基于超分辨率重建的低分辨率表情识别的研究
2021-08-02潘沛生
王 珏,潘沛生
(南京邮电大学 通信与信息工程学院,江苏 南京 210003)
0 引 言
近年来,人脸表情识别技术在医学研究、案件侦破、自动驾驶等领域[1-2]有着广泛的应用。但受限于目前的监控系统,绝大多数都是远距离的场景下,获得的人脸表情图像是视觉模糊和小尺寸的,该文将这类图像称为低分辨率人脸表情图像,这类图像具有较少的表情特征,所以低分辨率的人脸表情识别是极其困难的。目前研究低分辨率人脸表情识别课题的方向较少,其中张灵等人[3]利用压缩感知理论重建低分辨率疲劳表情图像;李桂峰[4]采用基于块和基于像素提出的正则化方法对低分辨率微表情图像进行处理。传统算法重建的图像会出现丢失细节、边缘模糊的问题。研究表明,深度学习在图像超分辨率重建[5-8]和识别领域[9-11]比传统方法取得了更好的效果。针对上述问题,该文提出一种基于深度学习的超分辨率重建算法用于对低分辨率面部图像进行表情识别。
1 算法框架
提出的低分辨率人脸表情识别的系统流程如图1所示。该算法主要包括两个子网络:基于新的混合损失函数的超分辨率重建网络和基于小尺度卷积核的人脸表情识别网络。具体操作流程是:先将低分辨率人脸表情图像输入超分辨率重建网络从而生成高分辨率人脸表情图像,然后对该人脸表情图像进行特征提取并实现分类即表情识别。
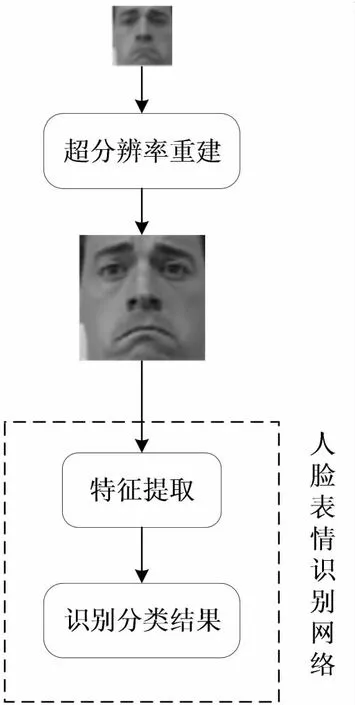
图1 低分辨率人脸表情识别系统流程
1.1 基于新的混合损失函数的超分辨率重建网络
该文基于深度学习的超分辨率重建网络结构[8]如图2(a)所示,输入的低分辨率图像经过卷积和32个相同的残差网络结构叠加构成残差块学习图像特征,再进行上采样操作,然后得到重建后的高分辨率图像。
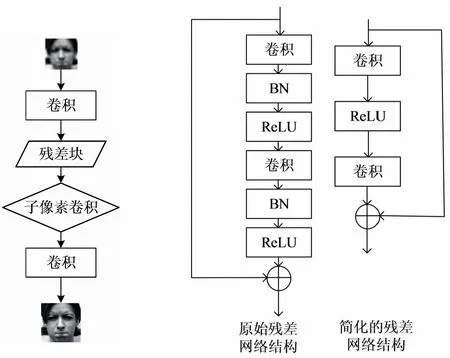
(a)超分辨率重建网络结构 (b)残差网络结构
首先残差网络[8]的结构如图2(b)中右图所示,对比原始的残差块(如图2(b)左图),该网络结构去掉了两个批量归一化操作(batch normalization,BN)和线性整流函数(ReLU)。因为,BN[12]会对提取到的特征值进行正则化处理,从而导致整个网络的灵活性下降。
其次,系统中对特征图进行上采样,采用的方法是子像素卷积(shuffle)层[13]。该方法是隐含在卷积层中的,可以实现自主学习,从而避免引入过多的人工因素的干扰,并且会提高算法效率。
最后,为了生成更高质量的人脸表情图像,该文提出一种新的混合损失函数以减少重建后的人脸表情图像与原始高分辨率人脸表情图像的差距,其定义为:
Lloss=αLsmooth L1+(1-α)LSSIM
(1)
其中,Lsmooth L1,LSSIM分别表示鲁棒的L1型损失函数[7]和结构相似性(structural similarity,SSIM)损失函数[14],α(0≤α<1)表示损失函数的权重。
Lsmooth L1损失函数用于衡量像素的相似性,其定义为:
(2)
其中x和y表示重建后的图像与原标签图像。
Lsmooth L1损失函数是基于逐像素比较差异,忽略邻域的标签,Lsmooth L1损失函数比L1型损失函数稳定,同时比L2型损失函数收敛速度块,易于模型的训练。
SSIM可以用于衡量图像相似性,该损失函数考虑每个像素的局部邻域,可以将较高的权重分配给边界。如果将其整合到网络的损失函数中,可以获得标签图像的结构信息,其表达式为:
(3)
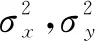
若采用单一的Lsmooth L1损失函数,其只考虑对应点像素的差异,会造成图像缺少部分高频,并且出现过度平滑的纹理[12]和局部结构缺失,因此采用混合损失函数共同监督。Lsmooth L1损失函数可以减小像素差异,LSSIM损失函数通过对邻域像素的计算,保留高频信息,提高图像质量。
现有研究中,针对社会化信任关系的协同过滤技术的隐私保护工作尚不多见.因此,从考虑隐私保护和预测准确率两者间的折中以及协同过滤技术中的数据稀疏性和冷启动问题,本文将差分隐私保护技术引入融合显/隐式信任关系的SVD++协同过滤技术中,提出目标函数加扰的TrustSVD差分隐私保护新策略.关于新策略,文中在理论上分析了其隐私保护的性能,实验上验证了其在协同过滤应用中的预测表现.结果表明:所提新策略与无隐私保护的TrustSVD具有相近的预测准确率,与做类似差分隐私保护的SVD++相比获得了更优的预测结果,此外还给出了核心参数的调节实验.
1.2 基于小尺度卷积核的人脸表情识别网络
如上所述,输入的低分辨率人脸表情图像经过基于深度超分辨率重建网络结构已经生成高分辨率人脸表情图像。之后再将该图像送入人脸表情识别网络结构后提取特征并分类。文中借用VGG网络[15]的思想,采用小尺度卷积核提取特征,然后使用softmax分类器得到表情分类的结果。
当前人脸表情识别研究中,为了提高人脸表情识别的准确率,大多数算法采用更深、更宽的网络结构,但在提高准确率的同时,带来了复杂的计算量和较低的识别效率。文中所述算法通过小尺度卷积核提取特征,降低计算复杂度,从而提高了识别效率。
如图3所示,基于小尺度卷积核的人脸表情识别网络结构由6个3×3卷积的小尺度卷积层、6个池化层、1个全连接层和softmax层组成。小尺度卷积核用来提取人脸表情特征;池化层用来减小特征图的大小,文中采用的是最大池化层;全连接层将前面提取到的表情特征加权求和得到每种表情的分数;softmax分类器的作用将全连接层得到的分数映射为概率,从而得到表情识别结果。
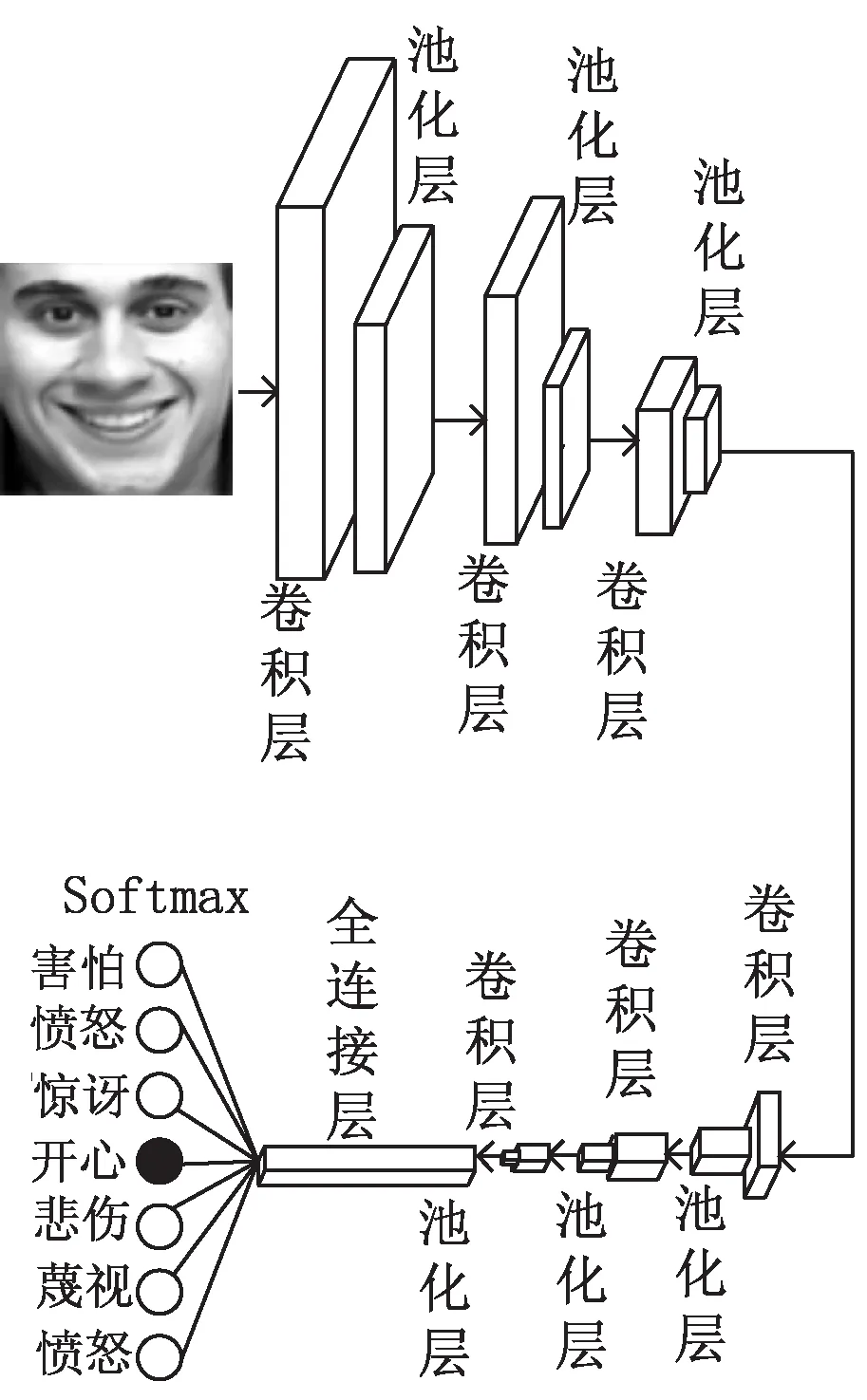
图3 人脸表情识别网络结构
其次,每个小尺度卷积层的卷积核个数分别为64,128,256,512,512,512,其中步长均为1。最大池化层的步长为2。假设人脸表情图像大小为88×88,将该图像输入网络结构,经过卷积层后,会得到64个88×88的特征图。这些特征图再通过最大池化层进行下采样得到44×44×64大小的特征图,再经过五个同样的卷积层和最大池化层的操作,输出1×1×512大小的特征图,然后将特征图送入含有512个神经元的全连接层,输出1×512维的向量。最后通过softmax分类器得到表情识别的结果。
为了衡量该网络结构的计算复杂度,一般通过其参数量(空间复杂度)来表示,其计算公式为:
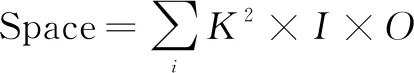
(4)
2 实验结果与分析
本研究所有训练和测试的过程均使用深度学习框架:GPU版本的Tensorflow,具有便携、高效和兼容性好等优点。实验采用的硬件平台为Ubuntu16.04,GTX 1080TI GPU。使用的开发环境和工具为Anaconda软件,python3.6环境。
2.1 人脸表情识别数据集
本研究采用的训练和测试的数据集为CK+[16]人脸表情数据库,该数据库中的实验样本包含7种表情:愤怒,蔑视,悲伤,厌恶,开心,惊讶,害怕。该数据库是在实验室条件下获取的,数据可靠。文中选取该数据中每个序列的最后三帧,总共981张,愤怒,蔑视,悲伤,厌恶,开心,惊讶,害怕表情数据集的数量分别为135,54,84,177,207,249,75。实验将表情图像裁剪为96×96大小,作为原始高分辨人脸表情图像。
2.2 实验处理及参数设置
在超分辨率重建网络结构中,将CK+数据集按照8∶2比例分为训练集和测试集,模型训练阶段迭代次数设置为40 000次,批量大小设置为16。经过多次实验,将混合损失函数中的权重α设置为0.8,可以取得最佳效果。
在人脸表情图像识别网络结构中,将CK+数据集也按8∶2比例分为训练集和测试集。由于CK+数据量过少,会造过拟合问题,因此,在训练阶段,随机在图像的左上角,左下角,右上角,右下角和中心进行切割,得到88×88的图像并做镜像操作,这样的操作可以使训练集增大10倍。在该网络结构训练阶段,动量设置值为0.9,学习率初始值为0.01,权重衰减的系数为0.000 5。
2.3 实验结果对比与分析
为了验证文中提出的低分辨率表情识别算法的有效性,将原始高分辨率图像进行4倍、8倍、16倍的下采样,分别得到24×24、12×12、6×6大小的低分辨率人脸表情图像,如图4所示。

图4 不同大小的低分辨率人脸表情图像
之后,将不同大小的低分辨率人脸表情图像送入超分辨率重建网络结构中,生成高分辨率图像,再将人脸表情图像送入人脸表情识别网络结构中。文中以12×12尺寸大小的图像为例,如图5所示,第一行是原始高分辨率人脸表情图像(HR),第二行是低分辨率人脸表情图像(LR),第三行是采用文献[6]中的算法(EDSR)重建的人脸表情图像,第四行是使用文中方法重建的人脸表情图像。从图中可以看出,低分辨率人脸图像(LR)非常模糊,表情特征难以区分。采用EDSR算法重建的人脸表情图像,五官位置比较明确,但在嘴角和眼角位置存在局部模糊问题。采用文中算法重建的人脸表情图像,不仅五官位置比较明确,对于嘴角和眼角的局部位置重建清晰,而且整体来看,图像纹理更加清晰。

图5 8倍超分辨率重建结果对比
文献[6]中提出的EDSR算法在基于深度学习的图像超分辨率重建方面是优于SRCNN[5]、FRSCNN[6]、VDSR[7]等算法的,因此,为了验证文中方法对人脸表情识别准确率提高的有效性,将低分辨率图像采用基于局部先验约束算法[17]、EDSR算法和文中算法重建得到的图像进行表情识别准确率的比较,如表1所示。

表1 CK+数据集人脸表情识别准确率 %
由数据分析可得,在识别相同低分辨率表情图像时,文中算法的识别准确率均提高了,并且均高于基于局部先验约束重建算法和EDSR算法,说明文中算法可以提高低分辨率面部图像表情识别的正确率。
同时,在输入极低分辨(6×6)人脸表情图像的情况下,准确率提高了9.091%,优于算法,表明文中算法对极低分辨率面部图像的表情识别效果最好。
最后,为了分析各种表情的准确率,依然以12×12大小重建的高分辨率人脸表情图像的各类表情准确率为例,如表2所示。
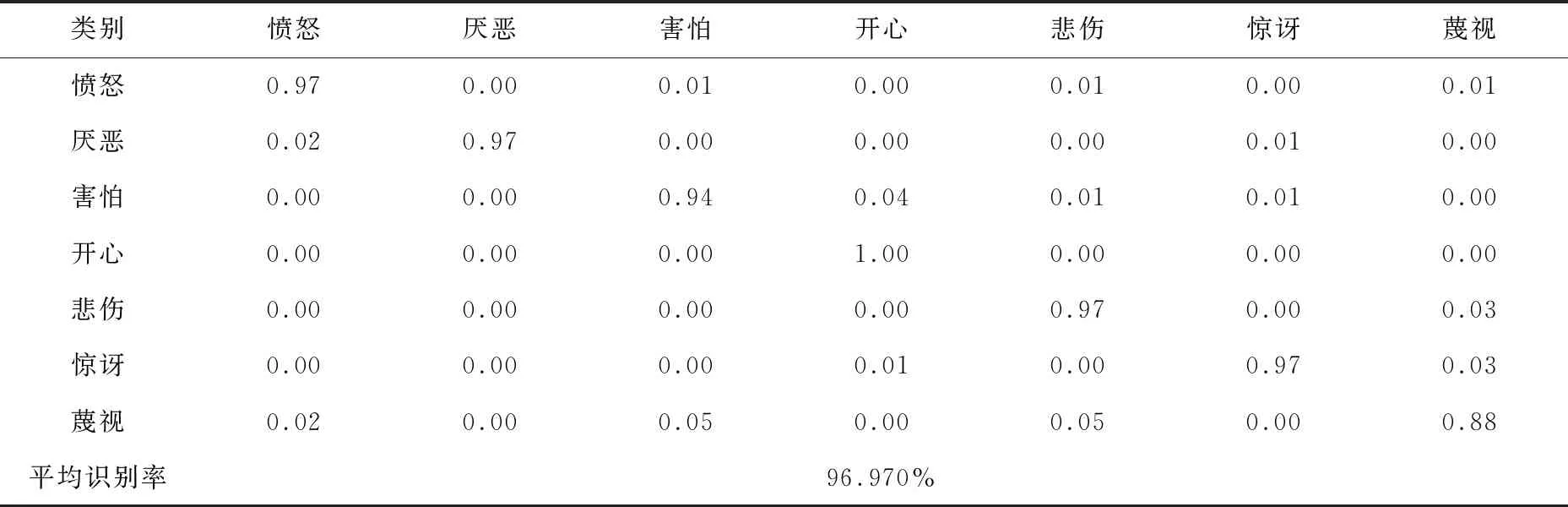
表2 重建后人脸表情图像识别准确率
在表2中,12×12大小重建后的高分辨率人脸表情准确率为96.970%。其中开心准确率为100%,愤怒、厌恶、悲伤、惊讶的表情识别准确率为97%,蔑视的准确率为94%,害怕的准确率为88%,该表情准确率较低的原因是数据集中该表情的数量较少,且表情不易区分。
3 结束语
文中提出了一种用于低分辨率表情识别的系统结构。首先,为了重建低分辨率人脸表情图像,引入了基于简化的残差块网络,并提出通过新的混合损失函数共同监督,Lsmooth L1虽然避开L1型和L2型损失函数的缺点,保持颜色亮度特征,但缺乏高频信息;LSSIM损失函数含有高频信息,但对亮度和彩色变化迟钝。当结合这两个损失函数时,既保留了图像的颜色和特征,也保留了高频信息。然后,将重建后的人脸表情图像通过小尺度卷积核提取特征,再进行分类识别。实验结果验证了该系统的可行性和优越性,有效地提高了低分辨率人脸表情的准确率。进一步的研究方向是针对部分人脸表情难以区分、准确率低的问题,考虑对提出的结构继续进行改进和优化。
