基于生理信号的情绪识别研究综述
2021-07-31邓丽娜王晓亮
邓丽娜,王晓亮
(湖南科技大学,湖南 湘潭 411100)
0 引 言
情绪(Emotion)是人的感觉、思想和行为的综合状态[1],在人们的交流中起着重要作用。情绪识别是指通过人的行为和生理反应来识别相应的情绪状态[2]。准确识别情绪在人机交互和人工智能领域的研究中占据重要位置,在教育、医疗和生活等领域拥有广阔的应用前景。
一般来说,用于情绪识别的数据可分为两大类:使用如面部表情和语音声调等行为数据,这类数据采集简单,但易被人为掩饰或伪装[3];使用脑电(Electroencephalogram,EEG)、 皮 肤 温 度(Skin-Temperature, SKT)、 眼 电(Electrooculogram, EOG)、体积描记器(Photoplethysmograph,PPG)、呼吸(Respiration, RSP)、肌电图(Electromyogram,EMG)、心电图(Electrocardiograph, ECG)和皮肤电反应(Galvanic Skin Response, GSR)等生理数据识别情绪,这类数据采集时无法伪装[4],能够获得真实客观的结果。英国Sander Koelstra团队提供了DEAP情感数据库,旨在通过机器学习的方法识别人类的情绪来改善生活[5]。上海交通大学吕宝粮教授所带领的团队提供的SEED数据集致力于安全驾驶的研究[6]。兰州大学胡斌教授所带领的团队提供的MODMA数据集致力于精神疾病和认知障碍的研究[7]。因此,利用多种生理信号进行情绪识别在研究和实际应用中具有重要意义。
1 情绪识别的理论基础
1.1 情绪理论模型
情绪划分是情绪识别首要解决的问题。目前心理学家倾向于以2种不同的方式来定义情绪:将情绪分为离散类别,使用多个维度标记情绪。
离散模型认为情绪空间是由离散、有限的基本情绪组成。Ekman[8]提出把情绪分为快乐、悲伤、惊讶、恐惧、愤怒和厌恶6种基本情绪,并将其他情绪视为这些基本情绪的反应和组合。Plutchik[9]提出了车轮模型,如图1(a)所示,包括欢乐、期待、惊奇、悲伤、厌恶、信任、恐惧和愤怒8种基本情绪,且复杂的情感可由基本情感混合而成。该车轮模型根据情绪强度来描述,其中越强烈的情绪越靠近中心位置,越弱的情绪越靠近边缘。
维度模型认为情绪可由二维或三维空间模型表达。最常见的维度理论是Russel绕线理论[10],他认为情感通过效价(Valence)和唤醒度(Arousal)在二维空间中分类,如图1(b)所示。效价反映了人对情况的判断,范围为不愉快(负)到愉快(正)。唤醒度表示人感受的兴奋程度,范围为平静(负)到兴奋(正)。Mehrabian[11]将情绪模型从二维扩展到三维,新增的维度为主导度(Dominance)。Dominance反映了人类在某种情感下的控制能力,范围为不可控(负)到可控(正)。

图1 维度模型
1.2 情绪诱发方法
情绪诱发是指通过不同的方法诱发出多种情绪。目前常用的情绪诱发方法有情景诱发和材料诱发。情景诱发是让受试者通过回忆或想象进行相应情境构建。该方法可以有效诱发情绪,但对诱发情绪的持续时间和强度难以把握。基于材料刺激的情绪诱发法即通过图片(视觉)、声音(听觉)或视频(视听觉)对受试者进行刺激以诱发其不同的情绪状态。该方法操作简便、易于控制,因此被广泛用于情绪研究。视觉刺激是最常用的诱发方法,通过给被试者呈现积极、消极和中性的图片,以及面部表情、文字等诱发被试者产生不同的情绪。经过标准化的材料库如国际情感图片库(International Affective Picture System, IAPS)[12]已在情绪识别领域中得到了广泛应用。听觉刺激诱发的效果更为深入持久,标准化的听觉刺激材料库包括国际情感数码声音库(International Affective Digitized Sounds, IADS)[13]等。目前,使用视听觉刺激结合的方式来诱发情绪的研究越来越多,但视听觉刺激使受试者产生多种情绪,特指性差。国内研究者罗跃嘉等人[14]建立了中国情感电影库。
2 DEAP数据库介绍
DEAP数据库是由英国Koelstra等基于音乐视频(Music Videos, MV)刺激诱发情绪并采集多模态的生理信号进行情绪识别的开源数据库。该数据库采集了32名被试者观看40首1 min的MV的脑电信号(EEG)和外周生理信号,实验流程如图2所示。

图2 实验流程
官网已提供经过预处理的数据,预处理操作包括将原始数据采样频率降至128 Hz、盲源分离法去除眼电伪迹、4~45 Hz的带通滤波器将脑电信号滤波等。表1所列为DEAP数据库内容概述。

表1 DEAP数据库内容概述
3 基于生理信号的情绪识别
本节主要介绍了利用生理信号进行情绪识别的方法,情绪识别框架如图3所示。训练方法:传统的机器学习方法需要先对数据提取特征再进行情绪分类;深度学习方法是一种端到端的训练方法。简单介绍3种模型的评估方法。

图3 情绪识别框架
3.1 预处理方法
由于原始生理信号的复杂性、对电磁干扰和运动产生噪声的敏感性[16],在进行情感识别的早期阶段必须通过预处理来消除噪声和伪迹带来的影响。一般情况下,对于明显的异常信号,可通过肉眼观察手动去除伪影。对于其他干扰信号,常用的预处理方法有滤波法(Filtering)、归一化法(Normalization)、主成分分析法(Principle Component Analysis, PCA)和独立成分分析法(Independent Component Analysis, ICA)等。目前研究者为了更好地去除伪迹,通常会采用2种或多种方法结合的方式对生理信号进行预处理。
滤波法能够有效滤除生理信号中掺杂的工频干扰和电磁干扰[17],方法简单,处理速度快,但对原始生理信号有较大的衰减作用。DEAP数据库中的EEG信号默认通过2 Hz的高通滤波进行滤波处理,然后使用Welch方法提取3~47 Hz的EEG信号。归一化法通常用来消除个体间的差异,减弱基线个体差异过大所产生的不利影响[18],最常用的方法是将数据统一映射到[0,1]区间。Lee等[19]在预处理PPG信号时,为消除PPG信号的个体差异,在删除基线值(介于0和1之间)后,对PPG信号的最大和最小值进行归一化处理。张强等[20]进行预处理时,对每个分段内RSP信号的局部平均值和标准差进行归一化处理,使得学习的特征仅对分段内的变化敏感,而对基线水平不敏感。独立成分分析(ICA)将多通道的观测信号分解成多个独立成分[21],通过选择保留或丢失成分的方法来消除伪迹。Kim等[22]提出了一种约束独立成分分析(constrained Independent Component Analysis, cICA)预处理算法,用于消除PPG信号的运行伪像。
3.2 传统机器学习方法
传统的机器学习包括特征提取和情绪分类2个流程,首先对原始数据进行特征提取,然后将提取的特征输入到分类器中进行情绪识别。
3.2.1 特征提取
从生理信号中提取与情绪相关、敏感和有效的特征分量,有利于后续更准确地识别不同情绪状态。常用的生理信号特征包括时域特征、频域特征和时频域特征。由于生理信号是非平稳非线性的时变信号,仅从时域或频域提取特征不够全面,因此采用时频域特征作为情感特征。提取的时频域特征常用方法有短时傅里叶变换(Short-Time Fourier Transform,STFT)、小波变换(Wavelet Transform, WT)和希尔伯特-黄变换(Hilbert-Huang Transform, HHT)等。
短时傅里叶变换(STFT)是最常见的时间-频率分析方法之一。它在傅里叶变换中加入了窗函数,某一时刻的信号特征由时间窗内ω(n-t)的一段信号表示:

式中:f(t)表示输入的生理信号序列;X(n,ω)为傅里叶变换后的结果。由于STSF时间窗的窗口是固定的,因此STFT无法同时在时域和频域上获得最高的分辨率,所以需要选择合适的时间窗长度。目前,DEAP数据库情绪识别研究中效果最好的时间窗长度多为1~2 s。吴诗怡等[23]使用快速傅里叶变换方法(Fast Fourier Transform, FFT)和WT方法提取脑电FP1和FP2通道的特征,如图4(a)所示。
小波变换(WT)是STFT方法的改进,其窗函数会随频率的改变而改变,可以同时在时域和频域获得良好的分辨率。假设φ(t)是一个平方可积函数,其傅里叶变换φ(ω)满足:

称φ(t)为基本小波函数,将φ(t)进行尺度或平移变换,得到小波变换函数WT(a,τ):

式中:a代表尺度,用来控制小波函数的伸缩;τ代表平移量,用来控制小波函数的平移。尺度a对应于频率,平移量τ对应于时间。但是WT算法在高频频率分辨率和低频时间分辨率上效果较差,会丢失信息细节。邓欣等[24]采用DEAP中预处理后的脑电数据,用WT将脑电信号分解为4层,从每层的细节分量(SRD)和近似分量(SRC)中提取delta波(0.5 ~3 Hz)、theta波(4~7 Hz)、alpha 波(8 ~13 Hz)、beta波(14~30 Hz)和 gamma波(31~47 Hz),图4(b)为其对应的4层小波频域分解树。

图4 特征提取方法
希尔伯特-黄变换(HHT)适用于处理非线性非平稳信号,它被分为2部分:第一部分为经验模式分解(Empirical Mode Decomposition, EMD),这是一个“筛选”过程,将非线性非平稳原始生理信号分解为几个本征模函数(Intrinsic Mode Functions, IMF);第二部分是希尔伯特谱分析,它将分解出来的各IMF进行希尔伯特变换,最终得到原始信号的Hilbert谱。
输入的原始生理信号可以表示为:

式中:f(t)表示输入的生理信号;IMFi(t)表示K个本征模函数;r(t)表示生理信号减去IMF后的余项。
希尔伯特变换表示为:

HHT的缺点是IMF的模态混叠频繁出现,导致IMF的稳定性差。庄宁等[25]用EMD方法分解出EEG信号的前5个IMF分量,发现IMF1的震荡变化最快,即用IMF1的3个特征作为情绪识别的特征。从多种生理信号中提取的原始特征通常具有很高的维数并且特征之间存在冗余特征,导致情绪识别精度降低。
3.2.2 分类方法
经过特征提取之后,利用分类方法进行情绪分类。在情绪识别中,适用于分类的方法有支持向量机(Support Vector Machine, SVM)、K-近邻算法(K-Nearest Neighbor,KNN)、决策树(Decision Tree, DT)、人工神经网络(Artificial Neural Networks, ANN)和随机森林(Random Forest, RF)等。
支持向量机(SVM)是一种二分类的线性分类器,在小样本训练集上能够得到比其他算法更好的结果。SVM的缺点是在训练大量样本和多分类问题上存在困难。刘伟等[26]提取了脑电图和眼信号的特征之后使用线性SVM(图5)进行情绪分类,平均识别率达到91.49%。Hassan等[27]将融合特征输入到高斯内核分类器(Fine Gaussian SVM, FGSVM)中进行情绪识别。Vijayakumar等[28]将提取的DEAP数据库中8个外周生理信号的统计特征输入到8个分类器中,对情绪进行二分类。结果证明,SVM分类器的准确率最高。

图5 线性SVM分类器
K-近邻算法(KNN)是一种基于权重的分类方法[35]。KNN基本思想:如果一个样本附近的k个最近样本的大多数属于某一个类别,则该样本也属于这个类别。KNN算法适用于处理多分类问题,也可以处理回归问题。缺点是当特征维度较高时计算量较大。Mert等[29]使用KNN和ANN对情绪进行二分类,平均识别率分别为59%和73.93%。
决策树(DT)是一种以树形结构表达的模型,能够基于已知数据构建具有多个分支的树状模型,实现数据的分类与预测。DT可以在时间相对较短的情况下对大量数据进行处理,效果良好。缺点是容易发生过拟合,并忽略数据间的相关性。Wu等[23]通过梯度提升决策树(Gradient Boosting DT,GBDT)对情绪进行分类,情绪平均识别率达75.18%。
3.3 深度学习方法
深度学习方法是一种端到端的学习方法,在输入端输入数据,从输出端得到预测结果。与传统的机器学习方法相比,该法无需在每一个独立学习任务之前对数据做复杂的处理和易错样本标注。常用的深度学习方法有自动编码器(Auto Encoder, AE)、卷积神经网络(Convolutional Neural Networks, CNN)、 深 度 信 念 网 络(Deep Belief Network, DBN)和递归神经网络(Recurrent Neural Network,RNN)等。
自动编码器(AE)神经网络是一种基于后向传播(Back Propagation, BP)的无监督算法,它包含1个输入层,1个或多个隐藏层和1个输出层,其中输入层的大小等于输出层的大小。AE包含编码器网络(Encoder Network, EN)和解码器网络(Decoder Network, DN),自动编码器结构如图6(a)所示。自编码器通过自学习方式将原始数据的高维特征用低维特征表示,一般用于高层特征非线性降维。AE的优点是训练时间较少,可以利用足够的无标签数据进行模型的预训练。但由于是全连接网络,AE需要较多的训练参数,因此容易出现过拟合现象。
刘伟等[26]提出了一种双峰深度自编码器 (Bimodal Deep AE, BDAE)特征提取方法,如图6(b)所示。该方法建立了EEG和EOG的受限玻尔兹曼机,然后将从BDAE中提取的共享特征发送到SVM中进行情绪识别。张强等[20]使用稀疏自编码器(Sparse AE, SAE)提取呼吸信号的特征,该SAE具有2层隐藏层:第一个隐藏层(200个神经元)处理呼吸信号,路径长度为640个样本;第二个隐藏层(50个神经元)处理第一个隐藏层中的200个神经元的输出,最后50个神经元(特征)形成SAE的输出,该SAE提供了许多提取的特征,作为逻辑回归的输入。Bagherzadeh等[30]提出了一种并行堆叠自动编码器(Parallel Stacked Ae, PSAE),将DEAP数据库中的EEG和8个外周生理信号的特征分成12个特征子集以并行方式输入多个堆叠式的自动编码器中,对愉悦度和唤醒度进行四分类,平均准确率达93.6%。

图6 自动编码器方法
卷积神经网络(CNN)是一种深层前馈人工神经网络。CNN包括卷积层和池化层。CNN的共享权值和高度不变性的网络结构降低了模型的复杂度和权值数量。缺点是深度模型容易出现梯度消散问题。Huang等人[31]提出了集成卷积神经网络模型(Ensemble Convolutional Neural Network,ECNN),用皮肤电(GSR)、呼吸(RSP)和眼电(EOG)信号对4种认知状态(放松,沮丧,兴奋,恐惧)进行分类。廖锦香等[32]提取EEG的110个统计特征并将其发送到CNN,二分类中Valence的准确度达到81.4%。Lee等[19]通过一维卷积神经网络(One-Dimensional Convolutional Neural Network, 1D-CNN)提取单脉冲的光体积描记图(Photoplethysmogram, PPG)的信号特征,实现了1.1 s短期情感识别。1D-CNN结构如图7所示。

图7 1D-CNN结构
深度信念网络(DBN)是一种深度神经网络的概率生成模型。它由多个受限玻尔兹曼机(Restricted Boltzmann Machine, RBM)和Sigmoid信念网络堆叠而成。DBN通过自顶向下的顺序逐层训练RBM网络,让神经网络按照最大概率生成训练样本。它不仅能生成数据,还能识别特征和分类数据。缺点是由于生成模型学习的是数据和标签间的联合分布,所以在某种程度上学习的复杂性更高。Hassan等人[27]将提取的EDA、PPG和zEMG融合特征输入到无监督的DBN中,生成深度级别的判别特征。对5种情绪(快乐、放松、厌恶、悲伤、中性)进行识别,其中快乐、厌恶、悲伤的识别准确率均超过90%。
递归神经网络(RNN)是一种树形结构的人工神经网络,通过对输入信息进行递归来连接网络节点。RNN叠加了以往的信息,用作当前网络的输出,解决了上述网络结构无法分析输入信息序列之间关联性的问题。缺点是需要的训练参数较多,训练困难,容易发生梯度消散或梯度爆炸。Liao等[36]提出了一种卷积递归神经网络模型(Convolutional Recurrent Neural Network, CRNN)用于情绪识别,该方法使用CNN学习多通道EEG信号的空间表示,使用LSTM方法学习外围生理信号(EOG,EMG,GSR,RSP,PPG和SKT)的时间表示。将2种表示形式结合后用于情绪分类,Arousal识别准确率为90.6%,Valence为91.15%。
3.4 模型评估
模型评估用来评估分类器的泛化能力,可以在一定程度上减少过拟合和欠拟合现象的出现,得到稳定、可靠的模型。基本思想是对原始数据分组,用大部分数据作为训练集进行训练,用小部分数据作为测试集进行评估。常用的模型评估方法有:留出法(Hold-Out)、K折交叉验证(K-Fold Crossing Validation, K-CV)和留一验证(Leave-One-Out Crossing Validation, LOO-CV)。
留出法是最简单也是最直接的验证方法,将样本数据随机分为训练集和测试集。一般情况下,选择数据集的2/3~4/5作为训练集,其余样本作为测试集。Hold-Out的缺点是在测试集上计算的分类准确率对原始数据的划分比较敏感。
K折交叉验证(K-CV)是Hold-Out的改进,它消除了Hold-Out的随机性,降低了对数据集划分的敏感性。K-CV将原始数据均分为K份,共交叉验证K次,每次选择其中1份作为测试集,另K-1份作为训练集。取K次的平均结果用作最终模型的结果。最常用的是10折交叉验证。
留一验证(LOO-CV)是使用原始样本中的一个作为测试集,其余样本保留为训练集。LOO-CV方法使用的测试集最接近原始样本的分布,评估的结果最可靠。缺点是当数据集较大时,计算成本较高,训练时间较长。
4 结 语
基于生理信号的情绪识别研究在脑-机接口、远程教育和精神疾病等方面有着广泛的应用。本文介绍了一些常用的情绪识别方法,重点分析比较了传统机器学习和深度学习方法。表2总结了近年来基于DEAP数据库中的生理信号进行情绪识别的相关研究文献。从被试人数来看,大部分研究使用了DEAP数据集的所有被试实验数据。在选取生理信号方面,有使用单一的生理信号,也有采用多生理信号融合的方式,总体而言,使用多生理信号融合方式的准确率更高。而识别模型的选取则依赖于所选取样本数据和分类任务,可以为一种或者多种分类器结合使用,综合来看,近年来使用深度学习方法愈加广泛,且识别精度也更高。
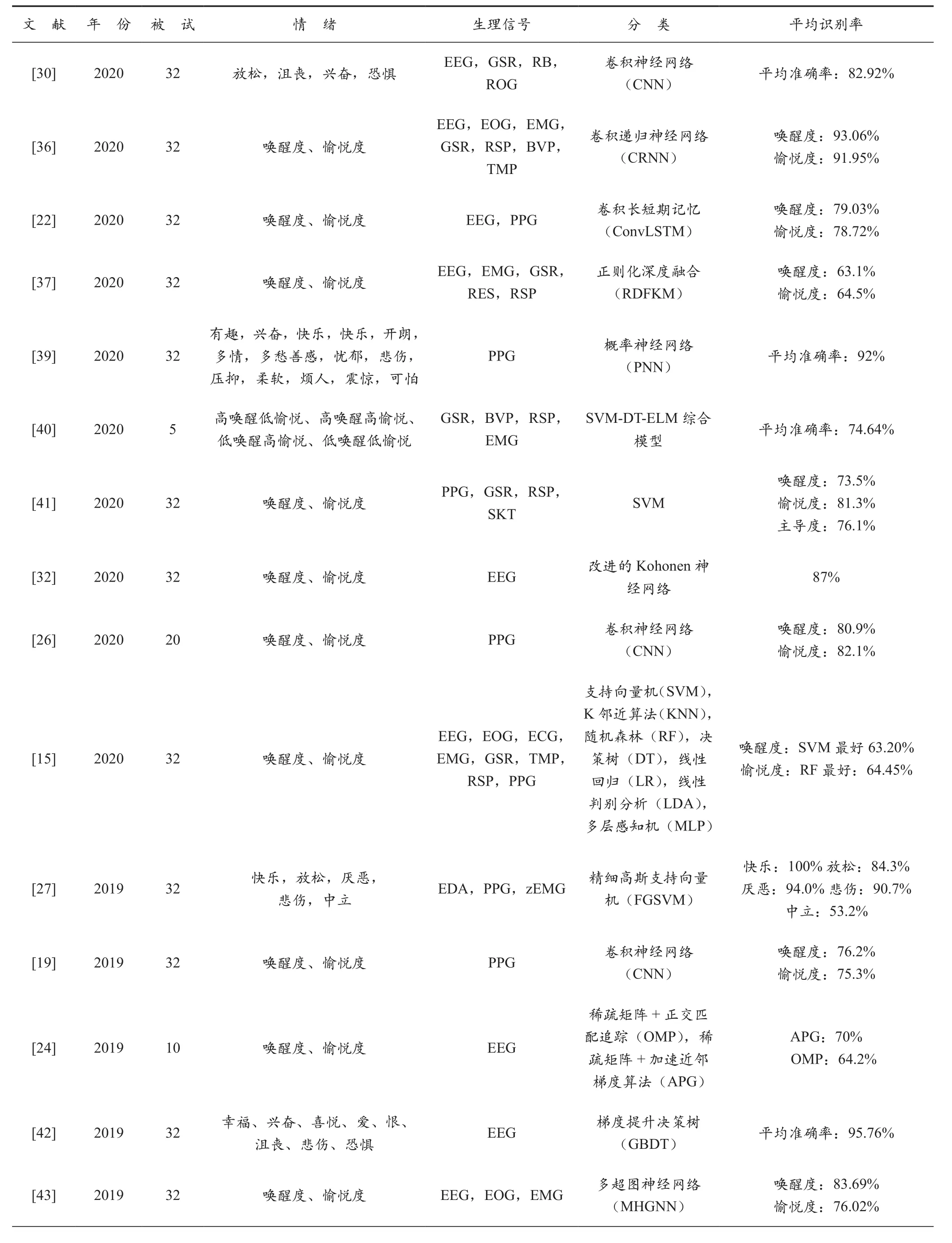
表2 基于DEAP数据库中的生理信号进行情绪识别相关研究文献

续表
由此看来,使用多种生理信号融合的方式和深度学习方法进行情绪识别将是情绪识别领域的发展趋势。如何进行多种生理信号的融合,既提高情绪的识别准确率,又解决数据维度和计算复杂度过高的问题将有待于进一步的研究。
