基于前景语义信息的图像着色算法
2021-07-30吴丽丹薛雨阳高钦泉
吴丽丹,薛雨阳,童 同,4*,杜 民,高钦泉,4
(1.福州大学物理与信息工程学院,福州 350108;2.福建省医疗器械与医药技术重点实验室(福州大学),福州 350108;3.筑波大学计算机科学学院,筑波3058577,日本;4.福建帝视信息科技有限公司,福州 350001)
0 引言
灰度图像着色技术是指通过一种指定的规则,对灰度图赋以颜色,还原、增强或改变图像的色彩信息[1],该技术在动漫制作领域、老照片修复、艺术创作等方面有着广泛的应用前景。目前图像着色算法基本分为三类:
第一类是带有用户提示的辅助着色方法。在图像着色算法早期,由于数据和算力的不足,使用人类辅助着色方法才能取得较好的着色效果。Levin 等[2]提出了基于颜色涂抹的方法,利用用户在局部区域涂抹的颜色,通过凸优化方法,实现对灰度图像进行着色,但实际上该模型并没有学习到特定类别的颜色信息;Heu 等[3]提出了基于优先级的色彩转移方法,用户在图像的一组源像素上涂抹颜色,通过优先级识别算法,把颜色转移到邻近像素上,得到了更可靠的着色性能。
第二类是基于参考的着色方法。Welsh 等[4]最早提出了基于彩色参考图像的灰度图着色方法。该模型获取灰度图像和参考图像之间的色彩映射信息,引导灰度图的着色效果向参考图靠近;Chang 等[5]提出基于色彩调色盘的颜色重建方法,包括从彩色图像创建调色盘的算法,以及一个新的色彩传输算法;Chen等[6]提出基于语言参考的图像着色方法,给定灰度图和自然语言描述即可生成目标图像。
第三类是全自动图像着色方法。深度学习算法的发展、高性能图像处理器的出现以及大规模数据集的建成和开源为图像着色方法开辟了新方向。该类方法使用卷积神经网络搭建不同的网络架构,通过激活函数得到非线性模型,提高模型学习能力,输入大量数据训练,让模型学习灰度图与彩色图之间的颜色映射。Cheng等[7]提出的自动着色技术,通过使用超大规模的数据集,结合基于联合双边滤波的后处理方法和自适应图像聚类技术来整合图像全局信息,得到了优于最新算法的着色效果;Zhang 等[8]使用VGG 神经网络将着色任务转化为分类任务,解决了着色中的颜色不确定性问题,为着色算法研究提供了一个新思路;Zhao 等[9]为了增强图像的语义理解,提出利用由像素构成的对象来指导图像着色,网络包括像素化语义嵌入部分和像素化语义生成器部分,分别学习对象是什么和对象对应的颜色;张娜等[10]提出基于密集神经网络的灰度图形着色算法,利用密集神经网络信息提取的高效性,构建了一个端到端的自动着色模型,能有效改善着色过程中漏色和对比度低等问题。
综上所述,为了充分强调图像前景的颜色信息、提高图像着色的整体质量,本文搭建的网络包括两个网络,分别为前景子网和全景子网。前景子网为全景子网提供多个前景目标的特征信息,两个网络采用生成对抗网络(Generative Adversarial Network,GAN)。实验结果表明,本文算法与传统算法相比,能明显改善前景部分着色效果。
1 相关研究
1.1 实例分割算法
实例分割算法的任务是机器自动从图像中用目标检测方法框出不同实例,再用语义分割方法在不同实例区域内进行逐像素标记。Mask R-CNN[11]在实例分割任务上取得了非常好的效果。首先,其模型架构中的backbone 使用了一系列的卷积用于提取图像的feature maps,根据网络越深得到的效果会更加好的观点,选用ResNet101[12]可以构建更深的网络,同时根据深度残差网络特性,不会使网络退化;其次是特征金字塔网络(Feature Pyramid Network,FPN)的提出,融合了底层到高层的feature maps,在提取出较强语义信息的同时,还保留了位置信息和分辨率信息;接下来是区域推荐网络(Region Proposal Network,RPN),用于帮助网络推荐感兴趣的区域;最后作者提出了ROI Align,是一种区域特征聚集方式,很好地解决了ROI Pooling操作中两次量化造成的区域不匹配问题。
由于Mask R-CNN良好的检测特性,本文将训练数据输入到Mask R-CNN 中,得到图像中每个对象bounding box 的坐标,根据坐标裁剪出所需区域,作为前景子网的训练数据。
1.2 IResNet
Duta 等[13]提出的IResNet(Improved Residual Network)是残差网络ResNet 的改进版,网络结构模块如图1,该方法通过以下三点改进措施得到了更高的准确性和更好的持续学习收敛性:1)改进信息流。作者提出了一种分段的组织结构,根据stage 不同的位置,安排每个ResBlock 都有不同的设计。2)改进快捷连接上的特征映射。在特征空间映射上使用最大池化操作,选择激活度最高的元素,减少信息的损失,在特征通道映射上使用1×1的卷积层和批归一化层,能减少空间背景信息丢失;3)分组构建块。主要表现为增加3×3卷积层的参数量,使得3×3卷积层有更多的通道和更高的空间模式学习能力。

图1 IResBlock的结构Fig.1 Structure of IResBlock
1.3 生成对抗网络
GAN[14]的基本思想源自博弈论的二人零和博弈,包括预测数据分布的生成器,以及估计样本来自训练数据的概率的判别器,通过对抗学习的方式来训练。GAN 作为一个优秀的生成模型,在图像风格转换、超分辨率、图像着色、图像生成等任务上广泛使用。
原始GAN 存在训练不稳定、梯度消失或爆炸问题,并且没有指导训练进程的指标。Arjovsky 等[15]提出的WGAN(Wasserstein Generative Adversarial Network)将GAN 中等价优化两个分布距离的衡量方法由JS 散度改为Wasserstein 距离,实现稳定训练和损失函数的变化可作为训练进程指标,表现为损失函数数值越小,表示真实分布与生成分布的Wasserstein 距离越小,GAN 训练得越好。使用Wasserstein 距离通常需要在模型中加入Lipschitz 约束,WGAN 通过权重裁剪,将判别器参数的绝对值限制在某个固定范围内;WGANGP[16]通过梯度惩罚,将判别器的梯度作为一个惩罚项,加入到判别器的损失函数中。但Wu 等[17]提出的WGAN-div 引入了Wasserstein 散度,如式(1)所示,使得模型去掉Lipschitz 约束的同时还能保留Wasserstein距离的优秀性质。
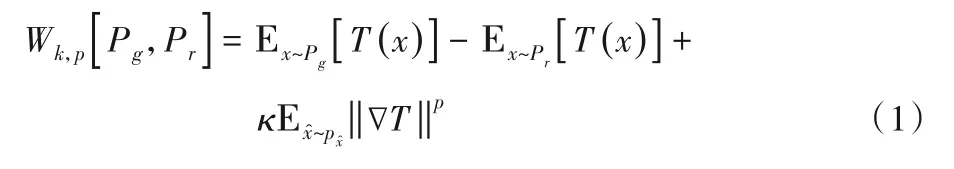
2 本文算法
本文算法使用两阶段网络训练方式,两个网络分别为前景子网和全景子网,利用前景子网提取图像中多个前景的特征,减少背景信息干扰,并且采用IResBlock 的网络构建方式,使输出彩色图像的细节特征更为丰富、目标轮廓更为清晰,实现了更好的着色效果。本文算法采用接近人类视觉且色域广的Lab色彩空间。
2.1 设计网络结构
2.1.1 总体网络结构
目前,在基于深度学习的灰度图像着色研究中,着色网络主要通过卷积神经网络的组合来提取图像特征、学习颜色映射。单一的神经网络特征处理能力有限、学习能力有限,着色效果有待提高。本文算法采用两个阶段网络训练的方式,充分利用低级特征信息和高级特征信息,有效提高了网络的性能;由于IResNet 具有良好的特征提取特性和减少信息损失的能力,所以本文前景子网和全景子网的生成器部分借鉴IResNet构建网络方式,构建卷积块内容;GAN在图像生成相关领域有其得天独厚的优点,本文采用WGAN-div 的训练策略,在实现稳定训练、损失函数的变化可作为训练进程指标的同时,提升了训练效果,加快了模型收敛。综上所述,将借鉴与改进的措施应用到本文的研究中,得到总体网络架构如图2所示。

图2 本文算法的网络结构Fig.2 Network structure of the proposed algorithm
两个网络结构都为U-Net[18]结构。在生成器网络的下采样部分,采用IResNet 中搭建卷积块的方式代替普通卷积层,卷积块参数如图1 所示。在第一个训练阶段,将前景子网中第4 个卷积块和第8 个卷积块的输出特征经过池化层与全连接层整合为1×512的特征向量,具体过程如图3所示。图3左边展示了一张前景图像的特征处理过程,在实际训练中,选用了n个不同的前景图像,得到n个1×512 的向量,在第二阶段的训练中,将它们作为辅助信息与全景子网中第4 个卷积块和第8 个卷积块的输出特征融合,所以最终融合后的特征维度有512 ×(n+1)维。根据训练前景子网时选择前景部分个数的不同,特征融合后的通道数也不同;在生成器网络的上采样部分,使用4×4 的转置卷积进行上采样,通过skipconnection把浅层特征引过来复用,增加空间域信息。
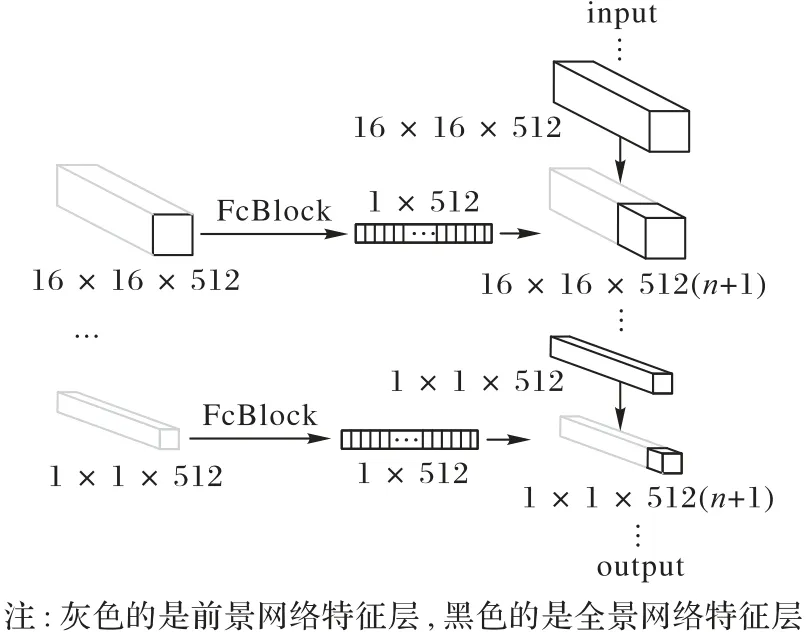
图3 特征融合的具体过程Fig.3 Specific process of feature fusion
2.1.2 判别器
使用马尔可夫属性的判别器,将重构的图像切割为多个patch,不同的patch之间相互独立,判别器对每个patch做真假判别,将多个patch 的判别结果取平均值,作为最终判别器的输出。WGAN 中的判别器近似拟合Wasserstein 距离,属于回归任务,需要将判别器最后一层的sigmoid 层去掉。判别器网络参数如表1所示。
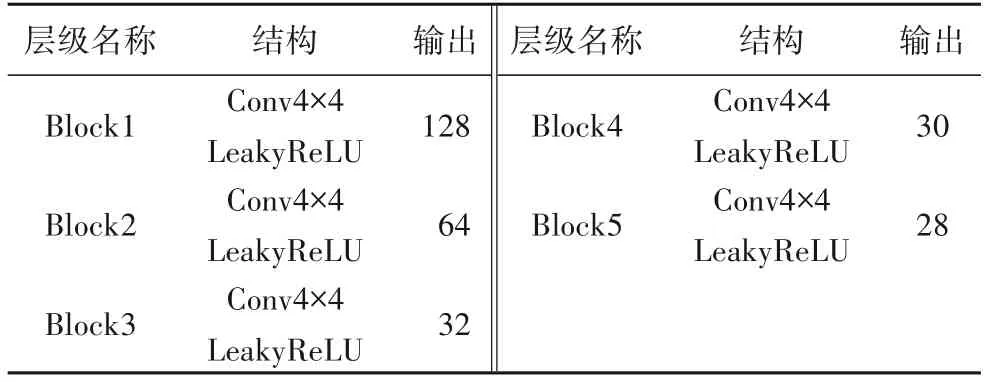
表1 判别器网络参数Tab.1 Discriminator network parameters
2.2 构造目标函数
深度学习算法的训练过程可以转化为对某个目标求解最优解问题。为了完成着色这一目标,构造目标函数如式(2)所示,通过不断优化目标函数来提升两个分布之间的相似程度。

其中:Lcolor表示算法的颜色损失,采用基于拉普拉斯先验的回归损失函数L1 Loss,能较好地恢复图像中的低频部分,得到清晰且颜色接近的图像;LG为生成损失函数,LD为判别损失函数,模型训练的目的是最小化生成损失函数和判别损失函数,如式(3)~(5)所示。
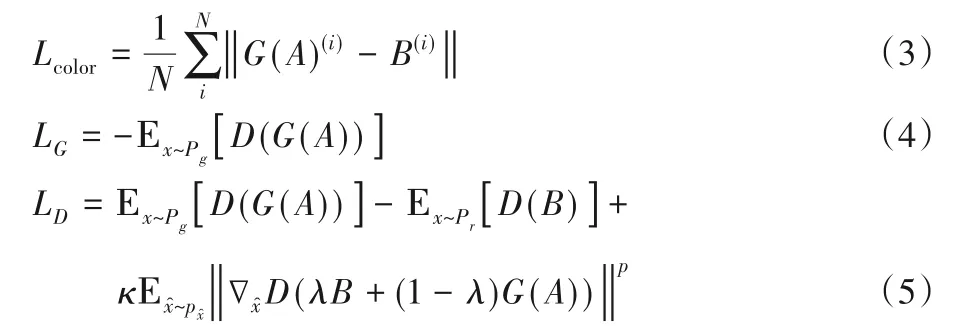
其中:A是输入灰度图像,B是真实彩色标签,N为样本数,G表示生成器网络,D表示判别器网络;G(A)为灰度图像经过生成器后的生成结果,Lcolor是输入G(A)(i)和目标B(i)的逐像素间差值的平均绝对值,D(G(A))表示生成的彩色图像输入到判别器的结果,D(B)表示真实彩色图像输入到判别器的结果。其中,参照文献[16]的实验结论,本文将式(5)中参数κ取2、p取6时,Wasserstein散度收敛最快,生成结果表现最优。
2.3 训练过程
第一阶段先训练前景子网,将训练数据输入到预训练的Mask R-CNN 网络中,每张图像得到n个前景部分的裁剪坐标,按照坐标裁剪可得到多张前景图像,作为前景子网的训练数据输入到网络中训练,保存训练好的网络,返回低级特征和高级特征。第二阶段训练全景子网,将256×256 大小的原图和第一阶段网络模型返回的特征输入到全景子网中进行训练,两个网络使用Adam 优化算法在训练过程中不断优化目标函数,更新网络参数。实验迭代次数为252 000,学习率设置为1× 10-4。
3 实验结果与分析
3.1 实验数据与环境
本文算法实现基于微软的COCO 数据集[19]和PASCAL VOC 数据集[20]。实验分别从COCO 和VOC 中选取18 000 和14 000 张图像用于训练,4 500 和3 000 张图像用于测试,所有数据预先裁剪为256×256大小。
本实验的硬件环境:Intel Core i7-7700 CPU 3.60 GHz,主机内存16 GB,显卡型号为GTX 1080,软件环境为Ubuntu16.04,CUDA 10.0,算法使用Python3.6 进行编程,采用Pytorch深度学习框架实现。
3.2 评价指标
本实验通过评价指标对着色效果进行客观评价。采用峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)和感知相似度(Learned Perceptual Image Patch Similarity,LPIPS)[21]。PSNR是评价图像质量时最普遍和使用最为广泛的图像客观评价指标,计算过程如式(6)所示,其中MSE为均方误差(Mean Squared Error),在本文实验中分别计算RGB 三个通道的均方误差,然后取平均值,最后将得到的平均值代入式(6)中计算。根据近几年的研究[22-23]可知,PSNR 本身存在很大的局限性,不能很好地反映人眼主观感受。LPIPS 是一项基于学习的感知相似度度量,比传统的目前广泛应用的方法更符合人类感知,分值越小即认为相似度越高。

其中:l是网络的层数;h和w是特征层的两个不同维度;从第l层提取特征并在通道维度中进行单元标准化得到通过矢量wl缩放激活通道维度并计算L2 范数;Hl和Wl分别是第l层特征的高和宽。
3.3 实验结果
3.3.1 与其他算法对比
为验证本文算法的有效性及优异性,选取部分代表性的图像与现有开源且表现优异的算法进行比较,包括Isola 等[24]的pix2pix 和Yoo 等[25]的MemoPainter(memo)。为了公正地对比各个算法的效果,所有实验均统一在相同的软件环境和硬件环境下进行,所有算法在COCO 数据集上训练14 个epoch,在PASCAL数据集上训练15个epoch,结果如图4所示。

图4 不同算法的着色效果对比Fig.4 Comparison of colorization effects of different algorithms
首先,在主观上比较各个算法的整体着色质量,如图4 所示,pix2pix只学到部分颜色信息,图像质量低,memo和本文算法在整体上着色效果表现较好;其次,比较彩色图像中不同层次物体的色彩对比度,可以看出memo的实验结果图像的颜色会趋向于一个色调,比如图像4会趋向于蓝色,图像5和图像6会趋向于棕色,pix2pix 和本文算法在色彩对比度上表现得较好;最后,比较各个算法与原图的接近程度,在图像1中的旗帜和人脸效果上,本文算法的结果更接近真实情况,色彩更鲜艳,在图像3 中本文算法更为真实地呈现了猫和格子沙发的颜色和纹理,总体比较下来,本文算法的实验结果最接近原图。在客观指标评价对比中,对整个测试集进行计算,PSNR表现为数值越大结果越好,LPIPS 表现为数值越小结果越好,本文算法在PSNR上比pix2pix和memo分别高出2.59 dB和7.54 dB,在LPIPS上分别降低了0.01和0.13,具体如表2所示。
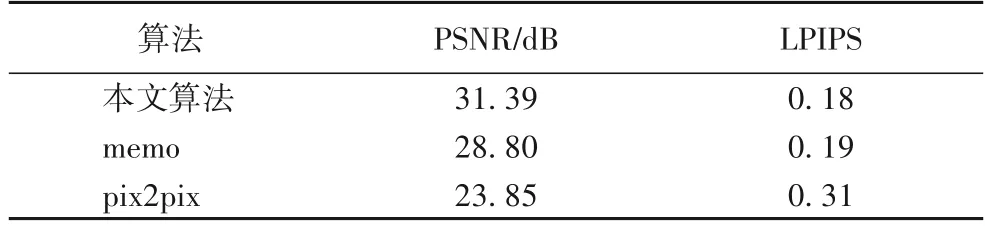
表2 不同算法的PSNR及LPIPS对比Tab.2 Comparison of PSNR and LPIPS among different algorithms
3.3.2 有无前景子网对比
本文算法结构包括前景子网和全景子网,为了验证引入前景子网训练的有效性,对比了有、无前景子网结构下的着色效果。选择7 张不同类型的图像进行对比,结果如图5 所示,在主观上明显可以看出,引入前景子网后,图像中前景部分着色更真实,颜色饱和度更高,呈现出了鲜艳且有层次的着色结果;在PSNR 和LPIPS 指标上,两个数据集的结果如表3 所示,可以看出引入前景子网后,本文算法在两项评价指标上取得了更好的分数。综上可知,引入前景子网训练有效地提升了着色效果。

图5 有无前景子网的着色效果对比Fig.5 Comparison of colorization effects with or without foreground subnetwork

表3 有无前景子网下的PSNR与LPIPS对比Tab.3 Comparison of PSNR and LPIPS with or without foreground subnetwork
3.3.3 有无IResBlock对比
在本文算法生成器的下采样过程中,使用普通卷积层,着色整体色调偏暖,着色效果还可以,但整个测试集中部分图像会出现效果不好的青色小色块;使用IResBlock 代替普通卷积层后,原图信息丢失减少,增强了通道上和空间上的学习能力,发挥其在深层网络中也能持续学习收敛性的特性,有效地消减了色块的出现。具体如图6所示。

图6 有无IResBlock的着色效果对比Fig.6 Comparison of colorization effects with or without IResBlock
4 结语
本文提出一种基于前景语义信息的灰度图像着色算法,该算法通过前景子网提取图像前景部分的低级特征和高级特征,再将这些特征与全景子网提取的特征信息相融合,实现像素级的颜色预测与彩色结果的输出。通过实验证明,本文算法与现有优秀算法相比,在较少的训练迭代次数下,可得到整体着色效果优异,颜色更鲜艳、更自然的彩色图像。下一步的工作将深入研究,将它运用到其他类型图像,比如动漫线稿类型,进一步强化算法的实用性和普适性。
