Android应用Smali代码混淆研究
2021-08-02邱子杨
邱子杨,付 雄
(南京邮电大学 计算机学院,江苏 南京 210003)
0 引 言
根据2016年第一季度统计报告指出[1],Android设备所占市场份额为76.4%。但同时根据《腾讯移动安全实验室2016年上半年手机安全报告》指出[2],2016年上半年新増安卓恶意应用安装包918万个,是2014年全年新增恶意应用包的9.15倍,感染用户数量已经超过2亿,同比去年增长了42%。安卓用户群体的高比例以及恶意应用软件的激增使得安卓应用软件的安全防护技术日渐重要。
攻击者一般会通过对安卓应用程序进行反编译并篡改代码再对其进行重新打包并且重新签名来进行恶意行为的攻击。当攻击者攻击一个安卓应用程序文件时,并不会直接反汇编去分析其smali代码[3],因为smali代码过于复杂,难以读阅,而他们往往会把可执行文件apk反编译成java源码,然后从java源码中获取到关键代码的位置,然后再去对应的smali代码位置进行篡改[4],然后重新打包,重新签名就可以得到一个被纂改过的安卓应用程序。
因此,防止Android应用程序逆向分析是非常重要的。在以往的研究中,Enck等列出了Android系统的安全性分析方法[5],分析了Android系统的安全性模型并解释其复杂性。Felt和Fahl等[6-7]详细说明了Android系统的安全性。Bernhard等[8]开发了Bauhaus,基于软件安全技术和代码分析技术的Android系统源代码分析工具,并通过案例研究从安全认证和许可机制的角度分析了Android系统实施中的不一致信息。
牛豪飞[9]实现一套在ART模式下的安卓应用保护方案。通过对Android平台的体系结构、安全机制以及常见静态和动态攻击的分析,提出了动态和静态两个方向的安卓安全防御方案。尉惠敏[10]提出了一套基于Hook文件的自修改方案,可以应对大部分攻击手段。其加密粒度更小,加密精度更准确。实现了So动态库中函数运行前解密运行后加密,保证任何时刻So动态库都不是完整的明文。是一种针对于Hook攻击的动态防御机制。
对于Java层面的安卓应用加固,彭守镇[11]提出了基于资源文件的加密方式。对反编译后的dex文件进行加密混淆处理,对资源文件进行加壳处理,从而预防apk被反编译篡改,增强打包难度。吕苗苗[12]提出基于Java的安卓应用代码混淆技术。通过抽离安卓软件中的code_item代码,将其进行混淆然后形成混淆代码索引表,同时在So中进行封装。最后采取JNI机制注册封装后的代码,生成特定的执行环境。从而做到对安卓应用代码的混淆加固。
对于smali层面的安卓加固,郑琪等人[13]通过插入多余的控制流和压扁控制流对控制流进行混淆以对安卓应用进行防御。并从功能、性能两个方面做出了评价。刘方圆等人[14]同样在smali层面对安卓应用加固进行研究,其主要是对寄存器的值加以混淆以及通过不透明谓词对控制流进行混淆,并且在强度、弹性、开销进行的技术评价。吴林[15]提出了基于Dalvik字节码指令的混淆技术,从数据流和控制流两个层面对apk进行混淆。
综合现有的工作,大部分的工作都是针对于Android应用程序中源码级别Java代码的混淆,对于Android应用程序中smali级别的代码的安全性分析还是比较缺少。对于Java源代码层面的混淆目前主要是控制流和标识符混淆两个方面,可是大部分情况下厂商并不可能直接提供源码给安全公司,这样的话这种保护就无法发挥其作用。对于现有的smali层面的研究,主要围绕数据流和逻辑流进行混淆[16-18],且混淆方式并不考虑对原来安卓应用的额外消耗,且混淆方式单一,缺乏动态性。
针对上述代码混淆技术出现的问题,文中提出了smali代码的混淆保护方法,在除去数据流和控制流两个层面之外,又增加了逻辑流层面的混淆,并且对于数据流和控制流消耗方面也做了优化和把控,其主要贡献如下:
(1)设计实现smali代码混淆系统,不需要提供源码,但能对抗攻击者的攻击。
(2)针对之前研究的混淆方式,提出新的混淆方式逻辑流混淆用来加强混淆强度。
(3)实验与评价。用这种方法保护后的应用程序可以抵抗静态分析,并使反编译后的代码出错。同时,还评估了其对时间和空间性能的影响,以证明该方法的有效性。
1 混淆框架综述
文中提出的混淆方式不同于Java策略方向的安全加固,不需要源码但是完全可以对抗恶意攻击,通过对Android应用程序代码中间产物smali代码的混淆,使得攻击者无法获取正确的逻辑代码。
下面简要介绍该方法的混淆过程(见图1):
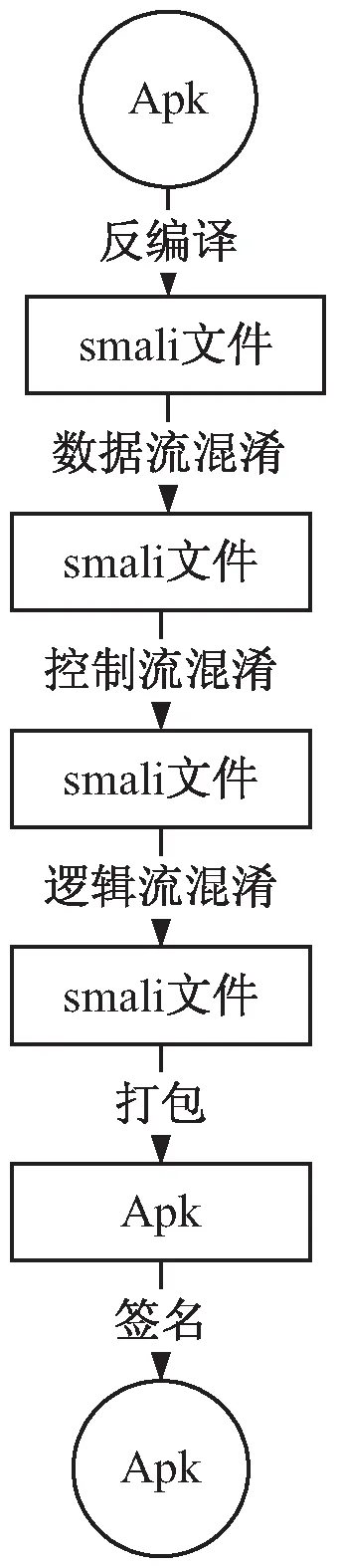
图1 混淆方法过程
step1:反编译待保护的apk文件;
step2:遍历所有smali文件,通过数据流混淆模块进行混淆;
step3:遍历所有smali文件,通过控制流混淆模块进行混淆;
step4:遍历所有smali文件,通过逻辑流混淆模块进行混淆;
step5:将编译后的文件重新打包为apk文件;
2 加密策略
在数据流混淆模块中,对数据通过加密策略进行混淆,为了不影响源程序的性能,且尽量缩短加密过程但对数据能起到混淆的作用,所以文中提出了一种基于字典的简易加密方式。但由于字典加密算法有较大风险,字典一旦被破解或盗取就面临数据泄露的风险,所以又通过RSA对字典进行加密存储在服务器端,且字典是由系统随机生成的,所以不同Apk的数据加密方式是不同的,减少被破解的风险。下面介绍字典的生成和传输过程。
step1:生成两个数组A,B,其大小为26,且每个数组依次存放0-25数字;
step2:打乱A数组和B数组的内容,即为字典D;
step3:使用混淆系统中的私钥对A与B进行加密存储,生成加密字典RSA(D);
step4:混淆系统发送字典RSA(D),给需要加密的apk端,apk端通过公钥解密得到字典D;
step5:使用字典D进行加密。
在上述过程中,小写字母x对应的密文为A[index_x],其中index_x=ascii(x)-0;ascii(x)为x对应的ascii的码值。同样大写字母X对应的密文为B[index_X],其中index_X=ascii(X)-0;ascii(X)为x对应的ascii的码值。
3 混淆策略
Collberg等人[19]提出了代码混淆的概念,提出了代码混淆的基本定义,给出了第一个代码混淆算法,将代码混淆分为外形混淆、控制混淆、数据混淆和预防混淆,通过强度、执行代价、弹性来评估有效性。代码混淆其实就是一种代码功能一致性的转化,会保留与之前代码一致的有效性,通过某种混淆转换,使得变换后的程序在具有相同功能的前提下更难分析[20]。如果程序和具有一致的可观测行为,则称其为混淆转换。
代码混淆的基本原理如图2所示,整体上说混淆方式主要有静态混淆和动态混淆两个方式。静态混淆有控制流混淆、数据流混淆等,动态混淆是通过自定义的混淆器来达到运行过程中动态的进行混淆以及解混淆的方法。
2017年,彩云社区在进行居民情况调查时,了解到杨家的事。李敬益打算啃啃硬骨头,牵头调解试试看。他把杨家七个兄妹都找来,挨个了解了下他们的想法;再把老太太的两个兄弟请来,“两个舅舅一来,讲了句公道话,‘都是一家人,现在就剩下你们妈妈了,也得考虑考虑她。’”李敬益听完,心里大概有了数,这一家人的目光总围着商铺转,如果按着以往的思路往下走,只讨论商铺的归属,这矛盾怕是难解。得转换个思路,综合考虑、综合盘算。
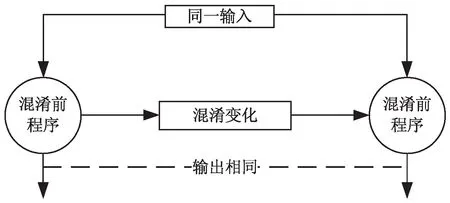
图2 smali代码混淆原理示意图
smali代码混淆:
(1)基于字典加密的数据流混淆。
在Dalvik虚拟机中,由于字符串是通过明文形式显示赋值给寄存器,然后再由具体操作在寄存器内取字符串的具体值,这样就会造成代码暴露的危险性。所以可以将字符串进行加密处理,对数据进行混淆,增加代码阅读难度,降低破解代码逻辑风险。
在传统加密方式中,常用的加密方式为对称加密和非对称加密,但其加密方式繁琐且性能消耗大,但是混淆方法中,对原有程序的影响越小则混淆方法是越有效的,所以文中采用基于字典的加密方式来简化加解密过程,减少对原有程序的影响。这种加密方式即随机生成a-z以及A-Z唯一对应的字典密文后进行加密。数据流混淆过程如算法1所示。
算法1:数据流混淆。
输入:待保护应用反编译之后的smali文件。
输出:数据流混淆之后是smali文件。
1.设smali文件集合为F=(f1,f2,…,fn),其中fi表示第i个smali文件。
2.遍历集合F,逐行读取fi文件。
3.设行内容为fij,记录加密位置pm=j(当fij满足正则s*const-strings+(v|p)(d),s+”(.*)”),添加到集合Pi中。
4.设字典加密算法为D(x),遍历集合Pi,获取加密字符串s=D(fipm),替换fipm=s。
5.遍历集合F,输出。
6. end
算法1只是对如下指令const-string v0, “InjectLog”进行简单的修改,并且由于加密算法是基于字典进行加密,所以并不会修改字符串长度,且解密过程是基于字典式的,所以查询密钥对应原文的时间复杂度为O(1),并不会对系统性能产生很大的消耗,也不会对系统文件大小产生改变,但是能在一定程度上抵抗逆向工具的逆过程,是一种低消耗、高性能的数据流混淆方式。
图3为数据流混淆后的结果。

图3 数据流混淆
可以看出,有意义的字符串全部被更换为了无意义的字符串,这样就使得攻击者无法从字面获取程序的意义从而进行逻辑分析,很大程度上增加了逻辑分析的难度。
(2)低消耗控制流混淆。
算法2:控制流混淆。
输入:待保护应用反编译之后的smali文件。
输出:控制流混淆之后是smali文件。
1.设smali文件集合为F=(f1,f2,…,fn),其中fi表示第i个smali文件。
2.设存储方法的集合为Map集合,M=(mi,ci),其中mi表示方法的全限定名称,ci表示mi被调用的次数。
3.遍历集合F,逐行读取fi,如果当前调用了方法mi,检测Map是否存在(mi,ci),如果存在则ci++,否则添加一个新元素(mi,ci)(其中ci=1)到Map中,并且维持方法总量C=C+ci(C初始值为0)。
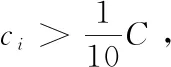
5.重新遍历集合F,逐行读取fi,如果当前调用的方法mi∈P,则执行控制流混淆器D(x),混淆结果s=D(mi),替换fi=s。
6.遍历集合F,输出。
7. end
控制流混淆相对于数据流混淆来说,是更有效的混淆方式,其原理是在程序的某些地方添加一些常用的控制switch、if等来隐藏原程序中真正的控制流程,从而阻止反编译攻击。并且在smali语法中,控制流语法复杂程度远远高于Java源代码,其是通过跳转指令来实现对代码的逻辑控制,所以加入一些无效控制流或者修改一些控制流,可以很大程度混淆代码,降低代码的可读性。
文中提出的低消耗控制流多注入的混淆方式,首先确定插入位置,确定插入位置的方式是将方法被调用次数作为依据,超过阈值的,将其被调用的位置确定为待插入位置。
控制流混淆不会对原有命令做修改混淆,而是在原有命令上增加无效控制流,比如常用的if分支,switch分支,这增加了原有程序的复杂性,给攻击者分析smali代码增加了难度。
图4为控制流混淆的结果。

图4 控制流混淆
可以看出,混淆后之前的简单逻辑被加大了复杂度,出现了分支,从而干扰攻击者的逻辑分析,增大了分析难度。
(3)逻辑流混淆。
对数据流混淆和控制流混淆来说,如果攻击者通过数据分析获取加密规则并且攻击者对smali语言十分熟悉,这种情况下,数据流混淆和控制流混淆会显得苍白。
为加大混淆力度,文中提出一种新的混淆方式—逻辑流混淆,逻辑流是指程序的执行过程。
由于smali源代码所有的逻辑必然都是与APP本身执行过程有关的,所以当攻击者进行反编译之后,对smali源代码,在短时间内很有可能分析出APP执行过程从而对APP的安全造成危害。为了提高安全性,文中提出了一种逻辑流混淆的思想,让攻击者在短时间内无法分析出APP的逻辑流,或者让其分析无效的逻辑流。
逻辑流混淆的具体做法是在APP逻辑流某一节点处添加不影响APP逻辑流和数据流的自定义逻辑流,不仅加大APP逻辑流的复杂程度,也由于无关逻辑流的加入,使得攻击者对于APP执行过程的分析并不都是有效的,进而增加APP的安全性。对于自定义的逻辑流,如果过于复杂会增加APP对系统的消耗,过于简单又对混淆加固起不到很大作用,所以选择合适的自定义逻辑流是尤为重要的。控制流混淆过程如算法3所示。
算法3:逻辑流混淆。
输入:待保护应用反编译之后的smali文件。
输出:控制流混淆之后是smali文件。
1.设smali文件集合为F=(f1,f2,…,fn),其中fi表示第i个smali文件。
2.构建逻辑流图T=(t1,t2,…,tn),其中ti为树节点,也就是调用的方法,其中T表示树的层次遍历序列,且T是一棵有序树。
3.选择逻辑流节点,这里采用随机选取的方式,调用逻辑流混淆器D(x),结果t=D(ti),替换ti=t。
4.遍历集合F,输出。
5. end
图5为逻辑流混淆的结果。

图5 逻辑流混淆
可以看出,之前的逻辑前后不只是单纯的一个逻辑的执行,而是被加上了多余的逻辑,而这些多余的逻辑是逻辑流混淆模块自定义的,与程序本身逻辑流无关,也不会影响程序逻辑流的执行。这样的混淆既做到了安全加固,增大攻击者分析难度,也不会影响源程序的执行,且由图可看出相对数据流混淆和控制流混淆,复杂度更高。
4 评价标准
4.1 强 度
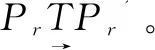
4.2 执行代价
混淆程序Pr'相对于原始程序Pr由于混淆产生的额外开销,通过执行代价来度量。
执行代价的定义如下:

表1 执行代价度量
4.3 弹 性
弹性用来度量混淆程序的抵抗攻击程度,是指针对于反混淆程序的攻击,主要包括反混淆程序运行时的时间和空间代价以及攻击者编写反混淆程序的代价。
弹性定义如下:
规定T是对Pr的一个单项的混淆变化当且仅当从原始程序Pr除去某些信息后无法通过混淆后的程序Pr'恢复出Pr。
5 有效性分析
5.1 强度分析
对于文中提出的smali代码混淆方法从数据流、控制流、逻辑流三个层面进行混淆。在数据流混淆方面,将constr指定中存储的字符串进行加密存储,这种方法使得逆向分析获取的字符串值是错误的,实验结果如图3所示。在控制流混淆方面,在关键函数调用指令和返回值获取指令中间插入不透明谓词,使得攻击者无法获得正确的控制流程,逆向工具逆向结果图4所示。在此基础上文中还提出了新的混淆方式,即逻辑流混淆方式,因为APP在逆向之后所有的逻辑流都是和APP本身运行有关的,所以引入逻辑流混淆,才进行一些无用逻辑的处理和调用。逆向工具逆向结果如图5所示,当攻击者利用逆向工具去逆向分析时,结果不仅仅是APP的逻辑流还有加入混淆的逻辑流。
5.2 开销分析
对不同的混淆方式分别进行时间开销的分析。对于数据流层面的混淆只是简单的加密混淆对时间开销必然没有影响。对于控制流混淆,插入的无效控制流时间复杂度都为O(1),并且控制流个数的插入也是有限的,所以并没有影响原程序的复杂度。对于逻辑流混淆,插入的新逻辑流的时间复杂度均为O(1),这在可以容忍的范围之内。对于空间开销来说,由于混淆仅仅是针对关键函数进行指令转换、插入定量的无效控制流、修改控制流,以及插入定量的空间复杂度为O(1)的逻辑流,因此,smali代码的混淆方法对于程序空间开销来说影响较小。
5.3 弹性分析
被混淆的程序,在数据流层面其字符串的值被加密混淆,在控制流层面进行的混淆,如图4所示,增加了程序的控制流复杂度;除此之外,对于逻辑流进行混淆,如图5所示,增加了许多无关程序的逻辑流,加强了程序的复杂度。可以看出文中的代码混淆方法具有较好的弹性。
6 实验结果
如图1所示,文中设计并实现了一个smali混淆系统,能够有效地抵抗逆向分析。
实验环境:Android7.0红米Note,Idea开发环境。测试用例说明如表2所示。

表2 测试用例说明
测试用例:本节采用四个自主编写的Android应用程序作为测试用例,这四种应用程序是具有代表性的,完全可以表明混淆方法的有效性。
文中从两个方面分析smali混淆系统的性能,一方面是通过应用程序保护方法的有效性来评估应用程序保护方法的质量,另一方面通过保护前后应用程序的性能消耗变化评估其质量。对于有效性,之前已经在强度、开销、弹性进行了分析,接下来对性能消耗变化作根据四个测试用例的实验结果进行分析,主要从三个方面分析性能消耗:保护前后的代码长度变化,时间开销变化和空间开销变化。
由于移动设备往往在内存和处理器方面是受限的,所以应用程序的大小以及APP启动时间很重要,这关乎到用户体验问题。因此对代码长度变化以及启动时间进行定量分析以此来证明smali混淆系统的有效性。
如表3所示,混淆程序相比于原始程序代码长度并没有显著变化,主要原因如下:
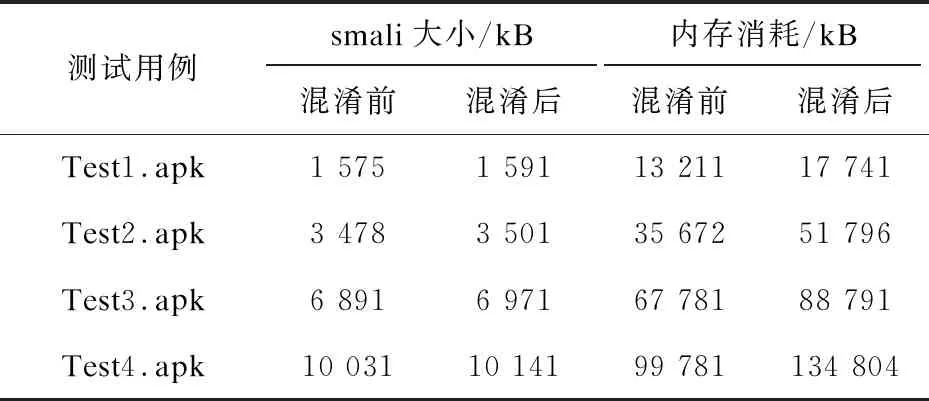
表3 代码长度和开销
(1)对const-str中的字符串只是加密等长替换,所以对代码长度不会有影响;
(2)只是简单的指令替换;
(3)测试用例的代码长度本身比较小,满足混淆操作的指令并不多;
(4)逻辑流混淆插入的部分的逻辑,是新增的逻辑,由于新增逻辑本身并不大,所以对代码长度和内存消耗也并不是很大。
为了更直观地体现混淆操作对应用程序的影响并不大,另外比较了应用程序混淆前后启动时间的变化(见表4)。
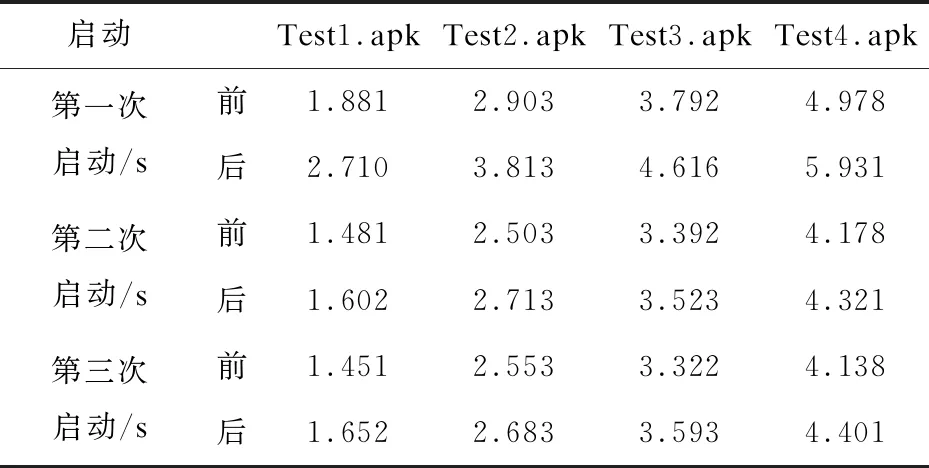
表4 启动时间变化
4个应用程序在第一次启动时,启动时间在混淆前后有明显的变化,分析原因可能是以下原因造成的:
(1)dex文件类加载器的替换;
(2)混淆方法的查找。但是在第一次启动之后,可以发现启动时间在混淆前后基本没有变化。
7 结束语
针对Android应用程序容易被反编译篡改smali源码并重新打包重新签名的问题,提出了一种smali代码混淆的应用程序保护方法,不同于常规的Android应用程序保护,是针对于smali层面做的防护,无需获得源码即可进行混淆,并且在常规的数据流和控制流层面使用了新的算法。在数据流层面采用快速加解密的字典式对其进行混淆,在控制流层面,选取特定的位置进行混淆,并且控制流的插入会选取轻量级消耗的控制流,从而减少对程序开销的影响。文中在此基础上还提出了新的混淆层面逻辑流混淆,相对于数据流和控制流来说混淆强度更大,扩展性更强,这使得对Android应用程序的防御有很大的提升。同时也从强度、开销、弹性三个方面对smali代码混淆方法进行了分析,也从代码长度和启动时间定量进行了分析,实验结果表明,smali代码混淆方法是有效的。
总之,提出的smali代码混淆对于解决Android安全性被破坏的问题有一定意义,但是对于自定义的逻辑流没有进行很好的选择,导致开销上有一定影响。因此下一步工作将针对逻辑流进行优化,以更好地保护代码并且减少消耗。
