结合深度残差神经网络与Retinex理论的低照度图像增强
2021-08-09周冬明刘琰煜谢诗冬王长城卫依雪
李 淼,周冬明,刘琰煜,谢诗冬,王长城,卫依雪
(云南大学 信息学院,云南 昆明 650500)
图像增强一直以来都是计算机视觉领域的重要研究方向,通常情况下由于相机曝光度或室内光线不足等原因,容易导致监控摄像头或者个人相机拍摄的图像出现局部甚至整体黑暗的情况,影响人们对图像的进一步的使用.特别是在极端低照度的情况下,靠人眼来识别图像细节几乎是不可能的.因此对低照度图像进行光照增强,能够将图像细节效果更好地提升,有利于让人们对图像进一步地处理使用.
低照度图像增强[1]方法主要分为传统算法和深度学习方法两类.传统方法中,通过利用红外图像和可见光图像的融合[2]也能捕捉图像的细节,但是红外图像仅仅能够捕捉热源信息,不能对细节进行更好的描述.另外,基于暗通道先验的算法[3]能够很好地对图像进行去模糊和重构,在细节方面保持较好,由于其先验理论是假设暗通道的灰度值趋向于零,而一般图像的天空区域的暗通道往往不为零,所以增强的图片容易产生光圈效应.Retinex 理论[4]20 世纪60 年代由Edwin.H.Land 提出,基于该理论的方法一直以来在图像增强方面有着显著的效果.通过Retinex 理论也衍生出了多种不同的传统模型方法,其中主要是基于路径的Retinex 算法.基于迭代的McCann Retinex 算法[5]和McCann99 Retinex 算法[6]分别采用螺旋式路径和图像金字塔的方式处理像素,利用多次迭代缓解了原始Retinex算法在光照估计上的不足,但是由于该类方法依旧是根据像素点对光照映射进行估计,从而容易导致图像结构模糊.在此基础上,发展出了单尺度[7]、多尺度[8]的Retinex 算法,以及带有色彩恢复的多尺度Retinex 方法,均在低照度图像增强方面有着良好的效果.2011 年提出的Dong 算法[9]算法将图像反转后,利用去雾的方式进行增强,取得了一定的效果,但是图像边缘痕迹突出,使物体和背景有所分割.2013 年提出一种NPE 算法[10],同样利用Retinex 理论,得到了不错的效果,但是图像的颜色深度较差,增强图像的色彩不够丰富.2017 年提出了BIMEF 算法[11]和LIME 算法[12],BIMEF 算法设计了一个多曝光图像的融合框架,根据这个框架来实现低光照图像增强,有效缓解了过度增强作用,很好地恢复了增强图像的对比度和亮度.LIME方法首先优化低光照图像的亮通道部分,从而得到细节较好的光照映射图,然后再将光照度进行一系列的变换最终得到增强的图像,同样取得了不错的效果.但是这些基于传统方式所构建的算法模型是对图像不同通道分别处理,容易引起色彩失真.
卷积神经网络出现以来,基于神经网络的低照度图像增强算法极大地改善了图像处理中的色彩失真和随机噪声.LLNet 方法[13]利用堆叠稀疏的深度自编码器对图像进行对比度增强和去噪,依旧会有色彩恢复不足的情况.RetinexNet[14]是基于Retinex 理论的深度学习方法,尽管其增强效果进一步提升同时一定程度上保持了色彩,但是增强图像会有一定程度上的模糊.Zhang 等[15]提出一种新的深度学习算法KinD 方法,在图像增强算法中有着很好的竞争力,在色彩恢复亮度调整上虽也有着优秀的效果,不过仍然存在图像锐化过度和局部细节不清晰的问题.
针对以上问题,本文通过引进深度残差网络,弥补已有方法的特征提取不足的缺点.在分解网络中,使用改进的U-net 网络来提取图像的反射分量;在重建网络中,利用深度残差网络对得到的光照分量和反射分量进行重建;最终再次结合对光照分量的增强,得到增强图像.从而构建出一套有效的低照度图像增强模型,一定程度上减少了细节的丢失,增强了对比度,并且保留了色彩.
1 相关理论
1.1 Retinex 理论Retinex 理论认为物体多样的色彩决定于物体自身的反射属性,我们通常看到的景色是由于各个物体本身反射不同,从而显得多彩缤纷,其色彩和光照强度无关.对于物体本身的反射属性来说是固有属性,无论是低照度图像还是正常亮度图像,同一物体的反射分量应当是相同的.所以,基于Retinex 理论的图像增强首要任务就是更好地提取物体的反射分量和光照分量.Retinex理论的数学模型为
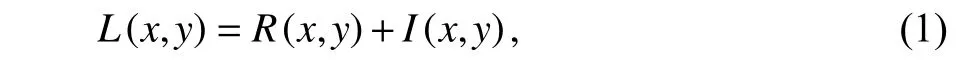
其中,R(x,y)表示图像的反射分量,L(x,y)是人眼看到的图像,I(x,y)是光照分量,其理论图如图1所 示.
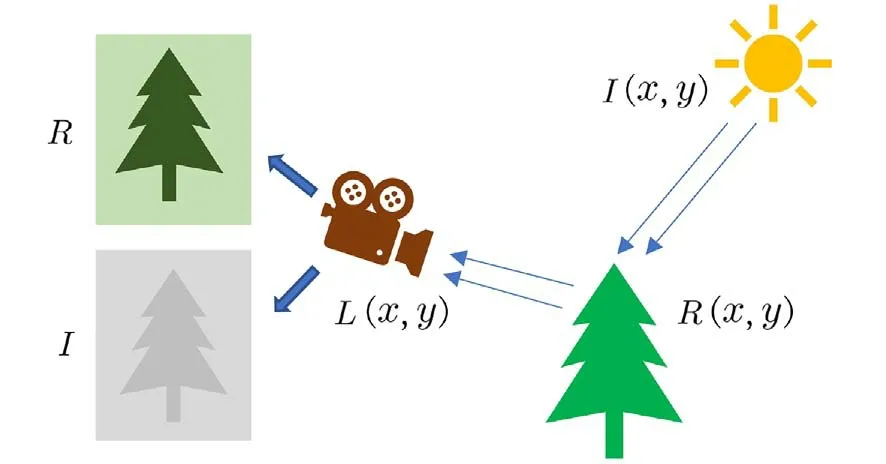
图1 Retinex 理论Fig.1 Retinex theory
1.2 SSR 和MSR 算法由Retinex 理论发展出来的单尺度Retinex 算法SSR(Single Scale Retinex)[7]理论是通过高斯模糊器联合对图像做卷积运算求出光照分量,以此分解图像.数学模型如下:

其中,σ 是算法中的尺度,称为高斯环绕尺度也就是高斯模糊器函数的标准差,χ2是图像中位置的二次型表示,即

多尺度Retinex 算法MSR(Multi-Scale Retinex)[8]主要就是三尺度算法,即选择大、中和小3 种尺度,对色彩保持效果较好.一般情况下,小尺度能够更好地提取到图像的边缘信息,中尺度处理能够使一定程度上的色彩信息得以保留,大尺度处理可以更好地平衡图像的色彩,在使用过程中可以人为地调整尺度的权重,方便得到不同场景下想要的结果.其数学模型为
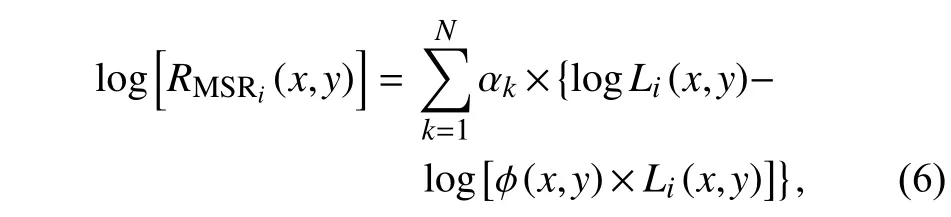
式中,N表示算法的尺度,αk表示在多尺度算法中每个尺度占有的权重,i表示图像的第i个通道.为了更好地保留MSR 算法的优点,尺度数量一般取3,即在大、中和小尺度上的作用均能有效结合.其中,权重 αk应满足

1.3 U-net 型网络U-net 网络[16]能够有效地提取图像的特征信息,最大的特点就是其U 型结构和跳跃连接.这种特殊的结构能更好地提取图像中的高级和低级的语义信息,在图像分割、特征提取领域有着出色的能力.网络中的卷积层和池化层后使用非线性激活函数,一般是Relu 函数.
由于光照分量包含着图像的低频特征,本文使用包含3 层跳跃连接的U-net 网络,相较于KinD网络适当增加了特征提取深度,使得到的光照分量在保留图像细节的同时尽可能地平滑均匀.具体对比如图2 所示,从图中可以看出,本文所改进方法提取光照分量保留了较少的高频信息,特征提取的更充分.

图2 图像反射分量和光照分量对比Fig.2 Comparison of the reflection map and illumination map
1.4 残差网络随着模型中卷积层的层数加深,过拟合和梯度消失的问题越来越突出,虽然训练中可以扩展数据集或者添加正则化来缓解上述问题,但是实际上随着深度的增加,模型的效果反而越来越差,浅层网络甚至强于深层神经网络,即出现了“模型退化”现象.由一系列的残差块所构成的残差网络(ResNet[17])能够很好地解决以上问题,残差网络已经发展成了一种最为重要的特征提取方法.残差块的数学模型如下:

式中,xl和xl+1分别为残差块的输入和输出特征图的映射,F(xl,Wl) 表示残差部分的运算过程,f(∗)表示激活函数.一般情况下,残差块由若干少数的卷积操作组成,每次卷积带有非线性激活函数.
图3 表示残差块的结构模型,其中特征映射xl输入到残差块中,经过残差块的卷积操作和激活操作,与输入映射xl进行单位加操作,得到残差块的输出.一般每个残差块有两到三层卷积,这样可以保留上下文的特征信息,有效地缓解过拟合和模型退 化的问题.

图3 残差块模型结构Fig.3 The model structure of the Res-block
2 本文算法
本文基于Retinex 理论,利用改进的U-net 网络以及残差网络构建分解、重建网络模块.分解模块利用正常亮度图像和低照度图像的反射分量相一致的先验理论.将正常光照图像的反射映射图作为重构图像的对照图,将正常图像的亮度映射作为低照度图像亮度信息增强的对照.
2.1 模型结构本文网络结构主要由分解和重构两部分构成.分解网络采用包含跳跃连接的端到端神经网络,重构网络利用多层残差块进行重建图像.具体步骤如下:
步骤1将成对的低光照、正常亮度图像送入改进的分解模型中,分别得到两组反射图和光照图Rl、Il、Rh和Ih.
步骤2利用分解模型中光照图生成网络进一步对光照图进行训练,得到含亮度信息的Il′.
步骤3将未增强的亮度映射Il和反射映射Rl送入设计的残差网络中,得到复原的图像G_sample′.
步骤4将增强的亮度图像按照一定的权重融合复原图像,以便进一步提高亮度信息,最终得到图像G_sample,G_sample 即是最终增强后的结果.
如图4 所示,分解网络首先输入暗光或者正常光照图像,经过一系列的卷积和池化,卷积操作增加图像的维度,可以更有效地提取图像信息.池化操作减小图像每一维度的尺寸,达到提取特征的目的,最终图像每一维度的大小降低至原图像的1/8,图像深度最高增加到128 深度层数.分解模型后半部分是上采样和复制链接部分,一共有3 次上采样过程和3 次复制链接过程.每次上采样都会扩大图像每一维的尺寸大小,同时将特征图的维度深度减半,上采样之后会将分解模型前半段中的特征映射复制过来,形成新的特征图,然后再进行卷积操作,从而减小维度,最后得到图像维度为3 的反射分量.图像的光照分量结构简单,光照分量维度只有一层,本文中仅将原图像进行3 次卷积来特征提取,在第2 次卷积操作时,将上一步提取反射分量的过程中同维度的反射映射图复制链接到光照特征图中,以便使光照分量能够在一定程度上表达图像的细节信息.最后,反射映射和光照映射均需通过sigmoid 非线性激活函数进行激活,最终得到分解之后的光照分量和反射分量映射图.

图4 提出的网络模型结构Fig.4 Network structure of the proposed model
重建网络是将低照度图像分解后的光照分量和反射分量送入重建模型中,区别于传统的图像融合方法例如多聚焦图像融合算法[18]等,本文首先将图像合并在一起,然后进行3 次卷积运算.第一次步长为1,不改变图像尺寸,后两次步长为2,即将每一维度的尺寸大小减半.随后通过一系列的残差块,利用上采样恢复图像的尺寸以及维度.由于低光照图像的光照分量亮度较低,需要对光照分量进行增强以达到更好的视觉效果,然后将增强后的光照分量和重构的图像进行合并,最终得到增强后的高亮度图像.
2.2 损失函数对于物体本身来说,其反射部分是固有属性,无论是低照度图像还是正常亮度图像,同一物体的反射分量应当是相同的.分解模块的损失函数我们采用已有的损失函数模型,主要由两部分组成.第一部分中,分解模型得到的反射图和光照图组合起来,然后同未分解图像计算L1损失,同时将低照度的反射图和正常光照的反射图进行计算L1损失,即

式中,下标x和y分别表示按照图像的水平和垂直方向,µ和τ分别为水平和垂直方向梯度损失的系数,I表示图像的光照分量,L表示标签图像,∇ 表示的梯度算子,包含二维图像的两个维度方向.通过对梯度信息的优化,极大地保留分解图的边缘信息和平滑一致性.
重建网络的损失函数也包含两部分,由于生成的是增强图像,需要保持与对应的低照度图像的一致性,依旧使用梯度损失.由于生成重建图是三通道RGB 图像,因此需要先将其转化为灰度图像.数学模型如下:
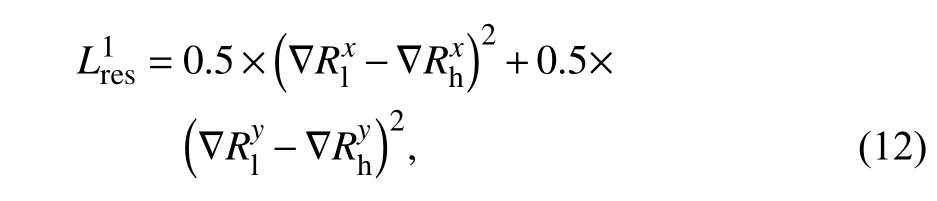
式中,上标表示对灰度图像的x和y方向上所求的梯度.第二部分使用L2损失以及优化结构性损失ssim,以便于使生成图像更接近原始图,数学模型如下:
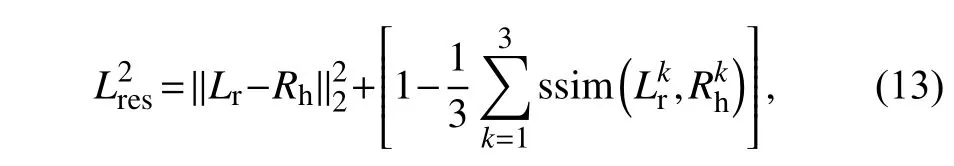
式中,Lr表示重构模型生成增强后的图像,k表示图像通道,对于生成图像和反射图像取值为3,ssim是 利用结构相似性算法构造的损失函数.
3 实验及结果分析
3.1 训练数据集本文使用的训练数据集为采用Retinex-Net[15]方法构建的LOL-dataset,该数据集包含485 对低光照/正常光照训练图像和5 幅低照度测试图像.测试数据集选用Brighting Train 和LOL-dataset,其中Brighting Train 包含1 000 对低光照和正常光照图像,LOL-dataset 中包含15 幅低照 度测试图片.
3.2 训练及结果分析实验在Intel i7 9700kF 3.6 GHz,32GB RAM,Nvidia 2080Ti GPU 平 台,tensorflow1.15 框架上完成.权重参数设置为:α=1,β=1,γ=0.01,µ=τ=0.15,重建网络残差块为n=6,分解网络训练次数为1 000 次,重建网络训练次数为2 000 次.本文方法与经典的算法和现阶段主流的算法均做了比较,对比算法有MSRCR[19]、LIME[12]、BIMEF[11]、NPE[10]、MF[20]、Dong[9]以及深度学习算法Retinex-Net[14]、KinD-Retinex[15],对比结果如图5 所示.

图5 不同方法在 Brighting Train 上实验结果Fig.5 Experimental results of different methods on Brighting Train
图5 中,MSRCR 提升了一定的亮度,但是造成了一定程度的色彩缺失,边缘信息也有所丢失.Dong、RetinexNet 边缘过于突出,图像细节的轮廓线明显被加粗,物体与背景信息分割严重.LIME方法一定程度上缓解了Dong 的边缘突出问题,但曝光度有所加重,导致天空背景区域过亮,并且色彩保持不够充分,色彩深度也有所减弱.KinD、NPE 以及BIMEF 与本文效果相似,都有着比较出色的结果,很好地实现了图像增强.但是BIMEF和NPE 在色彩深度上有所欠缺,某些区域例如天空背景上的对比度较低.
由于本文使用的是深度学习框架,对比算法中深度学习算法KinD 的结果与本文较为相似.相较于KinD,本文的细节描述如图6 所示.扩大的“雕像”图像上部的小鸟,羽毛的颜色深度和色彩比较,本文算法效果更好,且本文算法在背景天空中的乌云颜色和云缝的对比度较高,乌云细节轮廓也更为清晰.右侧建筑图中,本文算法门洞处明显消除了模糊,相比于KinD 本文方法的细节更为清晰,轮廓边缘可分辨度更高.

图6 本文方法和KinD 的结果细节对比Fig.6 The detailed comparison between our method and KinD
除了主观视觉上的效果,测试结果还采用了均方误差(MSE)、峰值信噪比(PSNR[21])、结构性检验标准(SSIM[22])等指标客观评价结果.SSIM 表示了一种全参考的图像评价质量指标,代表是的结构相似性指标,包括亮度对比度以及图像具体的结构3 个部分.PSNR 是峰值信噪比指标.MSE 表示图像的均方误差.
如表1 所示,本文方法在3 组增强图片的客观指标对比中均处于优势.对于“雕像”图像,传统的BIMEF 算法同样有着明显的效果,其SSIM 与本文方法较为接近,但也略低于本文方法.对于“建筑1”和“建筑2”,本文方法相较于对比算法均有着良好的优势.
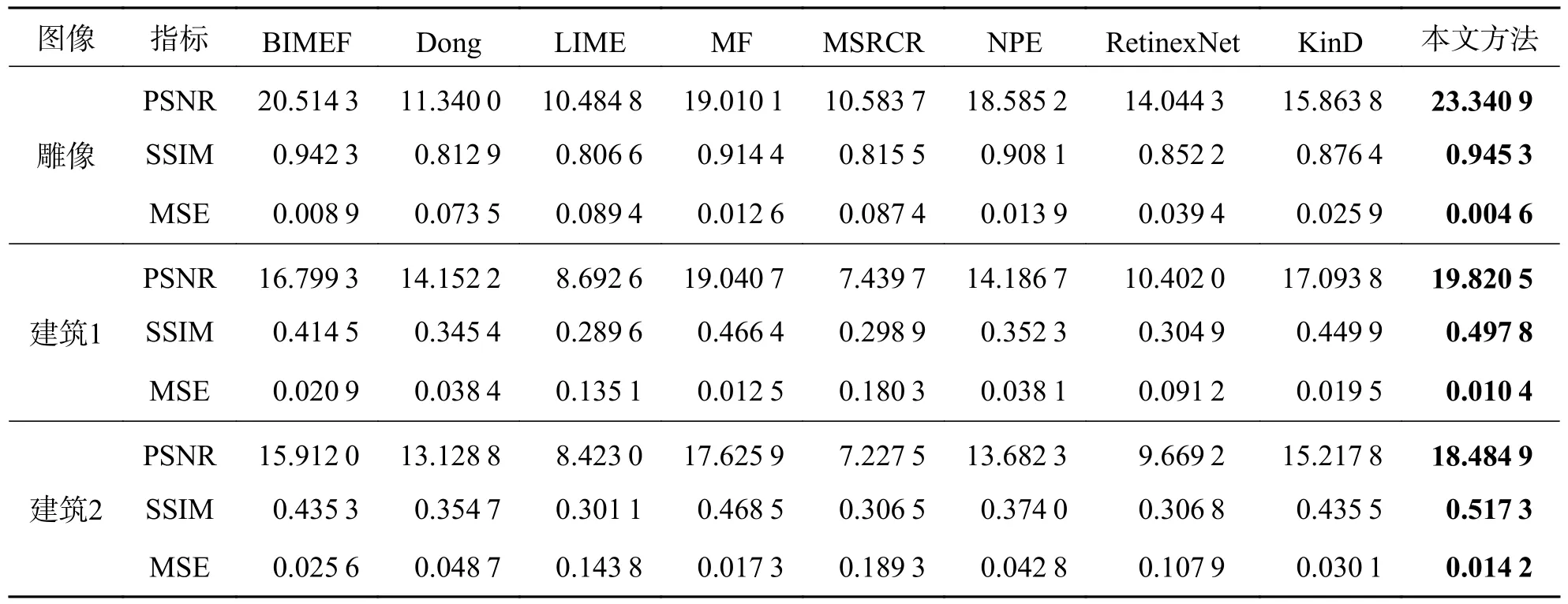
表1 Brighting Train 实验结果客观评价指标Tab.1 Objective evaluation index of experimental results on Brighting Train
此外,本文还使用LOL-dataset 来测试模型,在数据集中任意选取3 幅低照度图像进行实验对比.如图7 所示,MSRCR 和LIME 依旧是最亮的,但是图像变得很模糊,细节颜色突变明显,虽然能够看到图像中物体的具体轮廓,但是很大程度上缺失了平滑度,导致了图像的失真.RetinexNet、Dong 以及NPE 具有同样的问题,并且细节表现上受噪声干扰明显,不能自然地显示物体的平滑轮廓.BIMEF和KinD 与本文相近,并且取得了比较好的结果.但本文算法在色彩还原度上更胜一筹,在细节轮廓清晰度和色彩上有一定的优势.

图7 本文算法和其他算法在LOL-dataset 上的实验结果对比Fig.7 The experimental results of our algorithm and other algorithms on LOL-dataset
在LOL-dataset 上的客观指标如表2~4 所示,选用PSNR、SSIM 和MSE 客观指标,其中最优的方法用粗体标出,次优的方法用下划线标出.表中,“衣柜”图像效果的结构性指标SSIM 排名第二,PSNR 和MSE 指标与KinD 算法相当,略低于BIMEF算法.“游泳池”和“体育馆”客观指标效果显著,除了“体育馆”的SSIM 指标为0.242 1 略低于KinD方法的0.244 6 外,其余指标均优于其他对比方法.
从表2 可以看出本文方法在客观指标上略低于BIMEF 算法,对于这种情况本文测试了LOLdataset 中所给出的所有标准测试图像的客观结果,其中LOL-dataset 中测试图像12 组,所得到的详细结果如表3 所示.文中用黑体字标出指标低于BIMEF 的结果,可以看出,PSNR 指标中有4 组数据略低于BIMEF 方法,而SSIM 指标中仅有一组数据低于该结果.本文方法平均指标高于BIMEF算法.

表2 LOL-dataset 增强结果图像评价指标Tab.2 Image evaluation index of enhancement results on LOL-dataset

表3 LOL-dataset 测试图像客观指标Tab.3 Objective index of test image on LOL-dataset
在深度学习算法中,本文选取Retinex 还有较为优秀的KinD 进行比较.此外,使用LOE 指标进行客观分析,尽管在LIME13 中已经证明将低光照图片作为对比输入是不合适的,并且深度学习算法KinD 在LOE 指标上同样并没有达到最优结果,但是仍可作为一种客观的评价方式.特别是针对现有的深度学习算法,本文方法的LOE指标仍然会有一定的优势.如表2 中所示,LOE 指标本文方法的结果并未达到最优,但是相对于深度学习算法KinD 和RetinexNet,展现出更优的性能.此外,对于BIMEF 和Dong,基于深度学习的方法尽管LOE指标上有所劣势,但在具体细节表达上以及去噪方面,传统算法仍展现出部分不足.
3.3 优化比较本文基于深度模型框架进行优化,主要针对现阶段已有的深度模型进行优化,因此选取KinD 方法进行对比.并且由于残差块的出现,使得深度神经网络变得容易实现且应用广泛,残差网络在特征提取上的优秀表现同时也体现在网络层数上.于是本文跟据残差块数量的不同,进行了额外的对比,分别选取残差块数为6、10、12 和14进行对比实验.此外,评价指标额外使用图像自然统计特性(NIQE[23])指标,NIQE 是一种无参考评价指标,值越小越接近自然图像,越能够反映图像增强后的真实度,选取该方法原因是比较深度学习算法对图像的还原度.
实验结果中,主观方面如图8 所示,随着残差块数量的不同,细节描绘也有所不同.随着重建网络深度的增加,在训练1 000 次的情况下,雕像面部的粗糙部分被明显的加重,表现出一种过拟合的现象.在4 种模型对比中,Res-6 相较于其余方法,在色彩保持的基础上得到的结果图像更加平滑,而Res-10 已经开始显示出雕像面部的粗糙,随着残差块数增加,主观感受上显得比较模糊,图像的平滑一致性有所下降.

图8 不同残差网络实验结果细节比较Fig.8 Comparison of experimental details of different residual networks
客观指标方面,选取图片“雕像”、“建筑1”和“建筑2”进行实验对比,具体指标如表2 所示.其中PSNR、SSIM 和MSE 指标本文方法较为优秀,因此表中残差块为6 层整体效果最好,但是NIQE指标未能达到最优.随着网络深度增加,NIQE 指标逐渐变好的同时,PSNR、SSIM 和MSE 指标并未明显劣于KinD 算法,所以一定程度的增加重建模型深度可以提高NIQE 指标效果.随着深度的增加,尽管残差网络的特征提取能力有所上升,但也会使训练更为复杂,鉴于设备计算能力的限制和时间消耗,选取残差块为6 层的残差网络作为重建模型是最好的选择,而此时重建网络的神经网络层数是24 层.表4 列出了消融实验的结果和KinD 算法的比较,在表中当残差块数量为6 时效果明显较优,NIQE 指标是随着网络的加深稍有着很小的领先.因此我们选取残差块数量为6 作为我们最终的模型 参数.
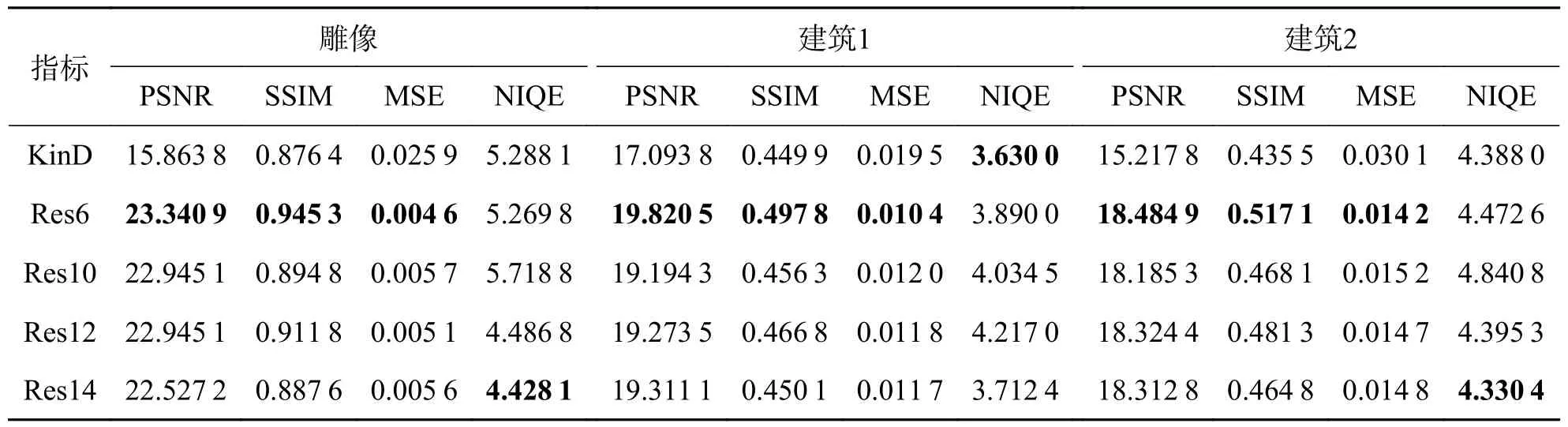
表4 不同残差层实验结果评价指标Tab.4 Evaluation index of experimental results in different residual layers
4 结束语
本文利用深度学习的方法,对低光照的图片进行增强,达到比较理想的效果.采用Retinex 理论,使用包含卷积和上采样的多层U-net 网络对图像进行分解,得到光照映射图和反射映射图,结合多层残差网络对分解后的图像进行重建,达到增强的目的,同时在多个数据集上进行了检验.实验结果表明,相较于传统的图像增强算法,由残差块所组成的残差网络实现较少的实验操作难度,得到的结果细节描述更准确,色彩深度更丰富,局部对比度更强,主观视觉上效果较好,在主观上和客观评价指标中都优于对比算法.
