基于人工智能技术的图书馆信息检索模型
2021-07-30布艳艳
布艳艳
(西安科技大学高新学院图书馆,陕西西安 710109)
图书馆已趋于数字化,图书馆将众多高科技应用于信息资源中,实现信息资源的管理[1-3]。数字图书馆存在检索信息与用户所输入检索词相关度较低,无法满足用户需求的缺陷[4-5]。以往图书馆信息检索模型仅将关键词作为搜索的主要元素,未考虑文献间的关联,无法体现检索信息间的语义关系,导致查询结果具有较高的误检率以及漏检率。程煜华等人研究基于D-S 证据理论的信息检索模型[6-7],利用D-S 证据理论建立信息检索模型,存在检索信息相关性较差的缺陷;李莉研究基于多Agent 技术的数字图书馆个性化信息服务检索模型,可有效提升检索精度,但检索实时性较差[8-10]。
人工智能技术包含机器学习、自然语言处理与自动化、机器视觉、语义网、贝叶斯网络等,为了提高图书馆信息检索正确率,提出了基于人工智能技术的图书馆信息检索模型,为图书馆信息实时检索提供理论依据。
1 图书馆信息检索模型具体设计
1.1 图书馆信息检索模型
基于人工智能技术的语义网建立图书馆信息检索模型,如图1 所示。从图1 可以看出,所建立图书馆信息检索模型包括用户请求模块、信息检索处理模块以及资源库3 部分。用户输入关键词或语句等查询请求后发送至信息检索模块,资源库利用图书馆信息资源通过标准化以及规划化表达方式和工作步骤创建本体,信息检索处理模块选取贝叶斯网络作为推理机,通过语义逻辑推理、语义抽取以及语义查询处理用户所输入关键词或语句,获取逻辑表达式,从知识库中寻找理想结果,将检索结果排序后输出结果至用户界面。
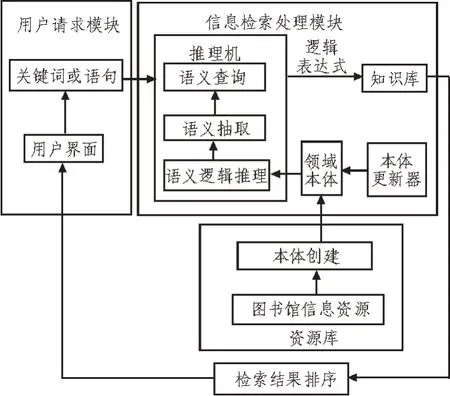
图1 图书馆信息检索模型
通过语义网处理海量图书馆信息资源,获取理想的信息检索结果。利用语义网的概念检索技术及资源标注技术与语义字典等工具结合,建立可体现图书馆信息资源领域知识的领域本体模型。建立领域本体模型过程中需充分利用领域专家的经验及知识来获取该领域内词汇,依据形式化模式获取不同词汇关系的具体定义,所获取领域本体可实现资源库内文档的标引[11-12]。利用本体更新器依据资源库内信息变化扩展领域本体,更新器可依据网络信息更新本体知识,并将不需要的知识进行实时删除以及修改。
1.2 本体创建
通过标准化以及规范化表达方式和工作步骤建立模型本体,依据待建立本体的层次、原则、用途、评价标准选取建立本体所需的描述语言和建立模式[13]。选取中国图书分类法构建图书馆信息检索模型知识本体,利用OWL 语言作为建立本体的描述语言,OWL 语言是语义互联网内的本体描述语言标准,利用斯坦福大学开发的本体开发工具Protégé软件建立本体,本体开发过程以及生命周期如图2 所示。利用领域专家辅助建立包括本体目的、范围、实现本体形式化程度的规格说明书,利用中国图书分类法获取不同信息间的关联知识,利用不同信息资源关联知识建立概念模型,通过识别领域词汇表呈现问题,并提出相应解决方案,实现模型本体创建。
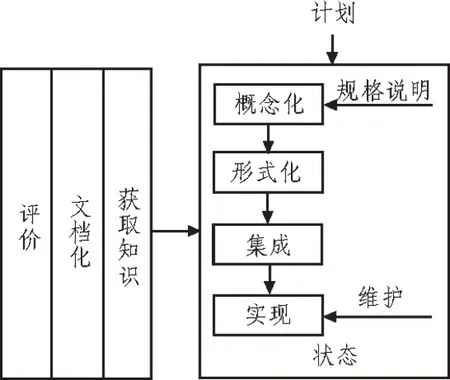
图2 本体开发以及生命周期
1.3 贝叶斯网络推理与检索
1.3.1 扩展贝叶斯网络
选取双术语层体现术语节点内的关联。设R与Ri分别表示原始术语层以及术语节点,将存在于原始术语层R内的全部术语节点Ri复制,所获取的术语节点用来建立新术语层,用R′表示。不同层次内术语节点间弧的指向用基于本体关联的术语节点间联系获取[14],其过程如下:

1.3.2 概率估计
设为随机存在的根术语节点,需明确与该根术语节点相关的边缘概率,设给定集合内全部术语节点的概率相同,可得根术语节点相关边缘概率为:

式中,M表示集合内术语节点总数。
根术语节点不相关概率公式如下:

贝叶斯网络内节点的父节点决定随机非根节点的概率,设Ri为集合内随机非根术语节点,pa(Ri)内各术语变量相关与不相关取值组合也用pa(Ri)表示,以此得到一般正则模型概率函数,计算公式如下:

其中,vij表示术语影响术语Ri的权重。
当术语Ri存在众多父节点时,可得权重vij为:
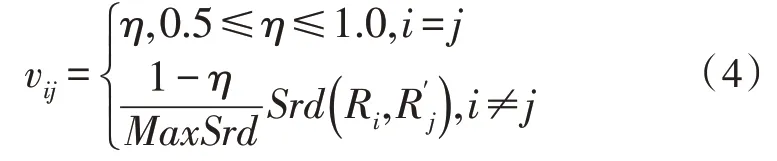
其中,η与Srd分别表示调节参数以及术语节点集合内术语本体关联度之和。
术语本体关联度之和的最大值为:
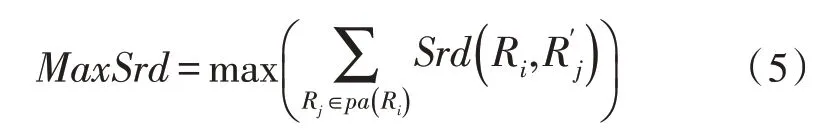
术语相关词对术语影响之和小于术语对自身的影响[15-16],当i=j,0.5 ≤η≤1.0 时,表现明显。
设Bj表示集合内存在的文档,得其条件概率为:
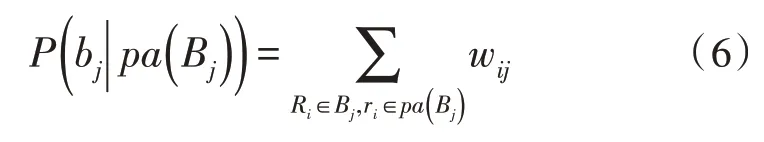
其中,pa(Bj)与wij分别表示pa(Bj)内各术语变量相关以及不相关取值的组合以及文档Bj的索引术语Rj的权重。以上公式需满足wij≥0(∀i,j),。当ri∈pa(Bj)时,表示pa(Bj)内相关术语权重之和。
Bj的相关概率值在pa(Bj)内相关术语越多时越高。选取TF-IDF 算法计算wij,如式(7)所示:
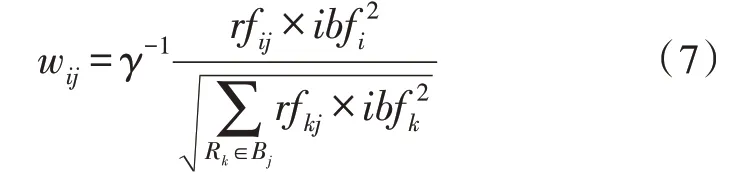
其中,γ为时的规格化常数,且满足∀Bj∈B,rfij与ibfi分别表示术语频度以及倒排文档频度。
1.3.3 推理与检索
设Q为用户查询以及提交的信息,相关度P(Bj|Q)表示查询Q时获取文档Bj的条件概率,获取相关度步骤如下:
1)属于Q术语的边缘概率在用户提交查询信息Q时,被实例化。当∈Q以及∉Q时,分别获取结果为。
2)依据以下公式获取随机术语Ri在术语层R内的后验概率:
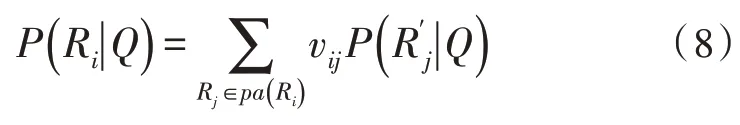
3)通过以下公式计算查询信息Q与文档Bj间相关度P(Bj|Q),即文档Bj最终后验概率:

所获取与查询信息Q相关度最高的文档Bj即为与用户所查询信息最相关文档,即用户所需文档,通过以上过程实现图书馆信息检索。
2 模型性能的测试
2.1 测试样本
选取Cornell 大学的SMART 11.0 系统测试文中所建立模型检索信息的有效性,该系统是利用向量空间模型建立的信息检索仿真系统,通过该系统可评价不同模型索引以及检索功能,是研究信息检索功能的实用平台。选取常用于信息检索测试的citeseer 图书馆科学标准数据集作为实验样本,该样本包含2 564 篇文档、6 854 个术语索引项、10 854 个词以及56 个查询。数据集内包含数据挖掘、人工智能、科学计算、地理等众多领域内容,选取大数据分析、模式识别、支持向量机、图像特征、神经网络、电磁波衰减作为测试词语。
2.2 测试指标
测试图书馆信息检索模型检索性能的指标众多,选取检索相关度、检索精度、查全率、查准率、查全率/查准率曲线作为模型检索性能测试指标。用Q与R分别表示用户查询信息以及相关文档集,|R|与A分别表示集合内文档数量以及检索后返回的文档集合,|A|与|Ra|分别表示文档集合的总数量以及文档集合R与文档集合A内存在相同文档的数量,可得查全率B以及查准率C,公式如下:

查准率/查全率曲线是指查全率以及查准率分别为横轴以及纵轴时所获取的曲线。检索精度是指实际检索相关文档数与全部检索获取文档总数之比。
2.3 测试结果
输入测试词语时,统计所获取检索结果与测试词语相关度,并将该文模型与D-S 证据理论模型(参考文献[6])以及多Agent 模型(参考文献[7])对比,统计结果如图3 所示。通过图3 测试结果可以看出,采用该文模型检索信息所获取文档的相关度明显高于采用D-S 证据理论模型以及多Agent 模型检索信息所获取文档的相关度,有效说明采用该文模型检索所获取结果与测试词语相关度较高,具有较高的检索性能。

图3 检索相关度对比
统计不同模型检索测试词语的检索精度,对比结果如图4 所示。通过图4 测试结果可以看出,采用文中模型检索测试词语的检索精度明显高于采用D-S 证据理论模型以及多Agent 模型检索精度,文中模型的检索精度高达99%以上,有效验证了文中模型具有较高的检索精度。

图4 检索精度对比
统计不同模型检索测试词语的查全率,对比结果如图5 所示。由图5 测试结果可以看出,输入不同测试词语后该文模型检索的查全率明显高于D-S 证据理论模型以及多Agent 模型,验证了该文模型具有较高的查全性能。

图5 不同模型查全率对比
统计不同模型检索测试词语的查准率,对比结果如图6 所示。由图6 测试结果可以看出,采用该文模型检索测试词语获取的查准率明显高于D-S证据理论模型以及多Agent 模型,有效说明了采用该文模型检索测试词语的准确性高于另两种模型。

图6 不同模型查准率对比
依据以上测试结果绘制不同模型的查全率/查准率曲线图,如图7 所示。由图7 测试结果可以看出,当查全率为10%以及20%时,3 种模型查准率相差较小,主要原因是查全率较低时,3 种模型可检索文档数量较少,所检索文档相关度较高,因此查准率相差不大。随着查全率不断提升,该文模型的查全率明显高于另两种模型,所检索文档数量也高于另两种模型,因此具有较高的查准率。
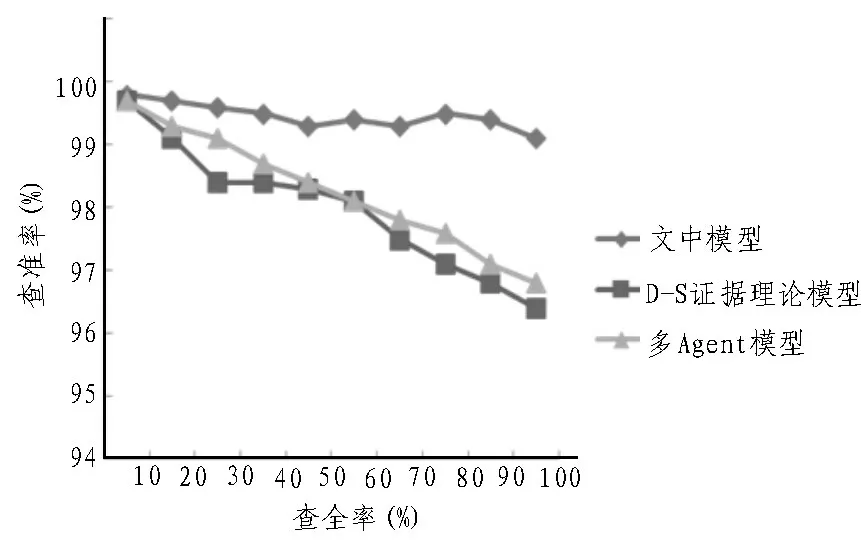
图7 查全率/查准率曲线
查全率、查准率以及检索精度是检测信息检索性能的重要指标,从以上测试结果可以看出,该文模型不仅具有较高的检索精度,且检索不同测试词语所获取的查全率以及查准率均明显高于另两种模型,有效验证了该文模型具有优越的检索性能。
3 结束语
大数据背景下图书馆信息检索需求有所提升,将人工智能技术应用于图书馆信息检索中具有较高的应用性。人工智能技术可符合用户信息采集需求,提升图书馆信息检索效率,推动数字化图书馆的不断进步及稳定发展。图书馆作为用户提供信息服务的载体,需充分考虑用户需求,知识化以及智能化集成数字信息资源和服务是数字化图书馆的重要发展方向。文中所采用的语义网技术可通过语义层次实现用户的信息检索需求,为数字图书馆智能化发展提供理论基础。
