基于静态特征融合的恶意软件分类方法
2021-08-06杨春雨张思聪李小剑
杨春雨,徐 洋,张思聪,李小剑
贵州师范大学 贵州省信息与计算科学重点实验室,贵阳 550001
国家互联网应急中心2020 年第8 期网络安全信息与动态周报指出,境内感染网络病毒的主机数量达到了58.6 万,被木马或僵尸程序控制的主机约52.7 万个,感染飞客蠕虫的主机约5.9 万,木马和僵尸程序较上周增长了3.4%,飞客蠕虫较上周增长了4.5%[1]。随着互联网的发展,快速增长的恶意软件无疑给国家和社会带来了巨大的经济损失,有必要提出更加精准快速的分析方法。
传统的恶意软件分析方法分为静态方法和动态方法[2]。静态方法主要是对恶意软件和其反编译文件提取的静态特征进行分析,但是仅仅采用单一类型的特征容易受到代码混淆或加壳等技术的影响,对多种特征融合和降维,然后使用分类算法对恶意软件进行分类往往能够获得更好的效果。动态分析方法主要是在虚拟环境中执行恶意软件样本,记录恶意软件的行为特征,如系统调用名称、上下文参数、环境变量等[3],然后基于动态行为特征进行分类,常用的恶意软件动态分析平台有Cuckoo Sandbox。恶意软件检测是一个二分类问题[4],而恶意软件分类是根据不同恶意软件家族的相似特征来识别出样本,是一个多分类问题。
2010年,Conti等[5]首次提出将二进制文件转化为灰度图像。2011年,Nataraj等[6]提出将恶意软件转化成灰度图像,利用同一恶意软件家族的灰度图具有纹理的相似性,提取灰度图的Gist 特征,使用KNN 作为分类器,在Malimg数据集上取得了98%的准确率。
2012 年,白金荣等[7]提取了恶意软件的结构特征,通过Wrapper算法对特征进行筛选,对恶意软件检测达到了99%的准确率。
2016年,任卓君等[8]通过将恶意软件转化成黄、绿双色通道的位图,将位图转化为像素归一图,使用Jaccard距离度量像素归一图的相似性,使用KNN作为分类器,在353个样本上达到了95.18%的准确率。
2019年,郎大鹏等[9]通过将恶意软件和Asm文件表示成灰度图的形式,提取灰度图的灰阶共生矩阵(Graylevel Co-occurrence Matrix)[10]和Gist 特征,并融合Opcode 3-gram序列特征,使用RF作为分类器,在2 625个样本上取得了85%的准确率。
2019年,张景莲等[11]提取恶意软件的灰度图前2 500个像素点的值和图像颜色直方图,再融合Opcode 2-gram序列特征,在Kaggle 恶意软件数据集上达到了99.56%的分类准确率。
2020年,郑锐等[12]同时设置25个安装64位Windows7的虚拟机执行恶意软件样本,通过Cuckoo Sandbox 平台收集样本的API 调用序列,使用双向LSTM 模型对6 681 个恶意软件样本进行分类,取得了99.28%的准确率。
通过上述可知,利用可视化技术提取恶意软件的特征,再融合其他语义特征分类取得了很好的效果。但是灰度图和n-gram 的特征维度比较高,以字节的2-gram模型提取为例,每个字节的范围是0~255,提取文件字节的2-gram 序列将会有65 536 维的特征,而一个2 MB的恶意软件转化成的灰度图大约具有2 097 152个像素点。动态分析耗费较长时间和大量硬件资源,且虚拟环境配置不当会导致缺少.dll 文件等错误,从而使恶意软件样本不能执行,收集不到有用信息。静态分析可以作为安全引擎的重要保护层[13],在不执行恶意样本的前提下提前预测恶意软件所属家族。因此针对现有恶意软件分类方法融合的静态特征维度高、特征提取耗时、Boosting 算法对大量高维特征样本串行训练时间长的问题,本文提出一种基于静态特征融合的恶意软件分类方法。利用相同恶意软件家族的样本具有数据、代码、结构的相似性,提取原文件和Lst文件的灰度图特征、结构特征、Lst 文件内容特征,并将特征进行融合和分类。通过融合多类特征分类,消除代码混淆对单一特征分类的影响,同时对训练集采用GOSS 采样和LightGBM 分类器训练,大幅减少训练时间。
1 特征工程
1.1 灰度图
同一家族的恶意软件代码存在较高的复用性,通过复用代码往往能够快速地生成新的恶意软件,因此将同一家族恶意软件转化为灰度图时,灰度图存在着较高的相似性。Kaggle 恶意软件分类竞赛冠军[14]提取Asm 文件前800 个像素作为一种融合特征对恶意软件进行分类,但是结果不具有可解释性。在采用恶意软件灰度图像素点的值作为特征时存在的问题是样本转化为灰度图时会存在十几万到几百万个像素点,从中选择对分类有用的特征比较耗时。
将文件转化成灰度图的过程如图1 所示。本文使用IDA Pro 对样本反编译输出Lst 文件,将原文件和反编译文件以二进制形式打开,以8位二进制数为一个无符号整数作为一个像素点,像素点的值的范围是0~255,参考表1设定图像初始宽度,图像高度根据样本大小设定,将样本转化成灰度图。通过合适的插值方法对灰度图进行下采样修改图像的尺寸,本文采用了32×32、48×48,64v64 三种图像尺寸,保留了恶意样本的全局信息的同时达到了降维的效果。常用的插值算法有最邻近、双线性、双三次、Lanczos。Lanczos算法较其余三类算法具有速度快,效果好的优点。因此采用Lanczos算法进行下采样,然后提取灰度图全部像素点的值作为特征。图2(a)和图2(b)为一个蠕虫家族恶意样本的Lst文件和EXE文件转化成的灰度图像。

图1 灰度图转化过程Fig.1 Process of converting to grayscale

表1 图像的初始宽度和样本大小的关系Table 1 Mapping of sample size to initial width of image

图2 两种文件的灰度图Fig.2 Grayscale images of two types of files
1.2 结构特征
PE(Portable Executable)文件是Windows操作系统使用的可执行文件,当其载入内存执行时具有固定的数据结构,常见的EXE、DLL、OCX、SYS、COM 文件都是PE文件。当PE文件载入内存后,称其为映像(IMAGE),图3 为PE 文件的结构。MS-DOS 头用来兼容MS-DOS操作系统,NT头包含PE文件的主要信息,节表是PE文件节信息,节表后面是包含了文件数据和代码以及资源的节。

图3 PE文件的结构Fig.3 Structure of PE file
同一恶意软件家族代码复用导致恶意软件作者或团队编码具有编码相似性[15],因此当同一家族恶意软件载入内存执行时其结构信息和数据也应该具有一定的相似性,因此本文将EXE文件以PE文件格式解析,提取样本的文本、全局、头部、导入导出表、节特征,特征提取通过LIEF实现。此外还提取了文件的字节直方图和字节-熵直方图[16]。
文本特征:PE文件中的文本表示了PE文件运行时候的信息。且文本可以较为直观地反映出PE文件的行为[17]。本文统计长度大于5的由可打印字符组成的字符串的个数、字符串的平均长度以及可打印字符的分布和熵。可打印字符是指ASCII 码范围在0x20~0x7E 之间的字符。统计含有“C:”(系统路径)、“http://”(URL 请求)、“https://”“HKEY_”(注册表)有特殊含义的字符串个数。
全局特征:统计文件的映像大小,符号表中符号的个数,以及是否包含线程局部存储(Thread Local Storage)、debug 信息、资源文件和重定向。TLS 的主要作用是引入程序执行前调用的回调函数。Trojan 对TLS 的使用率高达47.3%[18]。
头部特征:提取并使用列表存储IMAGE_FILE_HEADERS 中的文件属性(如分离了debug 信息并存储在单独文件中的样本具有IMAGE_FILE_DEBUG_STRIPPED属性、文件是否可写可执行属性等)、子系统名称。提取并使用列表存储IMAGE_OPTIONAL_HEADERS中的导入DLL属性,统计映像、链接器、子系统、操作系统的版本号、代码段大小和所有头部大小。
导入导出表:统计导入导出表个数,对于导入的DLL文件和导入函数名用冒号连接并使用列表存储,如advapi32.dll:AdjustTokenPrivileges表示使用了advapi32.dll中的AdjustTokenPrivileges 函数,该函数常用来启动或禁用特定访问权限,执行进程注入的恶意软件会调用该函数获得额外权限。
节特征:使用列表分别存储样本每个节的名称和节的物理大小、映像大小、熵的对应关系,如列表1为([‘.text’,19 456),(‘.rsrc’,512)],列表2为([‘.text’,20 480),(‘.rsrc’,8 192)],列表3为([‘.text’,5.476 359 828 917 223),(‘.rsrc’,1.434 135 665 302 386 2)],并使用列表存储程序入口点节的名称和其属性的对应关系。统计可执行节、可写节、异常节的个数,异常节包含物理大小为0 的节和名字为空的节。Virus可写节的个数占其节数高达75.6%,而Backdoor的异常命名节数通常占其节数的82%[18]。
Hash Trick:在自然语言处理中Hashing Trick是一种快速且节省空间的文本向量化和特征降维方法。在每一种类型特征提取的过程中,对于以列表或者文本形式出现的特征,如文件的属性、导入导出表、节特征,使用Hash Trick算法将其转换成维度固定的特征向量。
字节直方图直接体现了每个恶意软件的字节分布。字节直方图计算公式:

其中,K表示字节的十进制值,N表示文件的字节总数,nk表示字节十进制值为K的个数。
本文实现16×16的字节-熵直方图。字节-熵直方图通过滑动窗口实现,滑动窗口大小为2 048 Byte,步长为1 024 Byte。首先计算窗口内字节的熵,再将熵值乘二取整,使熵的值落在0 到15,最后将字节的值整除4,计算每个值的分布,并将字节分布累加到指定的熵值下。熵的计算公式:

其中,p(x)表示窗口内每个字节的概率。
字节-熵直方图实现的伪代码如下:

1.3 Lst文件特征
微软的Kaggle恶意软件数据集的原始文件是Bytes文件,且该数据集的Asm文件包含了节信息,而本文采用的Virustotal数据集的原始文件为EXE文件,IDA Pro反编译产生的Asm文件不包含节信息,因此在本文数据集上选择反编译输出Lst文件,在Asm文件的基础上包含了节信息。
如图4,对于反编译获得的Lst 文件,从每一行前缀能知晓汇编代码属于哪一个节,提取部分节的频数和关键字的频数。.text或者.CODE代表了代码节,.bss与.data节毗邻,其中包含的是初始化为0的变量或者未初始化的变量,.rsrc节包含了资源数据,.tls是线程本地存储节,关键字std::表示使用了C++中的输入输出标准,:dword表示定义为双字的标识符。通用寄存器可用于传送和暂存数据,也可参与算术逻辑运算,并保存运算结果,本文提取每个Lst 文件中的32 位通用寄存器的频数。Opcode 通常分为三类[19]:数据移动、算术/逻辑和控制流类型,从其中筛选出比较重要的Opcode,并统计其频数。表2 所示为32 位通用寄存器及本文统计频数的Opcode。

图4 Lst文件内容Fig.4 Contents of Lst file

表2 通用寄存器和OpcodeTable 2 Opcode and general register
1.4 标准化
为了消除不同类型特征之间量纲的影响,提高数据之间的可比性,需要对特征进行标准化处理,常用的标准化方法有Min-max标准化、Z-score标准化。本文采用Z-score标准化方法将各类型特征转化到同一量纲下。
标准化的过程如下:
其中X为训练集的特征矩阵,每一行是一个样本的特征,每一列是相同类型特征在不同样本的值,n为特征个数,m为特征维数,μj、σj是训练集某一维度特征的均值和标准差。首先求得训练集每一维特征的μ和σ并对训练集标准化,为减小误差使用训练集的μ和σ参数为测试集的每一维度的特征做标准化。

2 模型和算法
2.1 分类模型和特征处理模型
图5 为基于静态特征融合的恶意软件分类方法的分类模型,分为模型的训练阶段和测试阶段。训练阶段训练的分类器是LightGBM,LightGBM会对输入的特征进行预处理后再进行训练。

图5 分类模型Fig.5 Classification model
图6 为特征提取和处理流程,分别从原文件和Lst文件中提取四类特征,再选择不同类型的特征融合,最后进行标准化,为减小误差测试集的标准化使用训练集的均值和标准差参数。

图6 特征提取和处理流程Fig.6 Feature extraction and processing flow
恶意样本的每一种类型的特征使用样本的ID(样本的SHA256值)标识。选择特征融合和标准化的伪代码如下:


2.2 LightGBM
LightGBM[20]和XGBoost[21]都是对梯度提升决策树(Gradient Boosting Decision Tree)的高效实现。Light-GBM 引入Histogram 算法对特征进行离散化降低内存使用、GOSS 算法减少训练的样本数、EFB 算法减少特征维数,并具有支持GPU 并行学习的优点。在处理大量样本和高维特征时,计算速度和内存消耗明显优于XGBoost。XGBoost和GBDT算法的基分类器使用分类与回归树(Classification And Regression Tree)中的回归树,在分类问题中它输出的是样本属于每一类的概率,其生长策略是如图7 的按层生长(level-wise)策略,而LightGBM 采用更为高效的如图8 的按叶子生长(leaf-wise)策略,减少了很多没有必要的分裂开销。

图7 按层生长策略Fig.7 Level-wise learning

图8 按叶子生长策略Fig.8 Leaf-wise learning
直方图(Histogram)算法是一种把连续浮点型特征值离散化的算法,如把区间[0,0.3)之间的值离散化为0,[0.3,0.8)之间的值离散化为1。然后就可以统计区间内的样本个数和样本的梯度之和,再根据直方图寻找特征的最佳分裂点,减少训练时间。
单边梯度采样(Gradient-based One Side Sampling),是一种训练集采样方法,启用后每次迭代之前,对所有样本采样,计算每个样本的梯度绝对值并排序,设定一个比例采样梯度前a%大的样本组成集合A,为了使数据均衡,从剩余的小梯度样本中随机提取b%的样本组成集合B,然后使用集合A⋃B进行训练,对于小梯度样本在计算增益的时候赋予其(1-a)/b的权重。回归树的分裂基于信息增益,而信息增益使用分裂后的方差增益衡量[20],方差增益公式是:

其中,j是使用的分裂特征,d是样本特征的分裂点,n是A⋃B的样本数,xi是样本,Al是分裂的左子节点的大梯度样本,Bl是分裂的左子节点的小梯度样本,Ar和Br为分裂的右子节点的大、小梯度样本,gi是样本梯度,是分裂的左、右节点样本数。
因此可以设置a和b的值调整对训练集大、小梯度样本抽样的比例,在保证模型精度的情况下使得每次计算方差增益的时候减少计算次数,从而减少训练时间。
互斥特征捆绑(Exclusive Feature Bundling),本文所提取的特征存在互斥特征,即多个特征之间存在只有一个特征为非0的情况。如特征A的取值是[0,5),特征B 的取值是[0,20)且A 和B 互斥,则将B 的值加5 使其范围落到[5,25),然后合并特征A和特征B形成特征C,C的范围是[0,30),当C取值为10时等价于B取值为5。
本文对LightGBM 进行训练时,会提前设定a和b的值,然后LightGBM 会对图6 模型输出的特征进行处理。首先启用GOSS 算法,计算并提取梯度前a%大的样本作为本次训练的样本,并从剩余样本提取b%比例的小梯度样本加入训练样本,这一步主要是减少训练的样本数。然后使用EFB 算法合并互斥的特征减少特征的维数,这一步能够有效减少构建直方图特征的维度。最后使用Histogram算法将连续的浮点数特征在多个区间离散化,特征离散化的好处是可以减少对特征分裂点的寻找时间,使得寻找特征分裂点的开销从原来的需要遍历所有特征值减少为只需要遍历离散值。
3 实验
3.1 实验环境
本文的实验是在CPU 主频为2.6 GHz 的Intel i5-3230M,显卡为显存2 GB的NVIDIA GeForce 710M,内存为8 GB的Ubuntu 18.04.3 LTS系统上实现的。
3.2 实验数据
实验的数据集来源为Virustotal 学者数据集。为2019 年1 月至2019 年5 月收集的32 位Windows 平台下的EXE恶意软件样本,一共35 552个,采用卡巴斯基命名规则为样本标记。筛选出9类恶意软件家族的15 887个样本,分别是广告(Adware)、后门(Backdoor)、风险工具(Risktool)、木马(Trojan)、病毒(Virus)、蠕虫(Worm)。其中木马又可以分为四个子类,分别是Trojan-Dropper、Trojan-PSW、Trojan-Ransom、Trojan-Spy。表3所示为每一种上述恶意软件的数量分布。训练集和测试集的比例为7∶3,划分时设置stratify 参数,使训练集和测试集中的各个家族之间数量的比例保持不变。

表3 恶意软件分布Table 3 Distribution of malware
3.3 评价指标
采取宏平均精确率(Macro-avg(Precision))、宏平均召回率(Macro-avg(Recall))、宏平均F1-scoreMacroavg(F1-score)、准确率Accuracy作为评价指标。
其中:

TPn(True Positive)代表正确预测的正样例数;FPn(False Positive)代表将负样例错分为正样例数;FNn(False Negative)代表将正样例错分为负样例数。
3.4 实验结果
本文一共选取四类特征,分别是原始样本转化为灰度图和反编译的Lst 文件转化为灰度图的像素点特征、提取的结构特征、从Lst文件中提取的特征。xx_xx_File和xx_xx_Lst 分别表示原文件和Lst 文件的某个尺寸的灰度图,Stru_fea 表示结构特征,Lst_fea 表示从Lst 文件提取的特征。首先对这几个特征使用不启用GOSS 的LightGBM 进行分类,选出灰度图中效果最好的两种尺寸的图像,再从四类特征中选两种或者三种特征融合分类,最后查看所有特征融合的分类效果。表4是单一特征下的分类结果,可以看出原文件64×64 尺寸下的F1-score值和准确率高于其他尺寸的值,Lst文件48×48尺寸下的F1-score值和准确率高于其他尺寸的值,分类效果最好的是结构特征,F1-score达到了89.43%,准确率达到了96.58%。在单一特征下对比了Opcoden-gram特征、Gist特征、灰阶共生矩阵(Glcm)特征[10],结果显示Opcoden-gram 特征的F1-score 在62%左右,准确率在77%左右,且本文使用的灰度图像素特征分类的F1-score(除64_64_File外)和准确率优于Gist特征和Glcm特征。表5可以看出融合原文件灰度图特征的精确率较高,而融合了Lst 灰度图特征的召回率较高,效果最好的是结构特征和Lst特征的融合,F1-Score达到90.16%,准确率达到96.92%。从表6可以看出Lst灰度图融合结构特征和Lst特征取得了最好的效果,F1-Score达到90.45%,准确率达到97%。表7对比了启用GOSS采样的LightGBM算法,并设置a值为0.3,b值为0.19,发现在F1-score损失0.03%的情况下节省了29%的训练时间。
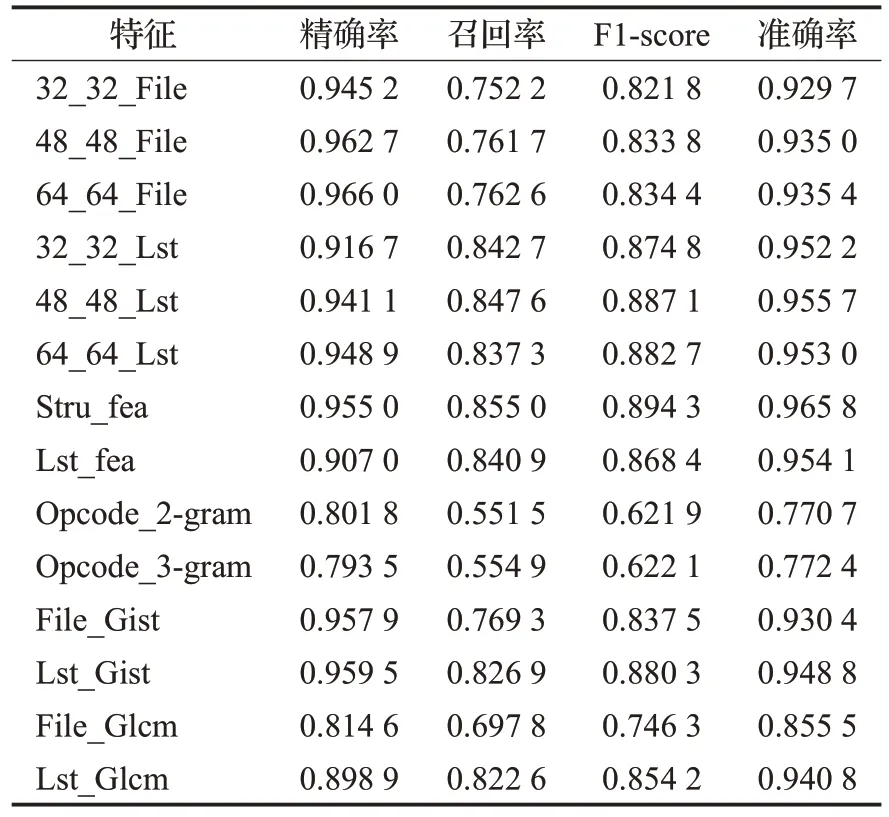
表4 单一特征下的分类结果Table 4 Classification results under single feature

表5 两类特征下的分类结果Table 5 Classification results under two types of features

表6 三类或四类特征下的分类结果Table 6 Classification results under three or four types of features

表7 启用GOSS的结果(n_estimators=500)Table 7 Result of enabling GOSS(n_estimators=500)
3.5 分析与比较
本文通过对四类特征进行融合分类实验,在Lst 灰度图融合结构特征和Lst 特征下取得了最好的效果,启用GOSS采样技术减少了29%的训练时间。图9所示为分类的精确率矩阵,可知每一类的分类精确率都超过了93.5%,宏平均精确率达到了96.85%。图10所示为分类的召回率矩阵,宏平均召回率达到了86.29%。Trojan-PSW的召回率只有50%,初步确定是由于样本数量不均衡和这类样本的数目太少使模型产生了欠拟合。

图9 48_48_Lst+Lst_fea+Stru_fea精确率矩阵Fig.9 Precision matrix of 48_48_Lst+Lst_fea+Stru_fea

图10 48_48_Lst+Lst_fea+Stru_fea召回率矩阵Fig.10 Recall matrix of 48_48_Lst+Lst_fea+Stru_fea
本文比较了GOSS(LightGBM)和另外两种Boosting算法(XGBoost、GBDT)以及两种深度学习算法(CNN、GRU)。表8结果显示GOSS(LightGBM)和XGBoost在F1-score 和准确率取得了最好效果,F1-score 分别为90.42%和89.41%,且在对比算法中GOSS(LightGBM)所用训练时间最短,XGBoost 训练时间是GOSS(Light-GBM)的4 倍且占用内存高于GOSS(LightGBM),而GBDT 训练时间是其11 倍。在深度学习中分类效果最好的是GRU,F1-score达到85.45%,准确率达到95.12%,但是训练时间超过了5 个小时。本文还对比了其他机器学习算法(RF、KNN、LR、SVM、MLP),相较于其他机器学习算法GOSS(LightGBM)的训练时间和内存消耗不占优,但是表9显示GOSS(LightGBM)除了精确率比RF 低0.35%外其他指标均占优。最后对本文的数据集提取了文献[9]和文献[11]所用的特征,使用Lst 文件代替Asm 文件,并使用LightGBM 分类,表10 结果显示本文特征分类效果优于文献[9]和文献[11]使用的特征,且提取特征的维数低于另外两种方法提取的特征维数。

表8 GOSS(LightGBM)算法和其他Boosting算法和深度学习算法对比(n_estimators=500,epochs=100)Table 8 Comparison of GOSS(LightGBM)algorithm and other Boosting algorithms and deep learning algorithms(n_estimators=500,epochs=100)

表9 GOSS(LightGBM)和其他分类算法结果对比Table 9 Comparison of GOSS(LightGBM)and other classification algorithms

表10 LightGBM在不同融合特征下的分类结果Table 10 Classification results of LightGBM under different fusion features
4 结束语
本文提取了恶意软件和其反编译的Lst文件转化成灰度图的像素点特征,通过插值算法将图片缩小,保留了全局特征的同时实现了像素特征的降维,并提取了原文件的结构特征和Lst文件特征并对特征进行融合。分类器选择了LightGBM,通过启用GOSS采样算法在F1-score 损失0.03%的情况下节省了29%的训练时间。实验证明本文提取的融合特征比融合Opcode 2-gram 或3-gram 的特征分类的F1-score 和准确率更高。Light-GBM 比RF、KNN、LR、SVM、MLP 的F1-score 和准确率更高,比XGBoost、GBDT、GRU、CNN 的F1-score 和准确率更高,且训练时间更短。
可以看出Trojan-PSW 类不能有效的召回,初步确定是由于样本数量不足所致。下一步准备从其他数据集扩充Trojan-PSW数量,增加该样本特征的数量,进一步检验模型的有效性,同时采用其他算法进一步对本文所提取特征进行处理,如使用TF-IDF 或信息增益指标对特征进行降维,保证模型分类效果的前提下进一步加快训练速度。
本文所提取的特征不涉及n-gram 特征,特征提取和处理较n-gram 更加节省时间,可以部署到安全引擎前端,快速地对未知样本进行初步检测。
