基于注意力生成对抗网络的单幅图像去雨方法
2021-08-06朱德利胡雪奎
朱德利,熊 昌,胡雪奎,李 炜,王 青
1.重庆师范大学 计算机与信息科学学院,重庆 401331
2.重庆市数字农业服务工程技术研究中心,重庆 401331
下雨是一种常见的天气现象,当在雨天进行拍摄任务时,雨条纹会对场景中的内容进行遮挡和干扰,从而使拍摄到的图像质量下降,直接导致主观视觉效果变差,并降低后续计算机视觉系统的性能,对无人驾驶、道路监控等实际应用产生极大的影响。因此,如何改善有雨图像的清晰化问题受到国内外科研工作者的广泛关注。然而,单幅图像中并不具有视频信号中丰富的时空相关性,不能利用这些时空特征,这进一步增加了单幅有雨图像清晰化的难度。因而,对单幅图像去雨问题进行研究具备极大的意义。
目前,单幅图像去雨的方法可大致分为两类,基于模型驱动和基于数据驱动。其中,基于模型驱动的方法侧重于挖掘和利用图像的先验知识,并将其用到解决反问题时的约束和建模中去,再通过设计优化算法求解模型,获得无雨图像;而基于数据驱动的方法,主要是以深度学习为代表,通过构建神经网络,并采用仿真数据和反向传播算法对神经网络进行监督训练,让网络从数据中自行学习有雨图像到无雨图像的映射关系。
Kim 等[1]通过非均值滤波器将雨条纹移除,但是该方法的缺点是物理模型限制了其性能。Kurihata等人[2]使用PCA 来学习雨的形状,并试着将测试图像中的一个区域与所学雨的区域相匹配。然而,由于雨是透明的,形状各异,尚不清楚需要了解的雨数量有多大,如何保证PCA 能够模拟雨的各种外观,以及如何防止局部类似雨的区域被检测为雨。Luo等[3]提出了一种判别性稀疏编码,用于将雨条纹与图像背景分开,不足的地方是该方法去完雨后的图像上仍有雨条纹残留。当图像中的物体结构和方向与雨条纹相似时,便很难在去除雨条纹的同时又有效地保存物体的结构信息。在2017年之后单幅图像去雨主要采用基于深度学习的方法,Fu等[4]提出了一种名为DerainNet的去雨方法,将图像的高频部分输入到卷积神经网络中进行训练学习,但是该方法会造成图像色泽上的损失,在背景区域仍然存在雨条纹的残留痕迹,从而导致去雨效果不理想。Zhang 等[5]将条件生成对抗网络应用于单图像除雨任务。该方法能够捕捉信号保真度以外的视觉特性,并以更好的光照、颜色和对比度分布呈现结果。然而,当测试雨图的背景与训练集的背景不同时,有时会产生视觉伪影。Wei 等[6]提出一种半监督学习方法,以利用合成配对数据和未配对真实数据中的先验。在该方法中,残差被表示为输入雨图与其期望网络输出之间的特定参数化雨带分布。在雨带分布模型的指导下,基于合成的成对降雨图像训练的模型适用于处理真实场景中的各种降雨。然而,该方法并没有显示出有效的去雨效果,特别是对于真实的去雨图像。Qian等[7]提出了一种基于生成对抗网络[8]的去雨方法,可以有效地去除玻璃上的雨但对雨线移除处理效果不好。Jin 等[9]通过引入自监督约束和从未配对的雨和干净图像中提取内在先验,提出了一种无监督的去监督产生式对抗网络(UD-GAN)。设计了两个协同模块:一个模块用于检测真实去雨图像与生成的去雨图像之间的差异;另一个模块用于调整生成结果的亮度,使生成的结果更加直观。这种方法能够从雨图像中去除真实的雨,但不可避免地会丢失一些细节,特别是在雨带密集的情况下。
为了解决雨条纹对图像背景遮挡问题,本文提出基于注意力生成对抗网络的图像去雨方法。在生成网络部分,利用雨线提取模块来提取雨条纹特征,然后通过空间关注模块生成雨线注意力图,最后结合雨线注意力图和有雨图像通过上下文自动编码器生成清晰无雨图像。
1 基于注意力生成对抗网络的单幅图像去雨方法
因为当前基于深度学习的单幅图像去雨方法都是通过设计不同的网络结构,然后采用监督学习的方式,将有雨图像和对应无雨图像作为训练数据,利用反向传播算法更新网络参数,使网络可以学习出从有雨图像到无雨图像(如图1)。可以知道,解决此类问题的关键在于如何设计深度神经网络结构,以获取更加有效的特征表示。
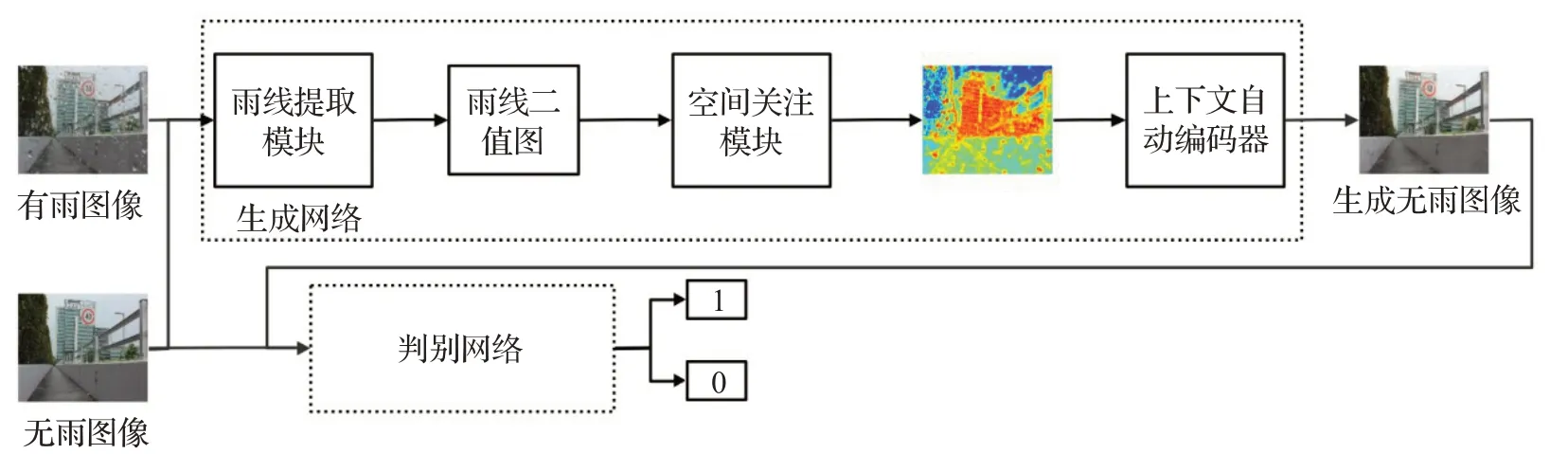
图1 网络结构图Fig.1 Structure of network
1.1 生成网络结构设计
生成网络由三个模块组成:雨线提取模块、空间关注模块、上下文自动编码器。首先,雨线提取模块的目的是为后续模块提取有效的雨线二值图,然后利用空间关注模块准确地定位降雨条纹的位置,以增强泛化能力。最后,使用注意力图来指导上下文自动编码器执行去雨操作。
1.1.1 雨线提取模块
本文使用快速导向滤波器[10]和Haar 小波变换[11]进行检测雨线。雨线提取模块处理流程如图2所示。
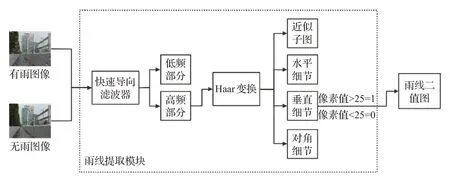
图2 雨线提取模块流程图Fig.2 Flow chart of rainline extraction module
导向滤波是一种保边滤波。它在计算上的时间复杂度是O(N),即与当前图像像素点个数N成线性关系,与滤波器大小无关。导向滤波还能够有效地抑制梯度翻转的现象。而快速导向滤波在导向滤波的基础上,进一步简化计算,通过下采样,将时间复杂度降低为O(N/s2),其中s为采样率。该滤波能够通过引导图像保留边缘信息,磨平区域信息中的噪点。因此能有效地将高频雨条纹细节信息分离出来,如图3。它的输入是要处理的图像和引导图像,将雨图作为要处理的图像,选择雨图对应的无雨图像作为引导图像。经快速导向滤波器处理后雨线细节如图3(c)所示。

图3 快速导向滤波器图像Fig.3 Fast steering filter image
再通过使用Haar 小波变换[12-13]对雨线细节图进行水平和竖直两个方向进行低通和高通滤波。小波分解示意图如图4所示,首先将一幅N×N的图像先进行滤波,再作1/2的抽取,把得到的水平方向的低频子带放在左边,高频子带放在右边;然后再进行列滤波,垂直方向的低频子带放上边,高频子带放下边。这样得到的小波变换是由4 个的子图构成,图像小波分解的正变换可以根据变换方式进行扩展。
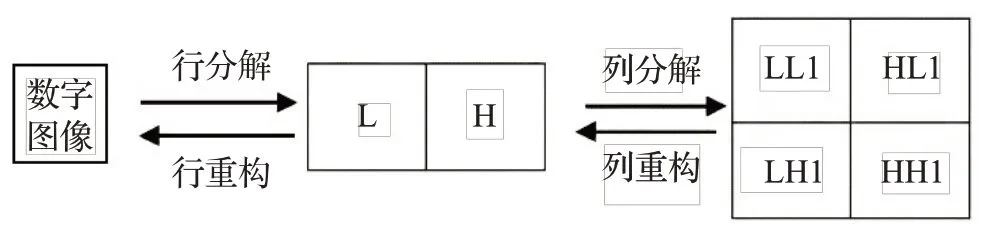
图4 小波分解示意图Fig.4 Wavelet decomposition schematic
通过Haar 小波对雨线细节图分解后,能够突出高频域中的雨条纹,有助于后续的特征提取,进而消除雨条纹噪声。如图5 所示,近似子图表示图像的低频信息,水平细节图图像的水平方向纹理边缘信息,垂直细节图图像垂直方向的纹理边缘信息,对角线细节图图像对角方向的纹理边缘信息。
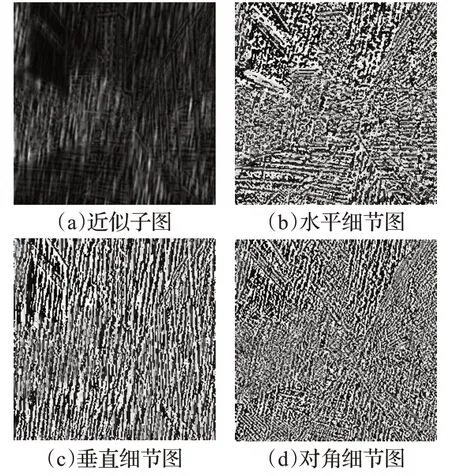
图5 雨线细节图小波分解示例图Fig.5 Wavelet decomposition schematic of rainline detail
由于雨噪声的方向性,垂直细节图包含更多的雨条纹信息。在获得雨线区域及边缘细节信息后,使用一个阈值来确定是否属于雨线区域及边缘结构,在实践中,经过测试,将阈值设置为25,其余小于25的像素值为0,大于等于25 的像素值为1,得到二进制矩阵MR,再用MR引导生成雨线注意图。
1.1.2 空间关注模块
视觉注意力机制模型已被应用于定位图像中的目标区域,以捕捉区域的特征。这一思想已被用于视觉识别和分类。因此,视觉关注对于生成无雨背景图像是非常重要的,因为它允许网络知道去除雨应该集中在哪个区域。通常,神经网络通过大量数据识别对象,以训练网络识别对象的能力,但是训练后的网络中图片的整体价值是相等的,也就是说,这些特征在神经网络的眼中并没有什么不同,并且网络不会在某个区域上过多关注,因此计算机视觉中的关注机制的基本思想是使网络具有忽略无关信息并专注于关键信息的能力。
空间关注模块结构如图6 所示是一个三层的循环视觉注意网络。每层循环视觉注意网络由深度残留网络(ResNet)[14],卷积长短记忆网络单元(ConvLSTM)单元[15]和标准卷积层组成。ResNet 主要用于从输入图像和上一个块的蒙版中提取特征。每个残差块包括一个具有LrReLU非线性激活函数的具有3×3卷积的两层卷积核;它被用于图像特征提取。提取的特征图和初始化的注意图被拼接并转移到ConvLSTM单元中进行学习。
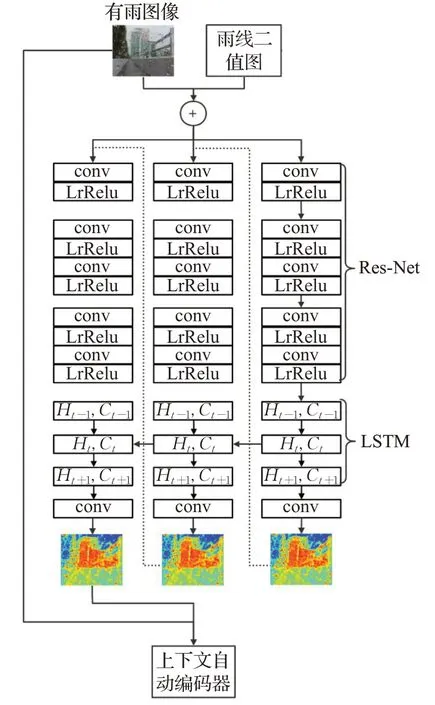
图6 空间关注模块结构图Fig.6 Structure of space concerned module
ConvLSTM 单元包括一个输入it、一个忘记门ft、一个输出门ot以及一个单元状态Ct。
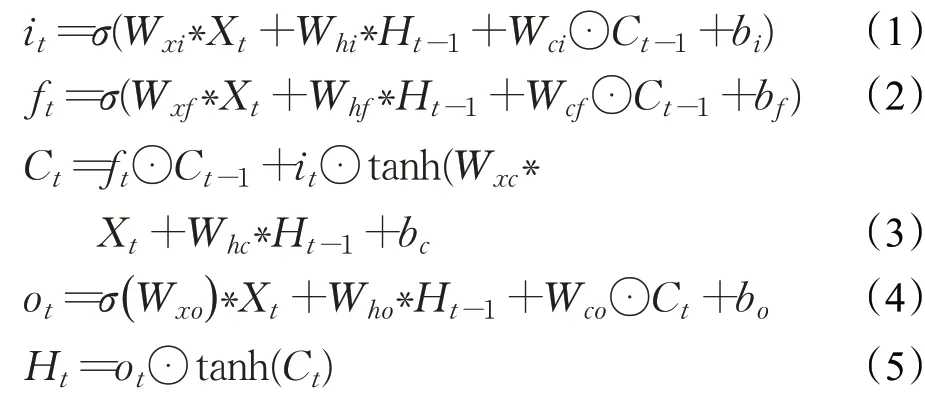
其中,Xt是由ResNet 生成的特征;Ct对将要转递到下一个LSTM 的状态进行编码;Ht代表LSTM 单元的输出特性;运算符∗表示卷积运算。LSTM的输出特征随后被输入到卷积层,这将产生一个2D的注意图。
1.1.3 上下文自动编码器
本文使用上下文自动编码器作为无雨图像生成部分。上下文自动结构示意图如图7所示,与传统的U-net结构类似,有16 个conv-LrRelu 块可对输入执行两次下采样操作和两次上采样操作,并添加了跳过连接以防止在下采样期间丢失高分辨率功能。不同地,在上下文自动中间编码器,使用具有不同扩张因子的四个连续扩张卷积层,以在不增加参数的情况下将接收场增加到不同程度。这样,不仅可以从雨线位置的像素中去除雨条纹,还可以通过利用雨线位置和背景图像之间的相关性更准确地填充遮挡的部分。同时,连接不同大小的接收场意味着可以在每层之间获得不同大小的信息,从而解决了网格伪影的问题。
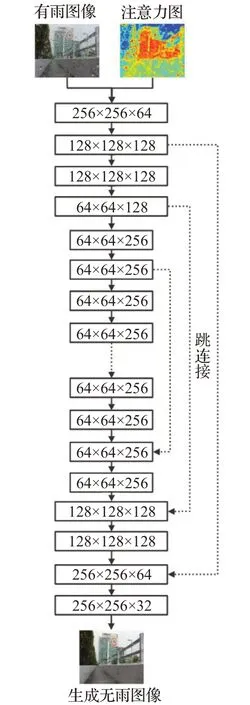
图7 上下文自动编码结构图Fig.7 Structure of context automatic encoder
1.2 判别网络结构设计
为了区分假图片与真实图片,一些基于GAN 的方法在区分部分采用了全局和局部的图片内容一致性。就像在图像修补中给出要恢复区域的情况一样,用于直接区分的局部区分策略也很有用。因此,使用注意力判别器直接确定所生成图像的雨线区域是否正确是最有效的方法。判别网络的功能等效于二分类器。判别网络由9 个卷积层组成。每个层都连接到LrRelu 激活函数。5×5卷积核用于提取和融合纹理特征。6个输出通道分别为8、16、32、64、128 和128。从鉴别器的第六层提取特征,通过卷积层输出注意掩码,然后将鉴别网络的第六卷乘以注意掩码,然后再输入下一层,这是因为鉴别器将注意力集中在注意力图上。后面的三层卷积使用(跨步4)卷积层,并且缺少池化层主要是借鉴了深度卷积生成对抗网络(DCGAN)中提到的技术,它不仅可以提取高维纹理特征,还可以使输入特征更小并且更可控。最后,通过两层全连接层,对图像特征进行降维后进行加权,然后输出一个特定值来表示输入图像是去雨图像可能性,将其激活,将输出值限制为[0,1]。判别网络结构如图8所示。
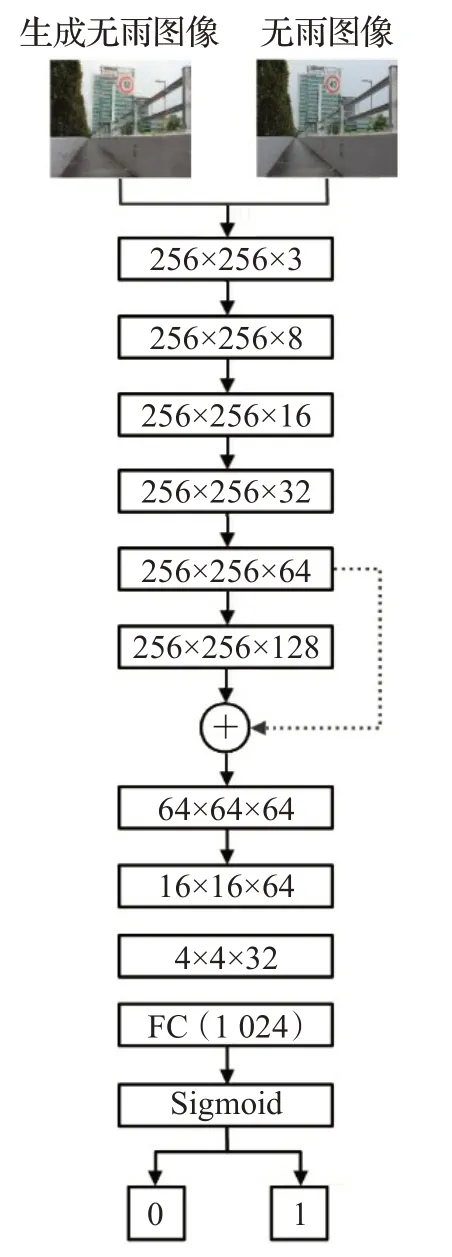
图8 判别网络结构图Fig.8 Structure of identifying network
1.3 网络损失函数定义
为了优化上述所提改进生成对抗网络以获得较好的去雨效果,本文通过最小化重建生成图像与真实图像之间的差异来调整网络参数。
采用以下损失函数训练生成网络:
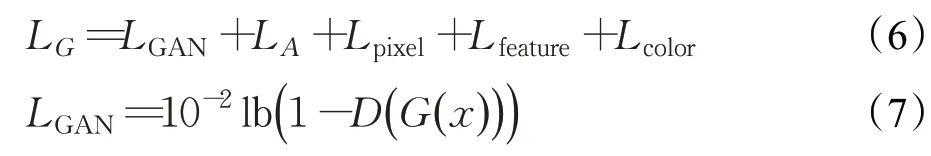
其中,LA表示雨线注意力图和雨线二值掩码图之间的MSE 距离,并通过计算用于约束关注图生成的降雨图像和原始清洁图像之间的差异来获得二元蒙版图。使用Lpixel损耗来测量每像素的重建精度以捕获低频信息,并且Lpixel损耗可以防止梯度爆炸。Lfeature用于约束图像特征空间的损失,利用训练好的VGG16 网络对生成图像与真实图像的进行特征图提取,计算两张特征图之间的MSE距离,作为特征空间上的误差。Lcolor表示去雨图像和真实图像色差的损失,其中N是像素数的总和,为了使去雨后的图像在颜色上更接近地面真实,引入了CIEDE2000 色差作为损失函数的一项。为了计算去雨图像和真实图像之间的色差,需要将RGB图像转换到Lab颜色空间。
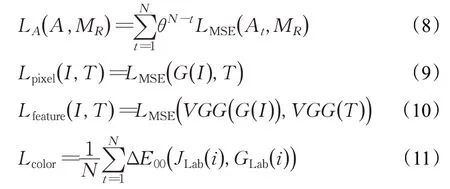
在公式(11)中E00表示Lab颜色空间中两个图像之间每个像素的色差,JLab(i)和GLab(i)是真实无雨图像和生成去雨图像对应的Lab颜色空间。
判别网络的目的就是区分生成图像和真实图像,采用以下损失函数训练对判别网络进行训练:
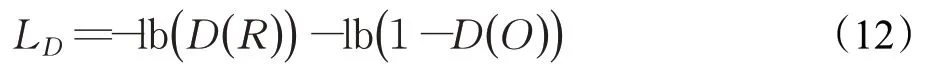
2 实验
本文实验环境为Intel®Xeon®Silver 4114 CPU,64位的Windows10,使用NVIDIA TITAN V 型号的GPU对网络训练并行加速,所使用的编程语言为Python,并采用谷歌公司开发的TensorFlow 深度学习工具箱进行网络的搭建。训练网络时,随机选取输入图像(有雨和无雨图像对)上256×256像素大小的图像块作为一对样本输入到卷积神经网络中。网络模型训练采用Adam算法下降策略,初始学习率大小设定为0.000 2,小批量数据大小为1个样本,最大迭代次数为80 000。
2.1 实验数据集及评价指标
由于从现实世界中难以获取有雨图和对应无雨图的图像对,训练和测试选用公开数据集,选取了Fu 等提出的Rainy image dataset 和Rain800。Rainy image dataset数据集中有1 000张真实无雨图像以及对应1 000张合成有雨图像。Rain800的训练集总共由700个图像组成,其中500 个图像是从UCID 数据集的前800 个图像中随机选择的,200 个图像是从BSD500 的训练集中随机选择的。测试集由总共100 个图像组成,其中从UCID 数据集中的最后500 个图像中随机选择50 个图像,并从BSD-500 数据集的测试集中随机选择50 个图像。此外还选取了Rain12、Rain100L 以及Rain100H 数据集测试本文所提方法的性能。Rain12 包括12 幅合成的雨图,Rain100L 有100 张低雨量的合成雨图,Rain100H有100张高雨量的合成雨图。
鉴于本文所用测试集有可供参考的真实图像,因此,选择峰值信噪比(PSNR)[16]和结构相似度(SSIM)[17]来作为算法评价指标,其中PSNR 常用于测量图片的重建质量,PSNR 值越高说明图片的重建质量越好;SSIM 是一种考虑人眼视觉感知的图像质量评价方法,常用来衡量两幅图像的相似度,该值越大表示两幅图像之间越相似,算法性能越好。值得一提的是,本文旨在于无需图像增强作为后处理即可有效去除单幅图像上的雨条信息。为了进行公平比较,本文实验对比是在不同去雨方法未采用图像增强作为后处理的设定下进行的。
2.2 实验结果与分析
表1 列出了本文所提方法与目前主流单幅图像去雨方法在上Rain12、Rain100L、Rain100H以及Ran800数据集上的SSIM与PSNR比较。可以看出本文所提出的方法在两种评价指标上对比各种方法中具有一定的优越性。
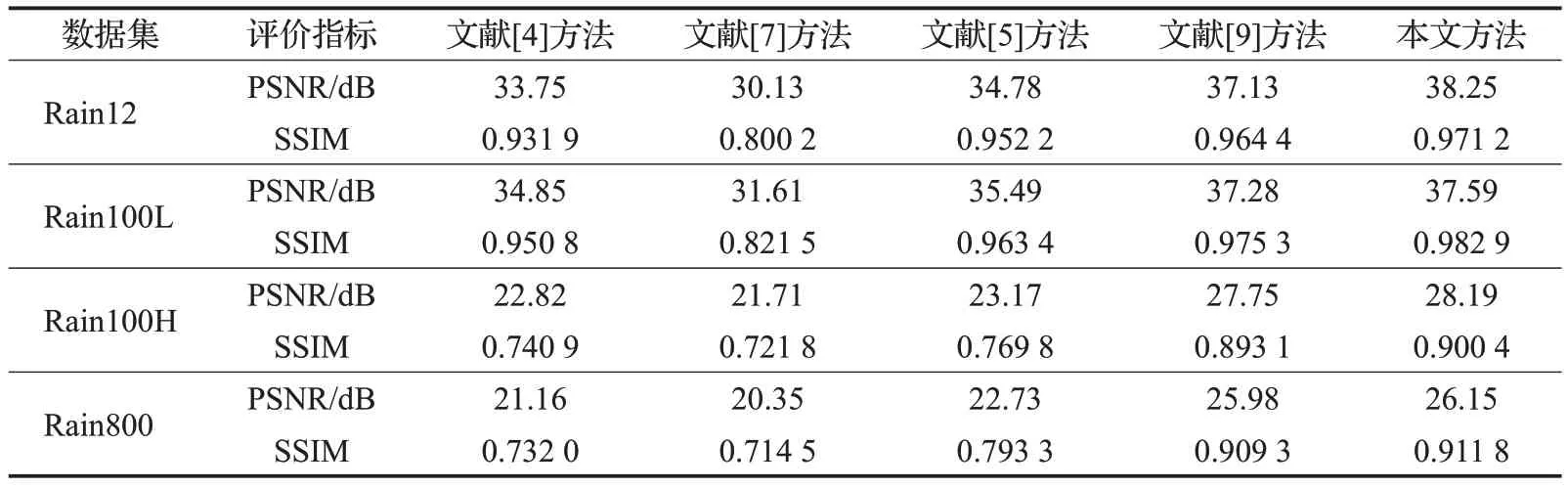
表1 不同方法的PSNR和SSIM对比结果Table 1 Result of different methods in PSNR and SSIM
本文所提方法与主流去雨方法在四幅不同图像去雨效果对比结果如图9所示,局部细节放大信息如图10所示。从视觉效果上可以看出,文献[7]方法的方法得到的去雨图有显著的雨水残留,文献[4]方法、文献[5]方法、文献[9]方法在去雨图像有明显的去雨痕迹而本文所提方法能够有效地去除有雨图像上的雨条,并且去完雨条后的图像背景上几乎没有雨条痕迹残留。表明本文所提方法所得到的去雨图像具有更好的视觉效果,该结果进一步验证了本文所提方法的优越性。

图9 合成图像去雨效果对比图Fig.9 De-raining effect of synthetic image comparison

图10 合成图像细节放大图Fig.10 Enlarged detail of composite image
为了验证本文提出的单图像雨模型也可以应用于现实生活中的雨图像,并强调该模型的实际应用价值,测试在雨天拍摄的真实降雨图像。真实雨景图像的测试结果如图11所示,从视觉上可以看出,尽管本文所提方法对真实雨景下的图像仍然具有良好的去雨效果。

图11 真实图像去雨效果Fig.11 De-raining effect of real image
为了验证结构中添加的每个组件的有效性,在测试集上针对每个组件的不同组合进行了结构分析。如表2所示,上下文自动编码器是基准模块,第二列是雨线提取模块,第三列是空间关注模块,第四列PSNR 指标。结果表明网络中的每个组件都在一定程度上改善了最终结果。通过消融实验,验证了所提出方法中各个模块的有效性。
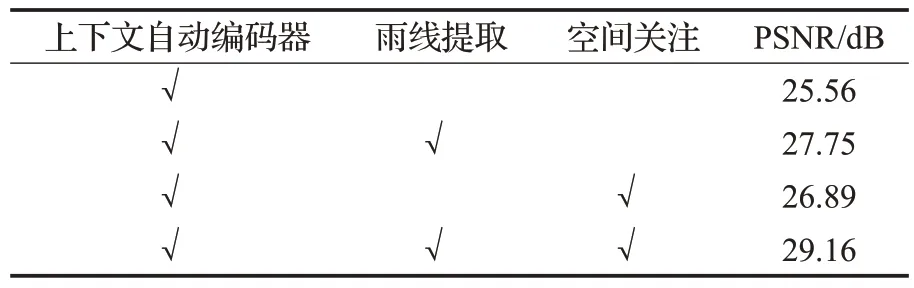
表2 生成网络结构分析Table 2 Analysis of generate network structure
表3 给出了本文方法与其他主流方法在图像尺寸大小为(3×320×240)上同时采用相同的GPU 硬件环境的去雨运算时间上的对比结果。本文所提方法在去雨运算速度上具有一定的优越性。

表3 图像去雨速度测试Table 3 Test of image de-raining
3 结束语
本文提出了一种基于注意力生成对抗网络单幅图像去雨方法。生成网络使用雨线提取模块生成雨线二值图,以为后续的空间关注模块提供有价值的降雨条纹特征,然后空间关注模块生成雨线注意力图,以指导上下文自动编码器生成清晰无雨图像。在综合测试数据集和真实图像上进行实验,对比几种深度网络去雨方法,无论是在去雨图像的视觉感观上,还是在PSNR 和SSIM数据量化上,都处于领先的地位。但是,本文的网络有局限性。例如,雨天经常伴随着雾。对于真实世界的多雨图像,只能去除雨水条纹,但是如果没有雾,将无法恢复清晰的背景图像。因为不可能获得真实世界的无雨无影图像对,并且在合成图像中,仅合成了雨条纹,而没有模拟雾。在进一步的研究中,可以改善合成图像对,以训练网络在去除雾气并消除雨水条纹后恢复清晰图像。
