基于正样本的产品缺陷检测研究
2021-07-31齐宇霄
齐宇霄,王 正,谢 辉,唐 倩,童 莹
(南京工程学院 信息与通信工程学院,江苏 南京 211167)
0 引 言
表面缺陷检测对工业生产而言至关重要,缺陷检测通常是指对物品表面缺陷进行检测。传统缺陷检测通过人眼检查,费时费力,效率低下,检测精度难以达标。
近几年,随着机器视觉的兴起,表面缺陷检测随之发生变化,使用机器视觉系统代替人类视觉系统大大提高了检测效率和检测精度。传统图像特征提取算子处于较低水平,在很多情况下提取的特征无法处理,因此很多算法并不适用。最近,深度学习在图像特征提取方面展现出其优势,卷积神经网络对目标分类与定位、语义分割等精度较高。
Faghih-Roohi等[1]使用深度卷积神经网络在轨道表面执行缺陷检测。将轨道图像分为6类,包括1类非缺陷图像和5类缺陷图像,之后使用DCN对它们再次分类。LIU等提出了两阶段方法[2],该方法将选择性搜索和卷积神经网络相结合,检测并识别获得的区域,然后完成对胶囊表面缺陷的检测。Yu等[3]使用2个FCN语义分割网络检测缺陷[4],其中一个为粗略定位,另一个为精细定位,由此准确绘制缺陷的轮廓,该方法在DAGM 2007数据集[5]上比原始FCN具有更高的精度,并可以实时完成[6]。
工业检测应用在实际当中时,因训练样本中的缺陷较少,因此难以事先收集全面的缺陷样型。所以,在训练过程中正样本和负样本的数量极不平衡,生成的模型可能不稳定或无效。同时,手动贴标签价格昂贵,因此难以在实际缺陷检测过程中采用。由于缺陷种类不同,且检测标准和质量指标也不同,这就需要针对特定需求手动标记大量训练样本,因此人力需求较大。
针对该问题,本文设计了一种基于正样本的产品缺陷检测方法。首先,需要在已有正样本中构建简单的缺陷特征,形成自构建负样本。之后,将自构建负样本放入自动编码器,恢复缺陷特征,实现对自动编码器的训练。然后,将测试集中的真实负样本放入训练好的自动编码器进行缺陷修复,生成修复样本。最后,使用LBP算法将修复样本与真实缺陷样本的LBP特征图相减得到差值特征图,再将差值特征图二值化,得到缺陷区域坐标。该方法无需手动粘贴标签,无需大量负样本进行训练,缺陷检测精度高、效率高,对工业检测的实际应用有很大参考价值。
1 网络介绍及算法流程
1.1 算法流程
系统训练流程和测试流程分别如图1、图2所示。
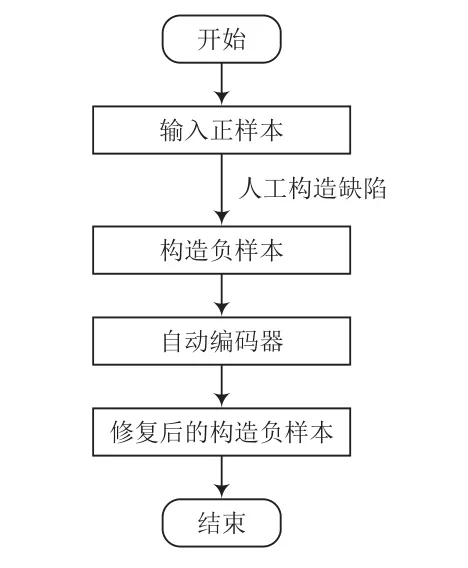
图1 训练流程
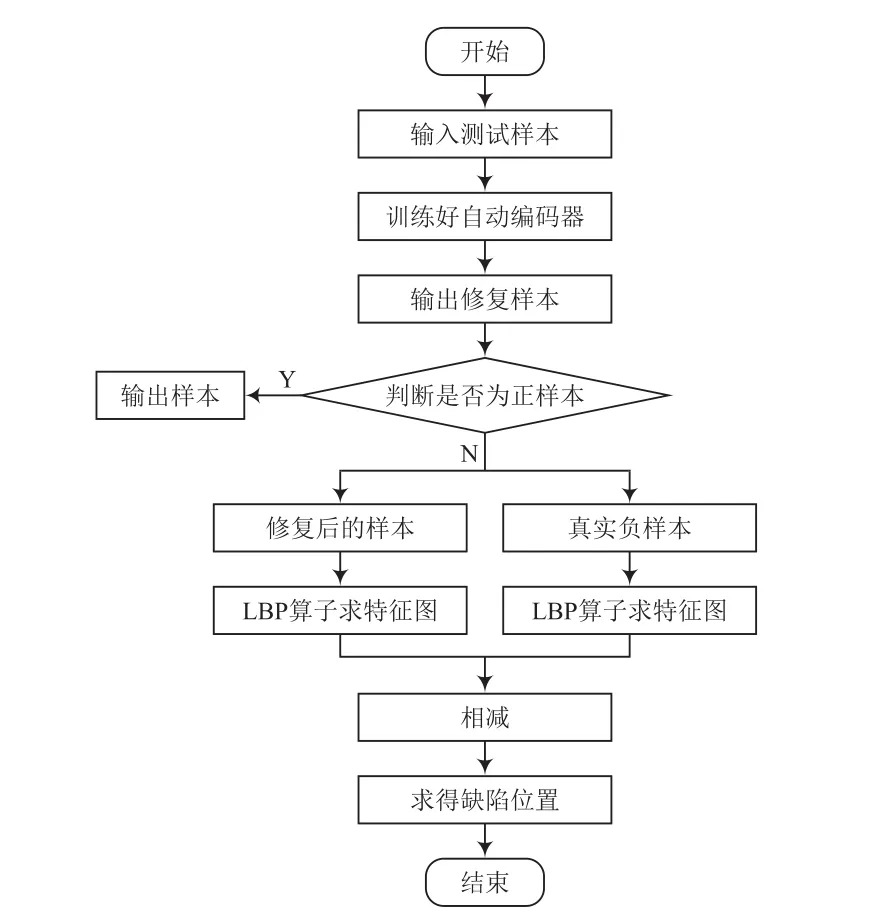
图2 测试流程
1.2 Autoencoder自动编码器
Autoencoder(简称AE)[7]是一种可以以无监督方式进行学习的人工神经网络。早期,自编码器被用于解决表征学习中的编码问题,其结构如图3所示。
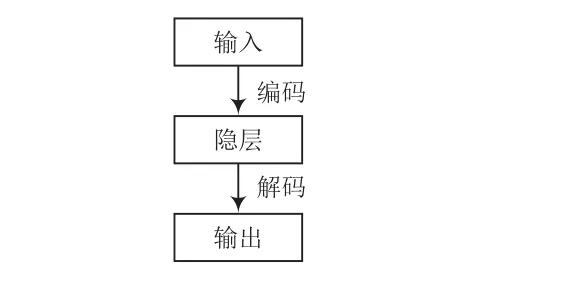
图3 自编码器结构
自编码器结构简单,训练时无需标签,输出数据与输入数据基本可保持一致,所以自编码器是一种无监督算法。重建输入的神经网络训练过程,其隐藏层向量具有降维作用。编码器会创建一个隐藏层(或多个隐藏层),包含有输入数据含义的低维向量。解码器通过隐藏层的低维向量重建输入数据,通过神经网络的训练,AE在隐藏层中得到一个代表输入数据的低维向量,帮助数据进行分类、可视化显示、存储。
为了能让网络更好地处理图像类的输入数据,我们用卷积层和反卷积层替换了自编码器中的全连接层,自编码器结构如图4所示。
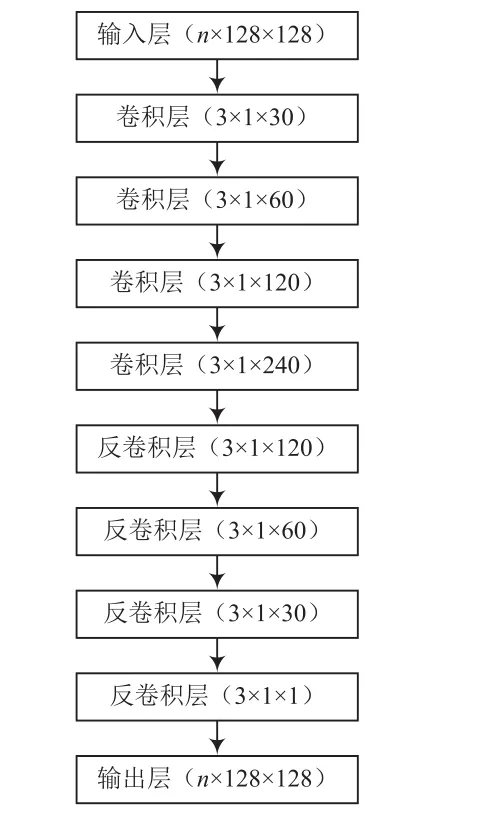
图4 自编码器结构
用卷积的思想替换全连接层,可以大大减少网络架构的参数,同时卷积可以更好地学习图像特征(具有平移不变性)。一般的卷积神经网络在卷积层之后接池化层,但这往往会遗漏很多图像信息,为改善这一现象,我们设置卷积核的步长为2。逐层卷积后,图像尺寸越来越小,所以在网络后部分使用反卷积方法,逐渐将特征图融合复原成原始尺寸,通过训练尽可能让输出接近原始图像。损失函数计算:
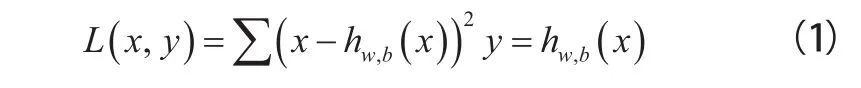
1.3 LBP算子
局部二值模式(Local Binary Pattern, LBP)是用于描述图像局部纹理特征的算子,具有旋转不变性和灰度不变性等优点。它首先由T. Ojala,M.Pietikainen于1994年[8]提出,用于纹理特征提取。
传统的LBP算子定义在3×3窗口内,以窗口中心像素为阈值,将相邻8个像素的灰度值与其进行比较,若周围像素值大于中心像素值,则该像素点的位置被标记为1,否则为0。这样,3×3邻域内的8个点经比较可产生相应的二进制数(通常转换为十进制数,即LBP码,共256种),之后得到该窗口中心像素点的LBP值,并用该值反映该区域的纹理信息。LBP计算如图5所示。
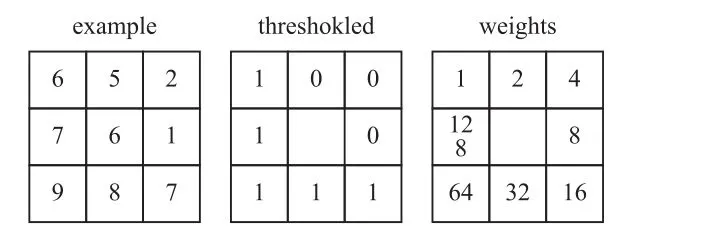
图5 LBP计算
提取LBP特征向量的步骤如下:
(1)首先将检测窗口划分为16×16的小区域(cell)。
(2)对于每个cell中的像素,将相邻8个像素的灰度值与其进行比较,得到该窗口中心像素点的LBP值。
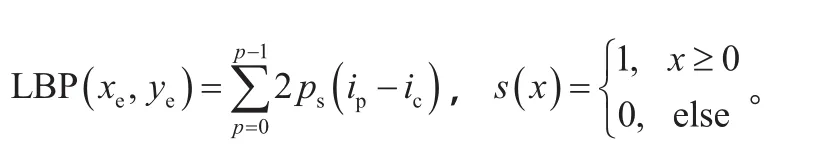
(4)将得到的每个cell的统计直方图连接成为一个特征向量,即整幅图的LBP纹理特征向量。
图6所示为本文模型使用LBP求缺陷位置的流程。
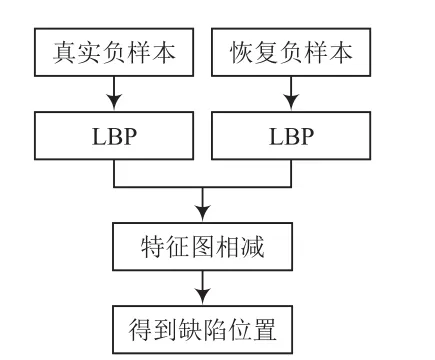
图6 利用LBP求缺陷位置的流程
2 训练策略
2.1 训练模块
在训练过程中,输入训练集中给定的正样本,在正样本上人工构建缺陷,形成缺陷样本。然后将缺陷样本放入自动编码器中训练其修复能力。本次实验使用“征图杯”人工智能大赛数据来测试实验模型的性能,数据集为平坦区下的缺陷数据集与非缺陷数据集。其中,训练集全为正样本,测试集既有负样本也有正样本。训练流程如图7所示,使用自构建负样本训练自动编码器的效果如图8所示。
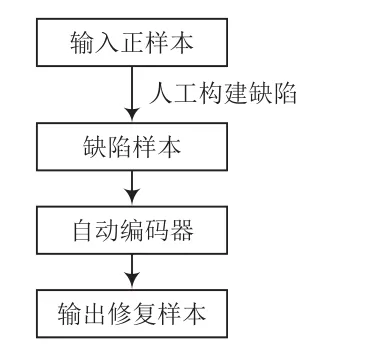
图7 训练流程

图8 使用自构建负样本训练自动编码器的效果
2.2 测试模块
测试过程中,将测试图片真实负样本输入自动编码器中,得到生成的修复样本(若判别为正样本则直接输出),由于还原的图片细节信息存在一些错误,因此不应直接将还原图片与原始图片进行分割。使用LBP算法进行特征提取,然后在每个像素周围搜索最匹配的像素。LBP算法是一种非参数算法,具有光不变性特征,适用于密集点环境。获取有缺陷图片的步骤:通过LBP算法对真实负样本和修复样本进行处理,设得到的特征图为x和y。对于x的每个像素点,在y的对应位置搜索最近的特征值点,该点作为匹配点的像素点。得到2个匹配点特征值之差的绝对值,获得的值越小,该点成为缺陷的可能性就越低。使用固定阈值二值化进行处理[9],找到缺陷的位置。测试流程如图9所示,测试效果如图10所示。
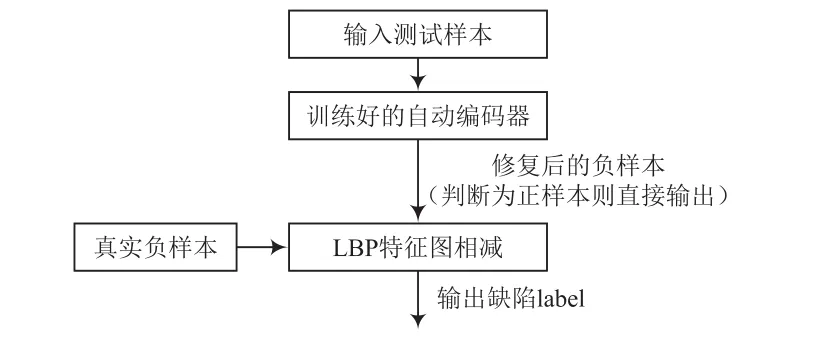
图9 测试流程

图10 测试效果
3 实验结果分析
本实验基于Keras深度学习框架,采用Python语言,选择首届“征图杯”校园机器视觉人工智能大赛的初赛A榜数据集[10],在只使用给定正样本数据集训练的情况下,检测出给定正样本与负样本混合的测试集缺陷样本。实验将同时使用本文提出的网络模型与传统的图像边缘检测(使用Sobel算子)加填充的方法对缺陷区域进行检测,对比模型的效果优劣。数据信息见表1所列。结果对比如图11所示。

表1 数据信息

图11 结果对比
从测试模块中得到的效果图像结果可以看出,我们的模型对于缺陷区域检测的检测精度较传统的检测方法更高。此外,分别计算2个模型测试得到的缺陷标签图与缺陷真实标签的交并比和漏检率与过检率之和,比较2种模型的优劣。标签对比结果如图12所示。测试结果比较见表2所列。

图12 标签对比结果
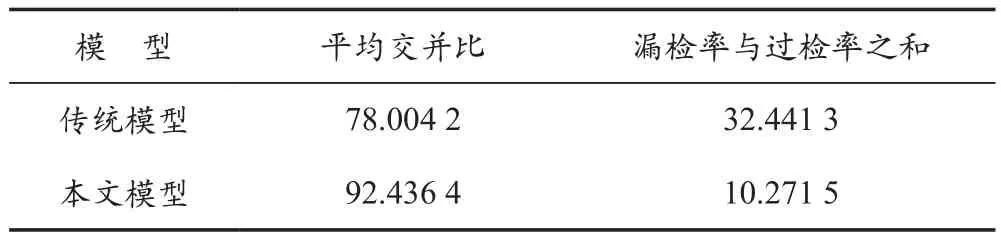
表2 测试结果比较 %
实验表明,在只有正样本作为训练集的情况下,我们的模型与传统方法相比,在缺陷区域检测精度上有很大优势。可以看出,对于传统的边缘检测加填充的方法,样本分类存在很多缺点,自动编码器与LBP结合的模型效果更好。
4 结 语
本文提出的基于正样本的产品缺陷检测方法对于只有正样本作为训练集且背景较平坦的缺陷检测有着不错的效果,该方法无需手动设置标签,无需大量负样本训练,在缺少负样本的情况下缺陷检测精度和效率更高。
