA渐近结果如图7所示。可以看出Tmax=100时模型性能最佳。 图7 不同最大迭代次数下,EM-MFF模型的绩效指标变化 所提出模型的计算复杂度取决于两个因素:数据集中的图像数量和使用的标准数量(组合为全局能量函数)。在MSRC-21数据集上,对于Intel 64处理器内核i7-4800MQ,2.7 GHz,8 GB RAM内存和在Linux上运行240×240的图像的非优化代码,执行时间平均需要5~6 min。更准确地说,标记过程需要0.14 s,几何检索步骤需要0.32 s。然而,所提模型的计算时间主要由205 s的区域生成代码和171 s的特征提取所占用的时间。前者可以通过并行化实现而减少,而通过仅执行一次提取,然后将提取的特征存储在数据结构中,可以加速后者。所提模型与其他四种模型的分割时间对比如表7所示。 表7 计算时间对比结果 续表7 为解决图像语义分割的问题,本文提出了一种新颖且易实现的结合多类特征融合与ICM目标函数优化的图像语义分割方法。通过使用基于称为全局一致性误差的几何检索策略,从包含完全分割和带注释的图像的数据库中选择了最近的邻居。此外,EM-MFF模型的成本函数有效地结合了不同全局非参数语义似然能量项,并将多类特征融合到能量或目标函数中,以集成有关场景中可能存在的对象的更多信息。在MSRC-21和SBD数据集上对该方法性能进行了实验,结果表明其具备可行性和较高的分类准确度,且多特征融合可以显著改善场景解析的最终结果。此外,本文方法无需大数据集来训练高精度分类器,节约训练成本。 本文方法仅考虑了颜色、纹理和位置这三种特征,未来工作将结合更多的特征,在不同的几何和语义抽象级别进一步提高分类准确性,以增加所提方法的普适性。

2 实 验
2.1 数据集


2.2 评估指标
2.3 实验结果









2.4 计算时间


3 结 语
