融合社交关系和局部地理因素的兴趣点推荐
2021-08-06张金凤
夏 英,张金凤
重庆邮电大学 计算机科学与技术学院,重庆 400065
目前,随着智能手机、移动互联网等技术的发展,LBSN 得到广泛应用,如国外的Gowalla、Foursquare,国内的大众点评、美团等。在LBSN 平台,用户可对当前访问的POI(如餐厅、书店、旅游景点等)进行签到、评论等操作,并能与社交好友分享自己的签到信息。在LBSN除了用户签到信息,还包含社交关系、兴趣点、用户评论等海量数据,充分挖掘这些数据,可以更好地分析用户的签到行为,把握用户群体兴趣特征和访问规律,有利于提高个性化POI推荐服务质量。
在LBSN平台,POI的规模庞大且分布广泛,而每个用户访问并签到过的POI往往很少,这使得用户签到数据十分稀疏,给POI推荐带来挑战。
针对用户签到数据的稀疏性问题,本文提出基于社交关系和局部地理因素的POI推荐算法,通过融合社交关系、地理位置信息来丰富有效数据,提高推荐质量。本文的主要贡献有以下三点:
(1)在构建社交关系影响模型时,综合考虑用户间的共同签到和距离关系,提出一种用户相似性度量方法,减少相似性计算误差。
(2)在构建地理因素影响模型时,通过为每个用户划分一个局部活动区域,分析用户所属区域内尚未访问POIs 间的签到相关性,更加充分地剖析出每个用户签到的地理偏好。
(3)在进行兴趣点推荐时,将上述考虑的社交关系和局部地理因素融合到加权矩阵分解模型中,构建一个更加符合用户偏好的POI推荐模型,在一定程度上缓解了数据稀疏性问题。实验表明,本文所提出的算法具有更高的准确率和召回率。
1 相关工作
POI推荐是LBSN 中重要的个性化服务,旨在为用户推荐符合他们兴趣但尚未访问过的POI列表。目前,针对位置社交网络的POI推荐已展开大量的研究工作,一些特定场景的应用也开始大量涌现,如餐厅推荐[1]、旅游路线推荐[2]等。
目前,大多数的POI推荐都是通过用户签到数据结合丰富的上下文信息来缓解数据稀疏性,挖掘用户对尚未访问POIs 的偏好程度。如Cheng 等人[3]采用多中心高斯分布来建模POIs 间距离分布,并结合社交关系进行POI 推荐。Zhang 等人[4]为避免所有用户采用统一分布造成的误差,采用核密度估计模拟任意两个POIs 间的距离分布,构建地理因素影响模型。Zhang 等人[5]从位置序列中挖掘顺序模式,并将序列影响、社交影响和地理因素影响融合在统一的推荐框架中。Yali等人[6]在基于朋友协同过滤基础上,综合考虑社交关系和地理位置特征,提出个性化的兴趣点推荐模型。Zhang 等人[7]对标签、社交和地理因素分别进行建模,并将它们融合到一种矩阵分解方法中。Zhang等人[8]利用BPR模型对矩阵分解进行优化,并结合用户社交关系和地理位置信息进行POI推荐。
除此之外,也有很多研究利用其他上下文信息进行POI推荐,如Gao等人[9]将一天划分为多个时间段,分别构建不同时间段下的User-POI签到矩阵,然后使用矩阵分解法获取不同时间段的用户偏好。Zhang等人[10]对用户评论进行语义分析和情感计算,根据用户的情感倾向预测用户偏好。Wu等人[11]将POI流行度特征融入基于用户协同过滤方法中,并结合社交关系和地理因素进行POI推荐。
尽管通过融合丰富的上下文信息可以有效缓解数据稀疏性问题,但现有融合上下文信息的POI推荐算法中仍存在以下一些问题:在研究社交关系影响时,用户相似性影响因素选取往往比较单一,对于那些拥有较少签到信息的用户难以构建社交影响模型;在分析地理因素影响时,现有计算全局POIs 间地理相关性的方法不能充分剖析每个用户的地理偏好。因此,本文提出融合社交关系和局部地理因素的POI推荐算法,可以有效地提高推荐的准确率和召回率。
2 兴趣点推荐模型
POI 推荐的任务是给用户推荐一个其感兴趣但尚未访问过的POIs列表。本章通过深入分析社交关系和地理因素对用户签到行为的影响,构建更加符合用户偏好的POI推荐模型。
2.1 相关符号及定义
为方便后续讨论,表1 给出了相关符号及其含义。同时,对签到矩阵和签到热点进行了定义。

表1 相关符号描述Table 1 Relevant Symbols description
定义1(签到矩阵)根据用户历史签到记录,构建签到矩阵R||U×||I,矩阵中每个元素rui表示用户u对POIi的签到次数。
定义2(签到热点)用户u签到次数最高的POI。
2.2 社交关系影响模型的构建
在LBSN中,用户的签到行为在一定程度上受到其社交关系的影响,进而促使用户访问一些未去过的POIs。例如,在日常生活中去过一个体验很好的餐厅或书店后,很可能会邀请或推荐自己的朋友前去,这些都可能使得用户在相同的POI产生共同签到,社交用户间存在一定的行为相似性。因此,考虑用户的社交关系对用户签到行为的影响有利于提高POI推荐质量。
对于用户尚未访问过的POIs,本文使用基于用户的协同过滤方法[12]计算社交关系信息对用户签到行为的影响程度,其计算公式如下:

其中,cvi的定义如下:

其中,sui表示用户u对POIi的偏好程度。Fu表示用户u在社交网络上的所有朋友集合,用户v是用户u的社交好友,cvi表示好友v对POIi的签到情况,simuv表示用户u和v的相似度。
对于式(1)中的用户相似度simuv,不同的研究采用的方法不同[3-6]。大多数研究中,只考虑了基于共同签到的用户相似度,这对那些拥有较少签到信息的用户无法有效计算其社交偏好。因此,本文考虑在以往基于共同签到的相似性研究基础上,同时通过用户间距离关系来度量用户间的兴趣差异,减小用户相似度的计算误差。
一方面,通常认为用户间的共同签到越多,他们的偏好就越相似。在基于行为相关性的相似性度量方法中,Jaccard 方法[13]在计算效率和推荐准确率上效果更好,基于Jaccard方法计算用户签到相似度公式如下:

其中,Ru和Rv分别表示用户u和v签到的POIs集合。
另一方面,考虑到相距较近的用户拥有更多的共享兴趣点,会产生较多的共同签到。因此,对于距离越近的用户,其签到行为的相似度越高。本文通过改进Sigmod函数计算用户距离相似度。
Sigmod函数是常见的S型函数,公式定义如下:

该函数连续、光滑、严格单调,关于点(0,0.5)中心对称,在区间[-∞,+∞]上呈非线性增长。基于上述假设中距离相似度随着用户间距离应呈递减状态,因此考虑改进Sigmod 函数来衡量基于用户距离的相似度,改进后的用户距离相似度计算公式如下:

其中,dis(u,v)表示用户u与v间的距离,其根据用户签到热点的经纬度信息,利用Haversine方法[14]计算得出。计算公式如下:
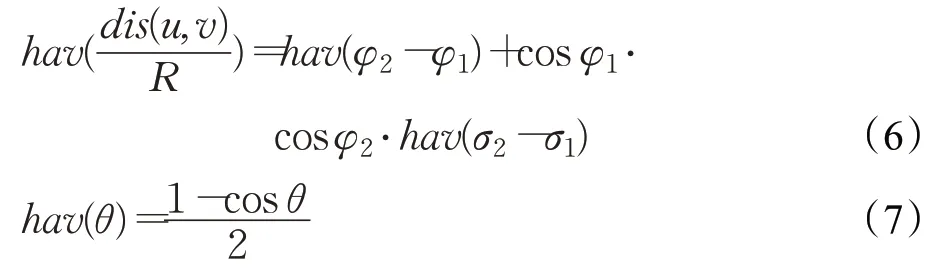
其中,R为地球半径,φ1和φ2分别表示用户u和v签到热点的纬度,σ1和σ2分别表示用u和v签到热点的经度。
综合以上设计,本文对用户签到相似度和距离相似度行线性加权,得到用户u和v的最终相似度,计算公式如下:
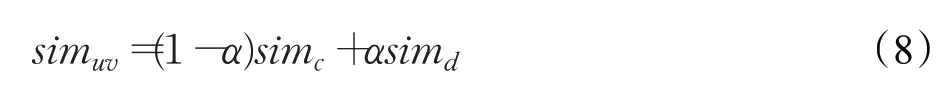
其中,α为调节用户签到相似度和距离相似度影响权重的参数。
将式(8)代入式(1)即可得到在社交关系影响下用户对兴趣点的社交偏好矩阵S。
2.3 局部地理因素影响模型的构建
在位置社交网络中,地理位置信息是其特有的语境信息,是提升POI 推荐质量的重要因素。目前,考虑地理因素影响的模型主要是通过分析用户所有签到POIs的分布情况,通过POIs 间距离关系计算用户对POIs 的签到概率,如常用的高斯分布[3]及核密度估计[4]等。为了进一步研究地理因素的影响,这里发现用户签到呈现出空间聚类现象[15],表明用户喜欢访问邻近POIs,如用户去某个城市旅行,往往会对相邻区域集中的POIs 都进行访问,邻近POIs 间的签到情况具有一定的关联性[16]。因此,本文考虑为每个用户划分一个局部活动区域,充分剖析区域内尚未访问POIs间的签到相关性,构建更加符合用户偏好的局部地理因素影响模型。
步骤1划分用户活动区域
首先,找到用户u的签到热点,然后为用户u划分一个距离签到热点半径为β的局部活动区域。
步骤2寻找区域内用户尚未访问的POIs
在步骤1所划分用户活动区域内,寻找用户u尚未访问的POIs集合,分析与集合中POIi相距小于γ的邻居POIs的签到情况。
步骤3计算地理偏好程度
研究发现,用户往往会对邻近POIs进行集中访问,针对邻近POIs 的签到影响已展开相关研究[16]。其中,Hossein等人[17]认为用户对邻近POIs的签到数量会对用户u签到POIi产生一定影响,并构建出一个更加符合用户偏好的地理偏好模型。因此,本文根据邻居POIs的签到情况,采用文献[17]中的地理偏好定义,计算用户u对POIi的签到概率,公式如下:

其中,表示用户u对POIi所有邻居POIs 的签到数量,Lu表示用户u曾访问过的所有POIs集合。
2.4 融合社交关系和局部地理因素的兴趣点推荐模型
2.4.1 基础模型
在LBSN 中,用户社交关系、地理位置等上下文信息都会影响用户的签到行为,但最主要的是从用户历史签到数据中反映出来的用户自身偏好。在POI推荐中,矩阵分解技术[18]常用于挖掘用户的自身偏好。但由于User-POI签到矩阵中只能观察到用户访问过的POIs,对于那些用户尚未访问过的POIs 会产生大量的缺失项,因此无法使用一般的矩阵分解技术来构建用户自身偏好模型。Hu等人[19]首次在大规模隐式数据上提出加权矩阵分解(Weighted Matrix Factorization,WMF)模型,该模型通过对用户已访问的POIs 分配较大权重,对尚未访问的POIs分配一个较小权重来解决User-POI签到矩阵中存在的缺失项问题。
在POI 推荐中,WMF 方法将User-POI 签到矩阵分解为两个低维隐藏特征矩阵Pm×k和Qn×k,用户对POI的自身偏好矩阵即为两个隐藏特征矩阵的内积。本文基于WMF 模型构建用户自身偏好模型,其目标函数定义如下:

其中,pu和qi分别表示用户u与POIi对应的隐特征向量,λ表示正则化系数。wui表示每个用户签到次数rui对应的权重,本文采用文献[20]中权重设置方法,加权矩阵w的权重系数设置如下:

其中,ε是用来控制权重系数随用户访问POI 次数增长的速率。
2.4.2 模型融合
在2.4.1节中,WMF模型根据用户的签到频次信息提取用户对POI的自身偏好,但没有考虑社交关系和地理位置等影响因素。本文在WMF 模型上进行改进,将上述考虑的社交关系和局部地理信息融合到WMF 模型中,构建一个更加符合用户偏好的POI 推荐模型SLGMF。该模型的目标函数如式(13)所示:

其中,eui表示用户u对POIi的最终偏好,‖pu‖2和‖qi‖2分别表示用户u和POIi的正则化项,加入目的是为了防止过拟合。
本文目标函数采用交替最小二乘法进行优化,其主要思想是先依次固定矩阵P,优化矩阵Q,然后再固定矩阵Q,优化矩阵P,反复交替,不断修正p和q分量,获得最优矩阵P和矩阵Q。
SLGMF模型的构建如算法2所示。
算法2SLGMF模型构建


3 实验评估
3.1 数据集
实验选取数据集Gowalla[21],Gowalla收集了2009年2 月至10 月期间的所有签到数据、用户社交关系和POI信息。为使实验数据更加有效,将数据集中用户和POI签到数量少于15条的低价值数据去除。处理后的标准数据集共有5 628个用户,31 803个POIs和620 683条签到记录,以及46 001条社交关系。
3.2 评价指标
实验选取常用的准确率(Precision)和召回率(Recall)作为评价指标来衡量推荐算法的性能,其定义分别如下:

其中,|U|表示用户数量,Ru表示为用户u推荐的POIs列表,Tu表示用户u曾访问过的POIs列表。
3.3 对比方法与参数设置
为了验证所提SLGMF 算法的性能,实验选取两种均融合社交关系和地理因素的POI推荐算法:MGMPFM[3]和LORE[5]。另外,为了考察不同因素对POI 推荐的影响,本文将SLGMF 算法拆分为仅融合社交关系的推荐算法S-MF和仅融合局部地理因素的推荐算法LG-MF,并进行自身对比。
MGMPFM:利用多中心高斯模型建模地理因素影响,在概率矩阵分解基础上融合社交和地理位置信息进行POI推荐。
LORE:从用户签到的位置序列中挖掘出序列模式,并融合社交和地理因素进行POI推荐。
S-MF:本文提出的模型,仅融合社交关系信息的推荐算法。
LG-MF:本文提出的模型,仅融合地理位置信息的推荐算法。
SLGMF:本文提出的模型,基于加权矩阵分解,综合考虑社交关系和局部地理因素的推荐算法。
在参数设置上,所选用对比模型应尽量与原文献保持一致,使各个算法性能达到最优。对于本文提出的SLGMF 模型,分别设置隐藏特征矩阵维度K=25,用户相似性影响因子α=0.6,地理因素影响因子β=30,γ=12,上述参数的取值使得推荐效果达到最优。另外,地球半径R取平均值为6 371。
3.4 实验结果与分析
本文在相同数据集上对各个POI 推荐算法进行Top-N(N=5,10,15,20,25,30)推荐,图1和图2展示了Top-N推荐的准确率和召回率。可以观察到准确率随着N的增大而减小,召回率随着N的增大而增大。这是由于返回的POIs 越多,越有可能发现更多用户愿意访问的POIs。

图1 推荐的准确率Fig.1 Recommendation precision

图2 推荐的召回率Fig.2 Recommendation recall
图1和图2可以看出,对比MGMPFM和LORE这两种均融合社交关系和地理因素的POI推荐算法,无论N取何值,SLGMF算法在准确率和召回率上均有所提升,表明了本文所提出SLGMF算法的有效性。
另外,本文将SLGMF 模型拆分为仅融合社交信息的POI 推荐模型和仅融合地理位置信息的POI 推荐模型,通过实验分析融合单一上下文信息的推荐效果,结果如图1和图2所示。当为用户进行Top-5推荐时,在准确率上,SLGMF 算法相对S-MF 算法提升了14.6%,相对LG-MF 算法提升了11.2%。在召回率上,SLGMF 算法相对于S-MF 算法提升了24.3%,相对于LG-MF 算法提升了22.8%。这说明本文在加权矩阵分解基础上融合多种上下文信息,确实可以有效地缓解数据稀疏性问题,提高推荐性能,并且融入有效的上下文信息越多,推荐效果越好。除此之外,对比S-MF和LG-MF算法可以发现,仅融合地理因素的LG-MF 推荐性能要优于仅融合社交因素的S-MF,这表明地理因素对用户签到行为的影响要高于社交因素。
3.5 模型参数的影响
在2.4.1节中构建用户自身偏好模型时,通过WMF将用户签到矩阵分解为两个维度为K的隐藏特征矩阵P和Q,参数K的值决定用户对POI 的自身偏好程度。本节选取不同的K值,对用户进行Top-5 推荐,推荐结果如图3所示。可以看出,当维度K=25 时,SLGMF推荐性能最好,且随着K的不断增加,推荐效果开始呈下降状态,这是由于模型已经出现过拟合的原因。

图3 参数K 对准确率和召回率的影响Fig.3 Effect of parameters k on precision and recall
在式(8)中计算用户最终相似度时,参数α决定着距离相似度和签到相似度的影响程度。为了探究用户间距离和共同签到对用户签到行为的影响,实验选取不同的α值对用户u进行Top-5 推荐,结果如图4 所示。可以看出,当α=0.6 时,推荐效果最佳,同时也表明用户签到行为相似度受用户间距离的影响更大。

图4 参数α 对准确率和召回率的影响Fig.4 Effect of parameter α on precision and recall
在2.3 节构建局部地理因素影响模型时,为每个用户划分一个局部活动区域,参数β是用来控制用户活动范围,参数γ用来判别区域内尚未访问POIi的邻居POIs。因此,为探究用户局部签到规律,实验选取不同的β和γ进行Top-5推荐,分析局部地理因素对用户签到行为的影响,推荐结果分别如图5 和图6 所示。可以看出,当β=30,γ=12 时,推荐效果达到最佳,也可以看出用户比较倾向访问离自己较近的POIs。

图5 参数β 对准确率和召回率的影响Fig.5 Effect of parameters β on precision and recall

图6 参数γ 对准确率和召回率的影响Fig.6 Effect of parameters γ on precision and recall
4 结束语
为了解决POI推荐中存在的数据稀疏性问题,本文提出一种融合社交关系和局部地理因素的POI 推荐模型SLGMF。首先,根据社交关系中用户间的共同签到和距离关系提出一种用户相似性度量方法,并基于用户的协同过滤得出社交关系对用户签到行为的影响程度;然后,为每个用户划分一个局部活动区域,充分剖析区域内尚未访问POIs 间的签到相关性,计算局部地理因素对用户签到行为的影响程度;最后,基于加权矩阵分解构建用户自身偏好模型,并结合上述考虑的社交关系和局部地理因素,构建更加符合用户偏好的POI推荐模型,有效地缓解数据稀疏性问题;在Gowalla数据集上进行实验,结果表明所提的SLGMF 算法具有良好的推荐性能。
现实生活中,影响用户签到行为的因素除了本文所考虑的社交关系和地理因素外,还有诸如时间、评论文本、图像等丰富的上下文信息。在未来的研究工作中,将重点考虑如何利用更多的上下文信息来提高POI 推荐性能。
