用户互动表示下的影响力最大化算法
2021-07-30李维华
张 萌,李维华
(云南大学信息学院,昆明 650504)
0 引言
随着网络技术的不断发展,越来越多的人们在获得即时信息的同时也因互联网成为了信息传播的主体,一些学者利用Instagram、微博、Facebook 和Twitter等社交平台用户间信息扩散的优势,挖掘社交网络用户潜在的商业价值。影响力最大化问题作为数据分析下的新兴领域,利用“口碑效应”在病毒营销、广告发布和政府监管等方面有着良好的应用前景。例如,品牌方有一批新产品待推广,他们首先要在社交网络中选择最佳的用户群体进行产品投放,通过这些种子用户的宣传,让尽可能多的人们购买和使用该产品,这就是影响力最大化在商业推广中的巧妙应用。研究影响力最大化对人们了解真实的网络信息具有非常重要的意义。
影响力最大化问题最早由Domingos等[1]定义为在网络中寻找t个节点,这些节点利用自身影响力使得信息最终的传播范围最广。随后,Kempe 等[2]证明了影响力最大化问题是一个NP 难(Non-deterministic Polynomial hard)问题,并提出了两种经典的扩散模型——线性阈值(Linear Threshold,LT)模型和独立级联(Independent Cascade,IC)模型,并在此基础上结合蒙特卡洛模拟提出了贪婪算法求解影响力最大化问题。后来的研究者们运用不同的方法对影响力最大化算法进行了改进,也得到了不错的研究结果;但这些方法在计算节点间影响概率时都是依赖于人工处理好的简化网络和理想状态下的公式计算,没能真正地通过节点间的互动得出影响概率。
近年来,网络表示学习(Network Representation Learning,NRL)作为学术热点在社交网络用户行为研究中得到了广泛的运用。其思想是利用一种映射函数将社交网络中的每个用户表示为低维向量,这些向量在一个向量空间中具有表示和推理的功能。Preozzi等[3]在2014年提出了基于网络的表示学习模型DeepWalk,该模型是受到Mikolov 等[4]在2013 年提出的用于自然语言处理的经典模型Word2vec 的启发,将网络中的节点看作单词,将利用随机游走生成的节点序列看作一个句子,通过SkipGram 模型的学习得到节点的向量表示。在社交网络中利用这些向量表示可以进行商品个性化推荐、节点分类、节点间链路预测和兴趣社区发现等。之后,一些学者在DeepWalk 的基础上提出了Node2vec[5]、LINE[6]和Struc2vec[7]等网络表示学习模型。图1 展示了网络表示学习模型的流程,可以看出网络表示学习为后续的社交网络研究开辟了新方向。

图1 网络表示学习流程Fig.1 Flowchart of network representation learning
现阶段影响力最大化问题的研究面临着两个主要的挑战:1)如何跳出理想状态下的公式计算,获得更真实的节点间影响概率;2)现有的大部分工作集中于在简化网络中考虑最大化的影响扩散,能否脱离固定的传播模型,考虑节点间的交互,从交互联系的角度来进行影响评估。针对上述问题,本文提出一种用户互动表示下的影响力最大化(Influence Maximization based on User Interactive Representation,IMUIR)算法,主要工作包括:
1)根据社交网络中用户的互动痕迹来构造用户上下文对;
2)利用SkipGram 模型学习用户表示,得到能表示用户的特征向量,根据用户活跃度和交互联系度,利用贪心策略选择最佳种子集;
3)在两个真实的社交网络上与4 个算法进行对比实验,验证了IMUIR算法的有效性。
1 相关研究
国内外的研究学者利用不同类型的方法对影响力最大化问题进行了研究。Chen 等[8]基于IC 模型和节点度的中心性提出了DegreeDiscount 算法;李敏佳等[9]综合考虑了核心节点和结构洞节点的传播优势,提出了基于结构洞和度折扣的最大化算法;Aldawish 等[10]通过对邻居节点的约束提出一种新的改进的度折扣启发式方法MDD(Modified Degree-Discount);Kim 等[11]提出了一种随机游动排序和秩合并修剪的算法,通过修剪无影响节点来避免无用的影响扩散;张宪立等[12]基于度和PageRank 的思想提出了一种混合启发式算法来解决大型网络上的影响力最大化问题;吴安彪等[13]在时序图上对影响力最大化问题进行了研究,提出了用来计算节点影响力的AIMT(Advanced method for IMTG)和IMIT(Improved method for IMTG)。
此外,一些群集智能算法也被运用到了影响力最大化的研究中。Jiang 等[14]提出一种评估预期影响的函数EDV(Expect Diffusion Value),结合模拟退火算法求解影响力最大化问题,该算法比利用函数子模性改进的贪心算法CELF(Cost-Effective Lazy Forward)快了近3个数量级;Cui等[15]基于一种降阶搜索策略,融合遗传算法提出度数递减搜索(Degree-Descending Search Evolution,DDSE);Gong 等[16]利用离散离子群算法与评估节点二阶区域内的预期影响函数相结合提出了DPSO(Discrete Paticle Swarm Optimization)算法,能够较为准确地找出种子节点;Sankar 等[17]受到蜂群摆舞行为的启发,提出了蜂群算法,在具有主题标签的Twitter重推网络中验证了该算法的有效性;Tang 等[18]提出了离散混合蛙跳算法,该算法基于一种新的编码机制和离散进化规则寻找种子节点。
尽管上述算法均取得了不错的效果,也在一定程度上取得了突破,但存在两个明显的弊端:一方面是基于理想状态来计算的节点间影响传播概率;另一方面是通过扩散模型来计算受一组种子用户影响的节点数量,而现有的扩散模型依赖于假设会导致结果不可靠,使得影响力最大化的求解面临着可扩展性[19]。
由于复杂网络包含数十亿的用户和连接关系,想要从中获取用户信息会非常棘手,而网络表示学习能够将影响力最大化问题在大规模网络中进行扩展。Wang 等[20]通过学习低维向量来计算影响概率,并利用启发式算法DiffusionDiscount来寻找种子集;王正海[21]将社交网络的节点引入到向量空间后先用K-Means聚类算法找到候选种子集,再利用KD 树确定最终的种子集。上述算法虽然利用网络表示学习对节点进行了表示,但仅利用网络结构来进行研究,没有考虑用户间的互动。Feng 等[22]从用户日志级联中提取用户上下文对,通过构建传播网络,利用低维表示来描述用户的社会影响嵌入,由于信息传播的有向性,每个用户有两种嵌入表示——源嵌入和目标嵌入,源嵌入表示对其他用户的影响,目标嵌入表示受其他用户的影响。该方法脱离了简单网络结构,从用户级联中确定影响扩散。Panagopoulos 等[23]利用多任务神经网络预测种子节点的预期影响和级联大小,利用预测的级联大小和CELF 算法的思想来选取种子集。该方法提出利用测试级联评估种子集的影响范围,更贴合真实的信息传播,但在采样和寻找种子集时没有考虑到用户行为特征。由上述研究可知,目前利用网络表示学习解决影响力最大化问题的研究还较少,且还有许多问题有待研究。
受Feng 等[22]研究的启发和针对Panagopoulos 研究中的不足,本文利用社交网络中用户自身的行为特性和用户间的互动,提出IMUIR算法。
2 用户互动表示下的影响力最大化算法
2.1 问题定义
Panagopoulos 等[23]在其研究中提出了利用用户产生的测试级联来评估种子集的影响范围,这样更贴近真实社交网络的规律。因此在本文中,给定一个社交网络图G=(V,E,Q),V表示社交网络中的用户,E表示用户关系,Q表示G中用户在一个时间段T内产生的同类型社交事件,事件的类型包括但不限于发博、评论、点赞和投票等用户交互行为。按照时间顺序将时间T中的事件划分为训练级联Qtrain和测试级联Qtest,影响力最大化问题就是从G中找到一组大小为K(K≤|V|)的用户集合U,使得U在Qtest中的影响范围σ(U)最大,形式化定义如下:

其中U*为最佳用户集合。
2.2 构建用户上下文对
利用网络结构求解影响力最大化问题时存在一个弊端,大多数固定的社交网络结构均来自用户的关注列表和粉丝列表,但在社交网络中通常都会存在“僵尸用户”,这些“僵尸用户”的存在对用户影响力的评估是没有意义的,甚至会导致评估产生偏差。而事件记录了一个用户在过去一段时间T内与网络中其他用户的互动行为,利用这些互动行为能较好地捕捉到用户之间的影响传播。Panagopoulos 等[23]在其研究中证实了那些在社交网络中具有较大影响力的用户多数都是在事件中发起互动的用户,也就是一个互动级联的产生者,而不是参与者。同时,根据影响力的传播动力学研究显示,由于影响衰减,最近邻域范围内的影响评估往往是最可靠的[24]。因此本文在构建用户上下文对时仅考虑用户的直接互动,通过事件中的用户互动级联进行采样,并且仅对产生互动级联的用户进行采样,利用该方法相当于对网络中的用户进行了初步筛选。
给定一个社交事件Qtrain,Xi为事件Qtrain中的一个用户互动级联,在Xi中ui(ui∈V) 为该互动的发起 者,vi={vi1,vi2,…,vik}(vi⊆V)表示在该级联下与ui进行互动的k个用户集合。以ui为源用户,从集合vi中随机选取目标用户构建ui的用户上下文对context(ui)={(ui,vi1),(ui,vi2),…,(ui,vik)},由于只考虑直接互动,因此事件中的级联是一对多的关系,一个用户上下文对中只有两位用户,分别是源用户和目标用户。根据图2 的事件描述可给出具体例子,X2是事件Qtrain中的一个用户互动级联,在X2中,u2是发布微博的源用户,v2={v21,v22,v23}是转发了该条微博的目标用户,假设从v2中随机选取两个用户v21和v22,那么可构建u2的用户上下文对context(u2)={(u2,v21),(u2,v22)},该集合表示u2直接影响了v21和v22。利用同样的方法可构建任意一个ui的用户上下文对。

图2 事件描述Fig.2 Event description
2.3 SkipGram模型
SkipGram 本质上是一个神经语言模型,在自然语言处理中被广泛使用,可根据单词向量表示利用当前的单词Wi预测其上下文Wi-2,Wi-1,Wi+1,Wi+2出现的概率,它规定了固定长度的“词窗口”,Wi的上下文仅由“词窗口”内的单词组成而非整个句子。将该思想运用到网络表示学习中就是预测一个当前用户的上下文概率假设出现在用户ui上下文中的各个用户间相互独立,那么用户ui上下文的概率如下所示:

SkipGram 模型的目标是最大化用户上下文的联合概率,并以此来更新用户的向量表示,因此目标函数的定义如式(3)所示:
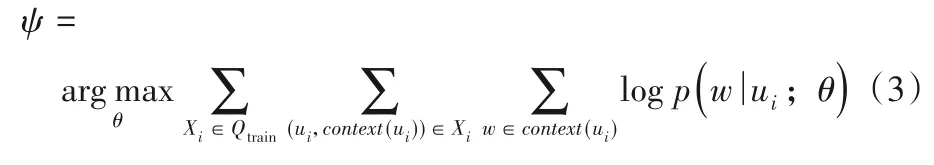
其 中:w∈context(ui) 表示用户ui的上下文用户w;(ui,context(ui)) ∈Xi表示ui的上下文对均来自Xi。
要计算目标函数的值ψ,首先需要计算用户上下文对中ui对w的概率p(|w ui),这个概率的计算需要通过表示用户间关系的特征向量来完成;θ为模型训练过程中需要更新的参数,也就是用户的特征向量矩阵,d为特征向量的维度,该矩阵可表示为

在本文方法中,将ui这类产生影响的用户称作源特征,表示为;将w这些受别人影响的用户称作目标特征,表示为Tw;b表示ui的影响偏置;ui对w的影响概率p(|w ui)可以利用学习到的特征向量经softmax函数得出,定义为
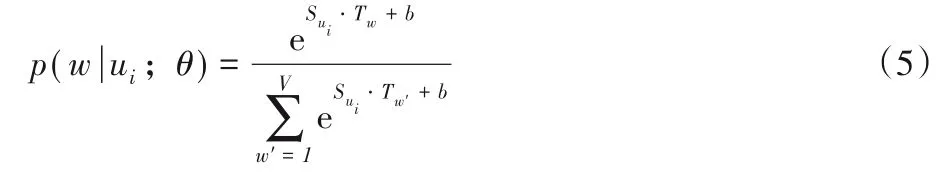
2.4 寻找种子集
由于媒体时代信息的快速更新使得用户信息产生了存活时长,而用户活跃度和用户间交互联系度在一定程度上决定了信息存活时长。在日常的社交网络平台的使用中,如果一个源用户在平台上的活跃度越高,源用户和目标用户间的交互联系就越频繁,这样可以增加源用户的信息存活时长,那么源用户的影响力也会越大。本文中的用户活跃度a是指源用户在一个事件中产生级联的次数,产生级联的次数越多,用户的活跃度也越高。
交互联系度f是源用户ui与网络中其余用户的互动联系的多少。首先利用特征向量根据式(5)计算ui对网络中其余用户的影响概率,选出网络中受ui影响最大的前α个目标用户(α为用户在Qtrain中产生的平均级联长度),因此,ui的交互联系度就是ui对网络中其余用户影响概率降序排列后前α个目标用户的影响概率总和:

本文根据用户活跃度和交互联系度利用贪心策略寻找最佳种子集,具体思想是:1)根据源用户在Qtrain中出现的次数计算源用户的活跃度a,选取部分活跃度高的用户作为候选种子集;2)根据式(6)计算候选种子集中每个源用户对网络中其余用户的影响概率,利用贪心策略选出当前f(ui)最大的源用户ui加入最佳种子集中,之后将选出的ui和受其影响最大的α个用户从网络中删除;3)重复过程2)直到迭代完成。具体算法描述如下所示:
输入 种子集大小K,事件Qtrain,源特征,目标特征Tw;
输出 最佳种子集U*。

2.5 时间复杂度分析
根据用户采样、训练模型和寻找种子集对IMUIR 算法进行时间复杂度分析。设采样数为I,特征向量的维数为m,Qtrain中的影响传播用户数为n,负采样数为M,种子集大小为K,候选种子集大小为|C|,训练过程中的收敛次数为D,则IMUIR的时间复杂度为:
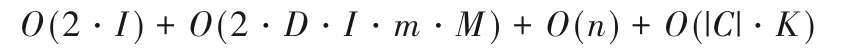
3 实验结果与分析
3.1 实验数据与对比算法
本文使用Digg和Weibo两个真实的社交网络数据进行实验,数据集除了有真实网络,还包括用户的日常互动级联,根据时间将前80%的级联作为训练集,将剩余级联作为测试集,详细信息如表1所示。

表1 实验数据集Tab.1 Datasets used in experiments
经实验测试,本文提出的IMUIR的参数设置为:采样率为400%,学习率为0.02,向量维度的设置参考了部分表示学习对于节点向量的人为设定,设定为50。同时为了验证所提算法IMUIR 的性能,选取下述4 个具有代表性的算法进行对比实验。
1)Random:该算法从网络中随机选择K个用户作为种子节点。
2)Average Cascade(AC):该算法的思想是利用用户产生的平均级联大小来决定种子集中的节点,产生的平均级联越长,就越有可能被选为种子节点。
3)Kcore:根据网络中用户的核数来决定种子节点。
4)Imfector:利用多任务神经网络学习得到用户的向量表示和用户可能产生的级联大小,利用特征向量计算用户的期望影响用户的比例Λ,根据Λ与影响扩散概率选取种子节点。在对比时,该算法的向量维度为50,采样率为120%,学习率为0.1,与其论文中的设置一致[23]。
本文所有算法均使用Python3 编写,在Windows 10 系统的PC端上运行,硬件配置为2.3 GHz Intel i5-6300HQ处理器,8 GB内存。
3.2 结果分析
评价影响力最大化算法通常使用影响扩散范围和运行时间这两个指标。本文的影响扩散范围是指在测试级联Qtest中与种子用户互动的用户数量,数量越多,种子集影响力越大[23]。运行时间是指算法找到最佳种子集所需要的时间,IMUIR 和Imfector 的时间包含采样、训练和寻找种子集三部分。
3.2.1 种子集质量评估
在利用算法找到最佳种子集后,首先需要找到种子用户出现在测试集中的数量,这主要是根据种子用户能否在未来的一段时间内产生影响来评估选出的用户集合的质量。在Digg和Weibo数据集中找到的种子用户数如表2、3所示,在指定的种子大小下基于用户级联的表示学习方法找到的种子用户比基于网络结构的方法多,而在表示学习的方法中,IMUIR能找到的种子集数量比Imfector 多。这说明利用表示学习寻找到种子集的方法是可行的,并且IMUIR 能找到的有效节点更多,种子集质量优于其他方法。

表2 Digg中找到的种子用户数量Tab.2 Number of seed users found in Digg
3.2.2 影响范围对比
在影响范围图中,X轴表示不同大小的种子集,Y轴对应不同种子集下影响的用户数量。
图3 展示了5 个算法在两个数据集和不同种子集大小下的实验结果,从Digg 数据集可以发现,IMUIR 算法表现最好,当种子集大小为200 时,其影响范围比Random、AC、Kcore 和Imfector 分别高了13.59%、39.47%、16.10%和5.90%,产生的影响范围最广,Imfector其次,而AC表现最差。值得注意的是,结合表2 和图3(a)可以看到,当种子集大小为80 时,IMUIR 找到的56 个高质量用户产生的影响范围是31 144,而Imfector 找到的50 个高质量用户产生的影响范围是33 417,Imfector 在高质量种子比IMUIR 少了6 个的情况下影响范围比IMUIR高了7.29%,产生的原因可能有两个:一方面是因为IMUIR 找到的这56 个种子在影响传播时产生了富集性,通常来说就是有一部分用户可能受到多个种子用户的影响,出现在了多个种子用户产生的级联下,由此产生了影响重叠;另一方面是种子用户在未来的这段时间内自身产生的影响范围较小。此外,当种子集大小为200 时,Kcore 与Random 相比影响范围低了2.2%也是上述原因之一导致的。当种子集大小为20 时,在IMUIR 和Imfector 中均找到15 个能够产生影响的种子用户,但IMUIR的影响范围比Imfector高了4.4%。
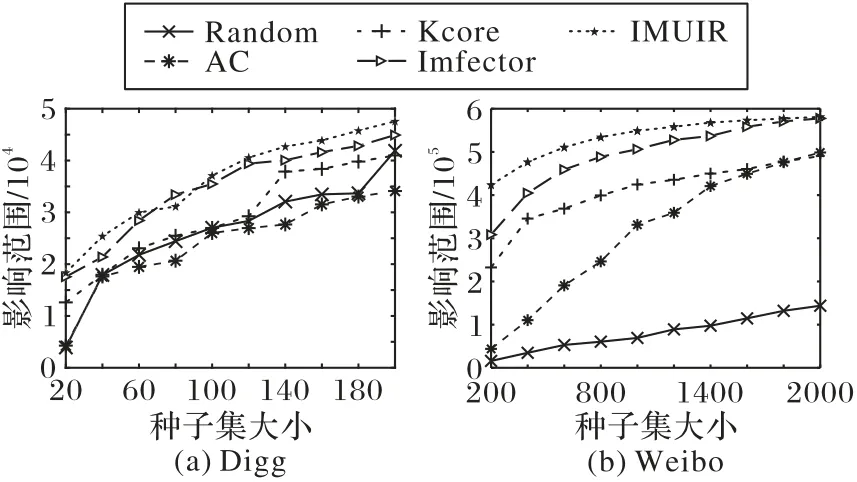
图3 影响范围对比Fig.3 Comparison of influence scope
在Weibo 数据集中,从整体来看,基于表示学习的IMUIR和Imfector的表现远优于其余三个算法,但IMUIR依旧表现最好,而Random 表现最差。当种子集大小为2 000时,IMUIR 的影响范围比Random、AC、Kcore 和Imfector 分别高304.19%、16.53%、18.48%和0.58%。同样结合表3 和图3(b)可以看到,AC 与Random、AC 与Kcore 也出现了上述在Digg 数据集中讨论过的现象,当种子集大小为200和400时,Random 中能产生影响的种子数量比AC 多,但在传播范围上AC 比Random多了174.82%和217.34%。当种子集大小为2 000 时,Kcore中能产生影响的种子数比AC 多了129 个,但影响范围比AC低了1.64%。
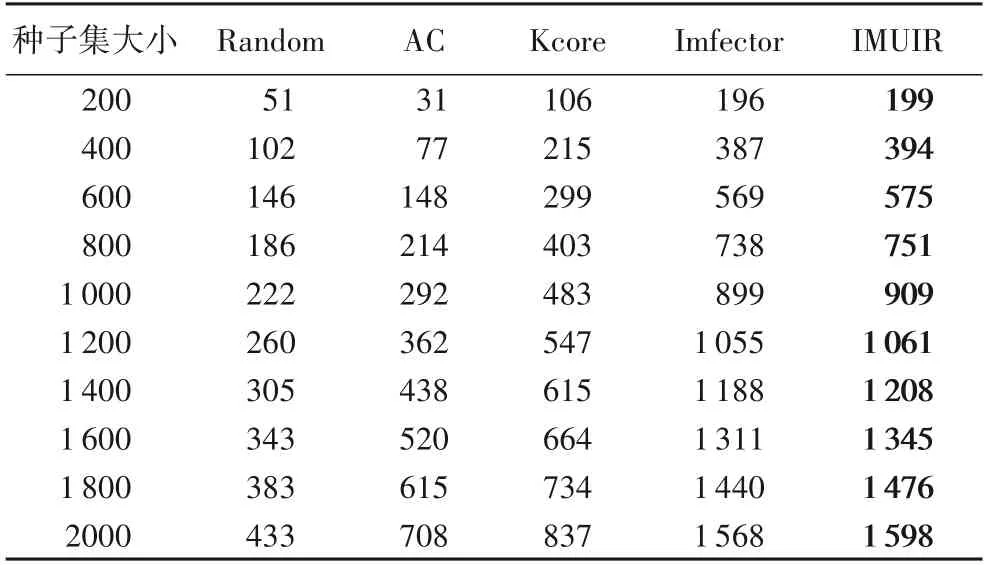
表3 Weibo中找到的种子用户数量Tab.3 Number of seed users found in Weibo
此外,为了进一步证明IMUIR 的有效性,将Qtest中产生的级联大小排在前K的源用户所组成的种子集产生的影响范围C(k)(k为种子集大小)作为参考基线,并将5个算法与C(k)进行影响范围对比,获得在以C(k)为基线的参考下,5个算法影响范围降低或提高的百分比,如表4 和表5 所示,其中:“+”表示算法的影响范围与C(k)相比提高的百分比,“-”则表示降低的百分比。

表4 各算法在Digg上与C(k)影响范围的对比 单位:%Tab.4 Comparison of influence scope of different algorithms on Digg with C(k unit:%
在Digg 数据集中可以看到,当种子集大小为200 时,IMUIR 的影响范围只比C(200)小22.43%,Imfector次之,相差26.76%,而AC 与之相差44.38%,差距最大。在表5 显示的Weibo 数据集中,在不同种子集大小下,IMUIR 的影响范围均超过了C(k)产生的影响范围,可能的原因是C(k)产生影响时有较多的影响重叠,局限了传播范围,而IMUIR寻找到的种子集产生的影响重叠不多,影响范围更广,说明利用IMUIR寻找到的种子集质量更高。
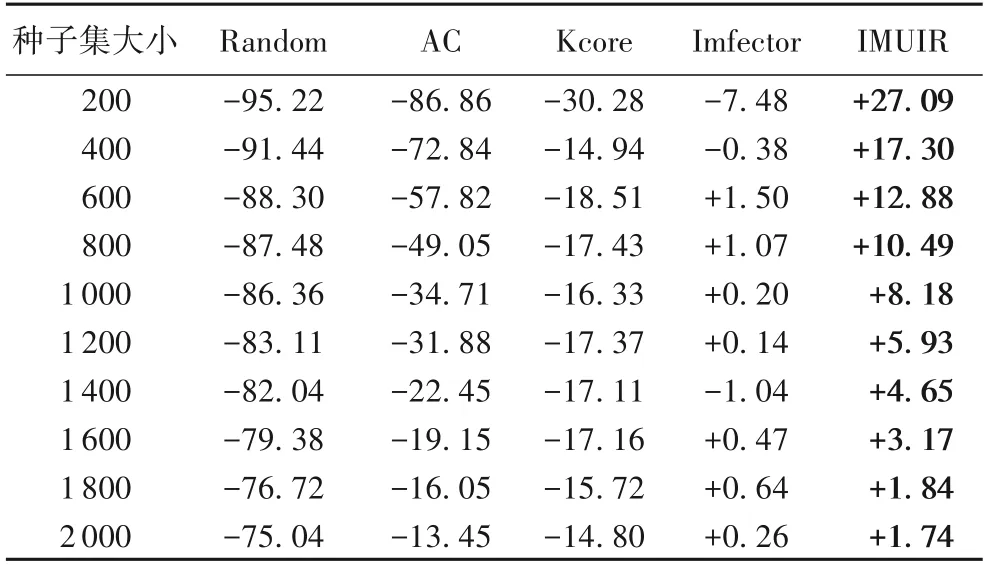
表5 各算法在Weibo上与C(k)影响范围的对比 单位:%Tab.5 Comparison of influence scope of different algorithms on Weibo with C(k unit:%
上述实验结果表明,本文提出的IMUIR 在两个数据集上表现都较好也较为稳定,IMUIR 和Imfector之间的比较也说明了在寻找最佳种子时考虑用户的活跃度和交互联系度是必要的,而像AC这样根据平均级联来选择种子集的算法对用户级联很挑剔,Kcore表现也较为稳定,但总体效果不佳。
3.2.3 运行时间对比
图4 显示了Kcore、AC、Imfector、IMUIR 这四个算法在两个不同数据集上的运行时间对比,这里需要说明的是由于Random 算法的运行时间极短,在Digg 和Weibo 这两个数据集上的运行时间分别为0.81 s 和1.97 s,因此没有在图上进行显示。虽然Random 运行时间最短,但其算法性能不稳定,效果也不佳。从图中可以发现,表示学习算法由于要进行采样和学习,因此运行时间均比其他几个算法多。Kcore也只需要125.847 7 s 就能从Digg 数据集中找出最佳种子集,但找到的种子集质量不高,传播的影响范围也不够大;AC 相比起Random 和Kcore用时多一些,但算法性能也不稳定,对数据结构很挑剔;IMUIR 在两个数据集上的用时比Imfector分别多了14.28%和6.53%,但IMUIR 在影响范围上的优势可以弥补效率上的不足,说明IMUIR 也是能够解决影响力最大化问题的一种方法。

图4 不同数据集上各算法的运行时间对比Fig.4 Running time comparison of different algotirhms on different datasets
4 结语
本文基于用户互动表示提出IMUIR 算法,主要利用用户自身活跃度和特征向量捕捉的交互联系度寻找最优种子集,并验证了算法的有效性。但利用表示学习求解影响力最大化问题还有充足的改进空间:一方面针对上述算法可以寻求更便捷的方法以缩短时间,在兼顾效果的同时提高效率;另一方面,用户间不仅仅有行为上的交互,还会涉及情感交互,在有合适数据集的情况下可以将情感交互融合到这种类型的影响力最大化问题的求解中,以探索更真实可靠的用户影响力。
