基于最小描述长度原则的属性图概要方法
2021-08-06毕雪华
张 陶,于 炯,廖 彬,毕雪华
1.新疆大学 信息科学与工程学院,乌鲁木齐 830046
2.新疆医科大学 医学工程技术学院,乌鲁木齐 830011
3.新疆财经大学 统计与信息学院,乌鲁木齐 830012
图是一种能够表现实体及其之间复杂关系的模型。许多领域如Web网络、通信网络、社交网络、生物网络、交通网络、传球网络[1]等,都可以用图数据结构进行描述,采用基于图数据的方法进行处理。然而,随着时间的推移,图变得越来越大,例如截止2017 年10 月,Facebook 的常规移动用户达到20 亿[2]。如何从这些具有上亿节点和千亿条边的大规模图数据中找到和分析用户所需要的信息,是一个极具挑战性的难题。因为将如此大规模的图直接加载内存,不仅耗费大量资源,而且导致可视化视图非常混乱。图概要(图聚集)技术是大图内存处理的一种有效的方法。它将一个大规模图概要成一个简洁且能够反映原始图结构和属性信息的小规模图(被称为“概要图”或“摘要图”)。概要图代替原始大图进行数据分析,帮助用户理解和分析原始图中的有用信息。如图1所示,图1(右)是图1(左)的一个摘要结果。显然图1(右)较图1(左)更容易分析和理解。超点V4、V5,因为里面的节点属性不相似,被划分到不同超点中。若为了结构更紧凑,可继续合并超点V4、V5为超点V6。

图1 由原始图产生的摘要图Fig.1 Summary graphs generated from original graphs
实际应用中图数据往往拥有大量信息,除了用节点来表示实体、边表示实体之间的关系之外,还有大量的属性信息伴随着节点和边出现。这种图称为属性图。节点的属性信息是非常重要的,例如在社交网络、合作网络等图应用领域中顶点所代表的实体都带有某些语义的属性,而语义的含义是不可忽视的。此种情形下,同时利用结构信息和属性信息意味着会得到更加准确和有意义的分析结果,使聚集图具有更全面的原始图信息。但这也为属性图概要研究带来了许多挑战,如结构信息和属性信息在语义上是相互独立的实体,如何能够同时考虑到节点属性和结构信息[2],实际应用中,当图中节点附加有多个属性,且属性维度具有多种表现形式,如离散值、连续变量、字符串等时,那么属性值距离的度量方式也会不一样。如何确立统一的属性相似性度量公式是需解决的问题之一。本文通过对属性图概要问题进行分析和建模,结合最小描述长度原则(Minimum Description Length,MDL),提出了两种多属性图概要方法(Greedy algorithm-based Multi-Attributed Graph Summarization,Greedy-MAGS)和(Random algorithmbased Multi-Attributed Graph Summarization,Random-MAGS)。
本文所做工作如下:
(1)基于MDL 原则,对属性图概要问题进行分析建模。
(2)借鉴Levenshtein Distance 思想,本文提出了一种计算节点属性相似性的方法。该属性度量方法对节点属性的限制较小,不要求节点属性的距离或表现形式是一致的,节点的属性可以是不同形式,不同的类型。并且将节点间的相似性统一为存储代价,实现了节点结构相似和属性相似的协同考虑。
(3)提出了两种属性图概要算法:贪心算法Greedy-MAGS,追求全局最优,每次选择图中最佳的节点对进行合并,最后输出一个高度压缩的概要图;随机算法Random-MAGS,不追求全局最优,而是随机选择一个节点,将其与其附近的最佳节点合并。此算法提高了生成概要图的速度,可以更好地适应更大原始图的图概要需求。
(5)通过在真实数据集和合成数据集上实验,表明了本文所提算法的有效性。
1 相关工作
图概要研究的目的是减少大型图的结构复杂度和描述长度,通过压缩、总结原始图,来创建一个有意义的摘要图,它近似地保留了底层图的结构特性。目前的研究可以根据原始图类型的不同分为仅结构图[3-9]、属性图[10-17]或动态图[18-19]的总结。综述可在[20-23]中找到,以便全面了解。图概要的算法采用的主要核心技术分类如表1所示。

表1 图概要算法的核心技术分类Table 1 Technical classification of graph summarization algorithm
文献[3-5]基于邻接节点一致性,使得同一分组内部各节点具有相同的邻接节点。Tian 等人[13]基于每个聚类中的节点属性一致原则,根据节点的属性对属性图进行聚类(k-SNAP)。该算法将属性完全相同的点聚到一组,通过允许用户下钻和上取,实现了OLAP 形式的多粒度的图聚。但这些算法都仅仅是考虑节点结构或属性单方面的信息,这样往往会造成某些分组中的属性或者节点结构联系非常松散。
而绝大部分方法考虑属性相似性的方法一般先考虑属性相似,然后根据结构相似性进行聚合摘要,不能实现结构和属性的协同考虑,如文献[10,12-14];或者要求同一维度属性的距离或表现形式是一样的,工整的。
尹丹等人[10]研究了属性图的聚集方法,该算法将整个聚集过程分为了两个阶段,首先根据节点属性的Jaccard相似性将节点划分为M≤k个分组,然后根据边的分布,选取节点,不断迭代划分至k个分组。此算法需预先设定超点的数量k,当用户对数据没有充分了解时,无法生成高质量的概要图。
Navlakha 等人[4]提出了一种利用MDL 原则进行图概要的方法,该算法既压缩了原始图,又产生了高层次抽象的概要图,此方法奠定了基础。但他们仅考虑了节点的结构相似性,未考虑属性相似性。当输入图中的节点附加属性时,它极可能合并具有高邻域相似性但属性不相似的节点。
Khan 等人[15-16]将MDL 与局部敏感哈希(Locality Sensitive Hashing,LSH)相结合,提出了一种基于集合的相似散列的总结方法。
本文借鉴了文献[4]将MDL 原则应用于图概要,可以实现图压缩和图概要双重目标的思路,改进了其衡量节点相似度的代价计算模型,同时考虑节点的结构相似性和属性相似性这两个信息来生成候选的相似节点,以解决属性图概要的问题。
2 问题描述
在本章中,定义了本文中的各种关键概念以及陈述问题。
2.1 基本概念及定义
定义1原始图G。
设摘要前的属性图G=(V,E,A)为原始图,其中V={v1,v2,…,vn} 表示节点集合;E={(vi,vj)|vi,vj∈V且i≠j}表示边的集合;A={a1,a2,…,ak} 表示节点的k维属性的集合,每个节点vi∈V的属性可以表示为属性向量attri(vi)=[a1(vi),a2(vi),…,ak(vi)]。
定义2概要图GS。
G中的每个节点都分到唯一超级节点,形成一个节点分组,原始图G关于此节点分组的概要图为GS=(VS,ES,AS)。注意VS中的节点形成了不相交的节点子集,这些节点的联合覆盖了点集合V。
定义3图的最小描述代价表示GMDL。
最小描述长度MDL原则[24]是由Rissanen于1978年提出的一种信息论原理。MDL原理指出当描述数据的总描述长度(代价)最小时的模型就是最佳的模型。数据的总描述代价由两部分组成:模型的大小和模型编码的大小。在图概要中,数据是原始图G,模型是概要图GS,而模型编码就是边和属性修正列表C(修正列表C是在摘要过程中添加或删除的边,以及节点的属性修正值,主要用于重构原始图)。当图表示(GS,C)是原始图的最小描述代价表示时,那么MDL 原则认为GS就是“最佳”的图摘要结果。也就是说,GS既是原始图G的最压缩表示,同时也是其最好的摘要图。最小代价图表示(GS,C)被称为图G的最小描述代价表示GMDL。
GMDL由两部分组成:GMDL=(GS,C)。第一部分是概要图GS(VS,ES,AS)(比原始图G小得多),它捕捉了原始图中的重要集群和关系;第二部分是一组修正C,C可细分为两部分:边修正CE——原始图G的一组边,它们被标注为正(+) 或负(-) ;和属性修正CA——一组G中节点的属性值,它们被标注为插入(+)、删除(-)或替换(→)。如果有必要,C可以帮助重新创建原始图,重构G中每个节点只需要展开一个超级节点并读取C中的相应条目。
2.2 问题定义
将MDL原则用于图概要的目的就是找到具有最小修正C且高度紧凑的概要图GS。
本文研究的图概要问题的形式化定义如下:
即给出一个静态无向属性图G,图中每个节点都有多个属性,目标是通过对具有公共邻居且属性相同或相似的节点进行合并压缩,求解出图G的最小代价MDL表示GMDL=(GS,C)。图2显示属性图概要的结果示例。
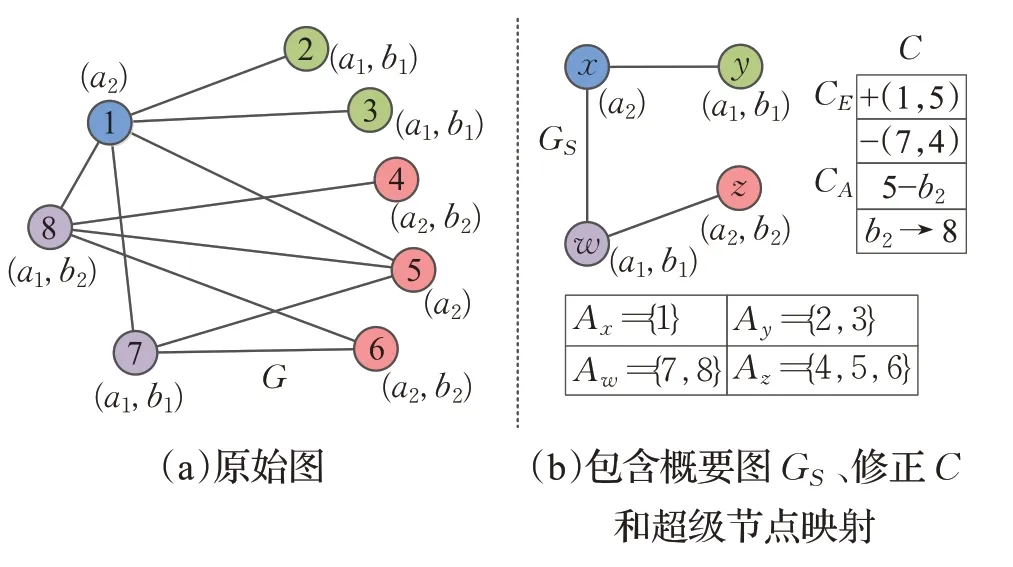
图2 属性图概要示例Fig.2 Example of attributed graph summarization
输入:G(V,E,A)
输出:GMDL=(GS(VS,ES,AS),C=CE+CA)
如果给出一组超级节点VS,通过查看每个超级节点,根据创建超边及修正的规则进行简单选择就可以计算出最小的表示代价cost(GMDL),然而,如何为GMDL找到最佳的超级节点集才是主要的挑战,它是将在第3章中要解决的一个困难问题。在第3 章中描述了关于代价模型和求解最小代价表示的算法的详细说明。
3 多属性图概要方法
在本章中,首先介绍了多属性图MDL 表示代价模型,然后给出了寻找原始图G的MDL 表示GMDL=(GS,C)的两种算法。
GMDL=(GS,C)的描述代价取决于GS和C的代价之和,即cost(GMDL)=|GS|+|C|。|GS|与模型的大小对应,|C|对应模型编码的大小。与超边集ES、属性集AS和C的存储代价相比,将节点分组Av映射为超级节点v∈Vs的存储代价通常要小得多,因此忽略了它。最小描述代价表示GMDL的代价计算公式为cost(GMDL)=|ES|+|AS|+|CE|+|CA|。
3.1 代价模型
邻接和属性列表在语义上是两个独立的实体。为了能同时考虑节点结构相似性和属性相似性,将其统一为存储代价来衡量。提出的代价模型分为结构存储代价和属性存储代价两部分。节点的相似性越高,合并后的存储代价越小。
定义4结构代价CostE。
在图中,邻域相似性是一种广泛使用的方法。通常,合并共享公共邻居的任何两个节点都可以降低成本,而更多的公共邻居通常意味着更高的成本降低。
公式(1)[2]计算了总结的结构代价,它是创建超级节点时的边数和边修正数之和。其中,Nu是超级节点u∈VS的邻居集合。

当原始图中的节点带有属性时,如果仅考虑结构相似性,减少了聚集图的信息量,则很有可能将具有高邻域相似性但具有不同属性相似性的节点合并起来,使聚集图的质量下降。为了克服这个缺陷,最好同时考虑候选相似节点对的结构信息及属性信息。
定义5属性代价CostA。
图中的每个节点都有多个属性,这些属性都是该节点的某些方面的特征信息,属性取值可能是离散型的(如布尔值),可能是连续型的,也可能是文本型的。如社交网络中的用户,不仅具有性别、年龄属性,还具有兴趣爱好等复杂属性。属性维度间不一样的表现形式会导致一样的相似性度量方式。有的文献是将属性转化为属性值矩阵,用0/1表示属性是否存在;有的方法是将属性值转化为集合的形式,然后使用距离度量函数(比如Jaccard相似度)衡量其相似性;也有方法将属性值映射到具体数值上,例如局部敏感哈希(Local Sensitive Hash)方法、SimHash 算法。但上述方法都需要节点属性的距离或表现形式是一样的,工整的。在实际的应用中图中节点的属性具有多样性,不同属性维度的距离往往是不一样的。针对这个弊端,本文提出了一种统一的属性相似性方法。本文借鉴了字符串相似性算法Levenshtein Distance的思想,来衡量节点属性的相似,该方法对节点属性的限制较小,节点的属性可以是不同形式、不同的类型,并将其转为属性存储代价,与结构代价相统一。
编辑距离(Edit Distance),是由1956年俄国科学家Vladimir Levenshtein给字符串相似度提出的定义,又称Levenshtein距离。是指两个字符串之间,由一个转成另一个所需的最少编辑操作次数。许可的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。例如从aware 到award 需要一步(一次替换),从has 到have 则需要两步(替换s 为v 和再加上e)。字符越相似,编辑操作则越少。若两个字符串等长时,编辑距离即为汉明距离。
本文受上述思想的启发,提出了用属性编辑距离(Attributed Edit Distance,AED)来计算节点属性相似度。此方法将每个节点的属性分布看作是字符串,其中的每个属性维度值则类似于一个字符。

公式(2)是节点间的属性编辑距离,距离值越小,属性分布越相似,编辑操作则越少。产生的编辑操作列表作为属性修正,加入CE。
公式(3)计算了总结的属性代价,它是创建超级节点时的属性维度个数和属性修正数之和。au(i)表示节点u第i维属性值,k是节点的属性维度个数。
如图3所示,以某社交网络精简的属性分布为例说明本文属性相似度计算方法。每行代表一个用户节点v1~v5,列表示其属性(4 个属性维度A、B、C、D)。A的属性域为一个0~1分布;B的属性域是数值类型的连续变量;C的属性域包含三种取值:a、b、c;D的属性域是一个集合,代表用户的兴趣爱好,比如音乐music或者阅读reading等。编辑操作列表是每个节点属性变为某一属性分布所需的最少编辑操作。假设节点v1与节点v2~v5具有完全相同的邻居节点,此时仅考虑它们的属性相似性。其中,节点v2具有与v1完全相同的属性分布,因此不产生编辑操作,是v1最佳的合并节点。而节点v5与v1属性完全不同,因此将产生4 个编辑操作。节点的属性越相似,则产生的编辑操作越少,属性代价越小。

图3 节点属性相似度计算示例Fig.3 Example of computing attribute similarity of node
对于节点集v1~v5,A属性维度是(0,0,1,0,1),A维度下重复出现次数最多的属性值(即最大频率属性值)是0。当将每个节点的A 维属性都变为最大频率属性值0,将产生最少的编辑操作次数(2 个)。按照属性值的出现频率节点集v1~v54 个属性维度下的最大频率属性分布为(0,10,a,Music),可得节点v1~v5变为此属性分布所产生的编辑操作之和是最小的,因此得到的属性修正是最小。因此,在图概要过程中,为了产生最少的编辑操作,生成最小的属性修正列表CE,将合并后超级节点的属性设置为最大频率属性分布的值。
定义6总代价Cost(u,v)。
公式(4)计算了总结的总代价,通过参数β∈[0,1]调整两种代价的权重。β越大表示结构代价的权重越大,合并更侧重于结构的相似性。
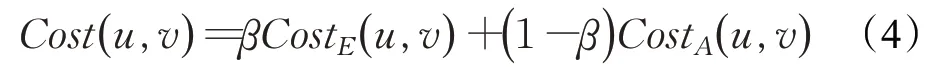
定义7代价降低比率s(u,v)。
在一个大图中,通过合并许多节点对可以降低图的存储代价。通常,任何两个具有相似结构和属性的节点合并就可以降低存储代价,比如两个节点拥有共同的邻居节点且属性值也相同,就可以将它们折叠成一个超级节点,用单个超边替换到每个公共邻居的两条边。显然,这将大大减少需要存储的总边数,同时节点属性的存储空间也会降低50%,从而大大降低了内存需求。而拥有更多共同邻居和相似属性的节点通常意味着更高的成本降低。在此基础上,定义了合并节点对(u,v)后的代价降低比率s(u,v),如公式(5)。s(u,v)被定义为合并节点u和v(形成一个新的超节点w)带来的存储代价降低值和合并节点u和v前存储总代价的比值。只要有利于存储代价降低的点合并都会进行,只是会根据s(u,v)值的大小调整其被合并的顺序。在贪心算法中,迭代地将图中具有对s(u,v)的最大值的节点对合并。算法的核心思想是选择具有最大共同邻居数及属性相似的节点对进行合并,以创建将s(u,v)降低到最大值的超级节点。随着算法的发展,维护了一组超级节点VS,它们构成了图概要中的超级节点。

当两个节点具有完全相同的邻接列表和属性列表时,则被认为是完全等价的节点,合并它们,s(u,v)可以取到最大值0.5。当节点u,v的属性完全不同时,属性编码代价的降低为0。
下面详细描述用于寻找原始图G的MDL 表示GMDL=(GS,C)的两种算法。
3.2 贪心算法
贪心算法Greedy-MAGS算法迭代地将最大代价降低(全局最优)的节点对合并成超级节点。为了有效地选择s(·)值最大的节点对,使用标准的max-heap结构H来存储s(u,v)大于0的图中的所有节点对。
算法1Greedy-MAGS算法


此算法分为三个阶段进行:第一阶段初始化(第1~7行):此阶段任务是采用时间复杂度最优的堆排序将所有候选合并节点对按照其s(⋅)值排序。步骤如下:首先遍历超点集VS中所有2 跳节点对,并计算它们的s(⋅)值。之所以只考虑相隔2跳的节点对,是因为观察到两个没有共同邻居的节点合并不可能降低结构存储代价,只有合并拥有公共邻居节点的节点对才能降低结构存储代价。而相隔2 跳的节点对之间必然有至少一个共同邻居节点。然后将(s(⋅)>0)的节点对放入一个最大堆H中进行排序。
第二阶段迭代合并:依次选择最大s(⋅)值的节点对进行合并,并更新超点集VS和最大堆H。对于每个超级节点,为了产生更少的属性修正,通过从{ }u,v中选择到最大频率属性分布的编辑距离AEDMAX更小的节点的属性值来设置其属性(第13~17行)。第23~28行重新计算了包含节点x∈Nw的所有对的s(⋅)值,并在堆H中更新它们(因为超点w的邻居节点x,它以前是节点u或v的邻居节点,合并u和v可能会改变边(u,x)(和/或(v,x))的s(⋅)值)。
结果输出阶段:第31~41行生成超边及修正列表C,包含边修正Ce和属性修正Ca两部分。当|Auv|>(|Πuv|+1)/2时,新增边(u,v)至ES。最后输出摘要图GS以及边和属性的修正列表集C。
创建超边及修正时寻求最小的内存需求,只对高度紧凑的总结和最少的修正感兴趣。具体规则如下:将Πuv定义为Au,Av∈VS之间所有可能边的集合,Auv作为Au和Av之间的实际存在的边集合。当符合|Auv|>(|Πuv|+1)/2 时,超点间创建超边(u,v),并对Πuv-Auv里的边创建负修正,内存代价是(1+|Πuv-Auv|);否则,不创建超边,仅对Auv里的边创建正修正,内存代价为|Auv|。也就是说为了让图表示更紧凑、体积更小,只有当Au与Av间的节点密集连接时,才在超级节点u和v之间存储一条超边,并且选择内存代价更小的边修正方式。
为了产生最少的编辑操作,生成最小的属性修正列表CE,对于每个超级节点u,通过选择Au中具最大频率属性分布的值来设置其属性。其余属性值作为属性修正创建。
算法1 时间复杂度分析:算法第1 行初始化复杂度为O(n) ;第2~7 行代码为堆排序操作,时间复杂度为O(n×lbn),其中n为超点集VS中所有具有正代价降低率的二跳节点对个数;8~26 行代码是while 循环嵌套if判断以及for循环,其中,第9~15每行复杂度都为O(1),对于第一个for循环,时间复杂度由每个节点的度m决定;同样,23~26 行代码复杂度为O(m);叠加外层while循环,所以8~26 行代码复杂度为O(n×2m);第30 行的时间复杂度为O(n),31~41 行为for 循环嵌套两个if 判断,当超点集VS里节点对个数为n时,每个if判断中的代码最多会被操作n次;所以,算法1 的时间复杂度为O(n+n×lbn+n×2m+n)≈O(n(lbn+m)) 。
3.3 随机算法
为了更大输入图的图概要需求,提高生成概要图的速度,本文又提出了一种生成概要图更快的策略方法——随机算法Random-MAGS算法。Random-MAGS算法不需要堆结构,它不追求全局最优,不是合并全局最优节点对,而是随机选取一个节点,将其与其附近的最佳节点合并。因此节点合并过程比贪婪算法Greedy-MAGS算法快很多。
算法2Random-MAGS算法


算法2中,算法第1~3行的初始化操作,每行时间复杂度为O(n),第4~18 行是while 循环嵌套if 判断,代码复杂度为O(n);所以,结果输出阶段,与算法1 一样,代码复杂度为O(n),所以,算法2 的时间复杂度为O(2n+1+n+n)≈O(n)。
4 实验结果与分析
本章从聚集效果和算法性能两方面评估两种属性图聚集算法Greedy-MAGS 和Random-MAGS。实验数据选取了4个真实的无向图数据集D1~D4 和一个合成数据集D5(在数据集D4 基础上,又创建了一维属性并随机生成其属性值(10个候选值))。表2给出了每个数据集的具体信息。选取BB-ULSH算法[15]进行对比,BBULSH 算法属性相似性设置为50%。实验环境是Core i7-8750H 2.20 GHz CPU和16 GB的RAM,所有算法用Java语言实现。

表2 数据集信息Table 2 Dataset information
4.1 聚集效果
使用边压缩率和属性修正代价来评价属性图概要的质量。在理想的情况下,摘要图的属性修正应该和超级节点一样都是最小的。

使用公式(6)计算边压缩率,其中PreviousCost表示原始图中实际存在的边;CurrentCost表示摘要图中超边和边修正之和。超边和边修正越少,此结果值就越大,代表了摘要结果越好。
如图4,两种算法都获得了较高的压缩率。这是因为两种算法都采用了成对创建超节点的策略,严格探索查询每个节点的2跳邻居节点,保证了合并的每一对节点都是最高压缩比,因此,都实现了较好的压缩。

图4 不同数据集下的边压缩率对比(越高越好)Fig.4 Compression rate comparison of different data sets(the higer the better)
4.2 算法性能
图5 显示了所有算法的运行时间对比,BB-ULSH算法的运行时间最短,是因为它是采用基于集合创建超点的技术,一次迭代可以遍历和压缩多个节点;而两种算法则都是以其迭代的成对超节点创建技术,遍历查询每个节点的2跳邻居列表以确定最佳可压缩节点,且每个迭代只压缩一对节点,因此花费了更多的时间,但随着图的稀疏性的降低,这两种算法的执行时间都不断下降。

图5 不同数据集下的运行时间对比(越小越好)Fig.5 Runtime comparison of different data sets(the smaller the better)
在D1 数据集上几种算法的运行时间差异不大。而数据集D5 上差异较大。这是因为采用成对创建超节点技术的两种算法运行时间与每个节点2跳邻居列表的大小成正比,而D5 中每个节点都有大量的2 跳节点。因此需要的运行时间更多,其中,与本文的预测一致,Greedy-MAGS 算法追求全局结构最紧密属性最相似,Random-MAGS 算法要明显快于Greedy-MAGS算法。
4.3 算法参数分析
本实验考察了本文两种算法在不同数据规模数据集上在摘要表示代价和运行时间方面的差异。
图6结果所示,采用两种算法都得到了远小于原始图存储代价的摘要图。Greedy-MAGS算法追求全局最优时间代价方面明显大于Random-MAGS算法,但同时也获得了存储代价更小的摘要图。

图6 两种算法表示成本和运行时间对比Fig.6 Comparison of representation costs and running times
接下来,观察了图中MDL表示的各部分存储代价。如图7,MDL表示的存储代价共有4部分组成:超点(节点分组)、摘要图、边修正和属性修正。其中边修正和属性修正是主要的表示成本,占到80%左右。同时也观察到,当原始图属性维度增加时(D4 →D5),属性修正代价呈直线上升。除了因为属性维度个数增加外,新增属性值是随机产生的也是原因之一。

图7 MDL表示成本(Greedy-MAGS算法)Fig.7 Breakup of cost of representation computed by Greedy-MAGS
整体来看,相较D5 数据集,所有算法在D4 数据集都产生了更少的属性修正。这是因为真实的数据集节点属性通常与节点邻居节点相关,称之为节点自然属性同质性的优势,比如社交网络上通常是相同层次的人员之间进行互动交流,他们具有共同的朋友和兴趣品味(属性)。因此产生较少的属性修正。D4 数据集具有节点自然属性同质性的优势。而D5 数据集因为每个节点有一维属性值是随机生成的,因此属性值与邻域之间不协调,则产生了更多的属性修正。
5 结语
首先,本文对多属性图概要问题进行了分析,提出了多属性图概要问题的MDL 模型。其次,提出了计算节点属性相似性方法,将节点间的相似性统一为存储代价,解决了不能同时考虑节点属性相似性和领域相似性这两个语义完全不同的实体的问题。然后,提出了两种多属性图概要算法贪心算法Greedy-MAGS和随机算法Random-MAGS适应不同的图概要需求。最后,通过在真实和合成的数据集上实验分析,证明本文所提能属性图概要方法的有效性。下一步工作主要集中在以下几个方面:基于MDL 的图概要方法对应的修正列表占据的空间消耗较大,几乎占所有消耗的80%,并且发现修正列表中存在一些重复率较高的编辑操作,可针对这个进行再次压缩,比如可以使用Huffma 编码或者串表压缩(LZW 算法)等算法提取修正列表中的不同编辑操作,基于这些编辑操作创建一个编译表,然后用编译表中的字符的索引来替代原始修正列表中的相应编辑操作,减少进一步原始数据大小。另外现有算法仅考虑了边的结构信息,下一步工作多加考虑边的类型以及权重等信息。
