PI-Unet:异质虹膜精确分割神经网络模型的研究
2021-08-06周锐烨沈文忠
周锐烨,沈文忠
上海电力大学 电子与信息工程学院,上海 201200
近些年来,生物特征认证技术快速发展。虹膜纹理由于其唯一性、极高的精度和稳定性、非接触性以及防伪性,在众多生物特征认证技术中脱颖而出,受到广大用户的青睐,具有很好的应用前景[1]。一个完整的虹膜识别过程包括虹膜图像质量评估、虹膜分割、归一化、特征提取和匹配等步骤[2]。其中虹膜分割是指在采集到的包括众多噪声的眼睛图像中准确找出虹膜区域。虹膜分割是整个虹膜识别过程中最关键的一步,对后续步骤的影响极大,也影响了整个虹膜识别系统的准确率。
传统的虹膜分割算法主要利用虹膜边界的梯度变化来确定虹膜边界。基于图像梯度的虹膜分割算法在理想状况下往往能取得好的分割效果,但是在非理想状况下,如采集到的图像虹膜区域与非虹膜区域的对比度不强时,传统算法的分割效果往往很差。在实际应用场景,采集到的虹膜图像不仅包括虹膜区域,还包括睫毛、眼睑、光斑等噪声干扰,传统的虹膜分割算法容易受到这些噪声的影响,从而对虹膜区域进行错误的分割,导致后续虹膜识别步骤出现错误。
近年来,深度学习蓬勃发展,在许多领域的表现都十分优秀。研究人员们开始将深度学习应用于虹膜分割领域,并取得了显著的效果,有效地解决了由于采集到的虹膜图像亮度、对比度等的影响而导致算法对虹膜区域进行错误分割的问题,提高了算法的鲁棒性。但是,对于异质虹膜图像(可见光和红外图像),目前虹膜分割算法的分割效果并不好。目前的虹膜分割算法大多只针对特定类型的虹膜图像,而对于红外图像和可见光图像混合的异质虹膜图像的分割效果很差。
本文提出的虹膜分割算法是基于深度学习的卷积神经网络模型,该模型不仅对成像质量参差不齐的虹膜图像都能实现准确的分割,而且对于异质虹膜图像的分割效果与目前的虹膜分割算法相比,准确率更高且参数量和计算量更小。本文将提出的异质虹膜分割卷积神经网络模型命名为PI-Unet(Precise Iris Unet)。PI-Unet主要有以下几点贡献:
(1)使用卷积神经网络进行虹膜分割,与传统算法相比,在受到噪声干扰时,更能保持分割效果的准确性。
(2)对虹膜分割网络的网络层、损失函数和数据增强方法都进行了重新设计和改动,使得提出的虹膜分割网络模型能够对异质虹膜图像进行准确的分割。与其他虹膜分割神经网络模型相比,PI-Unet 实现了更高的虹膜分割准确率。
(3)在保证准确率的同时,对网络结构进行重新设计。最终设计的网络模型参数量仅为2.49×106,计算量为1.32×109,均低于目前的虹膜分割神经网络,能够适用于低性能的边缘计算设备。
1 相关研究
目前的虹膜分割算法主要可以分为传统算法和深度学习算法两大类别。
传统算法中,最经典的虹膜分割算法便是Daugman于1993 年提出的微积分算子及其改进的虹膜分割算法[3],该算法目前仍被应用于一些虹膜识别设备中。1997 年,Wildes[4]提出了在边缘检测的基础上,使用Hough变换来检测虹膜内外边界的虹膜分割算法,该算法计算量相比Daugman的算法的计算量更小,分割速度更快。中科院谭铁牛[5]于2003 年提出将样条拟合算法用于虹膜分割,该算法运行复杂度较低,但是容易受到睫毛干扰的影响而导致分割准确率下降。
随着近几年深度学习的快速发展,越来越多的研究人员开始尝试将深度学习算法运用于虹膜分割。Lozej等人[6]提出将Unet作为虹膜分割网络模型应用于虹膜分割,在CASIA-Iris-intervel上实现了91.2%的mIoU,网络模型大小达到了138.2 MB。Shabab等人[7]提出基于FCN改进的FCDNN 网络,在UBIRIS.v2 上实现了0.939 0 的F1分数。Kerrigan等人[8]提出将结合了空洞卷积和残差网络的DRN 卷积神经网络应用于虹膜分割,在Biosec虹膜数据库的mIoU 达到了87.29%,网络模型大小为99.2 MB。Zhang 等人[9]将U-Net 结构和空洞卷积结合,提出FD-Unet 用于虹膜分割,在CASIA-Iris-intervel 和UBIRIS.v2上的F1 socre分别达到了97.36%和0.948 1。Lian等人[10]提出Attention guided U-Net,有效地解决了使用U-Net 进行虹膜分割时会出现的对非虹膜区域像素点进行错误分类的情况,在CASIA-Iris-intervel 和UBIRIS.v2上的mTPR分别达到了96.325%和96.812%,优于Unet 的分割效果。Chen 等人[11]提出将FCN 和dense block 结合的DFCN 网络,在CASIA-Iris-intervel、IITD 和UBIRIS.v2 上的F1 score 分别达到了0.982 8、0.981 2和0.960 6,其网络模型大小为138.91 MB。
2 PI-Unet网络模型的设计
以上用于虹膜分割的神经网络模型往往存在这样的问题:(1)对于红外虹膜图像的分割准确率很高,但对于可见光下的虹膜图像,分割准确率就有明显的下降,即对于异质虹膜图像的分割效果不好;(2)只追求准确率,而忽略了因模型参数量、计算量过大而不能适用于实际应用场景的问题。本文针对上述问题,提出了针对异质虹膜图像的虹膜分割神经网络模型PI-Unet。PI-Unet在设计上参照了Unet[12]的Encoder和Decoder相结合的语义分割神经网络结构,并且去除了其中的冗余部分,使得PI-Unet 在保持准确率的同时又能够快速地进行分割。在损失函数方面,本文放弃了传统的适用于语义分割的二分类交叉熵损失函数,选取了更适用于虹膜分割的损失函数。
2.1 Encoder设计
本文提出的PI-Unet 结构参考了Unet 的Encoder 和Decoder相结合的网络结构,其中Encoder的目的是提取虹膜图像的大小、位置、形状等特征。只有Encoder提取到的虹膜图像特征足够详细且准确,对虹膜图像的分割效果才更好。所以设计一个适合于虹膜分割的Encoder是整个虹膜分割神经网络中最重要的部分。本文基于对异质虹膜图像快速分割的考虑,提出了两种Encoder的设计方案,并对两种方案的参数量和运算量做对比,选取了其中适合异质虹膜图像快速分割的一种方案作为PI-Unet的Encoder。
本文设计的两种Encoder 的结构如图1 和图2 所示。在EncoderV1中,所有卷积层均抛弃传统的卷积方式,而采用MobileNet[13]所采用的深度级可分离卷积。经实验证明,使用深度级可分离卷积可以在保持准确率的同时,大幅度减小神经网络模型的参数量和计算量。输入图像经过三次下采样环节,其中下采样方式不是采用传统的2×2 最大值池化,而是stride=2 的3×3 深度级可分离卷积。由于使用深度级可分离卷积代替了传统卷积,可能会导致出现Encoder特征提取不明显的问题,所以采用stride=2的3×3深度级可分离卷积代替2×2最大值池化,可以适当增加用于特征提取的卷积层数,弥补了Encoder特征信息提取不明显的问题[14]。在EncoderV2中,依然采用深度级可分离卷积和stride=2 的3×3 深度级可分离卷积相结合的方式进行特征提取和下采样,但是将下采样环节增加到了5 次。增加下采样的次数是考虑到在异质虹膜图像分割任务中,可见光图像和红外图像的特征差异较大,下采样环节不足可能会导致提取到的异质虹膜图像特征信息不足,从而影响分割的准确率。

图1 EncoderV1网络结构Fig.1 Network structure of EncoderV1

图2 EncoderV2网络结构Fig.2 Network structure of EncoderV2
本文对提出的两种Encoder设计方案进行参数量和计算量的对比,对比结果如表1所示。在输入图像分辨率均为288×320×3的情况下,EncoderV2与EncoderV1相比虽然在参数量上有所增加,但是计算量上,EncoderV2却有明显的优势。这是由于EncoderV2 中充分的下采样环节降低了后续卷积计算的计算量。在实际应用场景中,参数量与计算设备的内存大小相关,计算量则与计算设备的运算能力相关。而边缘计算设备往往在运算能力方面性能较差,所以在综合考虑参数量和计算量的情况下,EncoderV2 比EncoderV1 更适合作为PI-Unet的Encoder。

表1 两种Encoder方案参数量和计算量对比Table 1 Comparison of params and flops of two Encoder schemes
2.2 Decoder设计
Decoder 的作用是将Encoder 提取到的特征信息转换为语义信息。在异质虹膜分割任务中,Decoder 对输入图像经过Encoder 得到的特征图进行上采样和卷积,最后经过softmax 函数对图像上每个像素进行分类,区分属于虹膜区域的像素和不属于虹膜区域的像素。目前,用于语义分割中的Decoder 的上采样方式主要有反卷积、插值法和反池化三种。其中反卷积的优点是参数可以学习,使用反卷积进行上采样能够使得异质虹膜分割结果更加准确。但是使用反卷积会增加参数量和计算量,使得分割速度变慢。插值法的优缺点则与反卷积相反,参数量和计算量减小的同时可能导致分割准确率的下降。反池化是SegNet[15]中所使用的上采样方式,实现方式是根据Encoder中最大池化层进行池化时记录的位置信息进行复原。反池化的优点是计算量小,计算速度快,缺点是需要占用一定内存用于储存位置信息。
由于在Encoder 的设计中,本文采用stride=2 的深度级可分离卷积代替最大值池化对特征图进行下采样,所以首先排除了使用反池化作为Decoder 中的上采样方式。为了充分发挥反卷积和插值法两种方法各自的优点,尽量避免两种方法的缺点,本文提出了将反卷积和插值法相结合的Decoder设计方案。在Decoder的前两次上采样中,由于特征图分辨率小,所以使用反卷积进行上采样能够提高准确率的同时只增加了少许参数量和计算量。而在Decoder 的后续上采样中,由于特征图分辨率变大,所以使用插值法进行上采样,避免参数量和计算量的大幅度增加。Encoder 和Decoder 之间通过特征融合通道相连接,目的是减少下采样过程中的信息丢失,使得分割效果更加准确。最终确定的PI-Unet 的网络结构如图3 所示,各个网络结构的细节如表2所示。

表2 PI-Unet网络结构细节Table 2 Network structure details of PI-Unet

图3 PI-Unet网络结构Fig.3 Network structure of PI-Unet
2.3 损失函数
在神经网络模型的训练过程中,选择一个合适的损失函数非常重要。一般语义分割神经网络的损失函数都选用交叉熵损失函数。交叉熵损失函数表示为:

其中,yi表示样本i的真实值,pi表示网络输出预测样本i为正类的概率。
使用交叉熵损失函数作为网络训练的损失函数可以有效地避免梯度较小时网络无法继续训练的问题,使得训练过程中神经网络权值能够有效地向真实值收敛。但是交叉熵损失函数有一个明显的缺点,当分割的图像存在类别不平衡的问题时,网络的训练就会被像素较多的类主导,对于像素少的类别,网络难以学习到其特征,从而降低了网络的有效性。在虹膜分割应用中,采集到的虹膜图像便可能存在类别不平衡的情况。如图4所示,由于采集虹膜图像时人离成像设备有一定的距离,所以采集到的图像中背景占据大部分的像素,而需要准确分割的虹膜区域只占小部分的像素。对于此种类别的虹膜图像,在网络训练时如果使用交叉熵损失函数,训练好的神经网络的分割效果肯定不理想。为了解决上述问题,需要使用一个能解决类别不平衡问题,又能在语义分割任务中表现良好的损失函数。

图4 虹膜图像中的类别不平衡现象Fig.4 Category imbalance phenomenon of iris images
Dice Loss 于2016 年V-Net 网络[16]中首次提出并应用于医学图像分割。作者提出Dice Loss的原因是因为感兴趣的解剖区域只占整个扫描区域中的一小部分,即类别不平衡现象。如果使用传统的交叉熵损失函数会使得网络的训练过程中陷入局部最小值。Dice Loss的定义如下:

其中,X表示Ground Truth图像,Y表示神经网络的输出图像。
Dice Loss 的本质是衡量X和Y的重叠部分,当Dice Loss 的值为0 时,则表示X与Y完全重叠,即神经网络的输出图像和Ground Truth 图像完全一致。可以看出,Dice Loss 和语义分割的评估指标IoU 的本质是一致的,当Dice Loss在训练过程中不断减小,则表示评估指标IoU 在不断上升,分割效果在不断变好,所以选用Dice Loss 作为语义分割的损失函数是完全可行的。而对于交叉熵损失函数所不能解决的训练样本存在类别不平衡的问题,Dice Loss 则完全可以避免。对于虹膜分割这种存在类别不平衡现象的语义分割任务,Dice Loss比交叉熵损失函数的表现更好。
2.4 实验细节
使用Pytorch深度学习框架[17]对本文提出的PI-Unet进行训练和测试。在Nvidia RTX2080Ti GPU 上训练300个批次。训练时将输入图片统一裁剪至288×320分辨率,以方便进行batch size为16的批量训练。优化器选用Adam,其中学习率为0.001,第一次估计的指数衰减率设为0.9,第二次估计的指数衰减率设为0.999。测试模型时以batch size 为1 进行测试,所以不需要进行裁剪,输出图片分辨率与输入图片分辨率保持一致。
3 实验评估
3.1 数据集
本文选取的数据集为CASIA-iris-intervel-v4,IITD和UBIRIS.v2,其中CASIA-intervel-v4和IITD的虹膜图像为为红外图像,UBIRIS.v2 的虹膜图像为可见光下的虹膜图像。
CASIA-iris-intervel-v4[18]:CASIA-iris-intervel-v4 是中国科学院自动化研究所CASIA-iris 虹膜数据库中的一个子集。该数据集一共包括来自249 个受试者的虹膜图像,本文选取其中124个受试者的虹膜图像作为训练集,剩余的受试者的虹膜图像作为测试集。
IITD[19]:IITD 虹膜数据集由印度理工学院德里分校提供。该数据集一共包括来自224 个受试者的虹膜图像,因使用此数据库的研究人员不多,不方便对比分割效果,所以本文选取该数据库所有虹膜图片作为训练集。
UBIRIS.v2[20]:UBIRIS.v2虹膜数据库由贝拉英特拉大学的SOCIA Lab提供。本文选取该数据集中的50个受试者共2 250 张虹膜图像作为实验用的数据集,其中25个受试者的虹膜图像作为训练集,剩余的受试者的虹膜图像作为测试集。
3.2 数据增强
数据增强在神经网络模型的训练过程中有很重要的作用。合适的数据增强方法既能提高模型的泛化能力,又能提升模型的鲁棒性。对于难以获取大量训练数据的任务,数据增强又能增加训练的数据量,降低过拟合现象出现的概率。
本文旨在对异质虹膜图像进行快速而准确的虹膜分割,因此选取的数据增强方法与一般语义分割所选用的数据增强方法有所不同。在虹膜识别的实际应用场景中,由于光照、对焦、采集距离等因素的影响,采集到的虹膜图像存在亮度差别大、模糊、虹膜区域位置面积不一致等问题。如果在数据增强中不考虑上述影响,训练网络模型时便会出现收敛速度慢的问题,训练好的模型也容易出现过拟合的现象。因此,本文综合考虑了上述实际应用场景中出现的情况,对数据增强方法做出了如下设计:
(1)随机亮度、对比度增强。由于网络训练所用的虹膜数据库图像的亮度、对比度单一,与实际应用场景中虹膜图像亮度差别大的现象不一致,所以对训练用的虹膜图像进行随机亮度、对比度增强,以达到模拟实际应用场景的作用。该数据增强方法旨在解决由于实际应用场景中采集到的虹膜图像亮度、对比度差别大而导致神经网络不能正确分割虹膜区域的问题。
(2)随机水平翻转。由于人的眼睛有左右眼的区别,左右眼中的虹膜区域在虹膜图像中的位置也有差异。对训练数据进行随机水平翻转,可以防止由于过拟合而导致训练好的网络模型不能准确分割左、右两种类型的虹膜图片的现象。
(3)随机缩放。语义分割的应用场景多为自动驾驶场景,自然景观场景等,这些应用场景没有特别明显的特点,训练一个运用于这些应用场景的神经网络一般不会用到随机缩放的数据增强方法。然而虹膜图像中都有明显的圆环区域,只是虹膜区域在采集到的图像中的位置不固定。而训练用的虹膜图像数据库大多都采用固定位置,固定距离的成像设备采集,所以训练用的虹膜图像的虹膜区域位置区域比较一致。如果不对训练用的虹膜数据库的虹膜图像进行处理,那么训练好的神经网络对于实际应用场景中采集的虹膜图像的分割效果会因为虹膜区域位置面积不一致而准确率下降。因此,本文采用随机缩放的数据增强方法对训练图片做处理,进行随机缩放后的虹膜图像中的虹膜区域的大小和位置具有一定的多样性,能有效提高训练网络的泛化能力。
(4)裁剪。裁剪操作是将图片调整为一个固定的分辨率,这一步骤的目的有两个,一是随机缩放后的图像分辨率会发生改变,进行裁剪操作后使图片恢复到原来大小,而只使虹膜区域的大小和位置发生改变。二是固定分辨率的图片便于批量训练,提高数据处理速度和训练效率。
3.3 评估指标
本文提出的PI-Unet是应用于异质虹膜分割的神经网络模型,所以既要追求准确率,又要在参数量和计算量上尽可能少。所以本文使用mIoU 和F1 分数作为准确率的评估指标,params 和flops 作为参数量和计算量的评估指标。
mIoU是计算真实值和预测值两个集合的交集和并集之比的平均值,其计算公式如下:

其中,pij表示真实值为i,被预测为j的个体,pji表示真实值为j,被预测为i的个体,k+1 是类别个数。mIoU的取值范围为[0,1],越接近于1 则表示分割准确率越高。
F1 分数同时兼顾了精确率和召回率,是两者的调和平均数,其计算公式如下:

其中,precision即准确率,recall即召回率。F1分数的取值范围为[0,1],越接近于1则表示分割准确率越高。
params即模型所有带参数的层的权重参数总量,主要由卷积层、全连接层、BN层等的权重参数组成。使用params可以衡量神经网络模型的参数量(空间复杂度),params值越小则表示模型参数量越小。
flops 是floating point operations 的缩写,即浮点运算数。使用flops 可以衡量神经网络模型的计算量(时间复杂度),flops值越小则表示模型计算量越小。
3.4 实验结果
在红外图像CASIA-iris-intervel-v4 和可见光图像UBIRIS.v2 虹膜数据库上,将本文提出的异质虹膜分割神经网络模型PI-Unet 与传统虹膜分割算法Caht[21]、Ifpp[22]、Wahet[23]和虹膜分割神经网络Unet[6]、FD-Unet[9]、DFCN[11]进行mIoU和F1分数两项准确率的评估指标的对比。为了证明本文提出的数据增强方法以及损失函数对异质虹膜分割准确率有提升作用,将该训练策略应用于Unet进行训练,并进行mIoU和F1分数两项评估指标的测试。对比结果如表3 所示。从对比结果可以看出,与传统虹膜分割算法相比,虹膜分割神经网络准确率更高,鲁棒性更强,但是红外图像(CASIA 数据库)与可见光图像(UBIRIS.v2数据库)两者之间的准确率仍有一定差距,即对异质虹膜图像的分割效果不好;与Unet相比,使用了本文训练策略的Unet在mIoU和F1分数上都有较大提升,可以得知本文提出的数据增强方法和损失函数对于训练异质虹膜分割神经网络有帮助。与其他虹膜分割算法相比,本文提出的异质虹膜分割网络模型PI-Unet 在CASIA-iris-intervel-v4 和UBIRIS.v2 上 都实现了更高的mIoU和F1分数,对异质虹膜图像的分割效果最好。综上所述,本文提出的PI-Unet 神经网络以及数据增强方法和损失函数能够训练出一个准确率高的异质虹膜分割神经网络模型。

表3 虹膜分割算法准确率对比Table 3 Comparison of iris segmentation accuracy
为了体现本文提出的PI-Unet能够适用于实际应用场景,对PI-Unet与分割准确率仅次于PI-Unet的Unet进行params和flops的对比,对比结果如表4所示。从对比结果可以看出,在输入图片分辨率为288×320×3的情况下,本文提出的PI-Unet 在params 和flops 上有明显优势,更适用于实际应用场景中的边缘计算设备。

表4 效果最好的两个网络参数量和计算量对比Table 4 Comparison of params and flops of the most accurate two network
本文提出的PI-Unet对于红外虹膜图像的分割效果如图5所示,对于可见光下的虹膜图像的分割效果如图6所示。可以看出,本文提出的PI-Unet对于异质虹膜图像的分割效果很好,能够对不同的成像环境下的虹膜图像都进行准确地分割。对于闭眼图像,PI-Unet 还具有一定的检测能力。如图7所示,对于此种类型的眼睛图像,PI-Unet 会判断该图像不存在虹膜区域。而在训练集的所有虹膜图像中并不存在闭眼图像,所以可以得知,PI-Unet 在训练过程中准确且充分地学习到了虹膜的特征。

图5 PI-Unet对红外虹膜图像分割效果Fig.5 Segmentation results of PI-Unet for infrared iris images

图6 PI-Unet对可见光虹膜图像分割效果Fig.6 Segmentation results of PI-Unet for visible iris images
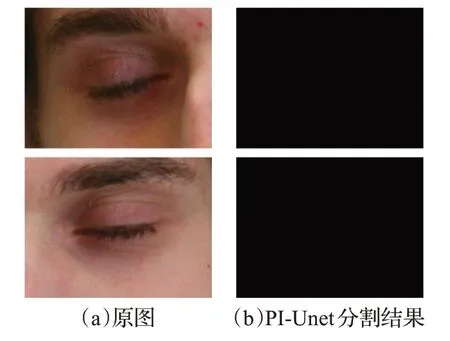
图7 PI-Unet对闭眼图像分割效果Fig.7 Segmentation results of PI-Unet for eye closed images
4 结束语
虹膜分割是虹膜识别流程中最为重要的一个步骤,关系到整个虹膜识别系统的准确率。目前虹膜分割算法的局限性在于无法对异质虹膜图像(可见光和红外图像)进行准确的分割。本文针对异质虹膜图像,提出PI-Unet 神经网络模型以及适合于虹膜分割的数据增强方法和损失函数。实验结果证明,使用PI-Unet对异质虹膜图像进行分割,在CASIA-iris-intervel-v4 和UBIRIS.v2 的mIoU 分别达到了97.50%和95.95%,F1 分数分别达到了0.990 7和0.989 0。与其他虹膜分割神经网络模型相比,PI-Unet 的两项准确率评估指标均为最佳,同时PI-Unet 的参数量仅为2.49×106,计算量仅为1.32×109,在实用性和快速性上均为最佳。本文的研究工作仍有不足之处,PI-Unet 在异质虹膜分割任务的准确率已经很难提升,但是在参数量和计算量方面仍有提升空间。接下来的研究方向应着力于进一步减小网络模型的参数量和计算量,使得训练好的神经网络模型更适用于低性能的边缘计算设备。
