基于Java的网络爬虫系统研究与设计
2021-08-06李尚林陈宫雷勇
李尚林,陈宫,雷勇
(桂林理工大学 信息科学与工程学院,广西 桂林 541004)
0 引言
如今信息化时代学习方式早已不同以前,利用网络开展学习必不可少。网络资源不同于传统学习资源,具有实时性高、数量大、内容丰富、传播速度快、范围广、易共享等特点。而且通过网络学习不受限于环境因素,这种随时随地获取学习资源的形式特别迎合快节奏人群的学习需求[1]。但随着互联网技术的日益发展,网络中信息量呈爆炸式增长,在搜索学习资源时尽管搜素引擎会帮助用户抓取一部分网络信息,但对于信息需求的不同往往还需要花费大量时间进行过滤筛选,显然这样的方式既费时又费力。爬虫技术的诞生有效的解决了这个问题。由于爬虫的种种优点,其也成为现代人检索网络信息的重要工具。
如何使用爬虫技术让程序高效、自动化的获取资源信息,简化获取学习资源的过程,成为人们在使用爬虫时所面临的主要问题。因此本文探究了静态网页爬虫和动态网页爬虫的设计过程,实现了静态网页的多线程泛用性爬虫,并以百度图片、百度文库为例设计实现了动态网页的多线程特殊性爬虫,完成对所需资源的高效爬取。
1 爬虫相关技术
1.1 爬虫技术简介
网络爬虫,又称为网络机器人或者网页蜘蛛,是一种按照自身需求和一定规则自动抓取万维网信息的脚本或程序。如今使用爬虫检索信息和资源已成为人们访问万维网的入口和指南。
按照系统结构和实现技术的不同,爬虫可大致分为四类[2]:
(1)通用网络爬虫。其爬取对象可从一个种子延伸到整个Web。这类爬虫爬取范围广、数量大,因此对爬取速度和存储空间要求较高。典型应用为百度、谷歌搜索等大型搜索引擎。
(2)聚焦网络爬虫。聚焦网络爬虫又称为主题爬虫,它是按照预先定义好的主题进行相关页面爬取的网络爬虫。由于只爬取与主题相关的页面,聚焦网络爬虫可大大节省硬件和网络资源。
(3)增量式网络爬虫。增量式网络爬虫指不爬取重复部分,只对已经获取网页的新增部分进行爬取。其采取增量式更新的爬取方法,可有效减少爬取次数。
(4)深层网络爬虫。Web页面按照存在方式可分为表层网页和深层网页。表层网页是指搜索引擎可以直接索引,通过超链接即可进入到静态网页主体;深层网页是指需要用户提交关键词或表单数据才能访问到的网页。因此深层网络爬虫需要分析页面结构,将预先准备的数据自动填写到表单中并提交至服务器验证处理,最终才能获得相应的资源信息。
实际中的网络爬虫应用往往是几种网络爬虫技术相结合实现的。
1.2 HttpClient技术简介
HTTP是面向事务的应用层协议,它是万维网上能够可靠交换文件(包括文本、声音、图像等各种多媒体文件)的重要基础[3]。在Java网络编程中会经常遇到HTTP协议编程,虽然JDK提供了HttpURLConnection编程接口对HTTP协议进行支持,但由于协议应用本身的复杂性,使得在大量实际项目中单纯使用JDK进行HTTP编程仍然比较困难[4]。HttpClient 是Java所支持的 Apache Jakarta Common 下的子项目,用来提供和支持 HTTP 协议的客户端编程,不仅如此它还支持 HTTP 协议最新版本和规范。HttpClient的出现大大降低了HTTP网络编程的复杂度,使其也成为了Java网络爬虫的核心技术之一。
1.3 Jsoup技术简介
Jsoup是一款HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM、CSS以及类似于jQuery的操作方法来取出和操作数据,只要解析的内容符合规定就能返回一个简洁的页面详情[5]。由于Jsoup良好的可扩展性API 设计,以及强大的HTML解析功能,其也广泛的应用于Java网络爬虫中。
1.4 多线程技术简介
计算机中正在执行的程序被称为“进程”,相对于程序来说进程是一个动态的概念,是程序的一次执行过程。线程相比进程来说属于更小的运行单位,一个线程是指进程中一个单一顺序的控制流。一个进程中可以并发多个线程,每个线程并行执行不同的任务。在如今信息高速化时代单线程的效率是非常低的,多线程技术可有效提高程序运行效率[6]。
2 系统分析
2.1 系统概述
本文研究的爬虫系统主要分为两部分,静态网页的泛用性爬取和动态网页的特殊性爬取。静态网面的泛用性爬取涉及的功能模块有:设置参数(User-Agent和cookie)模块、获取目标URL的HTML文本模块、Jsoup解析模块、深度爬取模块。动态网页的特殊性爬取涉及的功能模块有:百度图片按关键字爬取模块、百度文库文档爬取模块。下面对这些功能模块进行详细描述。
2.2 系统功能
2.2.1 静态页面爬虫设计及实现
静态网页爬取功能的核心是通过HttpClient对目标静态网页发出请求并取得服务器响应,接着将获得的响应内容(HTML文本)进行解析,获取所需资源的路径,从而将资源爬取下来[7]。静态网页爬取流程如图1所示:

图1 静态网页爬取流程图
(1)设置参数(User-Agent和cookie)模块的设计与实现。在HTTP协议中,报文的请求头部Header可用于服务器识别数据包来源(报文请求头部结构如图2所示),其中头部参数 User-Agent用于服务器识别用户身份,cookie中存储用户密码等信息[8]。如今网站大都有反爬虫措施,因此需要使用上述两个参数模拟真实浏览器向服务器发送请求,防止被服务器拦截[9]。user-Agent和cookie设置界面如图3所示。该部分核心代码如下:
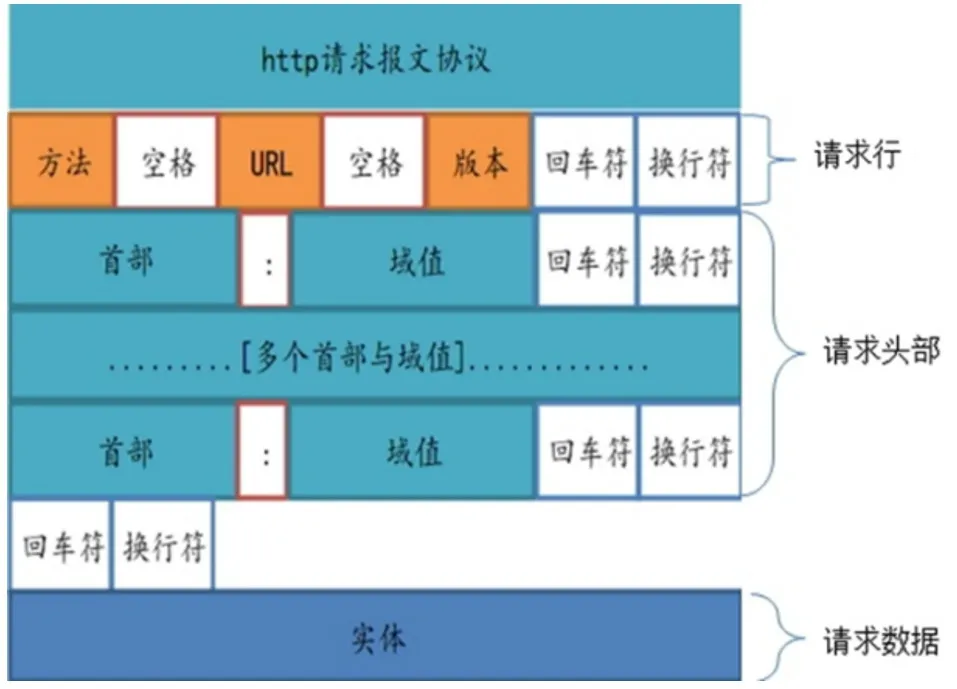
图2 http协议请求报文结构
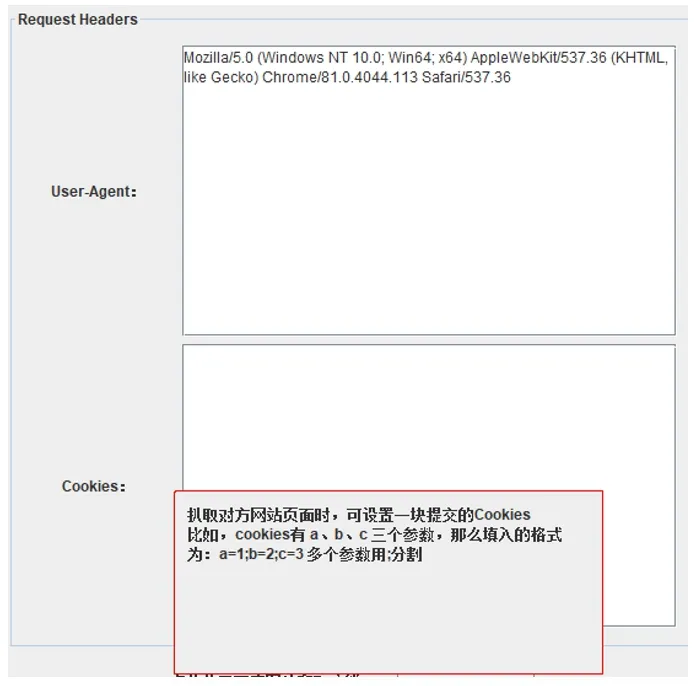
图3 user-Agent、cookie设置界面
//设置请求头
httpGet.setHeader(“User-Agent”, 真实浏览器的User-Agent);
httpGet.setHeader(“cookie”, COOKIE);
(2)获取目标URL的HTML文本模块的设计与实现。静态网页爬取的起点即为获取目标URL的HTML文本内容。设置请求数据包头部信息后使用HttpClient技术模拟真实浏览器向服务器发送请求,最终获得服务器响应得到所需的HTML文本信息,为下一步的内容解析做出准备。除此之外,还可以输入多个URL进行多线程爬取。该部分核心代码如下:
//获取客户端工具
CloseableHttpClient httpClient = HttpClientBuilder.create().build();
//创建get请求方法实例,并指定请求url
HttpGet httpGet = new HttpGet(url);
//发送请求,获取响应
response = httpClient.execute(httpGet);
(3)Jsoup解析模块的设计与实现。获取的HTML文本中往往只有某些特定元素是所需要的。因此利用Jsoup对HTML文本进行解析过滤,将所需资源从HTML文本中提取出来。通过观察所获取的HTML文本发现本文所需要的资源在a标签中,同时后续还需要进行深度爬取,因此利用Jsoup过滤出所有有效a标签中的链接。该部分核心代码如下:
//获取所有的href值
Elements aElements = this.doc.getElementsByTag(“a”);
//用来存放该页面中的连接
List<String> linkList = new ArrayList<String>();
for (Element aElement : aElements) {
//判断该href中是否有值,是否为”/”或者”//”,这些都是不需要的
if(aElement.attr(“href”).trim().length()>0 &&!aElement.attr(“href”).trim().equals(“/”) &&! aElement.attr(“href”).trim().equals(“//”)){
if (!aElement.attr(“href”).trim().equals(url)){
//查看是否链接中包含了http或者https,没有给链接加上
if(!(aElement.attr(“href”).toString().startsWith(“http:”)||
aElement.attr(“href”).toString().startsWith(“https:”))){
linkList.add(“http:”+aElement.attr(“href”));
}else{
linkList.add(aElement.attr(“href”));
}
(4)深度爬取模块的设计与实现。前面所设计的模块完成了静态网页简单爬取和解析,所爬取的内容局限于单个页面,因此需要进行深度爬取才能获取更多资源。深度爬取是通过解析起点网页中所有a标签的URL链接,将这些URL链接再次加入爬取队列并解析,如此重复循环,实现扩散性爬取。扩散性爬虫示意如图4所示。系统使用界面如图5所示。

图4 扩散性爬虫示意图

图5 系统使用结果界面
本文在使用多线程执行高强度爬取时会产生大量重复或无用的连接,因此需要对重复的连接去重以及使用cache存储筛选出有用的连接,从而大大减少无用的工作和程序负载,提高程序运行的效率。缓存结构流程如图6所示。

图6 缓存结构流程图
2.2.2 动态页面爬虫设计及实现
动态网页爬取往往是实现某个特定功能的爬取,不同的主题有不同的设计策略,因此没有一劳永逸的动态网页爬虫。动态网页不同于静态网页的资源可以直接完整爬取,动态网页通常需要用户进行特定操作后才会进一步加载展示,这种结构往往是用JSP、ASP、PHP等语言编写的服务器端代码。动态网页技术极大的增强了网页的多元性与新颖性,可以帮助网站吸引更多用户的注意[10]。对于动态网页的爬取主要是通过分析其搜索特性和报文交换规律,掌握服务器与用户之间是如何进行数据传递,最终利用爬虫技术将所需资源爬取下来。下面将以百度图片、百度文库为例设计实现动态网页爬虫。
(1)百度图片按关键字爬取模块的设计与实现。百度图片是百度针对用户需求,从8亿中文网页中提取各类图片而建立的中文图片库。设计爬虫程序,首先通过观察百度图片的数据加载过程可以得知,当用户输入关键字发起请求后,服务器通过json数据包返回所需图片资源信息,其中每项json数据中的middelURL项即为图片资源真正的url。在得知服务器如何向用户传送数据后还需要知道用户如何将请求准确的发送到服务器。因此分析百度图片request请求的URL参数规律。通过对比分析得知几个关键参数的含义,其中queryWord和word参数为用户所输入关键字的中文编码格式。百度图片数据加载过程如图7所示。

图7 百度图片数据加载过程
通过上述分析后,设计爬虫程序爬取百度图片。首先对URL的queryWord和word以及pn、rn、gsm三个参数赋予相应的值并向服务器发出请求,获取服务器响应内容后,从响应内容中解析JSON数据获取其中的middelURL地址,再对该middelURL地址发送请求即可将图片资源批量爬取下来(系统使用结果如图8所示)。详细步骤如下:

图8 系统使用结果界面
①对请求目标URL设置对应的queryWord和word以及pn、rn、gsm参数,并向服务器发送请求。该部分核心代码如下:
//设置参数值
String url = String.format(ROOTURL, keyWord,word, pn);
HttpGet httpGet = new HttpGet(url);
②对响应回来的json数据进行解析取出data数据,再对data数据中middelURL进行筛选。该部分核心代码如下:
//获得响应
res = EntityUtils.toString(response.getEntity());
//通过jsonobject来将CloseableHttpResponse转换成json对象
JSONObject jsonobject = JSONObject.fromObject(res);
//获取其中的data数据
String data = jsonobject.get(“data”).toString();
//使用正则表达式将middleURL给取出来
Pattern pattern = Pattern.compile(“middleURL”:”.*?””);
③获得middelURL后发起资源请求,完成对目标图片资源的爬取。该部分核心代码如下:
HttpGet request = new HttpGet(mURL);
//获取服务器响应,得到图片资源;
CloseableHttpResponse response = httpClient.execute(request);
④如此循环,开启多线程批量爬取图片资源。
(2)百度文库文档爬取模块的设计与实现。百度文库是百度发布供用户在线文档分享的平台,文档资源由百度用户上传,同时用户也可以在线阅读和下载这些文档。百度文库包括教学资料、考试题库、专业资料、公文写作、法律文件等多个领域。同样百度文库也是动态网页,分析其资源搜索特性和交换规律,设计爬虫程序(爬取流程如图9所示)。详细步骤如下:

图9 百度文库爬取流程图
①对服务器发起第一次资源请求。其中第一次资源请求中包含url、type、t、sign四个参数,url参数即为目标资源的url地址,type为文档类型即为doc。获得服务器响应后得到第一次资源请求所返回的json数据(如图10所示)。其中的s参数为所需文档资源的真实URL地址。

图10 第一次url返回的json数据
②得到文档资源的url等参数后,将文档资源的url、type、t、sign、f和h等参数重新拼接成新的url地址,向服务器发起第二次请求。
③获得第二次请求的服务器响应,得到所需资源的json数据列表后(如图11所示)通过使用Java的第三方jar包doc4j将其整合成所需的doc文档并写出成为文件,便完成对该文章的爬取(系统使用结果界面如图12所示)[11]。

图11 返回的json数据列表

图12 系统使用结果界面
3 结语
本文介绍了静态网页爬虫和动态网页爬虫的设计与实现,对爬虫原理进行了简要分析,并着重对爬虫的实现过程进行了讲解。如今网络资源数量巨大,掌握爬虫技术能够很好的帮助人们快速检索信息资源,简化获取资源的过程。本文从实际出发对静态和动态网页爬虫进行分析设计,完成了对静态网页的泛用性爬取,并结合特定实例(百度图片、百度文库)实现了动态网页的特殊性爬取,从而快速高效的获取资源信息,达到了预期效果。
