基于混合神经网络的开源社区软件开发者人力资源价值预测
2021-08-12汤佳杰曹永忠朱俊武
汤佳杰 曹永忠 朱俊武 顾 浩
(扬州大学信息工程学院 江苏 扬州 225127)
0 引 言
随着社会经济取得前所未有的发展,人力资源在推动社会经济发展中的作用不断提高。特别是21世纪以来,作为国家竞争力来源的人力资源已上升至国家战略层面的高度。但是,在如此激烈的竞争环境下,人力资源价值评估理论和实践却相对滞后,导致企业在招聘时需要通过多重环节对应聘者进行考核来确定其各项技能水平,整个招聘过程包括笔试、面试等预估环节将长达数月;同时,对企业内部已招聘的员工的人力资源价值没有进行量化分析,以至于许多经过企业培养,具有丰富管理经验及高新技术技能的员工因自身价值得不到体现而另谋出路。此现象在人力资源密集型、知识密集型的IT行业中十分常见,因此对IT行业中软件开发者的人力资源价值进行正确评估就显得尤为重要。
近几年以来,以大数据、云计算、人工智能、物联网、区块链等时代前沿技术为基础的数字科技正在不断加速各行各业的产业融合与转型,不断改变着人们的生活方式。因此,作为前沿技术开发者的高技术软件开发者被各企业所争抢。开源社区作为各层次水平的软件开发者的聚集地,其中积累了大量的软件开发者人力资源数据、软件开发数据及软件开发者日常活动数据。为了充分利用这些数据,GitHub根据注册用户在社区中的日常行为数据开发了“Discover repositories”向使用者推荐相关存储库。除此以外,我们仍可以从这些数据中挖掘高水平或高潜力的软件开发者信息,并用于公司招聘。
然而,GitHub并没有专门为招聘人员提供相关信息来推断软件开发者的技能水平。因此,为了评估开发人员的质量,招聘人员必须手工检索相应软件开发者的个人信息及存储仓库。Marlow等[1]认为,招聘人员必须投入大量精力和时间来收集和评估GitHub上软件开发者展示的某些相关技能方面信息。因此,本文将重点利用GitHub用户信息及其存储库相关指标来解决招聘者在招聘软件开发者时无法评价其价值的问题,为企业的高效招聘提供一种新的解决方案。
1 相关理论与方法
人们对人力资源研究的热情始于美国经济学家舒尔茨和贝克尔,他们提出的人力资本理论在经济学中具有举足轻重的地位。人力资源价值评估主要是根据被评估者自身现有条件,并参考在未来可能创造的价值,反映人力资源在当前时间点的劳动能力。从人力资源个体价值的角度出发,国内外一些学者先后提出了一系列计量模型。其中作为所有模型基础的理论是马克思的劳动价值论[2],其认为人力资源成长过程中积累的知识、技能和经验等因素可作为人力资源价值的组成部分,并在工作时将其中的价值转移到商品中。
目前,国内外人力资源个体价值评估方法分为两种:第一种为传统管理学评估模型,这些模型通过统计人力资源价值形成过程中的投入,并把工资作为评价个体人力资源价值的方式,如未来工资报酬折现法[3-4]、人力资本加工成本法[4]、随机报酬价值法[5]和完全价值测定法[6]等;第二种为机器学习的方法,如支持向量机、神经网络和深度学习等。文献[7]在问卷调查选择人力资源价值影响因素的基础上,对蓝领阶层价值影响因素进行聚类,通过聚类把人员划分为5个重要程度并针对情况对相应人员提出激励措施。文献[8]通过BP神经网络对电力企业员工绩效做出评估,首先由评估人员对设定的17个指标打分,把分数作为神经网络输入向量,并把当期考核结果作为输出向量对神经网络进行训练,验证了神经网络评估的有效性与高效性。文献[9]通过Elman神经网络对历年员工创造价值、员工人数、员工离职率的学习,预测当年可创造价值与员工离职概率,为企业人力资源配置的研究和实践提供了一种新的方法,具有一定现实意义。文献[10]设计了19项可能会为高校人力资源带来风险的因素,建立了高校人力资源风险评估模型,并通过RBF神经网络对风险做出分类评估,实证研究识别错误率为6%,能够较好地识别高风险样本。
近年来,随着计算机硬件的发展,深度学习也再次受到人们的关注,卷积神经网络及循环神经网络作为其中的代表,被广泛应用于各种领域,如计算机视觉[11]、自然语言处理[12]、语音识别[13]、机器翻译[14]、医疗[15]和金融[16]等领域。为了完成以上各项任务,构建的神经网络规模不断增大,并且为了获得更好的性能,多种神经网络结构堆叠使用。文献[17]构造了CNN-LSTM结构的神经网络,通过CNN提取样本特征,输入LSTM中预测设备故障,通过一周内采集的60万组数据对网络进行训练,预测值的准确率达83.27%。文献[18]提出了一种基于CNN-LSTM框架的绘画作品作者分类方法,对中国画的作者进行预测分类,给出其可能作者及其概率,较深度卷积神经网络精确率、召回率、F1-score分别提高8.45%、8.08%、8.27%。
综上,只要确定了合理的价值评估体系并将之科学地转换为量化的变量值,在样本足够的情况下,神经网络可以较准确地完成软件开发者人力资源价值评估。但仅仅知道软件开发者当前价值是不够的,招聘者无法预知其未来价值,所以需要使用LSTM神经网络对其未来价值进行预测。因此,本文提出一种基于CNN-LSTM混合神经网络的软件开发者人力资源价值评估及预测方法。
2 开源社区软件开发者价值评估要素
2.1 软件开发者价值评估指标体系构建
文献[19]研究了GitHub中流行的项目及受欢迎的软件开发者,使用PageRank算法评估用户的影响力,并根据影响力向招聘人员推荐GitHub软件开发者。文献[20]研究了存储仓库的流行度与其使用的编程语言、特征之间的关系,并使用存储仓库的Fork与Watch数来确定其流行程度。研究发现大多数对GitHub的研究单一地集中于用户或项目,而少数联合研究的多为项目推荐系统,如文献[21]基于用户行为及其关注项目特性构造用户行为矩阵,通过TF-IDF统计源代码文件和项目文档中每个单词,获取项目关键词并构造相似性矩阵,通过矩阵相似性向用户推荐相似项目。
鉴于未有GitHub软件开发者人力资源价值的相关研究,本文从软件开发者现有价值和未来价值分析了GitHub软件开发者价值的影响因素,将影响因素分为编程能力、项目管理能力、学习能力、团队合作能力和技术影响力,并提出敬业度概念,建立如图1所示的软件开发者价值评估指标体系。
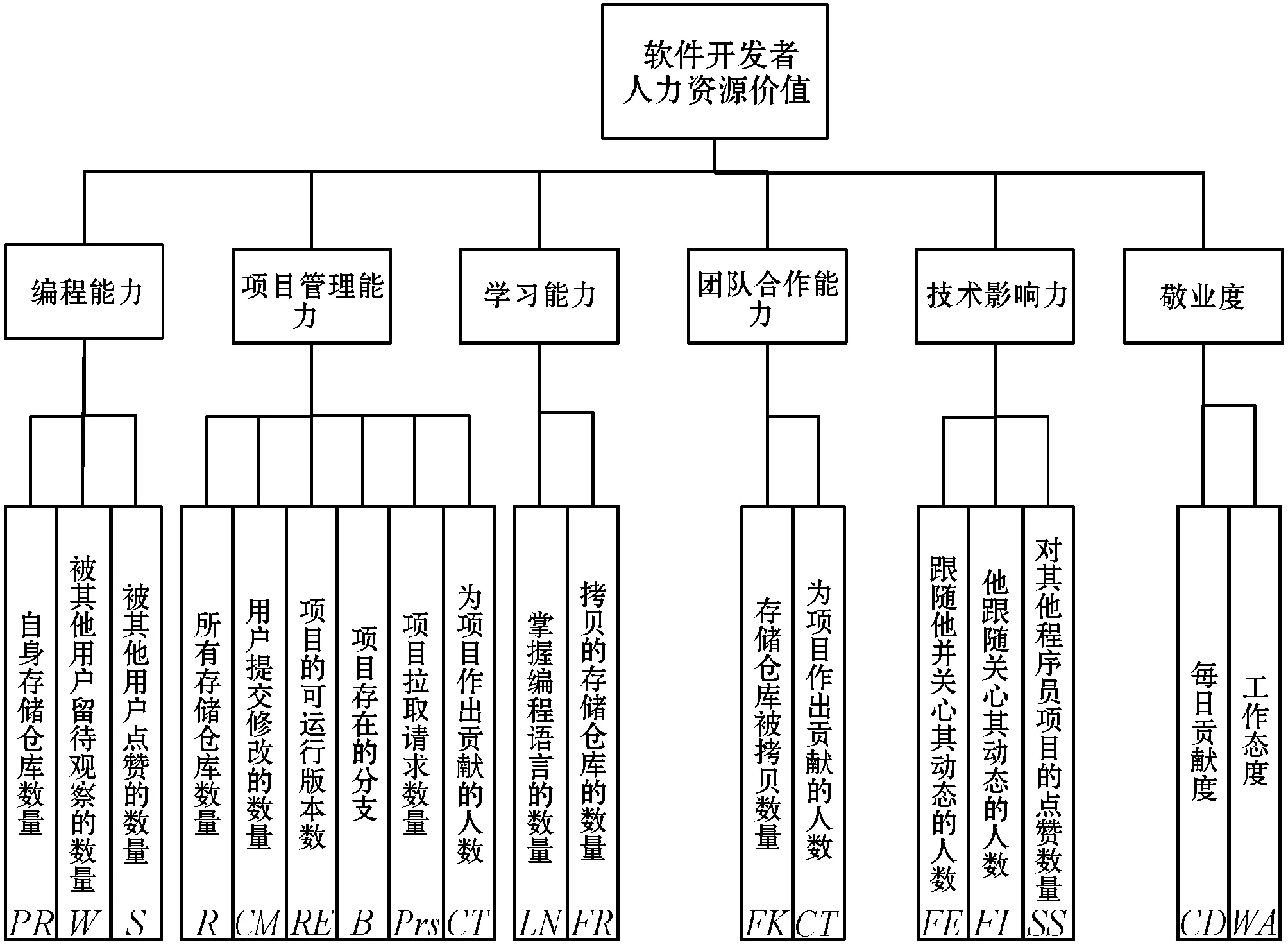
图1 开源社区软件开发者人力资源价值评估体系
定义1编程能力PA:表示为一个三元组PA=(PR,W,S)。其中:PR表示软件开发者自身创建的存储仓库的集合,在一定程度上创建的存储仓库越多编程能力越强;W表示存储仓库被标记数的集合,被标记数量表示有多少软件开发者对此仓库感兴趣,可以反映该存储仓库的质量与创新度;S表示存储仓库被其他软件开发者赞同数的集合,其反映内容与W相同。如果PR=∅,则W、S均为∅。
定义2项目管理能力MA:表示为一个六元组MA=(R,Prs,CM,RE,B,CT)。其中:R表示软件开发者所有存储仓库的集合;Prs表示项目拉取请求数量的集合,其表示仓库创建者对其他软件开发者提交修改的审核情况,数量越多,管理能力越强;CM表示存储仓库提交修改次数的集合;RE存储仓库拥有版本数的集合;B表示存储仓库拥有分支数的集合;CT表示为存储仓库作出贡献的人员数的集合,为项目作出贡献的人越多,管理者要审核的代码就越多,其管理能力也就越强。
定义3学习能力LA:表示为一个二元组LA=(LN,FR)。其中:LN表示软件开发者所掌握的编程语言集合,所掌握的编程语言反映软件开发者所能完成的工作领域,越多表示学习能力越强;FR表示拷贝的存储仓库的集合,拷贝的仓库需要时间熟悉其代码构成,软件开发者作出贡献的拷贝仓库越多,其学习能力越强。
定义4团队合作能力TA:表示为一个二元组TA=(FK,CT)。其中:FK表示存储仓库被拷贝数的集合,数量越多,仓库拥有者与其他软件开发者合作的概率越大;CT表示为存储仓库作出贡献的人员数的集合,其数量越多,表明为该仓库作出贡献的团队成员越多,仓库拥有者与其他软件开发者的合作就越多。
定义5技术影响力I:表示为一个三元组I=(FE,FI,SS)。其中:FE为关注该软件开发者的用户集合,关注该软件开发者的人数越多,表示越多的软件开发者认为其技术水平高超;FI为该软件开发者关注的用户集合,表示该软件开发者认为其技术值得学习;SS为该软件开发者被其他软件开发者赞同的信息集合,表示其对这些存储仓库的认可。
定义6敬业度LY,分为每日贡献度CD、工作态度WA。敬业度为二元组LY=(CD,WA),其中:WA表示软件开发者活跃天数占全年天数的比例,活跃天数越多表示其对工作越满意,其工作态度越端正;CD表示软件开发者每日贡献占全年活跃日平均贡献次数的比例。CD=(EC,AD),WA=(AD),其中:AD表示软件开发者在一年内的活跃天数;EC表示软件开发者每日贡献次数的集合。
(1)
(2)
LY=CD×WA
(3)
定义7软件开发者人力资源价值为七元组V=(P,PA,MA,LA,TA,I,LY)。其中:P表示待评估价值的软件开发者;PA表示软件开发者的编程能力,即项目经历的集合;MA表示软件开发者项目管理能力;I表示软件开发者的技术影响力;LA表示软件开发者的学习能力;TA表示软件开发者的团队合作能力;LY表示软件开发者的敬业度。V表示软件开发者的价值分类的集合。
2.2 数据获取及预处理
本文数据集为GitHub中真实用户信息,首先根据GitHub的advanced search搜索找出各个用户、用户项目之间的URL链接关系,再找出网页中存放所需数据的HTML标签,之后使用Python编写爬虫程序,获取整个网页结构。使用Beautiful Soup解析网页HTML标签,获得标签中数据,同时记录数据采集时间,本文中采集的数据集记录了部分软件开发者连续2年每日各项属性值的变化情况。
研究发现GitHub中软件开发者人数与其价值呈现幂律分布,即大多数软件开发者在GitHub中没有贡献,少数软件开发者贡献占据总贡献的80%,所以爬取的数据样本分布不均衡,为了解决这一问题,本文使用SMOTE算法[22]对训练样本进行扩充。
由于采集的17种参数大小范围都不同,为了防止大数吞小数的情况发生,同时为了加快模型的收敛速度与评估准确度,所以需要对数据进行归一化处理。本文把样本值与样本特征最大值的比值作为输入,计算公式如(4)所示,计算后,样本特征各数值将会在[0,1]范围之间。
(4)
式中:Xi表示某组样本的输入值;X和Xmax分别表示特征真实值和特征的最大值。
本文采用最小-最大规范化方法归一化后的17种输入特征来评估软件开发者当前的价值,并根据招聘人员对软件开发者的招聘欲望作为软件开发者价值,把软件开发者价值分为5类,如表1所示。
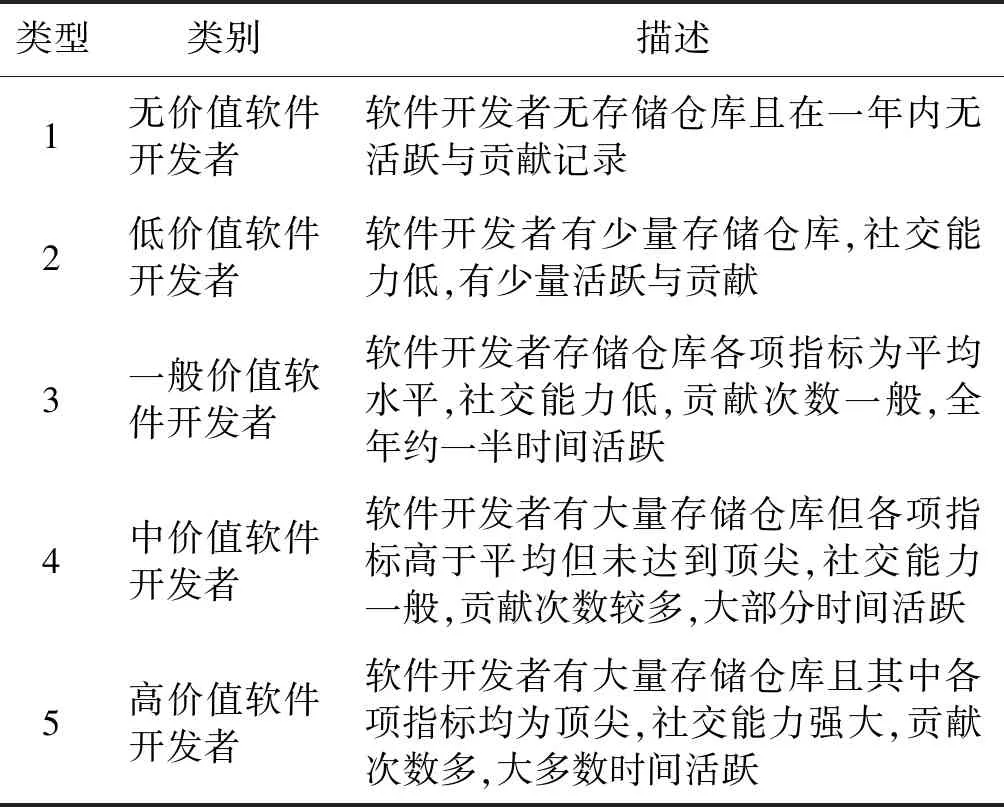
表1 软件开发者价值类别说明
3 价值评估模型
3.1 模型搭建
本文构建了包含一个卷积层、一个池化层、一个全连接层、一个输出层的卷积神经网络,因为输入数据维度较低,所以不需要过于复杂的网络结构。首先卷积层经过卷积核提取出不同的特征,再经过池化层的最大池化使得后续计算复杂度降低并提取样本主要特征。因为评估样本数据量有限,为降低过拟合风险,引入池化层Dropout[23],以此增加可训练模型数量。最后通过全连接层及Softmax分类器输出层得到软件开发者所属价值类别的概率,并反归一化为对应类别。类别数据同时与对应的日期信息作为特征输入构建的LSTM神经网络中预测软件开发者未来价值。本文采用的网络模型结构如图2所示,其中:Ti表示输入的第i种元素;T表示为此组数据采集时间。
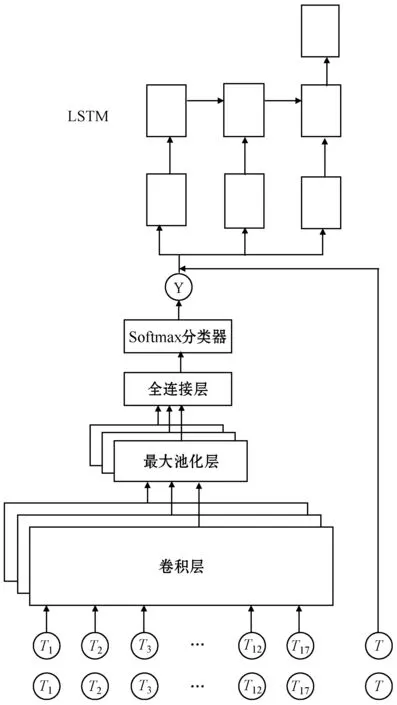
图2 混合神经网络结构
3.1.1卷积神经网络
输入样本Xi∈V包含17个元素,设卷积核尺寸为F,步长为S,补零层数为P,卷积核个数为N,则经过卷积后的特征图大小为:
(5)
对于每一个卷积层的神经元i:
neti=Xi×Fi+bi
(6)
outi=f(neti)=max(0,neti)
(7)
式中:neti表示卷积核输出的第i个元素;Fi表示卷积核的第i个元素;bi表示卷积核的偏置;f表示卷积层的ReLU激活函数。
池化层使用最大池化,设池化尺寸为Q×1,步长为S,那么卷积后每个特征图对应的池化输出大小为:

(8)
经过池化层的降维,然后再经过全连接层的计算,最后通过输出层的Softmax分类器,得到软件开发者对应每一类价值的概率,五类概率总和为1,其中概率最大的为软件开发者对应的价值类别。
模型使用反向传播算法进行训练,通过不断的迭代使误差函数收敛到最小,本文使用的误差函数为交叉熵损失函数,公式如下:
(9)
式中:ai表示实际输出;yi表示期望的输出;C表示误差。
模型通过Adam优化器[24]进行优化,该算法基于梯度的一阶矩估计与二阶矩估计计算更新步长,结合AdaGrad和RMSProp优化算法的优点,使得参数更新不受梯度变化影响,且能够自动调整学习率。首先计算时间t时刻的梯度:
gt=▽θJ(θt-1)
(10)
其次计算梯度的指数移动平均数,更新有偏第一矩估计和有偏二阶原始矩估计,指数衰减率β1=0.9,β2=0.999。
mt=β1mt-1+(1-β1)gt
(11)
(12)
然后计算偏差修正的一阶矩估计和偏差修正的二阶矩估计:
(13)
(14)
最后用以上计算出来的值更新模型的目标函数θ,初始学习率设置η=0.001,ε=10-8。
(15)
算法流程如算法1所示。
算法1软件开发者价值评估算法
输入:数据样本训练集U={X1,X2,…,X992},测试集T={X993,X994,…,X1 416},其中Xi=(PR,W,S,R,CM,RE,B,Prs,CT,LN,FR,FK,FE,FI,SS,EC,AD,V),V∈{1,2,3,4,5},ε,学习率η,迭代次数E,卷积核FC,卷积核个数N,卷积步长SC,池化窗口FS,池化步长SS,指数衰减率β1、β2。
输出:软件开发者价值类别概率V′。
1.T←SMOTE(U);
//均衡扩充样本
2.form←1 to length(T) do

//最大最小化归一
4.Yi,i=m←one-hot(V);
//样本标签转化为独热编码
5.end for
6.fore←1 toEdo
//多次迭代训练网络
7.form←1 to length(U) do
//训练集训练
8.forn←1 toNdo
//不同卷积核的训练

//一维卷积

//激活函数
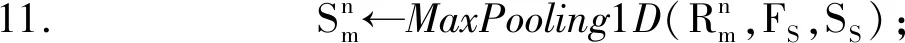
//最大池化
12.end for

//池化展平

//全连接层

//SoftMax分类器
16.Lm←Cross_Entropy_Loss(Yi,Ym);
//交叉熵损失函数
17.Adam(β1,β2,η,ε);
//Adam优化器更新参数
18.end for
19.end for
20.forn←1 to length(T) do
//测试集评估
21.Yn←trained_CNN(Tn);
//训练后CNN测试集样本评估价值
22.V′←decode(Yn);
//独热编码解码为对应价值类别
23.acc,recall,fscore←compare(V′,Tn.V);
//样本真实值与评估值计算评价指标
24.end for
3.1.2LSTM神经网络
使用训练完成的卷积神经网络对软件开发者历史价值做出评估,结果随对应时间输入LSTM神经网络中。LSTM通过神经元中的输入门、遗忘门、输出门来控制神经元对历史信息的记忆与遗忘,使得神经网络能够学习序列中的长期依赖关系。
输入门:
it=σ(Wxixt+Whiht-1+Wcict-1+bi)
(16)
遗忘门:
ft=σ(Wxfxt+Whfht-1+Wcfct-1+bf)
(17)
当前时刻的单元状态:
ct=ftct-1+ittanh(Wxcxt+Whcht-1+bc)
(18)
输出门:
ot=σ(Wxoxt+Whoht-1+Wcoct-1+bo)
(19)
ht=ottanh(ct)
(20)
式中:Wxi、Wxf、Wxcv和Wxo分别表示输入门、遗忘门、当前单元状态和输出门第i层权重矩阵;xt、ht-1和ct-1分别表示当前时刻网络的输入值、上一时刻的输出值和上一时刻的单元状态;bi、bf、bc和bo分别表示对应门的偏置;σ为Sigmoid非线性函数。通过式(16)-式(20)得出模型输出,并根据式(21)计算其反向传播误差。
(21)

算法流程如算法2所示。
算法2软件开发者价值预测算法
输入:注册时间大于三年的软件开发者三年内每日所有指标经过CNN评估后产生的数据集D={D1,D2,…,D1 095},训练集T1={D1,D2,…,D730},测试集T2={D731,D732,…,D1 095},其中Dm=(d,V′),d为数据采集日期,V′∈{1,2,3,4,5};lookback=2。
1.U←create_dataset(T1,lookback);
//根据条件划分训练集
2.form←1 to length(D) do
//LSTM训练
3.Lm←LSTM(Um);
4.Dm←Dense(Lm);
//全连接层得到预测值
5.Loss←MSE(Dm,Um);
//计算误差
6.Adam(β1,β2,η,ε);
//更新参数
7.end for
8.MPAE,RMSE←LSTM(T2);
//计算网络评价指标
//预测未来价值类别
3.2 模型训练
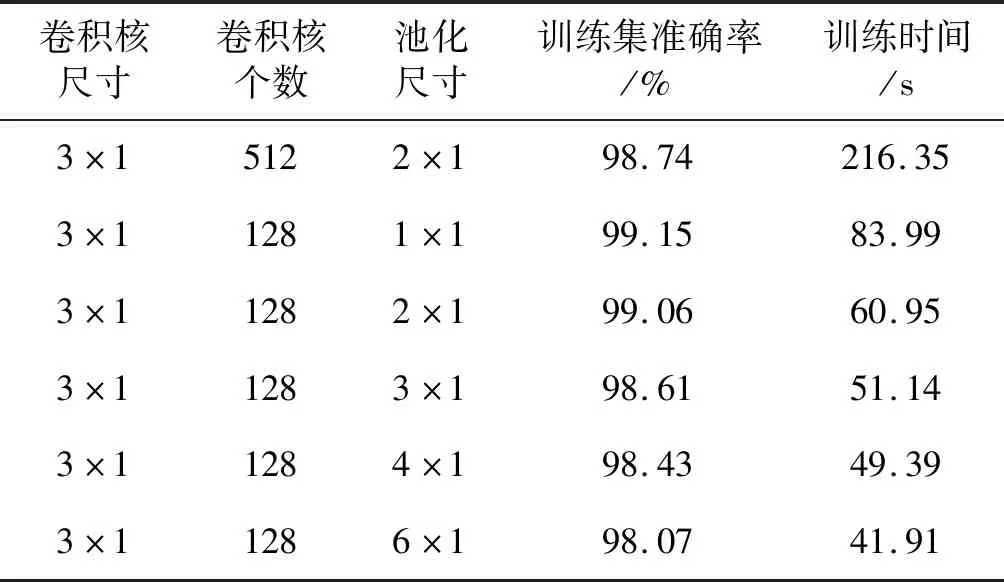
采用GitHub中采集并由专家做出评估的共992组数据作为训练数据,在采用SMOTE算法平衡数据集后,对不同参数设置下的卷积神经网络进行训练得到其准确率,卷积神经网络各参数对模型准确率的影响如表2所示。

表2 卷积神经网络各参数对模型准确率的影响
续表2
可以看出随着卷积核尺寸的增加,模型准确率先提升再下降,训练时间则不断增加,因为较小的卷积核能够提取样本中更为细化的特征,但是过于细化会导致过拟合,影响模型的分类能力。同时较大的卷积核会使卷积产生的特征输出增加,计算量暴增,这就导致了训练时间的增加,因此根据训练集准确率及训练时间确定3×1的卷积核尺寸。
确定卷积核尺寸之后,对卷积核的个数进行实验。从表2中可以看出增加卷积核个数,训练集的准确率开始时有所提升,但是再继续增加卷积核个数时,模型的准确率反而降低,训练时间却大大增加,因此根据训练集准确率及训练时间,本文选取的卷积核个数为128。
最后确定池化窗口大小,从表2中可以看出随着池化尺寸的增加,模型的准确率、训练时间则不断降低。这是因为最小的1×1池化尺寸输入输出相同,学习到的特征精细,但是训练时间将大幅增加且可能导致过拟合,较大的池化尺寸则可能忽略了样本特征,因此综合考虑训练集准确率及训练时间,本文选取了2×1的池化尺寸。
在选定各参数后,计算准确率最高情况下卷积神经网络在测试集上各项评价指标,如表3所示,其训练误差、准确率和迭代次数关系如图3、图4所示。

表3 测试集分类评价指标

图3 卷积神经网络训练误差
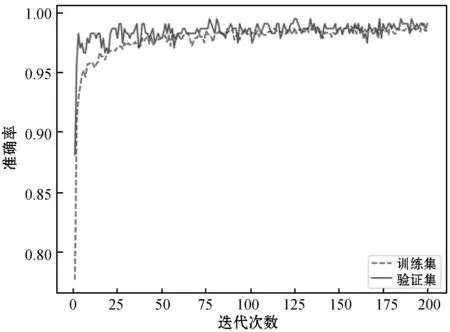
图4 卷积神经网络评估准确率
使用训练完成的卷积神经网络对注册时间大于三年的软件开发者历史数据进行评估,使用前两年历史数据作为训练集,并以2019年数据作为验证集,对LSTM神经网络进行训练,训练误差如图5所示;为了说明本文LSTM神经网络的预测性能,选择MSE(均方误差)、RMSE(均方根误差)、MAE(平均绝对误差)、MAPE(平均绝对百分比误差)和SMAPE(对称平均绝对百分比误差)对建立的模型预测效果进行评估,结果如表4所示。
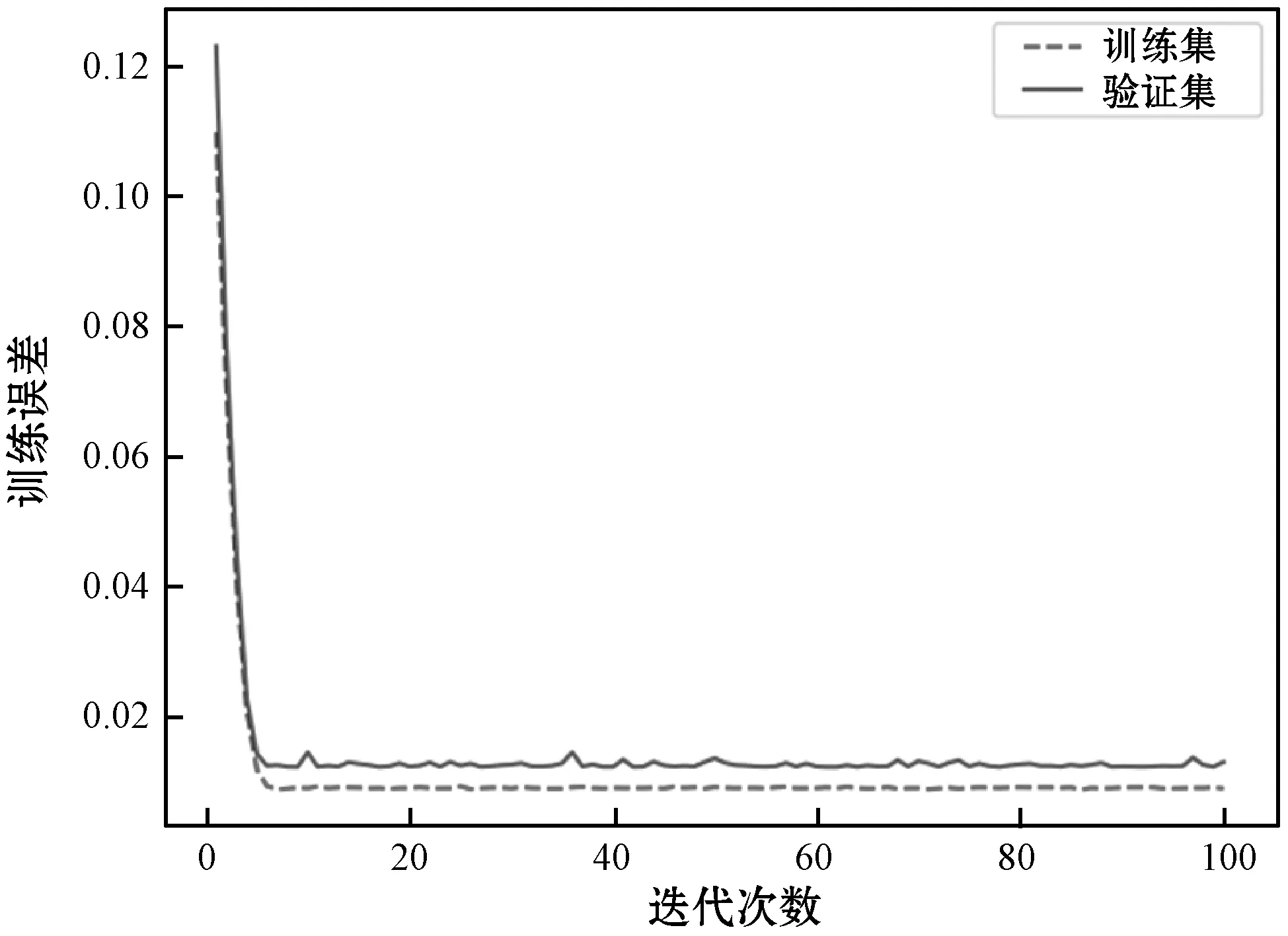
图5 LSTM训练误差

表4 预测模型评价指标
4 实例分析
利用已建立的评估模型对测试集软件开发者进行价值评估及预测,部分评估结果见表5。

表5 部分软件开发者价值评估结果
取序号为4的软件开发者历史记录,通过卷积神经网络评估人力资源价值后输入LSTM进行拟合,通过训练集样本的人力资源价值变化数据对LSTM进行拟合训练,预测开发者在测试集上的人力资源价值类别变化情况。
通过验证集数据分析可得:
(1) 424组验证数据得出的软件开发者价值评估结果与实际价值相符,评估正确率为98.59%。
(2) 通过表5中序号为1和2的软件开发者数据可以看出,在软件开发者无存储仓库或者有存储仓库无活跃的情况下,软件开发者是无价值的,符合管理学中人力资源价值评估的预测性特点。即当前的评估值能够在一定程度上反映未来其能够创造的价值,且未来不能创造价值的人力资源,是无法评估其当前价值的。
(3) 通过价值评估得到的软件开发者价值类别,可以帮助招聘人员快速发现GitHub中高价值技术人才,为企业人才战略提供基础保障。并且根据预测结果,能够大致判断该用户的职业,如图6和图7所示,用户在两年内价值为1的时间阶段较长且集中于寒暑假,可判断大致职业为教师或者学生,此类软件开发者招聘概率较高;而在职用户价值为1的时间较短且频繁,此种情况下招聘概率较低,若其前期价值变化符合规律而近期出现大幅变化,则招聘成功率将会增加。
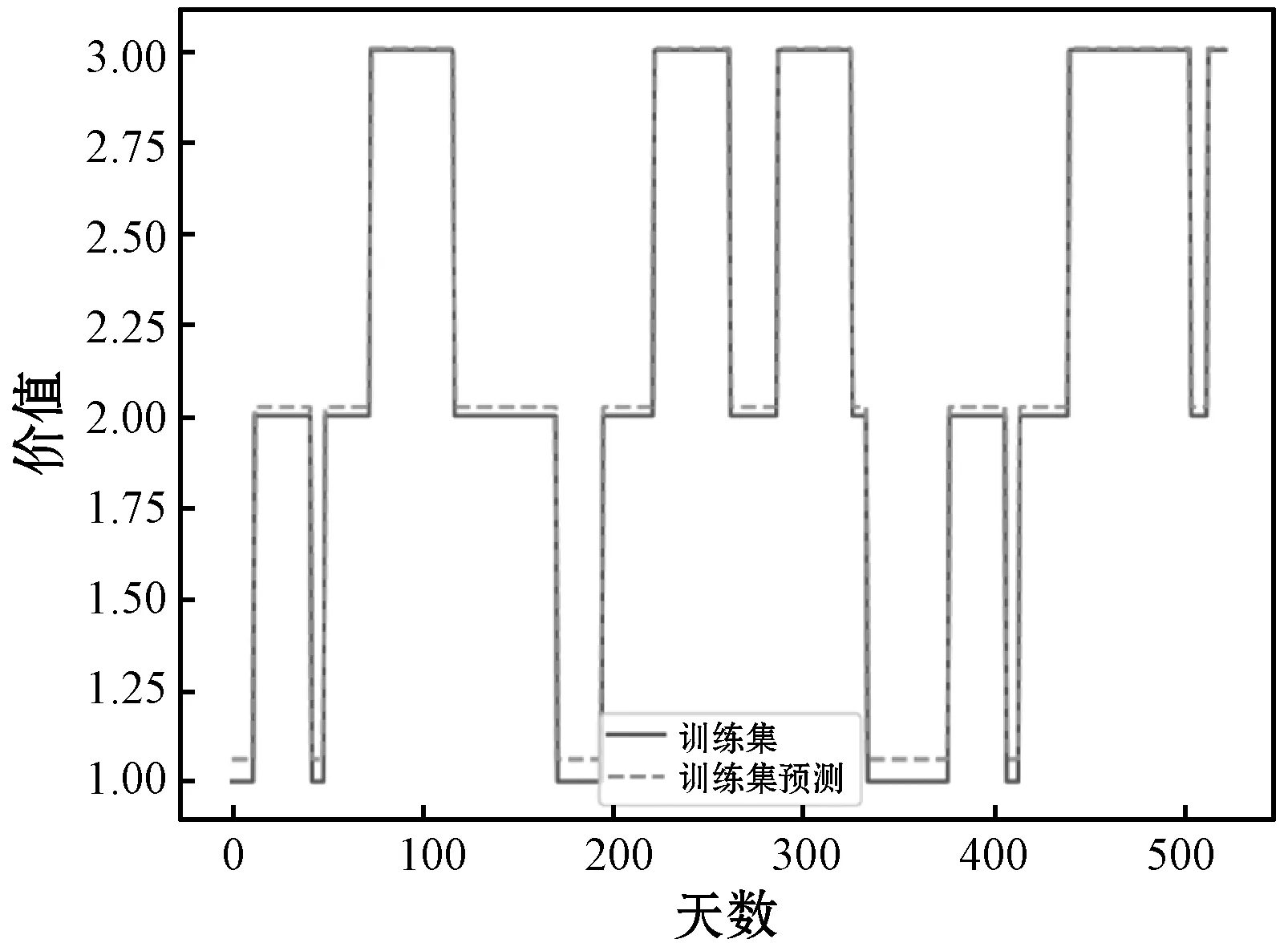
图6 LSTM神经网络训练集拟合

图7 LSTM神经网络测试集拟合
5 结 语
本文提出一种使用混合神经网络对GitHub软件开发者进行人力资源价值评估的方法,并对软件开发人才未来价值进行预测。首先分析了影响软件开发者的价值的因素,选取17种参数作为特征参数构建模型并训练;然后对GitHub软件开发者进行实例验证,通过对历史数据的学习,其预测结果符合当前人力资源,能够有效为企业招聘高技术人力资源及为企业内部人力资源考核提供参考,具有广泛的现实意义。
因为GitHub中无软件开发者的货币性特征,本文只选取了其中对评估影响较大的非货币性且可数值化的参数,后续应考虑把一些文本参数量化后作为特征,如软件开发者使用编程语言、项目使用编程语言等,并且根据这些数据评估软件开发者在不同编程领域的价值,以此作为推荐系统中Top-N排序的一项指标实现人力资源个性化推荐。
