基于深度学习的高分辨率图像的智能检测
2021-08-03朱雅乔史延雷马幪朔尚志武
朱雅乔,史延雷,马幪朔,岳 峰,尚志武
(1.天津中德应用技术大学航空航天学院,天津 300350;2.中汽研(天津)汽车工程研究院有限公司中汽中心汽车工程研究院,天津 300300;3.武汉科技大学汽车与交通学院,武汉 430065;4.天津工业大学机械工程学院,天津 300387)
在自然场景中,自动驾驶车辆所采集的图像一般都是具有高分辨率的图像,所需检测的目标在图像中占比不大。目前还没有一种有效的针对高分辨率图像的目标检测方法[1-2]。
为此,现以行人检测为例,探讨一种高分辨率图像的目标检测方法,力求不仅能有效检测出目标,还具有较好的实时性。
行人检测[3-4]作为自动驾驶和智能监控等应用的一个关键组成部分,在过去十多年里受到了极大的关注。大多数行人检测方法可以分为两大类:基于手工特征的方法和基于深度学习的方法。基于深度卷积神经网络成功用于计算机视觉任务之前,已经有多种手工制作的特征描述法,包括SIFT(scale invariant feature transform)[5],LBP(local binary patterns)[6], SURF(speeded-up robust features)[7],HOG(histogram of oriented gradient)[8],Haar[9]已经被用于行人检测。Piotr等[10]将图像的多种通道特征相结合,分别在灰度通道,梯度幅度通道,LUV颜色通道和梯度方向上计算Haar-like[11-13]特征,用于行人检测。Felzenszwalb等[14]提出了一种可变形的行人部件模型(deformable part-based model,DPM)。随着深度学习的迅速发展,基于深度学习的检测模型成为了研究热点,主要分为两类,一类是以R-CNN(region convolution neural networks)[15]、Fast R-CNN[16]、Faster R-CNN[17-19]为代表的基于候选框的检测方法;另一类是以YOLO(you only look once)[20-21]为代表的基于回归的检测方法。Liu等[22]提出一种扩展的Faster RCNN行人检测框架,通过添加网络分支,从不同网络层提取多分辨率特征图,确保不同规模行人的良好检测。
然而,尽管基于深度学习的检测算法能够快速准确地检测某些区域的目标,但是这些方法通常不能达到很好的性能,仍然存在下列不足。
(1)在行人检测过程中行人候选框的产生并非十分准确。
(2)对于高分辨率图像的目标检测,Faster R-CNN处理较为耗时且可能出现由于目标较小而无法识别的情况。
针对这些问题,提出一种基于LDCF-ResNet50的深度学习检测框架。首先基于局部无关通道特征(locally decorrelated channel feature,LDCF)[23],设计行人候选区域提议方法,用来检测行人潜在区域;然后设计一种提议区域合并和扩展的方法,将提议区域合并成正确的候选框,用于后续的ResNet-50[24]神经网络精检测;最后将ResNet50网络的结果映射到原始图像中,输出检测结果。
1 行人检测算法
车载摄像头拍摄的图像通常具有高分辨率。然而,一般的深度学习网络在处理高分辨率图像时性能相对较差。在实验过程中发现,如果将高分辨率图像分割成包含目标的小区域,深度学习检测网络可以在这些小区域上表现良好。
根据这种方法,提出了一种高分辨率图像中的行人检测方法,它主要包含三个方面:①基于区域提议方法;②基于ResNet50的行人检测方法;③用于精确定位的后处理步骤。
该方法的结构示意图如图1所示。
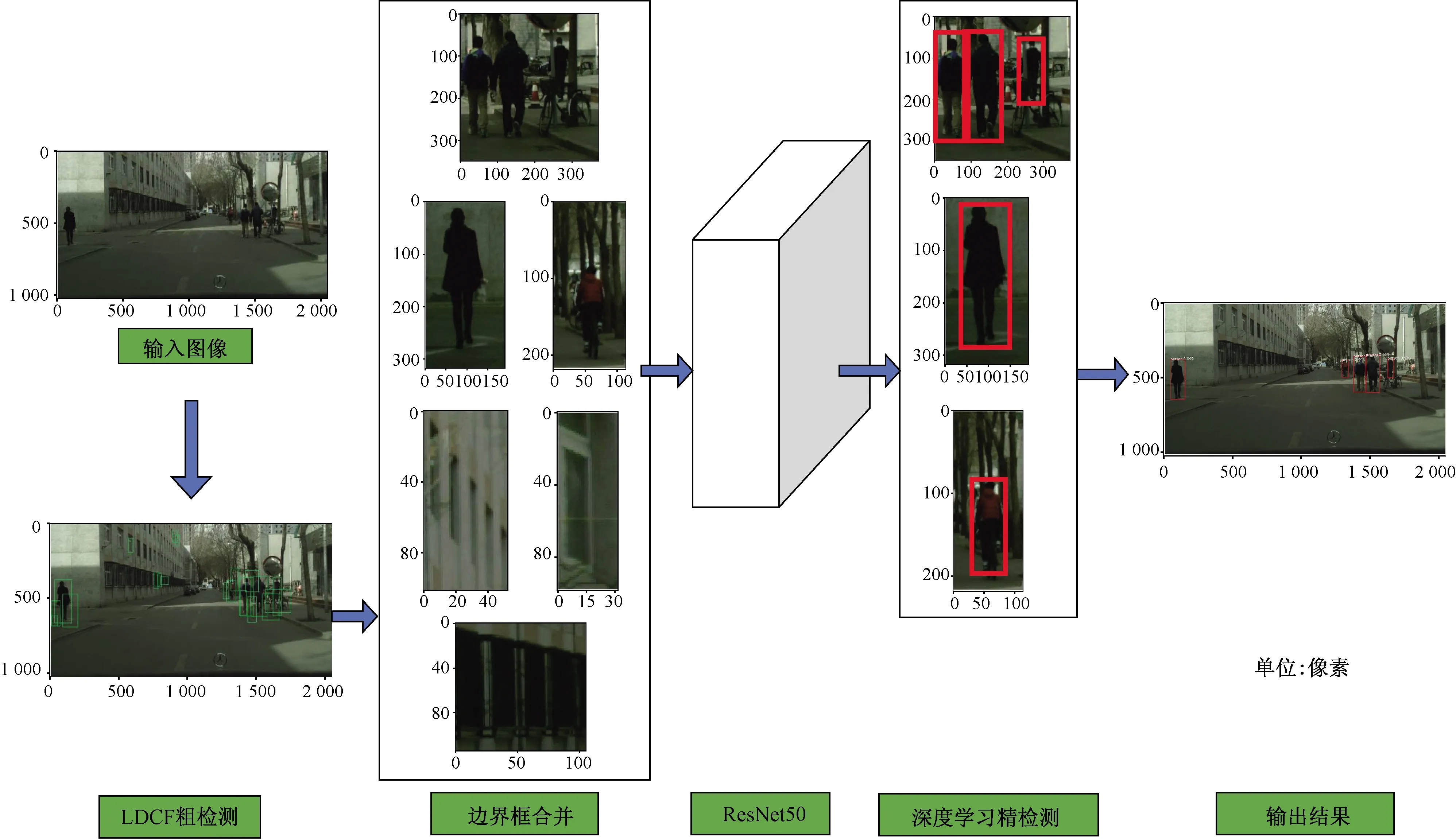
图1 提议的行人检测框架
1.1 基于LDCF区域提议方法
原始的LDCF在行人检测问题上已经取得了良好的性能,但是在高分辨率图像的检测上,还是会出现漏检的现象。为了解决这个问题,提出了LDCF提议区域生成方法,为之后的深度学习网络提供包含对象的优良潜在区域。给定一张输入图片,LDCF融合了多种特征通道信息,包括3个颜色通道(LUV),1个梯度幅值通道(|G|)和6个梯度方向直方图通道(G1-G6),如图2所示。LDCF将这10个通道采用LDA算法进行局部去相关,获取前4个特征向量构成滤波器核,并把这4个滤波器核分别与通道特征图像做卷积运算,则在每个特征通道上输出得到40张特征图,将这些特征图进行级联得到最终的LDCF特征,然后通过Adaboost分类算法进行训练。

图2 特征通道示意图
为了实现行人检测的高质量边界框,Zhang等[25-26]首次提出以0.41的统一纵横比自动生成边界框。将modelIDs设置为(50,20),modelDsPad设置为(64,25)。nNeg(要采样的负窗口的最大数量)设置为10 000,nAccNeg(要累积的负窗口的最大数量)设置为30 000。图3展示了LDCF行人粗检测算法的具体测试流程。
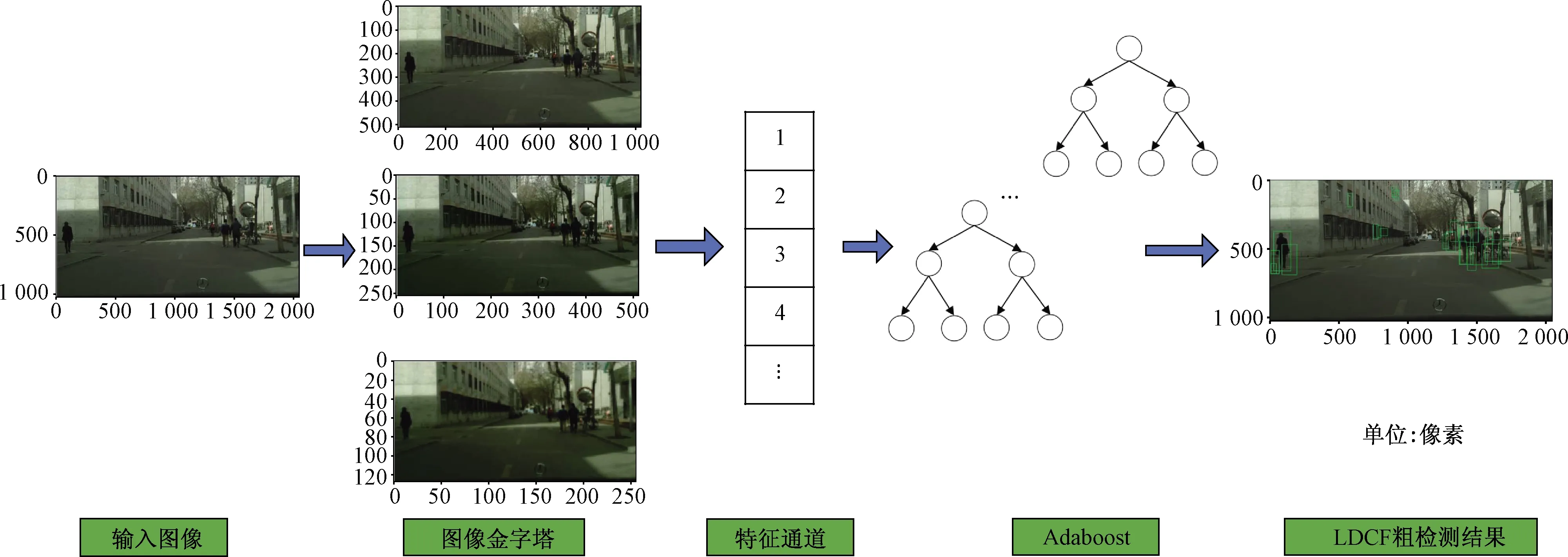
图3 LDCF行人粗检测算法流程
在检测实验过程中发现属于一个行人边界框之间的距离并不远。因此,设计了一种合并方法,用于合并属于同一对象的边界框。并根据边界框之间的距离分为两种情况。一种是两个边界框之间有重叠;另一种是两个边界框之间没有重叠。
第一种情况下,检测到的每个行人实例是由多个不同的边界框来标记。为了将边界框合并成一个正确的边界框,并得到整个行人实例,当两个边界框有重叠时将它们合并。用w1、h1和w2、h2表示两个边界框的宽度和高度,a,b分别表示两个边界框,表达式为
(1)
(2)
式中:(xa1,ya1)、(xa2,ya2)和(xb1,yb1)、(xb2,yb2)是两个边界框的左上角和右下角坐标。用xt1和xt2表示在两个边界框在x轴上的相对最小值和最大值。同样,用yt1和yt2表示在两个边界框在y轴上的相对最小值和最大值。
(3)
(4)
(5)
(6)
然后,通过计算两个边界框之间的wo和ho判断是否进行合并得到一个大的边界框,即
wo=(w1+w2)-(xt2-xt1)
(7)
ho=(h1+h2)-(yt2-yt1)
(8)
如果wo>0且ho>0时,进行合并操作,得到两个边界框的最大x坐标和最小x坐标为xt2和xt1,基于此可以计算合并后的边界框的宽度wt。同样的,得到两个边界框的最大y坐标和最小y坐标为yt2和yt1,可以计算合并后的边界框高度ht。其将合并后的边界框作为后续网络的输入。
第二种情况下,如果两个边界框距离彼此较远,也就是当wo≤0或ho≤0时,意味着这些边界框属于不同的实例,则不需要合并。或者当合并后的边界框wt≥345或ht≥835时,也不参与边界框合并。其中,345和835是本数据集中行人实例的最大大小。为了更好地定位和检测,这些边界框也将作为后续网络的输入,进行进一步的检测。
1.2 特征提取
特征提取模块采用ResNet-50[24]网络结构,将图像I作为输入,网络可以生成具有不同分辨率的若干特征图[27],其定义为
φi=fi(φi-1)=fi(fi-1{…f2[f1(I)]})
(9)
式(9)中:φi表示的是第i层输出的特征图;f表示的是卷积神经网络。给定输入图像I的大小H×W,最终拼接特征映射的大小为H/r×W/r,其中r为下采样因子。r=4是实验中所证明的最好的性能,因为r越大意味着粗糙的特征映射难以精确定位,而r越小则带来更多的计算负担。采取的特征融合方式及提取图片的特征的方法,如图4所示。
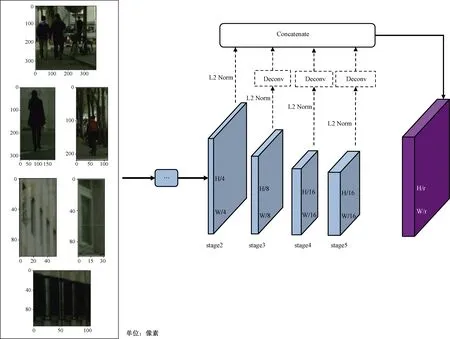
图4 基于ResNet50网络检测结构
2 实验
2.1 数据集和评估方法
所使用的数据集为TDCB[28],其涵盖了大量街道上各类行人的真实生活场景高分辨率(2 520×1 260)图片。其中包含行人30 490张,但是该数据集中的一些行人相对于肉眼来说都是不可见的,按照文献[29]的方法,剔除了行人像素小于30的图像。因此,在实验中又重新构建了训练集、验证集和测试集。随机选取包含10 000张包含行人的图像组成新的数据集,并按照训练集∶测试集∶验证集=7∶2∶1的比例分配。
使用PASCAL视觉对象分类挑战[30]中的方法,精度和召回率之间的关系来对模型进行评估。精度和召回率曲线。精度P和召回率R计算公式为
(10)
(11)
式中:TP表示真实阳性样本的数量;FP表示误报的数量;FN表示假阴性的数量。使用平均精度(AP)[31]表示检测的性能。AP定义为
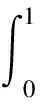
(12)
AP值越大,性能越好。使用IoU来测量检测相应对象的准确性,并且IoU的重叠面积必须超过0.5才被认为成功检测到。IoU的定义为
(13)
式(13)中:DR代表检测区域;GT表示真实目标区域;DR∩GT代表两者的重叠面积,DR∪GT代表两者的合并区域。
2.2 结果分析
为了评估本文所提方法的有效性,将所提方法与其他三种方法的性能进行了比较,包括YOLOv3[20]、Faster R-CNN[17]和SSD[32]。使用精度-召回率曲线和平均精度在验证集上对比评价本文所提出的LDCF-ResNet50深度学习网络。
图5所示为在验证集上测试的所有识别方法的P-R曲线,同时为了比较模型进行实时处理的能力,在3.40 GHz Xeon Gold 6128 CPU处理器和NVIDIA 2080 GPU处理器上对每个模型处理单张图片的速度进行的测试,结果如表1所示。
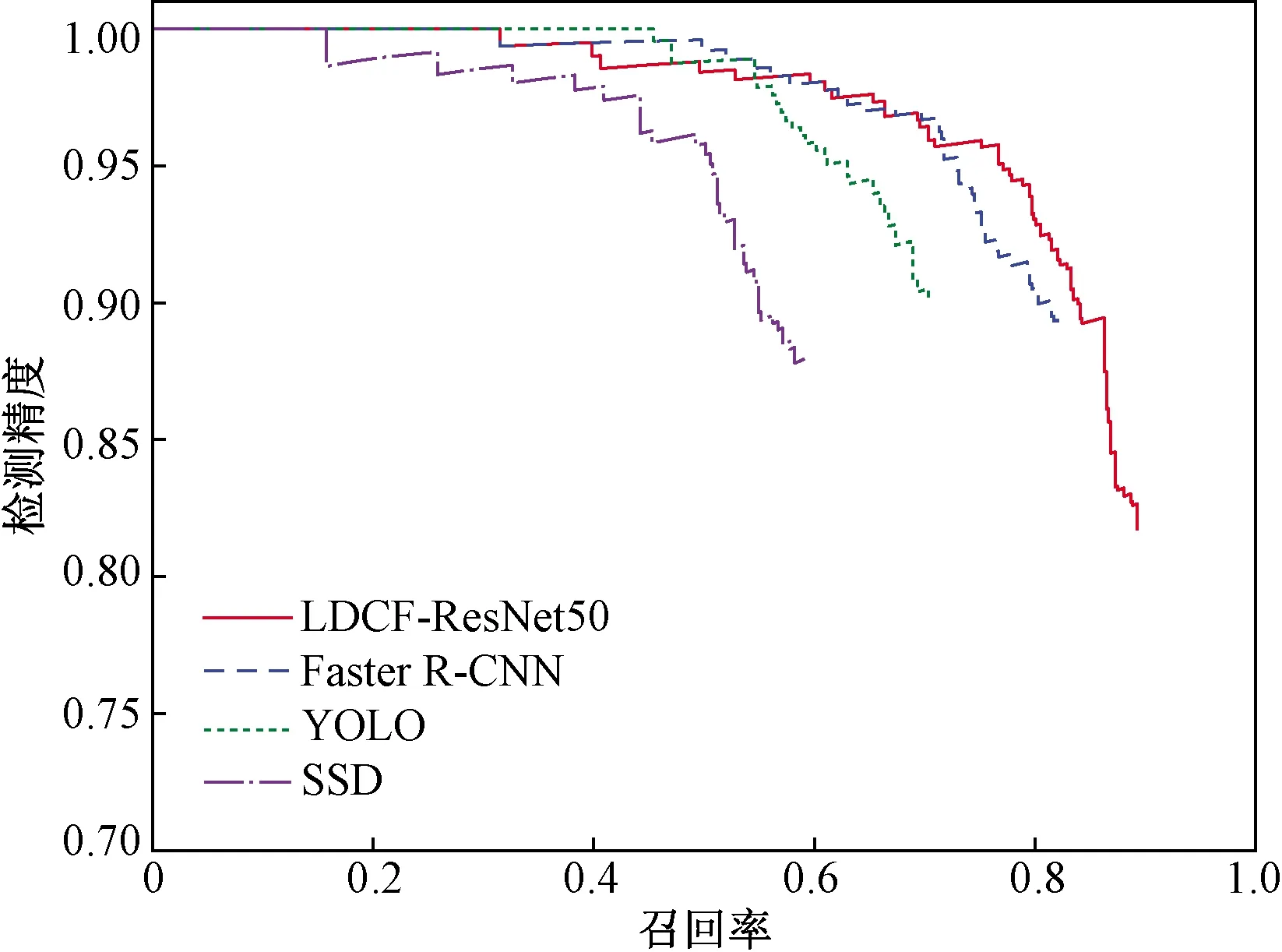
图5 不同行人检测方法的P-R曲线
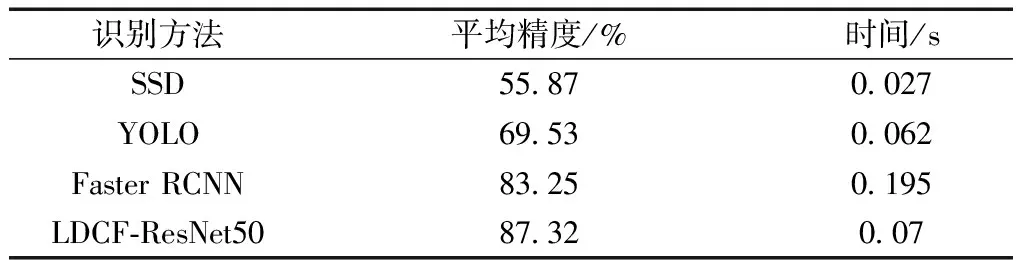
表1 不同行人识别方法的平均精度
在本文研究中,将AP用作检测精度的评估指标,并将匹配阈值设置为0.5。该指数综合考虑了定位精度和分类精度。同时,为了比较模型执行实时处理的能力,研究了在访问视频流的条件下处理每个模型的单帧速度。表1的比较结果表明,SSD是最快的方法,其次是YOLO,LDCF-ResNet50和Faster R-CNN。尽管YOLO和SSD比LDCF-ResNet50和Faster R-CNN快,但是它们的检测精度却低得多;LDCF-ResNet50为行人提供最高的检测精度,如图6所示。考虑到检测精度和速度之间的权衡,LDCF-ResNet50优于其他所有三种方法。LDCF-ResNet50的行人检测AP值分别比SSD,YOLO和Faster R-CNN高31.45%、17.79%和4.07%。
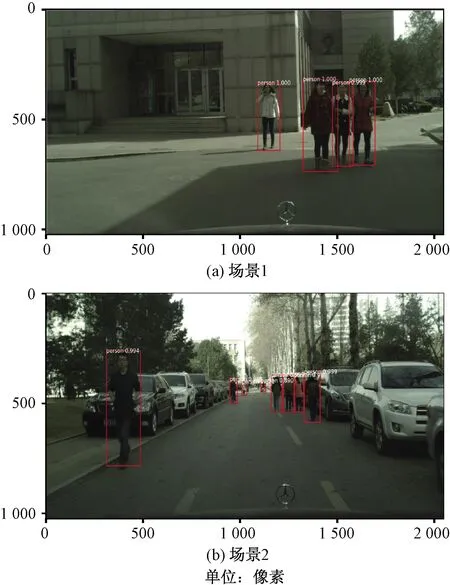
图6 行人检测结果
3 结论
研究使用LDCF-ResNet50方法解决了高分辨率图像上的行人检测问题。解决了大多数现有方法对于高分辨率图像检测速度慢、漏检和误检的问题。基于LDCF提取行人候选区域,进行粗检测;然后,设计一个合适的RseNet50深度学习网络以获取更多的细节信息,并对提议区域进行精检测。在高分辨率数据集下的实验证明:本文方法相比于之前的方法有了明显的提升。尽管本文中以行人检测为例,但是它在其他物体检测方面具有很大的潜力,如高分辨率图像上的车辆检测和一般物体检测等。
