基于Spark Streaming的并行K-means改进算法研究
2021-08-06宋国兴张清伟郑明钊杜飞陈彬
宋国兴,张清伟,郑明钊,杜飞,陈彬
(中国移动通信集团设计院有限公司山东分公司(华北二区),济南250101)
0 引言
在“大网络”、“新基建”等政策背景下[1],网络化信息时代逐步进入大数据的爆发期,海量数据随着人们日常交流、购物、学习等生活的方方面面爆炸式产生,这也就对从海量数据中获取实时性信息提出了挑战[2]。传统机器学习算法已经无法满足从动态数据中快速获取实时信息的要求,特别是聚类等被广泛应用的算法,需要进行实时性优化改进。
K-means聚类算法是一种经典的数据挖掘聚类算法[3],算法过程主要依赖数据点分配阶段和聚类中心点更新阶段两个步骤迭代进行。但是对于实时数据进行聚类时,由于输入的数据是以实时数据流的形式[4],随着时间的推移,数据量会不断增加,导致传统K-means算法无法快速聚类。本文重点对传统K-means聚类算法采用Spark Streaming框架进行并行优化之后高效地完成对流式数据分析处理进行研究。
1 优化改进的K-means算法
基于Spark平台的K-means聚类,对输入的样本数据进行RDD数据块划分,然后将数据块分配到不同的集群节点。集群节点通过SparkContext的广播函数[5]共享聚类中心,map函数进行数据点分配,reduce函数完成聚类中心点的更新。在平台并行化处理大数据量时,使用KD树对迭代过程进行二次优化,避免在数据点分配过程中与所有的聚类中心进行比较。
对数据点分配阶段和聚类中心点更新阶段的并行化处理如图1。
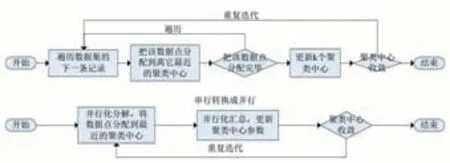
图1聚类模型并行优化
图1 聚类并行优化对应的算法伪代码如下:
输入:原始数据集,初始化数据聚类中心个数K输出:聚类模型
步骤:
1、输入原始数据集,将数据分成RDD数据块并分发到集群节点
2、基于随机方法或者Canopy等方法初始化聚类中心个数K
3、迭代运行步骤4至步骤9,直到模型收敛
4、把聚类中心广播分发到集群节点
5、针对每个RDD数据块,计算每个数据点x i到最近聚类中心u j对应的距离:

2 算法衡量指标
本文对K-means聚类算法[7]改进优化的目的在于使其适应实时数据聚类的要求,所以本文把收敛性、每轮迭代所需要的时间和吞吐量等方面作为衡量指标,着重从优化改进后算法的收敛准确率和时间效率两个方面进行算法的评价。前者主要考察算法优化的合理性、并行设计的科学性、迭代收敛的准确性[8],后者主要验证并行化之后效率的提升情况。
本文从以下几个具体的指标进行平台性能的综合评估。
平均运行时间:在算法参数收敛之前,需要对原始数据进行训练、迭代,整个过程需要消耗大量的运行时间,把每一轮迭代的平均运行时间作为基本衡量指标,来衡量算法收敛的时间效率。
吞吐量:单位时间内系统所处理的任务总数。在通常情况下,随着任务数量的增加,平台中排队等待的任务数会增加,这将导致系统的任务处理能力不会随着输入的任务数的增加而提高。本文设计的平台采用了Spark Streaming流式处理的方式[9],由于流式处理的逻辑通常比较简单,实时性处理能力优越,会在相当大的程度上弥补这个不足。
收敛准确率:算法在迭代过程中达到设定的迭代次数阈值时,被准确聚类的数据点个数占数据点总个数的比值[10],用来衡量算法收敛之后得到的聚类结果的准确性。
3 算法性能试验验证
3.1 试验环境
本文搭建包含6个节点的Spark集群进行试验,节点具体配置如表1和表2。
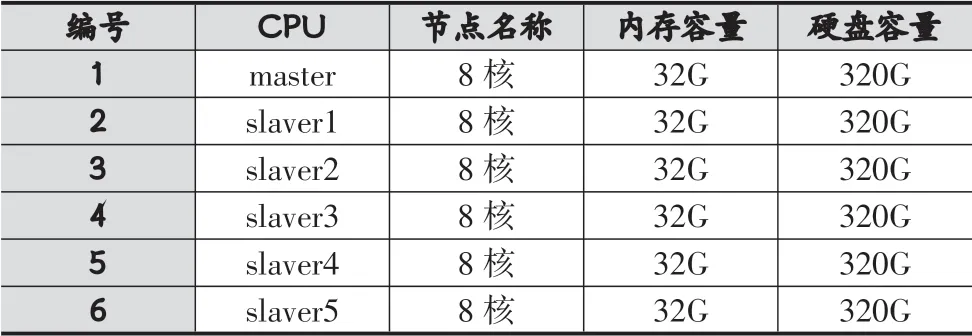
表1 节点硬件配置

表2 节点参数配置
集群环境安装Hadoop 2.6版本,Spark 2.4版本,JDK 1.8版本。Hadoop并行化最大map数为16,最大reduce数为2,每个任务可以使用4G内存,Spark每个节点的计算内存为20G,用于数据计算和RDD数据块间的调度和关系依赖加载。
3.2 试验结果对比
实验从平均运行时间、吞吐量和收敛准确率三个指标,对单机版的K-means聚类算法、Spark平台集成的算法和Spark Streaming优化后的算法三种状况下进行对比。实验数据为某购物平台的真实数据,选取的数据对(样本数,特征数)为(1w,100)、(1w,1k)、(10w,100)、(10w,1k)、(100w,100)、(100w,1k)。
(1)平均运行时间
从待测数据输入测试环境到得到收敛后的算法模型为一个运行周期,每种算法用六组数据进行独立测试,测试结果如图2。
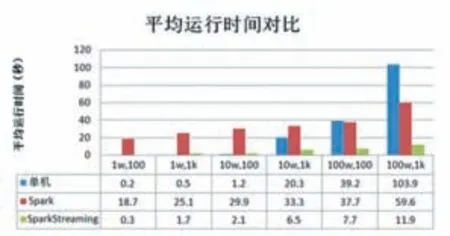
图2 平均运行时间对比
由图2测试结果可以看出,在数据量较小时单机模式和SparkStreaming模式都能取得较好的运行速度,SparkStreaming模式和Spark模式需要不断的进行节点间的信息传输和调度,但是SparkStreaming模式通过流式处理和并行优化,降低了节点间数据传输带来的时间消耗,而Spark模式由于需要节点间数据传输,所以会比单机模式消耗时间多。随着数据量和特征数量的增多,单机模式会越来越无法承受大数据量的迭代计算,时间消耗会成倍增加,SparkStreaming模式和Spark模式由于是采用分布式模式,处理大数据量数据较单机模式有明显优势,SparkStreaming模式的优化处理,即便是数据量增加,所消耗的时间不会增加太多。
(2)吞吐量
本实验选取10秒内在三种环境下处理的任务数(即迭代次数,并保留整数位)进行对比。为了尽可能模拟现实场景下的实时处理,测试数据以数据流的方式输入到测试系统,并且数据流以并发的形式从多个节点同时输入。在实验中,数据流生成间隔设定为0.5秒,滑动窗口为2秒。测试结果如图3。
由图3实验结果可以看出,三种处理模式的吞吐量都会随着数据量的增多而降低,但是由于本文的改进算法同时采用Spark的流数据框架和滑动窗口策略,在大数据量的聚类状态下仍然能保持较高的效率。
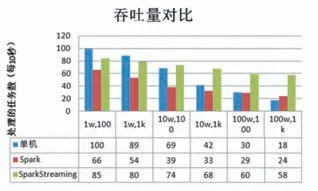
图3 吞吐量对比
(3)收敛准确性对比
本实验的聚类算法属于无监督的机器学习范畴,无法用某一个标准聚类结果作为参考,所以,在验证收敛准确性时,SparkStreaming模式和Spark模式的聚类结果与单机版模式做比较,用三者的偏差作为衡量标准。具体衡量指标为:同一聚类中包含的数据点个数和单机版模式下对应聚类中数据点个数的差值与单机版模式对应聚类中数据点总个数的比值。实验结果如图4。
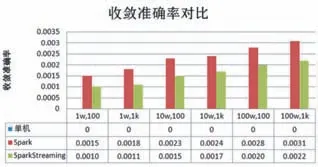
图4 收敛准确率对比
由图4实验结果可以发现,在六组数据上的测试结果偏差很小,说明基于Spark Streaming的并行K-means改进算法在聚类准确性方面可以满足要求。
综上实验结果,基于Spark Streaming的并行K-means改进算法在聚类准确性较高的情况下,在收敛速率方面又明显的优势,可以满足实时性数据聚类的要求。
4 结语
为了解决经典的K-means聚类算法无法满足大数据背景下对实时聚类的要求,本文基于Spark Streaming流数据处理框架对K-means聚类算法进行改进,通过SparkContext的广播函数共享聚类中心、KD树对迭代过程进行二次优化、以滑动窗口作为数据的输入单元动态调整批量数据的输入时间间隔和聚类中心的更新频率等优化策略,使得改进算法在满足聚类准确性的同时能够很好地处理实时数据。后续工作将继续针对不同的应用场景对改进算法进行定向优化。
